 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Multi-view Anomaly Detection with Disentangled Product-of-Experts Modeling
Oct 28, 2023

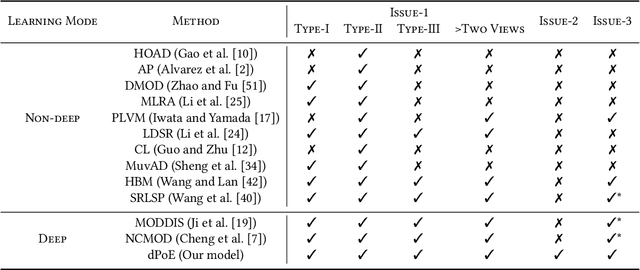
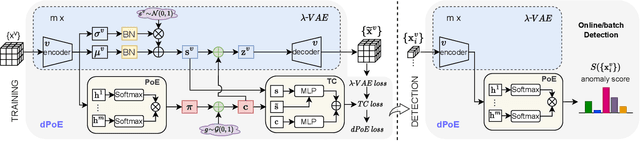
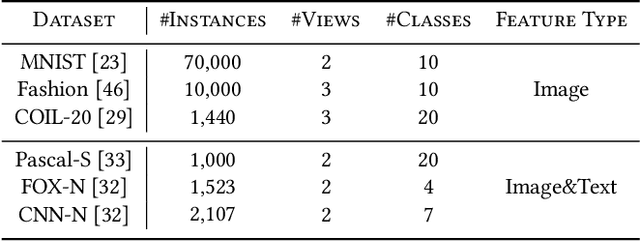
Multi-view or even multi-modal data is appealing yet challenging for real-world applications. Detecting anomalies in multi-view data is a prominent recent research topic. However, most of the existing methods 1) are only suitable for two views or type-specific anomalies, 2) suffer from the issue of fusion disentanglement, and 3) do not support online detection after model deployment. To address these challenges, our main ideas in this paper are three-fold: multi-view learning, disentangled representation learning, and generative model. To this end, we propose dPoE, a novel multi-view variational autoencoder model that involves (1) a Product-of-Experts (PoE) layer in tackling multi-view data, (2) a Total Correction (TC) discriminator in disentangling view-common and view-specific representations, and (3) a joint loss function in wrapping up all components. In addition, we devise theoretical information bounds to control both view-common and view-specific representations. Extensive experiments on six real-world datasets demonstrate that the proposed dPoE outperforms baselines markedly.
Tracking and fast imaging of a translational object via Fourier modulation
Oct 28, 2023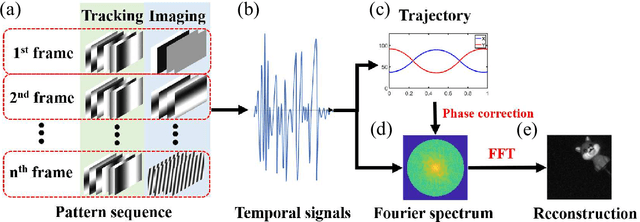
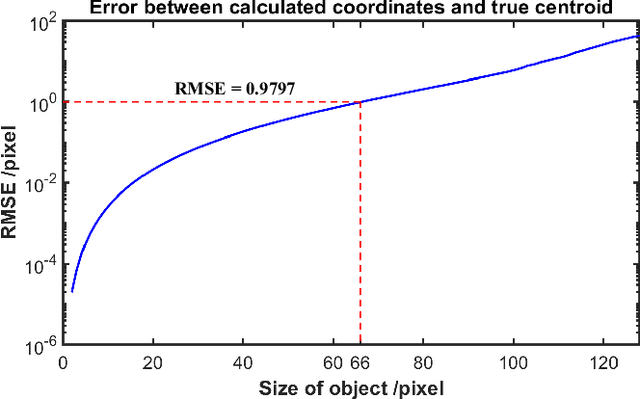
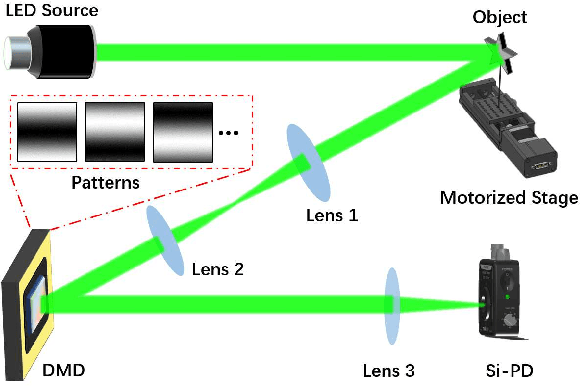

The tracking and imaging of high-speed moving objects hold significant promise for application in various fields. Single-pixel imaging enables the progressive capture of a fast-moving translational object through motion compensation. However, achieving a balance between a short reconstruction time and a good image quality is challenging. In this study, we present a approach that simultaneously incorporates position encoding and spatial information encoding through the Fourier patterns. The utilization of Fourier patterns with specific spatial frequencies ensures robust and accurate object localization. By exploiting the properties of the Fourier transform, our method achieves a remarkable reduction in time complexity and memory consumption while significantly enhancing image quality. Furthermore, we introduce an optimized sampling strategy specifically tailored for small moving objects, significantly reducing the required dwell time for imaging. The proposed method provides a practical solution for the real-time tracking, imaging and edge detection of translational objects, underscoring its considerable potential for diverse applications.
Optimizing Retrieval-augmented Reader Models via Token Elimination
Oct 20, 2023Fusion-in-Decoder (FiD) is an effective retrieval-augmented language model applied across a variety of open-domain tasks, such as question answering, fact checking, etc. In FiD, supporting passages are first retrieved and then processed using a generative model (Reader), which can cause a significant bottleneck in decoding time, particularly with long outputs. In this work, we analyze the contribution and necessity of all the retrieved passages to the performance of reader models, and propose eliminating some of the retrieved information, at the token level, that might not contribute essential information to the answer generation process. We demonstrate that our method can reduce run-time by up to 62.2%, with only a 2% reduction in performance, and in some cases, even improve the performance results.
A Benchmark for Semi-Inductive Link Prediction in Knowledge Graphs
Oct 18, 2023Semi-inductive link prediction (LP) in knowledge graphs (KG) is the task of predicting facts for new, previously unseen entities based on context information. Although new entities can be integrated by retraining the model from scratch in principle, such an approach is infeasible for large-scale KGs, where retraining is expensive and new entities may arise frequently. In this paper, we propose and describe a large-scale benchmark to evaluate semi-inductive LP models. The benchmark is based on and extends Wikidata5M: It provides transductive, k-shot, and 0-shot LP tasks, each varying the available information from (i) only KG structure, to (ii) including textual mentions, and (iii) detailed descriptions of the entities. We report on a small study of recent approaches and found that semi-inductive LP performance is far from transductive performance on long-tail entities throughout all experiments. The benchmark provides a test bed for further research into integrating context and textual information in semi-inductive LP models.
Deep Integrated Explanations
Oct 23, 2023This paper presents Deep Integrated Explanations (DIX) - a universal method for explaining vision models. DIX generates explanation maps by integrating information from the intermediate representations of the model, coupled with their corresponding gradients. Through an extensive array of both objective and subjective evaluations spanning diverse tasks, datasets, and model configurations, we showcase the efficacy of DIX in generating faithful and accurate explanation maps, while surpassing current state-of-the-art methods.
Probing LLMs for hate speech detection: strengths and vulnerabilities
Oct 19, 2023
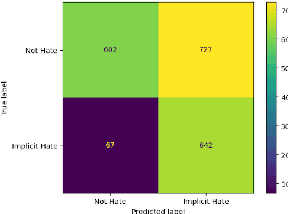
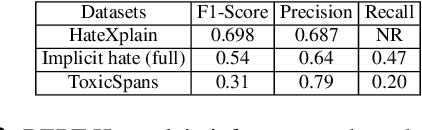
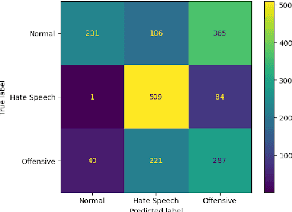
Recently efforts have been made by social media platforms as well as researchers to detect hateful or toxic language using large language models. However, none of these works aim to use explanation, additional context and victim community information in the detection process. We utilise different prompt variation, input information and evaluate large language models in zero shot setting (without adding any in-context examples). We select three large language models (GPT-3.5, text-davinci and Flan-T5) and three datasets - HateXplain, implicit hate and ToxicSpans. We find that on average including the target information in the pipeline improves the model performance substantially (~20-30%) over the baseline across the datasets. There is also a considerable effect of adding the rationales/explanations into the pipeline (~10-20%) over the baseline across the datasets. In addition, we further provide a typology of the error cases where these large language models fail to (i) classify and (ii) explain the reason for the decisions they take. Such vulnerable points automatically constitute 'jailbreak' prompts for these models and industry scale safeguard techniques need to be developed to make the models robust against such prompts.
FMRT: Learning Accurate Feature Matching with Reconciliatory Transformer
Oct 20, 2023Local Feature Matching, an essential component of several computer vision tasks (e.g., structure from motion and visual localization), has been effectively settled by Transformer-based methods. However, these methods only integrate long-range context information among keypoints with a fixed receptive field, which constrains the network from reconciling the importance of features with different receptive fields to realize complete image perception, hence limiting the matching accuracy. In addition, these methods utilize a conventional handcrafted encoding approach to integrate the positional information of keypoints into the visual descriptors, which limits the capability of the network to extract reliable positional encoding message. In this study, we propose Feature Matching with Reconciliatory Transformer (FMRT), a novel Transformer-based detector-free method that reconciles different features with multiple receptive fields adaptively and utilizes parallel networks to realize reliable positional encoding. Specifically, FMRT proposes a dedicated Reconciliatory Transformer (RecFormer) that consists of a Global Perception Attention Layer (GPAL) to extract visual descriptors with different receptive fields and integrate global context information under various scales, Perception Weight Layer (PWL) to measure the importance of various receptive fields adaptively, and Local Perception Feed-forward Network (LPFFN) to extract deep aggregated multi-scale local feature representation. Extensive experiments demonstrate that FMRT yields extraordinary performance on multiple benchmarks, including pose estimation, visual localization, homography estimation, and image matching.
Unveil Sleep Spindles with Concentration of Frequency and Time
Oct 27, 2023Objective: Sleep spindles contain crucial brain dynamics information. We introduce the novel non-linear time-frequency analysis tool 'Concentration of Frequency and Time' (ConceFT) to create an interpretable automated algorithm for sleep spindle annotation in EEG data and to measure spindle instantaneous frequencies (IFs). Methods: ConceFT effectively reduces stochastic EEG influence, enhancing spindle visibility in the time-frequency representation. Our automated spindle detection algorithm, ConceFT-Spindle (ConceFT-S), is compared to A7 (non-deep learning) and SUMO (deep learning) using Dream and MASS benchmark databases. We also quantify spindle IF dynamics. Results: ConceFT-S achieves F1 scores of 0.749 in Dream and 0.786 in MASS, which is equivalent to or surpass A7 and SUMO with statistical significance. We reveal that spindle IF is generally nonlinear. Conclusion: ConceFT offers an accurate, interpretable EEG-based sleep spindle detection algorithm and enables spindle IF quantification.
Reranking Passages with Coarse-to-Fine Neural Retriever using List-Context Information
Aug 23, 2023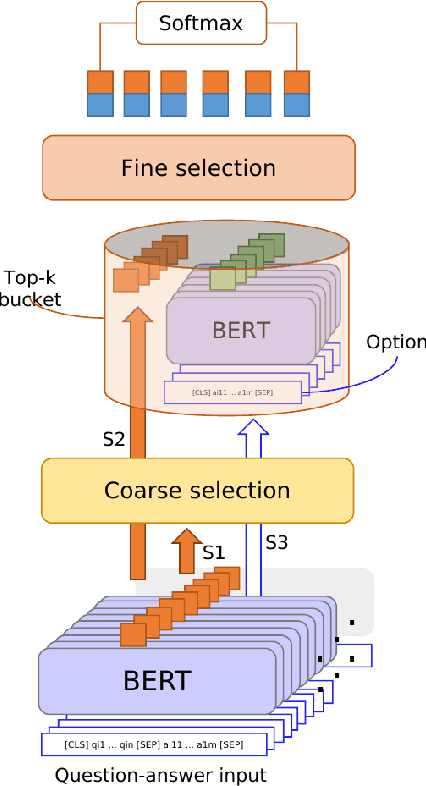
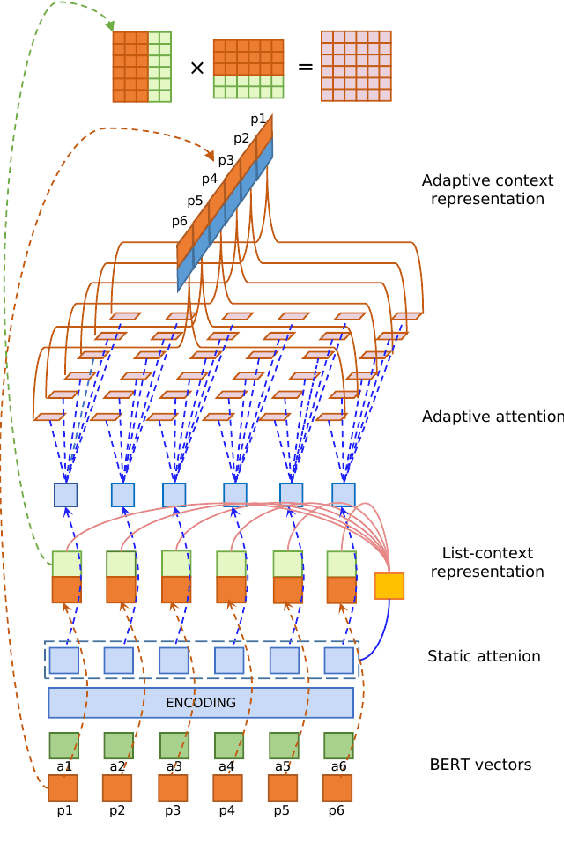
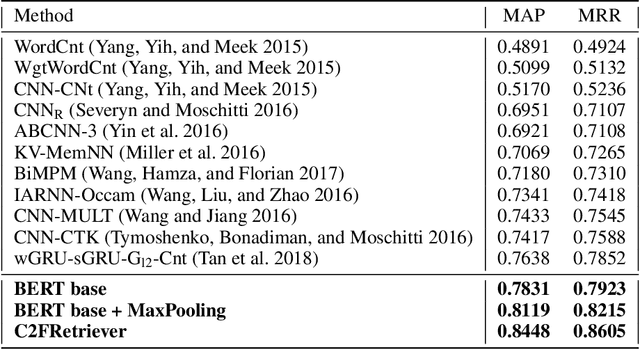
Passage reranking is a crucial task in many applications, particularly when dealing with large-scale documents. Traditional neural architectures are limited in retrieving the best passage for a question because they usually match the question to each passage separately, seldom considering contextual information in other passages that can provide comparison and reference information. This paper presents a list-context attention mechanism to augment the passage representation by incorporating the list-context information from other candidates. The proposed coarse-to-fine (C2F) neural retriever addresses the out-of-memory limitation of the passage attention mechanism by dividing the list-context modeling process into two sub-processes, allowing for efficient encoding of context information from a large number of candidate answers. This method can be generally used to encode context information from any number of candidate answers in one pass. Different from most multi-stage information retrieval architectures, this model integrates the coarse and fine rankers into the joint optimization process, allowing for feedback between the two layers to update the model simultaneously. Experiments demonstrate the effectiveness of the proposed approach.
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation
Oct 29, 2023This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.