 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Channel Reciprocity Attacks Using Intelligent Surfaces with Non-Diagonal Phase Shifts
Sep 20, 2023
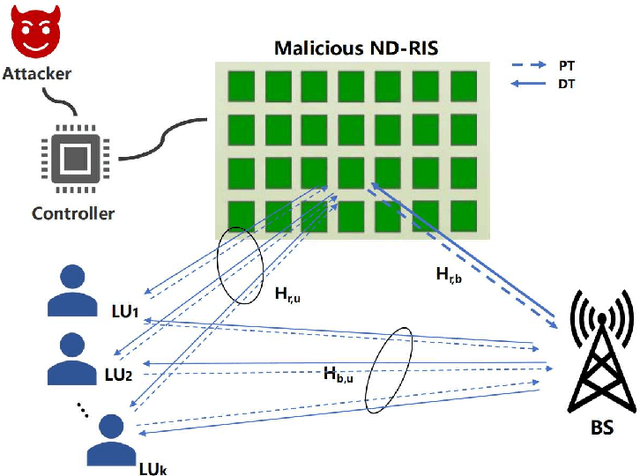
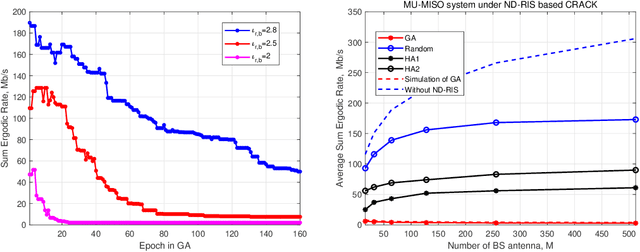
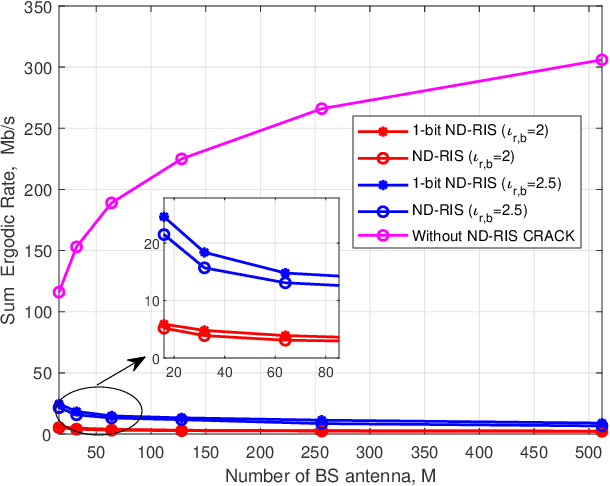
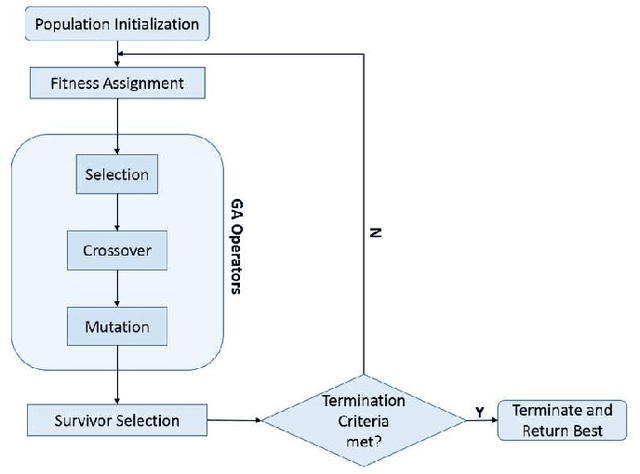
While reconfigurable intelligent surface (RIS) technology has been shown to provide numerous benefits to wireless systems, in the hands of an adversary such technology can also be used to disrupt communication links. This paper describes and analyzes an RIS-based attack on multi-antenna wireless systems that operate in time-division duplex mode under the assumption of channel reciprocity. In particular, we show how an RIS with a non-diagonal (ND) phase shift matrix (referred to here as an ND-RIS) can be deployed to maliciously break the channel reciprocity and hence degrade the downlink network performance. Such an attack is entirely passive and difficult to detect. We provide a theoretical analysis of the degradation in the sum ergodic rate that results when an arbitrary malicious ND-RIS is deployed and design an approach based on the genetic algorithm for optimizing the ND structure under partial knowledge of the available channel state information. Our simulation results validate the analysis and demonstrate that an ND-RIS channel reciprocity attack can dramatically reduce the downlink throughput.
Towards Robust Few-shot Point Cloud Semantic Segmentation
Sep 20, 2023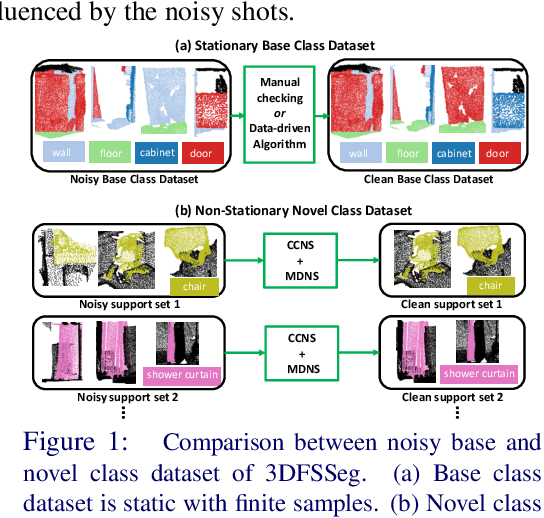
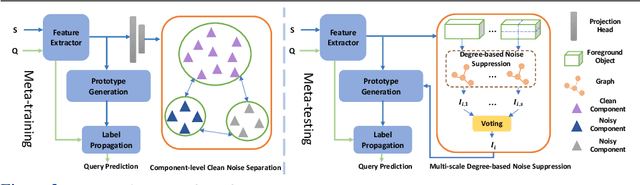
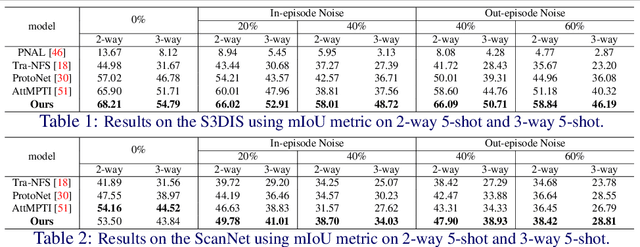
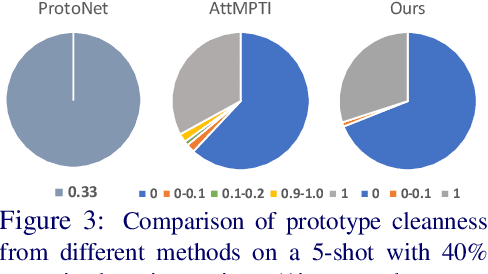
Few-shot point cloud semantic segmentation aims to train a model to quickly adapt to new unseen classes with only a handful of support set samples. However, the noise-free assumption in the support set can be easily violated in many practical real-world settings. In this paper, we focus on improving the robustness of few-shot point cloud segmentation under the detrimental influence of noisy support sets during testing time. To this end, we first propose a Component-level Clean Noise Separation (CCNS) representation learning to learn discriminative feature representations that separates the clean samples of the target classes from the noisy samples. Leveraging the well separated clean and noisy support samples from our CCNS, we further propose a Multi-scale Degree-based Noise Suppression (MDNS) scheme to remove the noisy shots from the support set. We conduct extensive experiments on various noise settings on two benchmark datasets. Our results show that the combination of CCNS and MDNS significantly improves the performance. Our code is available at https://github.com/Pixie8888/R3DFSSeg.
Multi-Step Model Predictive Safety Filters: Reducing Chattering by Increasing the Prediction Horizon
Sep 20, 2023Learning-based controllers have demonstrated superior performance compared to classical controllers in various tasks. However, providing safety guarantees is not trivial. Safety, the satisfaction of state and input constraints, can be guaranteed by augmenting the learned control policy with a safety filter. Model predictive safety filters (MPSFs) are a common safety filtering approach based on model predictive control (MPC). MPSFs seek to guarantee safety while minimizing the difference between the proposed and applied inputs in the immediate next time step. This limited foresight can lead to jerky motions and undesired oscillations close to constraint boundaries, known as chattering. In this paper, we reduce chattering by considering input corrections over a longer horizon. Under the assumption of bounded model uncertainties, we prove recursive feasibility using techniques from robust MPC. We verified the proposed approach in both extensive simulation and quadrotor experiments. In experiments with a Crazyflie 2.0 drone, we show that, in addition to preserving the desired safety guarantees, the proposed MPSF reduces chattering by more than a factor of 4 compared to previous MPSF formulations.
Multi-Risk-RRT: An Efficient Motion Planning Algorithm for Robotic Autonomous Luggage Trolley Collection at Airports
Sep 20, 2023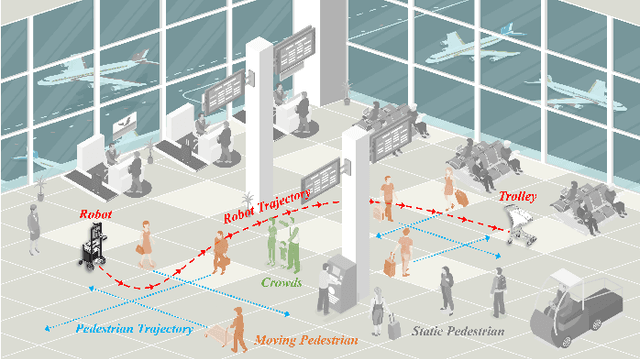
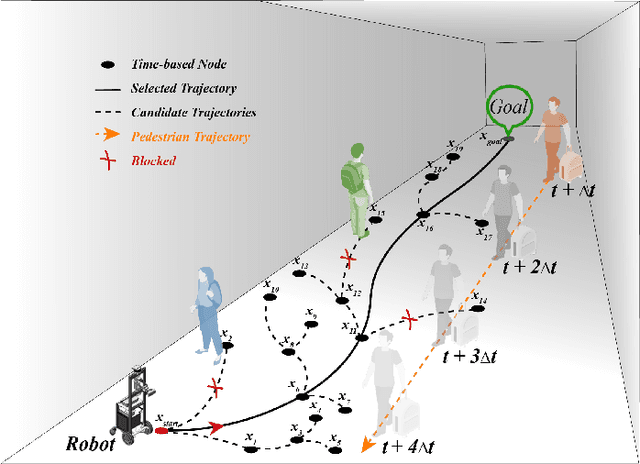
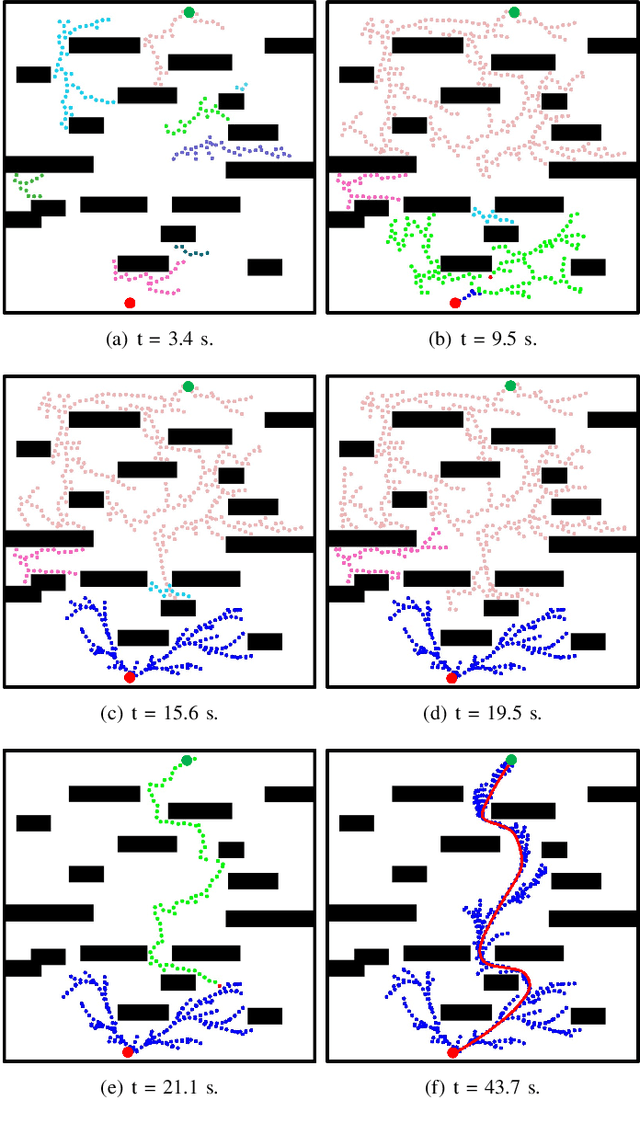
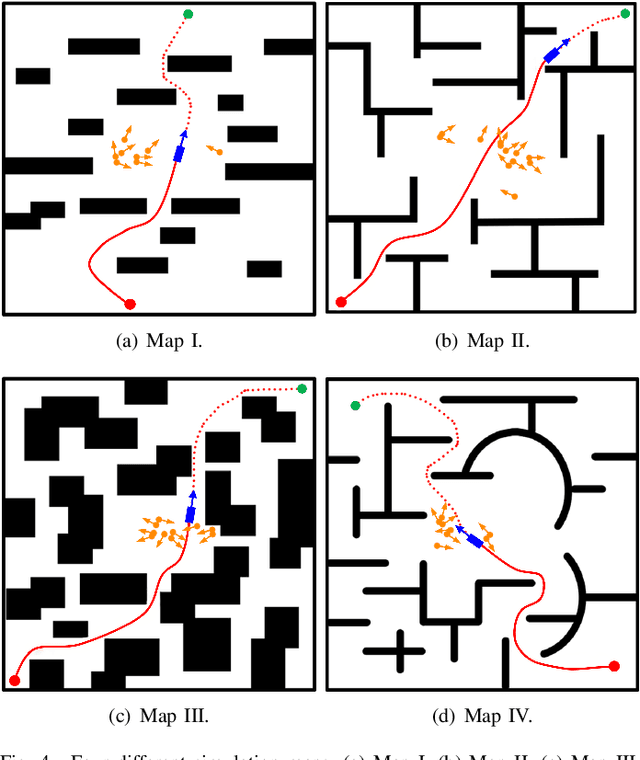
Robots have become increasingly prevalent in dynamic and crowded environments such as airports and shopping malls. In these scenarios, the critical challenges for robot navigation are reliability and timely arrival at predetermined destinations. While existing risk-based motion planning algorithms effectively reduce collision risks with static and dynamic obstacles, there is still a need for significant performance improvements. Specifically, the dynamic environments demand more rapid responses and robust planning. To address this gap, we introduce a novel risk-based multi-directional sampling algorithm, Multi-directional Risk-based Rapidly-exploring Random Tree (Multi-Risk-RRT). Unlike traditional algorithms that solely rely on a rooted tree or double trees for state space exploration, our approach incorporates multiple sub-trees. Each sub-tree independently explores its surrounding environment. At the same time, the primary rooted tree collects the heuristic information from these sub-trees, facilitating rapid progress toward the goal state. Our evaluations, including simulation and real-world environmental studies, demonstrate that Multi-Risk-RRT outperforms existing unidirectional and bi-directional risk-based algorithms in planning efficiency and robustness.
Fake News BR: A Fake News Detection Platform for Brazilian Portuguese
Sep 20, 2023The proliferation of fake news has become a significant concern in recent times due to its potential to spread misinformation and manipulate public opinion. In this paper, we present a comprehensive study on the detection of fake news in Brazilian Portuguese, focusing on journalistic-type news. We propose a machine learning-based approach that leverages natural language processing techniques, including TF-IDF and Word2Vec, to extract features from textual data. We evaluate the performance of various classification algorithms, such as logistic regression, support vector machine, random forest, AdaBoost, and LightGBM, on a dataset containing both true and fake news articles. The proposed approach achieves a high level of accuracy and F1-Score, demonstrating its effectiveness in identifying fake news. Additionally, we develop a user-friendly web platform, FAKENEWSBR.COM, to facilitate the verification of news articles' veracity. Our platform provides real-time analysis, allowing users to assess the likelihood of news articles being fake. Through empirical analysis and comparative studies, we demonstrate the potential of our approach to contribute to the fight against the spread of fake news and promote more informed media consumption.
Long-Form End-to-End Speech Translation via Latent Alignment Segmentation
Sep 20, 2023Current simultaneous speech translation models can process audio only up to a few seconds long. Contemporary datasets provide an oracle segmentation into sentences based on human-annotated transcripts and translations. However, the segmentation into sentences is not available in the real world. Current speech segmentation approaches either offer poor segmentation quality or have to trade latency for quality. In this paper, we propose a novel segmentation approach for a low-latency end-to-end speech translation. We leverage the existing speech translation encoder-decoder architecture with ST CTC and show that it can perform the segmentation task without supervision or additional parameters. To the best of our knowledge, our method is the first that allows an actual end-to-end simultaneous speech translation, as the same model is used for translation and segmentation at the same time. On a diverse set of language pairs and in- and out-of-domain data, we show that the proposed approach achieves state-of-the-art quality at no additional computational cost.
CaveSeg: Deep Semantic Segmentation and Scene Parsing for Autonomous Underwater Cave Exploration
Sep 20, 2023
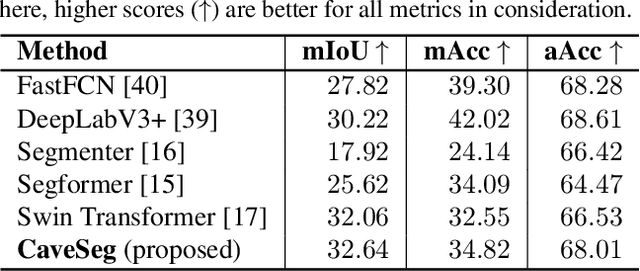

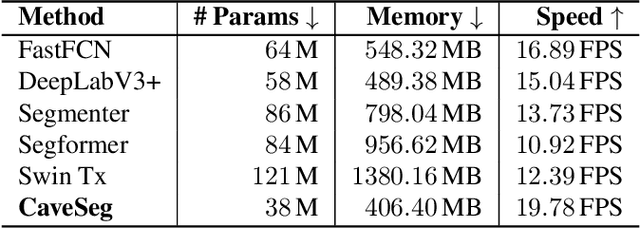
In this paper, we present CaveSeg - the first visual learning pipeline for semantic segmentation and scene parsing for AUV navigation inside underwater caves. We address the problem of scarce annotated training data by preparing a comprehensive dataset for semantic segmentation of underwater cave scenes. It contains pixel annotations for important navigation markers (e.g. caveline, arrows), obstacles (e.g. ground plain and overhead layers), scuba divers, and open areas for servoing. Through comprehensive benchmark analyses on cave systems in USA, Mexico, and Spain locations, we demonstrate that robust deep visual models can be developed based on CaveSeg for fast semantic scene parsing of underwater cave environments. In particular, we formulate a novel transformer-based model that is computationally light and offers near real-time execution in addition to achieving state-of-the-art performance. Finally, we explore the design choices and implications of semantic segmentation for visual servoing by AUVs inside underwater caves. The proposed model and benchmark dataset open up promising opportunities for future research in autonomous underwater cave exploration and mapping.
KFC: Kinship Verification with Fair Contrastive Loss and Multi-Task Learning
Sep 20, 2023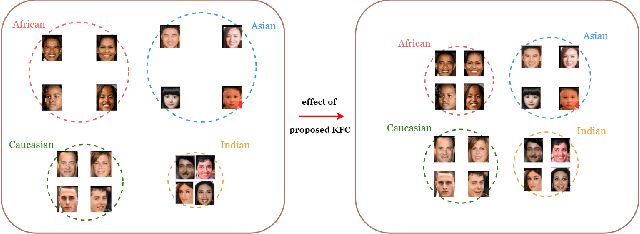
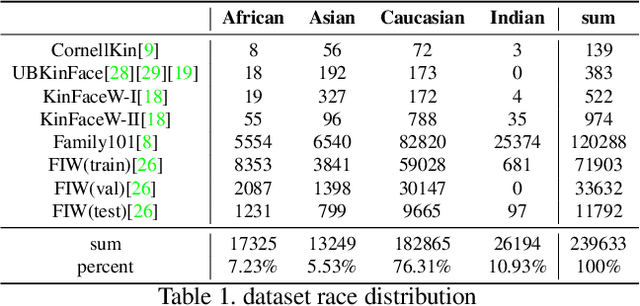
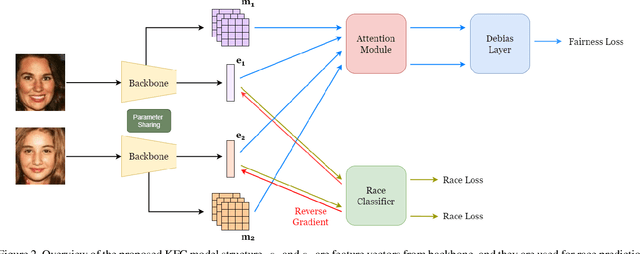
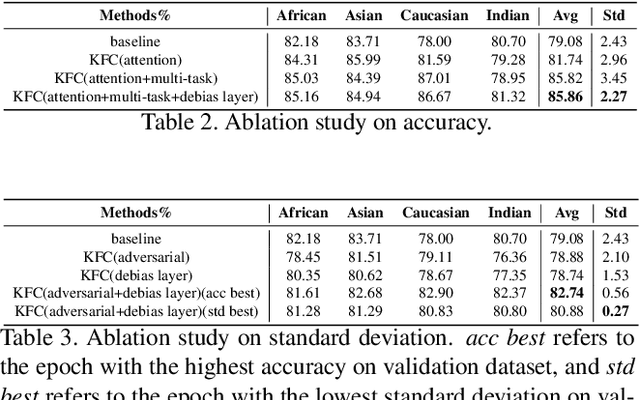
Kinship verification is an emerging task in computer vision with multiple potential applications. However, there's no large enough kinship dataset to train a representative and robust model, which is a limitation for achieving better performance. Moreover, face verification is known to exhibit bias, which has not been dealt with by previous kinship verification works and sometimes even results in serious issues. So we first combine existing kinship datasets and label each identity with the correct race in order to take race information into consideration and provide a larger and complete dataset, called KinRace dataset. Secondly, we propose a multi-task learning model structure with attention module to enhance accuracy, which surpasses state-of-the-art performance. Lastly, our fairness-aware contrastive loss function with adversarial learning greatly mitigates racial bias. We introduce a debias term into traditional contrastive loss and implement gradient reverse in race classification task, which is an innovative idea to mix two fairness methods to alleviate bias. Exhaustive experimental evaluation demonstrates the effectiveness and superior performance of the proposed KFC in both standard deviation and accuracy at the same time.
DynaMoN: Motion-Aware Fast And Robust Camera Localization for Dynamic NeRF
Sep 16, 2023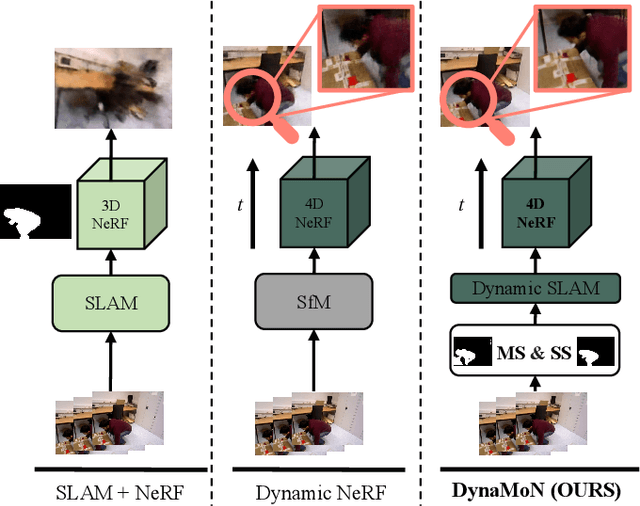
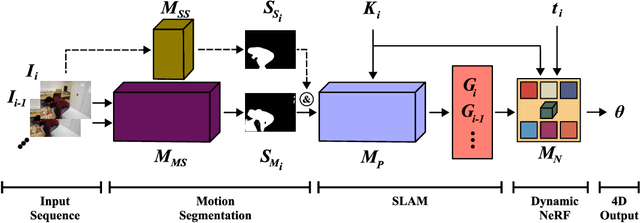


Dynamic reconstruction with neural radiance fields (NeRF) requires accurate camera poses. These are often hard to retrieve with existing structure-from-motion (SfM) pipelines as both camera and scene content can change. We propose DynaMoN that leverages simultaneous localization and mapping (SLAM) jointly with motion masking to handle dynamic scene content. Our robust SLAM-based tracking module significantly accelerates the training process of the dynamic NeRF while improving the quality of synthesized views at the same time. Extensive experimental validation on TUM RGB-D, BONN RGB-D Dynamic and the DyCheck's iPhone dataset, three real-world datasets, shows the advantages of DynaMoN both for camera pose estimation and novel view synthesis.
Dynamic Handover: Throw and Catch with Bimanual Hands
Sep 11, 2023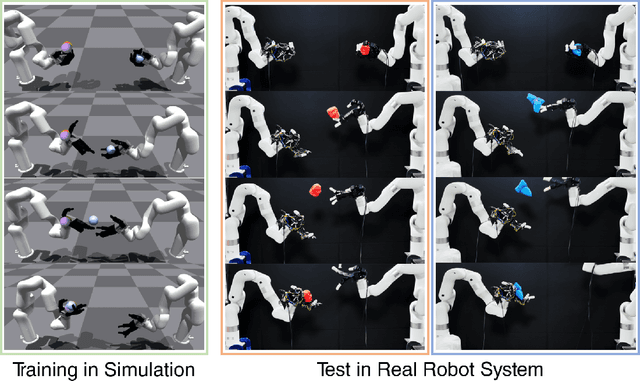
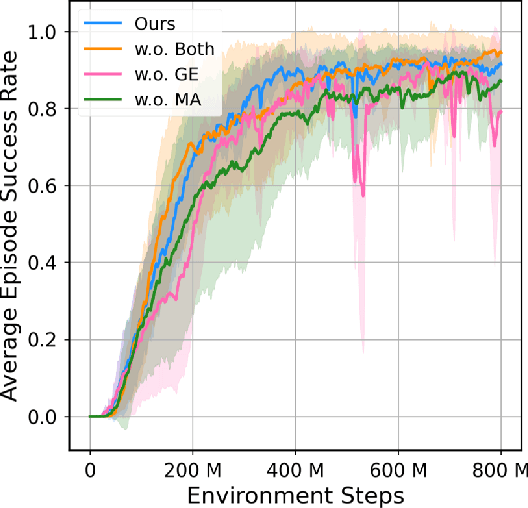
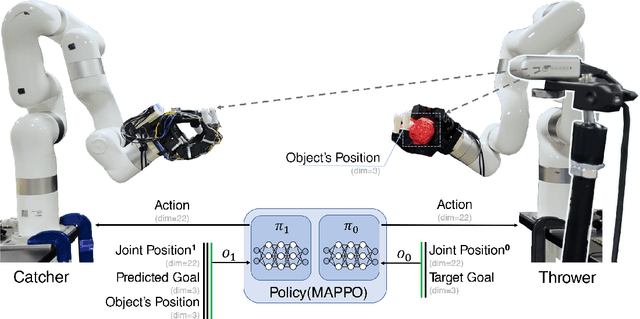
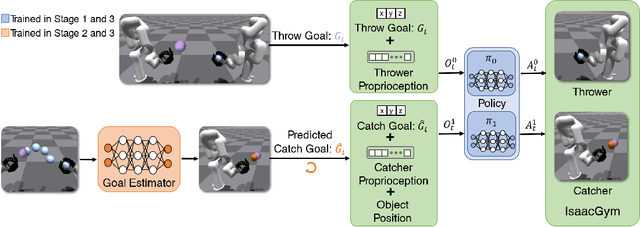
Humans throw and catch objects all the time. However, such a seemingly common skill introduces a lot of challenges for robots to achieve: The robots need to operate such dynamic actions at high-speed, collaborate precisely, and interact with diverse objects. In this paper, we design a system with two multi-finger hands attached to robot arms to solve this problem. We train our system using Multi-Agent Reinforcement Learning in simulation and perform Sim2Real transfer to deploy on the real robots. To overcome the Sim2Real gap, we provide multiple novel algorithm designs including learning a trajectory prediction model for the object. Such a model can help the robot catcher has a real-time estimation of where the object will be heading, and then react accordingly. We conduct our experiments with multiple objects in the real-world system, and show significant improvements over multiple baselines. Our project page is available at \url{https://binghao-huang.github.io/dynamic_handover/}.