 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning
Jun 15, 2026Human interventions provide crucial corrective signals for post-training Vision-Language-Action (VLA) models. However, enabling seamless humanoid interventions is a formidable systems challenge due to complex whole-body kinematics and dexterous-hand control. Consequently, the collected intervention trajectories are often suboptimal, and methods that rely on human interventions as expert supervision can absorb hesitant, inefficient, or even erroneous behaviors. To address both the system and algorithmic challenges, we propose ROVE, a reinforcement learning framework for humanoid VLA post-training with imperfect human interventions. First, ROVE introduces a human-in-the-loop pipeline capable of collecting deployment and intervention data for humanoid manipulation. Second, it utilizes Optimistic Value Estimation (OVE) to prioritize high-value behaviors from mixed-quality trajectories. To further robustify value estimation, we incorporate cross-embodiment human experience videos to provide rich supervision for long-tailed failure and recovery modes. The resulting critic yields informative advantage signals, steering the VLA actor to focus on high-value behaviors rather than indiscriminately imitating all actions. On challenging real-world contact-rich and fine-grained humanoid manipulation tasks, ROVE outperforms experience-learning baselines and consistently improves across multiple rollout-intervention iterations.
From Passive Observer to Active Critic: Reinforcement Learning Elicits Process Reasoning for Robotic Manipulation
Mar 16, 2026Accurate process supervision remains a critical challenge for long-horizon robotic manipulation. A primary bottleneck is that current video MLLMs, trained primarily under a Supervised Fine-Tuning (SFT) paradigm, function as passive "Observers" that recognize ongoing events rather than evaluating the current state relative to the final task goal. In this paper, we introduce PRIMO R1 (Process Reasoning Induced Monitoring), a 7B framework that transforms video MLLMs into active "Critics". We leverage outcome-based Reinforcement Learning to incentivize explicit Chain-of-Thought generation for progress estimation. Furthermore, our architecture constructs a structured temporal input by explicitly anchoring the video sequence between initial and current state images. Supported by the proposed PRIMO Dataset and Benchmark, extensive experiments across diverse in-domain environments and out-of-domain real-world humanoid scenarios demonstrate that PRIMO R1 achieves state-of-the-art performance. Quantitatively, our 7B model achieves a 50% reduction in the mean absolute error of specialized reasoning baselines, demonstrating significant relative accuracy improvements over 72B-scale general MLLMs. Furthermore, PRIMO R1 exhibits strong zero-shot generalization on difficult failure detection tasks. We establish state-of-the-art performance on RoboFail benchmark with 67.0% accuracy, surpassing closed-source models like OpenAI o1 by 6.0%.
Incentivizing Multimodal Reasoning in Large Models for Direct Robot Manipulation
May 19, 2025Recent Large Multimodal Models have demonstrated remarkable reasoning capabilities, especially in solving complex mathematical problems and realizing accurate spatial perception. Our key insight is that these emerging abilities can naturally extend to robotic manipulation by enabling LMMs to directly infer the next goal in language via reasoning, rather than relying on a separate action head. However, this paradigm meets two main challenges: i) How to make LMMs understand the spatial action space, and ii) How to fully exploit the reasoning capacity of LMMs in solving these tasks. To tackle the former challenge, we propose a novel task formulation, which inputs the current states of object parts and the gripper, and reformulates rotation by a new axis representation instead of traditional Euler angles. This representation is more compatible with spatial reasoning and easier to interpret within a unified language space. For the latter challenge, we design a pipeline to utilize cutting-edge LMMs to generate a small but high-quality reasoning dataset of multi-round dialogues that successfully solve manipulation tasks for supervised fine-tuning. Then, we perform reinforcement learning by trial-and-error interactions in simulation to further enhance the model's reasoning abilities for robotic manipulation. Our resulting reasoning model built upon a 7B backbone, named ReasonManip, demonstrates three notable advantages driven by its system-2 level reasoning capabilities: i) exceptional generalizability to out-of-distribution environments, objects, and tasks; ii) inherent sim-to-real transfer ability enabled by the unified language representation shared across domains; iii) transparent interpretability connecting high-level reasoning and low-level control. Extensive experiments demonstrate the effectiveness of the proposed paradigm and its potential to advance LMM-driven robotic manipulation.
Embodiment-Agnostic Action Planning via Object-Part Scene Flow
Sep 16, 2024



Observing that the key for robotic action planning is to understand the target-object motion when its associated part is manipulated by the end effector, we propose to generate the 3D object-part scene flow and extract its transformations to solve the action trajectories for diverse embodiments. The advantage of our approach is that it derives the robot action explicitly from object motion prediction, yielding a more robust policy by understanding the object motions. Also, beyond policies trained on embodiment-centric data, our method is embodiment-agnostic, generalizable across diverse embodiments, and being able to learn from human demonstrations. Our method comprises three components: an object-part predictor to locate the part for the end effector to manipulate, an RGBD video generator to predict future RGBD videos, and a trajectory planner to extract embodiment-agnostic transformation sequences and solve the trajectory for diverse embodiments. Trained on videos even without trajectory data, our method still outperforms existing works significantly by 27.7% and 26.2% on the prevailing virtual environments MetaWorld and Franka-Kitchen, respectively. Furthermore, we conducted real-world experiments, showing that our policy, trained only with human demonstration, can be deployed to various embodiments.
SKU-Patch: Towards Efficient Instance Segmentation for Unseen Objects in Auto-Store
Nov 08, 2023



In large-scale storehouses, precise instance masks are crucial for robotic bin picking but are challenging to obtain. Existing instance segmentation methods typically rely on a tedious process of scene collection, mask annotation, and network fine-tuning for every single Stock Keeping Unit (SKU). This paper presents SKU-Patch, a new patch-guided instance segmentation solution, leveraging only a few image patches for each incoming new SKU to predict accurate and robust masks, without tedious manual effort and model re-training. Technical-wise, we design a novel transformer-based network with (i) a patch-image correlation encoder to capture multi-level image features calibrated by patch information and (ii) a patch-aware transformer decoder with parallel task heads to generate instance masks. Extensive experiments on four storehouse benchmarks manifest that SKU-Patch is able to achieve the best performance over the state-of-the-art methods. Also, SKU-Patch yields an average of nearly 100% grasping success rate on more than 50 unseen SKUs in a robot-aided auto-store logistic pipeline, showing its effectiveness and practicality.
SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud
Apr 20, 2021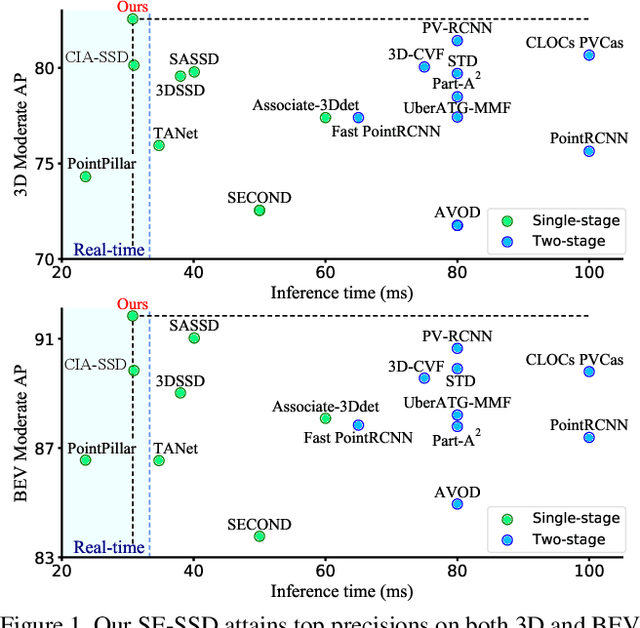
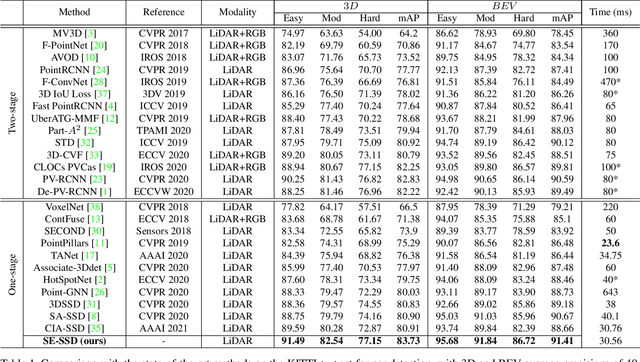
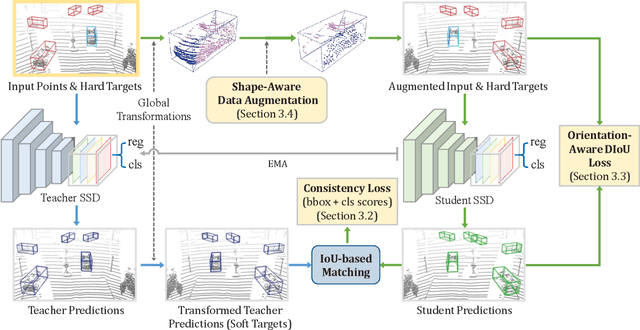
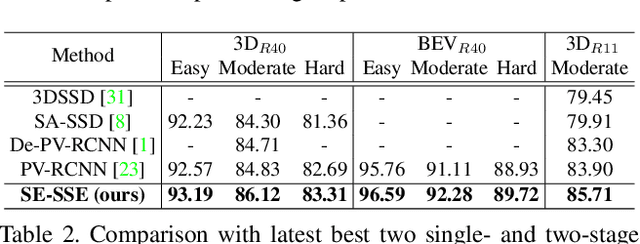
We present Self-Ensembling Single-Stage object Detector (SE-SSD) for accurate and efficient 3D object detection in outdoor point clouds. Our key focus is on exploiting both soft and hard targets with our formulated constraints to jointly optimize the model, without introducing extra computation in the inference. Specifically, SE-SSD contains a pair of teacher and student SSDs, in which we design an effective IoU-based matching strategy to filter soft targets from the teacher and formulate a consistency loss to align student predictions with them. Also, to maximize the distilled knowledge for ensembling the teacher, we design a new augmentation scheme to produce shape-aware augmented samples to train the student, aiming to encourage it to infer complete object shapes. Lastly, to better exploit hard targets, we design an ODIoU loss to supervise the student with constraints on the predicted box centers and orientations. Our SE-SSD attains top performance compared with all prior published works. Also, it attains top precisions for car detection in the KITTI benchmark (ranked 1st and 2nd on the BEV and 3D leaderboards, respectively) with an ultra-high inference speed. The code is available at https://github.com/Vegeta2020/SE-SSD.
CIA-SSD: Confident IoU-Aware Single-Stage Object Detector From Point Cloud
Dec 05, 2020
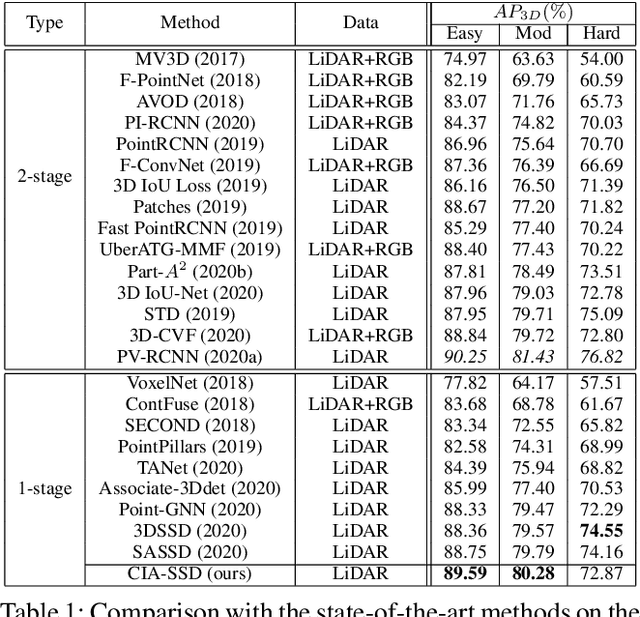
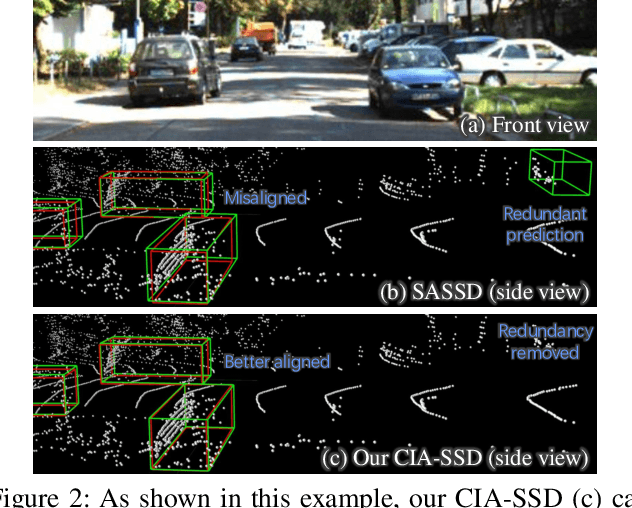
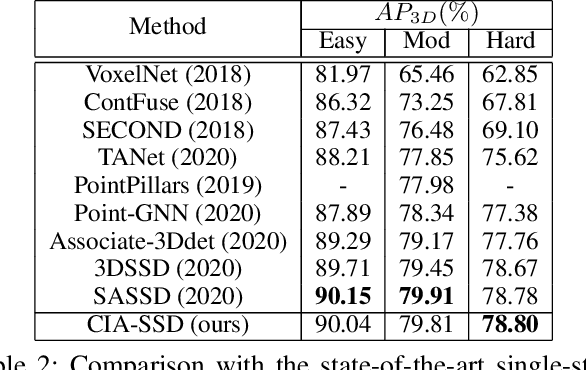
Existing single-stage detectors for locating objects in point clouds often treat object localization and category classification as separate tasks, so the localization accuracy and classification confidence may not well align. To address this issue, we present a new single-stage detector named the Confident IoU-Aware Single-Stage object Detector (CIA-SSD). First, we design the lightweight Spatial-Semantic Feature Aggregation module to adaptively fuse high-level abstract semantic features and low-level spatial features for accurate predictions of bounding boxes and classification confidence. Also, the predicted confidence is further rectified with our designed IoU-aware confidence rectification module to make the confidence more consistent with the localization accuracy. Based on the rectified confidence, we further formulate the Distance-variant IoU-weighted NMS to obtain smoother regressions and avoid redundant predictions. We experiment CIA-SSD on 3D car detection in the KITTI test set and show that it attains top performance in terms of the official ranking metric (moderate AP 80.28%) and above 32 FPS inference speed, outperforming all prior single-stage detectors. The code is available at https://github.com/Vegeta2020/CIA-SSD.