 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scaling Limits of the Wasserstein information matrix on Gaussian Mixture Models
Sep 22, 2023
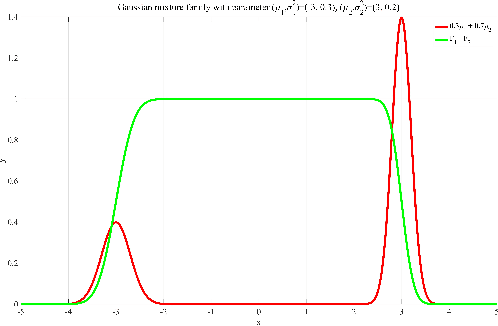
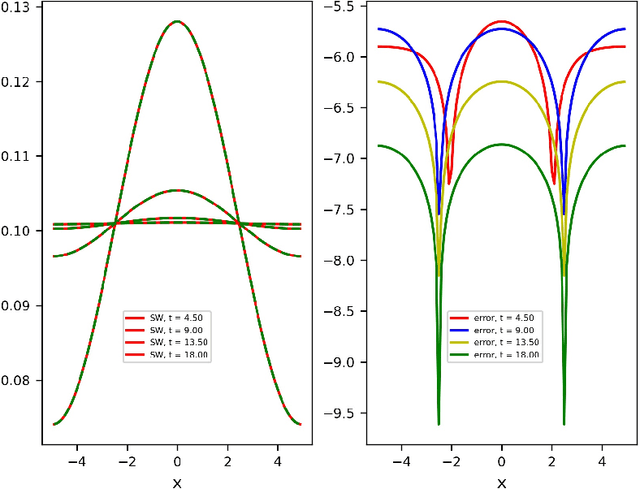
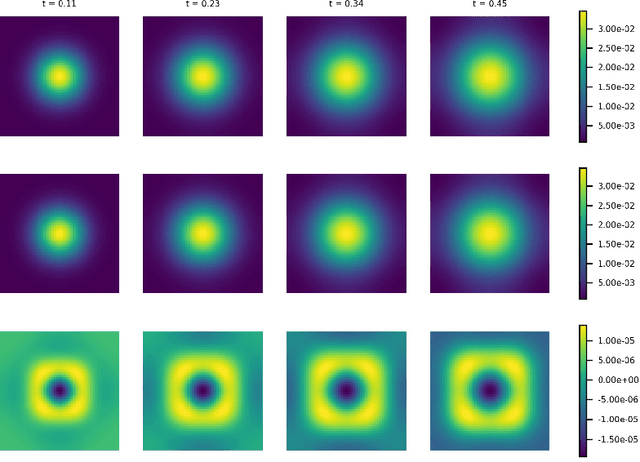
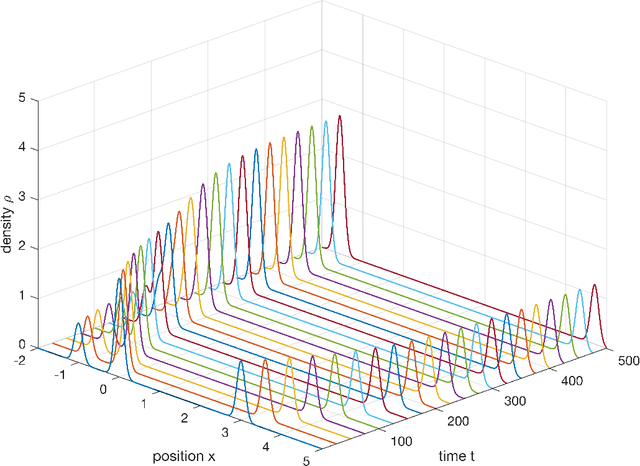
We consider the Wasserstein metric on the Gaussian mixture models (GMMs), which is defined as the pullback of the full Wasserstein metric on the space of smooth probability distributions with finite second moment. It derives a class of Wasserstein metrics on probability simplices over one-dimensional bounded homogeneous lattices via a scaling limit of the Wasserstein metric on GMMs. Specifically, for a sequence of GMMs whose variances tend to zero, we prove that the limit of the Wasserstein metric exists after certain renormalization. Generalizations of this metric in general GMMs are established, including inhomogeneous lattice models whose lattice gaps are not the same, extended GMMs whose mean parameters of Gaussian components can also change, and the second-order metric containing high-order information of the scaling limit. We further study the Wasserstein gradient flows on GMMs for three typical functionals: potential, internal, and interaction energies. Numerical examples demonstrate the effectiveness of the proposed GMM models for approximating Wasserstein gradient flows.
Long-Range Neural Atom Learning for Molecular Graphs
Nov 02, 2023Graph Neural Networks (GNNs) have been widely adopted for drug discovery with molecular graphs. Nevertheless, current GNNs are mainly good at leveraging short-range interactions (SRI) but struggle to capture long-range interactions (LRI), both of which are crucial for determining molecular properties. To tackle this issue, we propose a method that implicitly projects all original atoms into a few Neural Atoms, which abstracts the collective information of atomic groups within a molecule. Specifically, we explicitly exchange the information among neural atoms and project them back to the atoms' representations as an enhancement. With this mechanism, neural atoms establish the communication channels among distant nodes, effectively reducing the interaction scope of arbitrary node pairs into a single hop. To provide an inspection of our method from a physical perspective, we reveal its connection with the traditional LRI calculation method, Ewald Summation. We conduct extensive experiments on three long-range graph benchmarks, covering both graph-level and link-level tasks on molecular graphs. We empirically justify that our method can be equipped with an arbitrary GNN and help to capture LRI.
Distance-Based Propagation for Efficient Knowledge Graph Reasoning
Nov 02, 2023Knowledge graph completion (KGC) aims to predict unseen edges in knowledge graphs (KGs), resulting in the discovery of new facts. A new class of methods have been proposed to tackle this problem by aggregating path information. These methods have shown tremendous ability in the task of KGC. However they are plagued by efficiency issues. Though there are a few recent attempts to address this through learnable path pruning, they often sacrifice the performance to gain efficiency. In this work, we identify two intrinsic limitations of these methods that affect the efficiency and representation quality. To address the limitations, we introduce a new method, TAGNet, which is able to efficiently propagate information. This is achieved by only aggregating paths in a fixed window for each source-target pair. We demonstrate that the complexity of TAGNet is independent of the number of layers. Extensive experiments demonstrate that TAGNet can cut down on the number of propagated messages by as much as 90% while achieving competitive performance on multiple KG datasets. The code is available at https://github.com/HarryShomer/TAGNet.
Nonparametric modeling of the composite effect of multiple nutrients on blood glucose dynamics
Nov 06, 2023In biomedical applications it is often necessary to estimate a physiological response to a treatment consisting of multiple components, and learn the separate effects of the components in addition to the joint effect. Here, we extend existing probabilistic nonparametric approaches to explicitly address this problem. We also develop a new convolution-based model for composite treatment-response curves that is more biologically interpretable. We validate our models by estimating the impact of carbohydrate and fat in meals on blood glucose. By differentiating treatment components, incorporating their dosages, and sharing statistical information across patients via a hierarchical multi-output Gaussian process, our method improves prediction accuracy over existing approaches, and allows us to interpret the different effects of carbohydrates and fat on the overall glucose response.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
NEURO HAND: A weakly supervised Hierarchical Attention Network for neuroimaging abnormality Detection
Nov 06, 2023Clinical neuroimaging data is naturally hierarchical. Different magnetic resonance imaging (MRI) sequences within a series, different slices covering the head, and different regions within each slice all confer different information. In this work we present a hierarchical attention network for abnormality detection using MRI scans obtained in a clinical hospital setting. The proposed network is suitable for non-volumetric data (i.e. stacks of high-resolution MRI slices), and can be trained from binary examination-level labels. We show that this hierarchical approach leads to improved classification, while providing interpretability through either coarse inter- and intra-slice abnormality localisation, or giving importance scores for different slices and sequences, making our model suitable for use as an automated triaging system in radiology departments.
Enhancing Traffic Object Detection in Variable Illumination with RGB-Event Fusion
Nov 01, 2023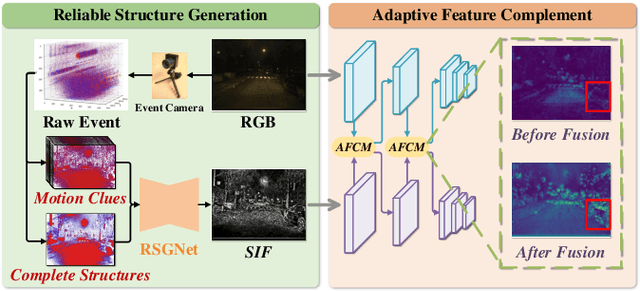

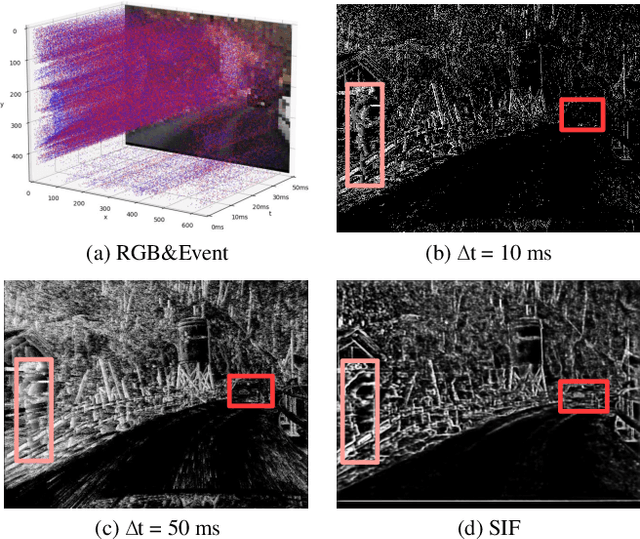
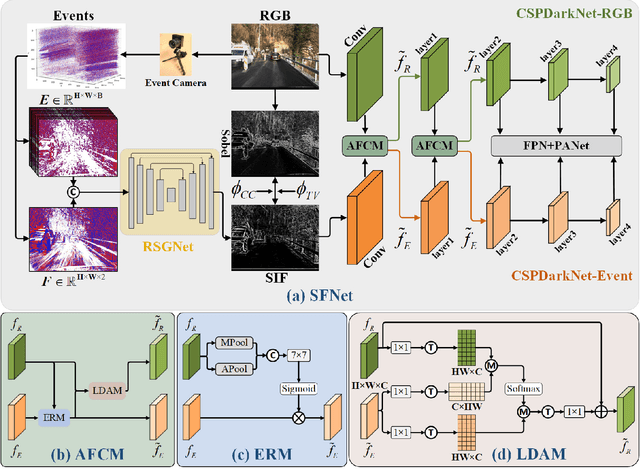
Traffic object detection under variable illumination is challenging due to the information loss caused by the limited dynamic range of conventional frame-based cameras. To address this issue, we introduce bio-inspired event cameras and propose a novel Structure-aware Fusion Network (SFNet) that extracts sharp and complete object structures from the event stream to compensate for the lost information in images through cross-modality fusion, enabling the network to obtain illumination-robust representations for traffic object detection. Specifically, to mitigate the sparsity or blurriness issues arising from diverse motion states of traffic objects in fixed-interval event sampling methods, we propose the Reliable Structure Generation Network (RSGNet) to generate Speed Invariant Frames (SIF), ensuring the integrity and sharpness of object structures. Next, we design a novel Adaptive Feature Complement Module (AFCM) which guides the adaptive fusion of two modality features to compensate for the information loss in the images by perceiving the global lightness distribution of the images, thereby generating illumination-robust representations. Finally, considering the lack of large-scale and high-quality annotations in the existing event-based object detection datasets, we build a DSEC-Det dataset, which consists of 53 sequences with 63,931 images and more than 208,000 labels for 8 classes. Extensive experimental results demonstrate that our proposed SFNet can overcome the perceptual boundaries of conventional cameras and outperform the frame-based method by 8.0% in mAP50 and 5.9% in mAP50:95. Our code and dataset will be available at https://github.com/YN-Yang/SFNet.
Bandit Pareto Set Identification: the Fixed Budget Setting
Nov 07, 2023We study a multi-objective pure exploration problem in a multi-armed bandit model. Each arm is associated to an unknown multi-variate distribution and the goal is to identify the distributions whose mean is not uniformly worse than that of another distribution: the Pareto optimal set. We propose and analyze the first algorithms for the \emph{fixed budget} Pareto Set Identification task. We propose Empirical Gap Elimination, a family of algorithms combining a careful estimation of the ``hardness to classify'' each arm in or out of the Pareto set with a generic elimination scheme. We prove that two particular instances, EGE-SR and EGE-SH, have a probability of error that decays exponentially fast with the budget, with an exponent supported by an information theoretic lower-bound. We complement these findings with an empirical study using real-world and synthetic datasets, which showcase the good performance of our algorithms.
SKU-Patch: Towards Efficient Instance Segmentation for Unseen Objects in Auto-Store
Nov 08, 2023In large-scale storehouses, precise instance masks are crucial for robotic bin picking but are challenging to obtain. Existing instance segmentation methods typically rely on a tedious process of scene collection, mask annotation, and network fine-tuning for every single Stock Keeping Unit (SKU). This paper presents SKU-Patch, a new patch-guided instance segmentation solution, leveraging only a few image patches for each incoming new SKU to predict accurate and robust masks, without tedious manual effort and model re-training. Technical-wise, we design a novel transformer-based network with (i) a patch-image correlation encoder to capture multi-level image features calibrated by patch information and (ii) a patch-aware transformer decoder with parallel task heads to generate instance masks. Extensive experiments on four storehouse benchmarks manifest that SKU-Patch is able to achieve the best performance over the state-of-the-art methods. Also, SKU-Patch yields an average of nearly 100% grasping success rate on more than 50 unseen SKUs in a robot-aided auto-store logistic pipeline, showing its effectiveness and practicality.
Communication Efficient and Privacy-Preserving Federated Learning Based on Evolution Strategies
Nov 05, 2023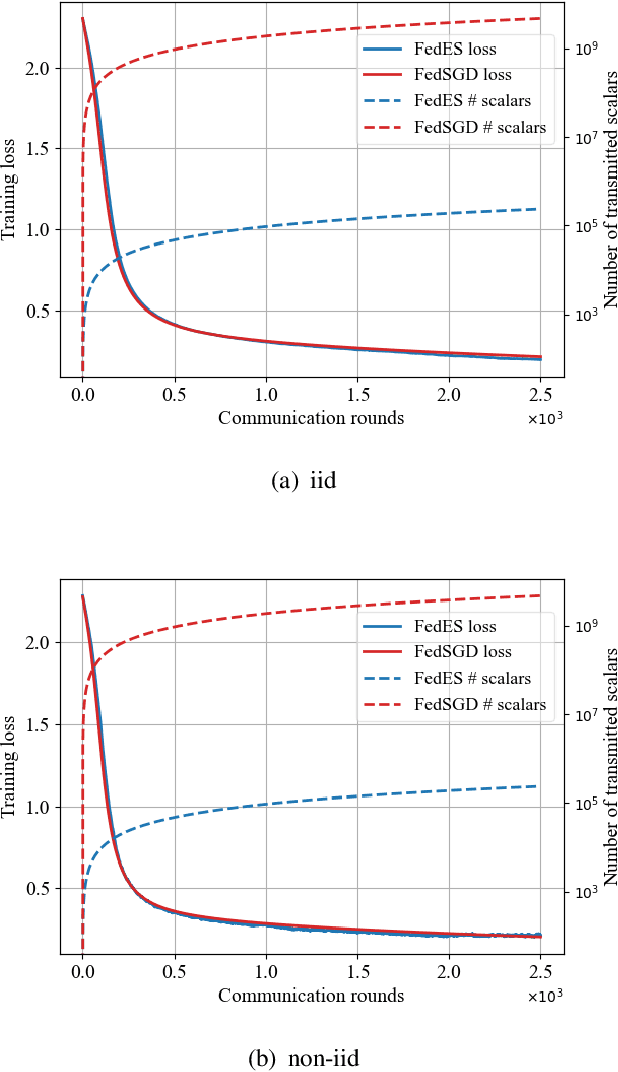
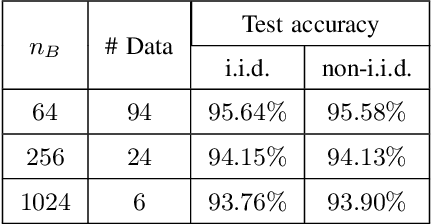
Federated learning (FL) is an emerging paradigm for training deep neural networks (DNNs) in distributed manners. Current FL approaches all suffer from high communication overhead and information leakage. In this work, we present a federated learning algorithm based on evolution strategies (FedES), a zeroth-order training method. Instead of transmitting model parameters, FedES only communicates loss values, and thus has very low communication overhead. Moreover, a third party is unable to estimate gradients without knowing the pre-shared seed, which protects data privacy. Experimental results demonstrate FedES can achieve the above benefits while keeping convergence performance the same as that with back propagation methods.