 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SKU-Patch: Towards Efficient Instance Segmentation for Unseen Objects in Auto-Store
Nov 08, 2023
In large-scale storehouses, precise instance masks are crucial for robotic bin picking but are challenging to obtain. Existing instance segmentation methods typically rely on a tedious process of scene collection, mask annotation, and network fine-tuning for every single Stock Keeping Unit (SKU). This paper presents SKU-Patch, a new patch-guided instance segmentation solution, leveraging only a few image patches for each incoming new SKU to predict accurate and robust masks, without tedious manual effort and model re-training. Technical-wise, we design a novel transformer-based network with (i) a patch-image correlation encoder to capture multi-level image features calibrated by patch information and (ii) a patch-aware transformer decoder with parallel task heads to generate instance masks. Extensive experiments on four storehouse benchmarks manifest that SKU-Patch is able to achieve the best performance over the state-of-the-art methods. Also, SKU-Patch yields an average of nearly 100% grasping success rate on more than 50 unseen SKUs in a robot-aided auto-store logistic pipeline, showing its effectiveness and practicality.
GNeSF: Generalizable Neural Semantic Fields
Oct 26, 20233D scene segmentation based on neural implicit representation has emerged recently with the advantage of training only on 2D supervision. However, existing approaches still requires expensive per-scene optimization that prohibits generalization to novel scenes during inference. To circumvent this problem, we introduce a generalizable 3D segmentation framework based on implicit representation. Specifically, our framework takes in multi-view image features and semantic maps as the inputs instead of only spatial information to avoid overfitting to scene-specific geometric and semantic information. We propose a novel soft voting mechanism to aggregate the 2D semantic information from different views for each 3D point. In addition to the image features, view difference information is also encoded in our framework to predict the voting scores. Intuitively, this allows the semantic information from nearby views to contribute more compared to distant ones. Furthermore, a visibility module is also designed to detect and filter out detrimental information from occluded views. Due to the generalizability of our proposed method, we can synthesize semantic maps or conduct 3D semantic segmentation for novel scenes with solely 2D semantic supervision. Experimental results show that our approach achieves comparable performance with scene-specific approaches. More importantly, our approach can even outperform existing strong supervision-based approaches with only 2D annotations. Our source code is available at: https://github.com/HLinChen/GNeSF.
Retrieval-Based Reconstruction For Time-series Contrastive Learning
Nov 01, 2023The success of self-supervised contrastive learning hinges on identifying positive data pairs that, when pushed together in embedding space, encode useful information for subsequent downstream tasks. However, in time-series, this is challenging because creating positive pairs via augmentations may break the original semantic meaning. We hypothesize that if we can retrieve information from one subsequence to successfully reconstruct another subsequence, then they should form a positive pair. Harnessing this intuition, we introduce our novel approach: REtrieval-BAsed Reconstruction (REBAR) contrastive learning. First, we utilize a convolutional cross-attention architecture to calculate the REBAR error between two different time-series. Then, through validation experiments, we show that the REBAR error is a predictor of mutual class membership, justifying its usage as a positive/negative labeler. Finally, once integrated into a contrastive learning framework, our REBAR method can learn an embedding that achieves state-of-the-art performance on downstream tasks across various modalities.
Weakly-supervised Deep Cognate Detection Framework for Low-Resourced Languages Using Morphological Knowledge of Closely-Related Languages
Nov 09, 2023Exploiting cognates for transfer learning in under-resourced languages is an exciting opportunity for language understanding tasks, including unsupervised machine translation, named entity recognition and information retrieval. Previous approaches mainly focused on supervised cognate detection tasks based on orthographic, phonetic or state-of-the-art contextual language models, which under-perform for most under-resourced languages. This paper proposes a novel language-agnostic weakly-supervised deep cognate detection framework for under-resourced languages using morphological knowledge from closely related languages. We train an encoder to gain morphological knowledge of a language and transfer the knowledge to perform unsupervised and weakly-supervised cognate detection tasks with and without the pivot language for the closely-related languages. While unsupervised, it overcomes the need for hand-crafted annotation of cognates. We performed experiments on different published cognate detection datasets across language families and observed not only significant improvement over the state-of-the-art but also our method outperformed the state-of-the-art supervised and unsupervised methods. Our model can be extended to a wide range of languages from any language family as it overcomes the requirement of the annotation of the cognate pairs for training. The code and dataset building scripts can be found at https://github.com/koustavagoswami/Weakly_supervised-Cognate_Detection
Dirichlet Energy Enhancement of Graph Neural Networks by Framelet Augmentation
Nov 09, 2023Graph convolutions have been a pivotal element in learning graph representations. However, recursively aggregating neighboring information with graph convolutions leads to indistinguishable node features in deep layers, which is known as the over-smoothing issue. The performance of graph neural networks decays fast as the number of stacked layers increases, and the Dirichlet energy associated with the graph decreases to zero as well. In this work, we introduce a framelet system into the analysis of Dirichlet energy and take a multi-scale perspective to leverage the Dirichlet energy and alleviate the over-smoothing issue. Specifically, we develop a Framelet Augmentation strategy by adjusting the update rules with positive and negative increments for low-pass and high-passes respectively. Based on that, we design the Energy Enhanced Convolution (EEConv), which is an effective and practical operation that is proved to strictly enhance Dirichlet energy. From a message-passing perspective, EEConv inherits multi-hop aggregation property from the framelet transform and takes into account all hops in the multi-scale representation, which benefits the node classification tasks over heterophilous graphs. Experiments show that deep GNNs with EEConv achieve state-of-the-art performance over various node classification datasets, especially for heterophilous graphs, while also lifting the Dirichlet energy as the network goes deeper.
Spatial Attention-based Distribution Integration Network for Human Pose Estimation
Nov 09, 2023In recent years, human pose estimation has made significant progress through the implementation of deep learning techniques. However, these techniques still face limitations when confronted with challenging scenarios, including occlusion, diverse appearances, variations in illumination, and overlap. To cope with such drawbacks, we present the Spatial Attention-based Distribution Integration Network (SADI-NET) to improve the accuracy of localization in such situations. Our network consists of three efficient models: the receptive fortified module (RFM), spatial fusion module (SFM), and distribution learning module (DLM). Building upon the classic HourglassNet architecture, we replace the basic block with our proposed RFM. The RFM incorporates a dilated residual block and attention mechanism to expand receptive fields while enhancing sensitivity to spatial information. In addition, the SFM incorporates multi-scale characteristics by employing both global and local attention mechanisms. Furthermore, the DLM, inspired by residual log-likelihood estimation (RLE), reconfigures a predicted heatmap using a trainable distribution weight. For the purpose of determining the efficacy of our model, we conducted extensive experiments on the MPII and LSP benchmarks. Particularly, our model obtained a remarkable $92.10\%$ percent accuracy on the MPII test dataset, demonstrating significant improvements over existing models and establishing state-of-the-art performance.
ChineseWebText: Large-scale High-quality Chinese Web Text Extracted with Effective Evaluation Model
Nov 10, 2023During the development of large language models (LLMs), the scale and quality of the pre-training data play a crucial role in shaping LLMs' capabilities. To accelerate the research of LLMs, several large-scale datasets, such as C4 [1], Pile [2], RefinedWeb [3] and WanJuan [4], have been released to the public. However, most of the released corpus focus mainly on English, and there is still lack of complete tool-chain for extracting clean texts from web data. Furthermore, fine-grained information of the corpus, e.g. the quality of each text, is missing. To address these challenges, we propose in this paper a new complete tool-chain EvalWeb to extract Chinese clean texts from noisy web data. First, similar to previous work, manually crafted rules are employed to discard explicit noisy texts from the raw crawled web contents. Second, a well-designed evaluation model is leveraged to assess the remaining relatively clean data, and each text is assigned a specific quality score. Finally, we can easily utilize an appropriate threshold to select the high-quality pre-training data for Chinese. Using our proposed approach, we release the largest and latest large-scale high-quality Chinese web text ChineseWebText, which consists of 1.42 TB and each text is associated with a quality score, facilitating the LLM researchers to choose the data according to the desired quality thresholds. We also release a much cleaner subset of 600 GB Chinese data with the quality exceeding 90%.
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 10, 2023
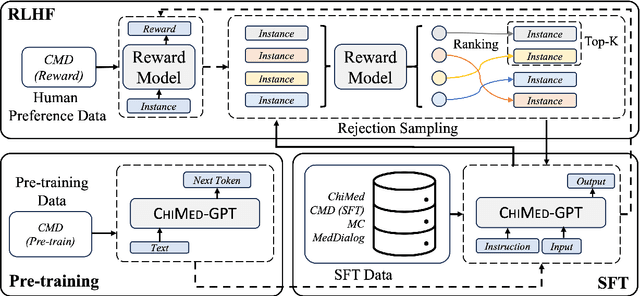

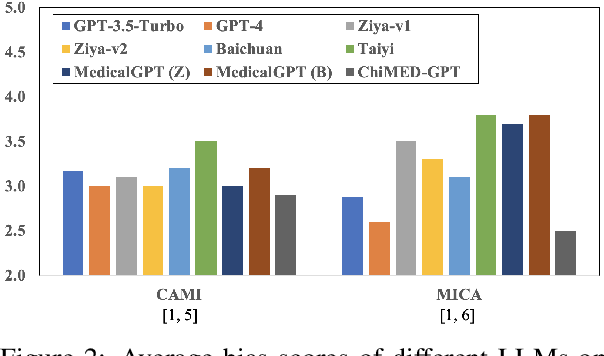
Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.
Exploring Fine-tuning ChatGPT for News Recommendation
Nov 10, 2023
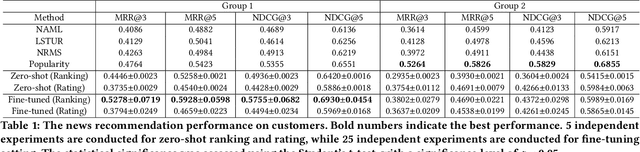
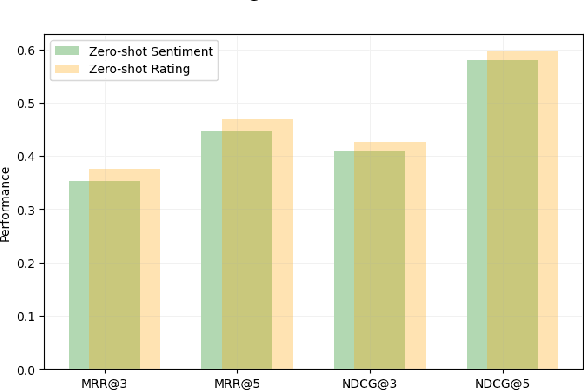
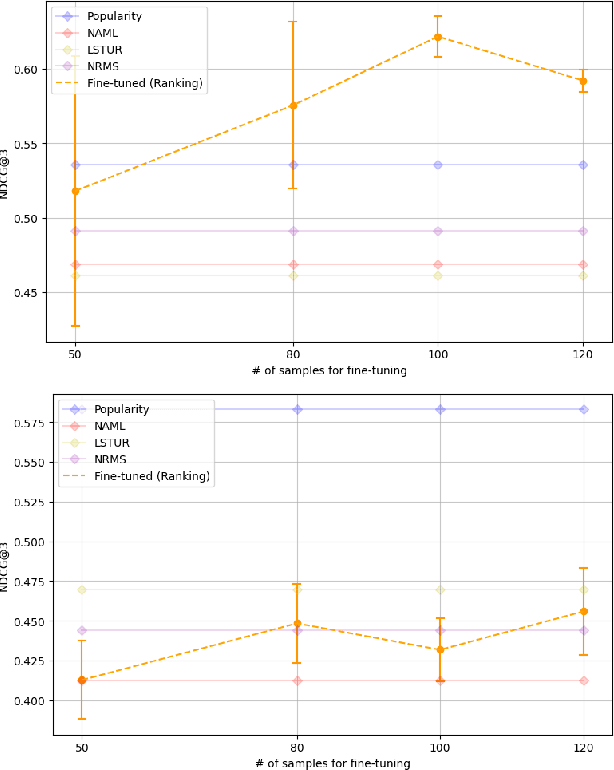
News recommendation systems (RS) play a pivotal role in the current digital age, shaping how individuals access and engage with information. The fusion of natural language processing (NLP) and RS, spurred by the rise of large language models such as the GPT and T5 series, blurs the boundaries between these domains, making a tendency to treat RS as a language task. ChatGPT, renowned for its user-friendly interface and increasing popularity, has become a prominent choice for a wide range of NLP tasks. While previous studies have explored ChatGPT on recommendation tasks, this study breaks new ground by investigating its fine-tuning capability, particularly within the news domain. In this study, we design two distinct prompts: one designed to treat news RS as the ranking task and another tailored for the rating task. We evaluate ChatGPT's performance in news recommendation by eliciting direct responses through the formulation of these two tasks. More importantly, we unravel the pivotal role of fine-tuning data quality in enhancing ChatGPT's personalized recommendation capabilities, and illustrates its potential in addressing the longstanding challenge of the "cold item" problem in RS. Our experiments, conducted using the Microsoft News dataset (MIND), reveal significant improvements achieved by ChatGPT after fine-tuning, especially in scenarios where a user's topic interests remain consistent, treating news RS as a ranking task. This study illuminates the transformative potential of fine-tuning ChatGPT as a means to advance news RS, offering more effective news consumption experiences.
Learned layered coding for Successive Refinement in the Wyner-Ziv Problem
Nov 06, 2023We propose a data-driven approach to explicitly learn the progressive encoding of a continuous source, which is successively decoded with increasing levels of quality and with the aid of correlated side information. This setup refers to the successive refinement of the Wyner-Ziv coding problem. Assuming ideal Slepian-Wolf coding, our approach employs recurrent neural networks (RNNs) to learn layered encoders and decoders for the quadratic Gaussian case. The models are trained by minimizing a variational bound on the rate-distortion function of the successively refined Wyner-Ziv coding problem. We demonstrate that RNNs can explicitly retrieve layered binning solutions akin to scalable nested quantization. Moreover, the rate-distortion performance of the scheme is on par with the corresponding monolithic Wyner-Ziv coding approach and is close to the rate-distortion bound.