 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich-Observation Reinforcement Learning with Continuous Latent Dynamics
May 29, 2024



Sample-efficiency and reliability remain major bottlenecks toward wide adoption of reinforcement learning algorithms in continuous settings with high-dimensional perceptual inputs. Toward addressing these challenges, we introduce a new theoretical framework, RichCLD (Rich-Observation RL with Continuous Latent Dynamics), in which the agent performs control based on high-dimensional observations, but the environment is governed by low-dimensional latent states and Lipschitz continuous dynamics. Our main contribution is a new algorithm for this setting that is provably statistically and computationally efficient. The core of our algorithm is a new representation learning objective; we show that prior representation learning schemes tailored to discrete dynamics do not naturally extend to the continuous setting. Our new objective is amenable to practical implementation, and empirically, we find that it compares favorably to prior schemes in a standard evaluation protocol. We further provide several insights into the statistical complexity of the RichCLD framework, in particular proving that certain notions of Lipschitzness that admit sample-efficient learning in the absence of rich observations are insufficient in the rich-observation setting.
Generalizing Multi-Step Inverse Models for Representation Learning to Finite-Memory POMDPs
Apr 22, 2024Discovering an informative, or agent-centric, state representation that encodes only the relevant information while discarding the irrelevant is a key challenge towards scaling reinforcement learning algorithms and efficiently applying them to downstream tasks. Prior works studied this problem in high-dimensional Markovian environments, when the current observation may be a complex object but is sufficient to decode the informative state. In this work, we consider the problem of discovering the agent-centric state in the more challenging high-dimensional non-Markovian setting, when the state can be decoded from a sequence of past observations. We establish that generalized inverse models can be adapted for learning agent-centric state representation for this task. Our results include asymptotic theory in the deterministic dynamics setting as well as counter-examples for alternative intuitive algorithms. We complement these findings with a thorough empirical study on the agent-centric state discovery abilities of the different alternatives we put forward. Particularly notable is our analysis of past actions, where we show that these can be a double-edged sword: making the algorithms more successful when used correctly and causing dramatic failure when used incorrectly.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
Anytime-valid off-policy inference for contextual bandits
Oct 19, 2022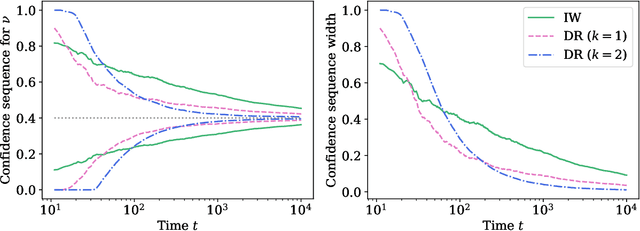

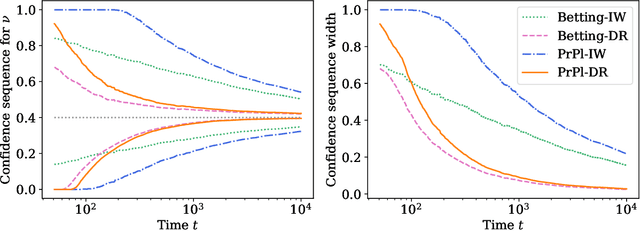

Contextual bandits are a modern staple tool for active sequential experimentation in the tech industry. They involve online learning algorithms that adaptively (over time) learn policies to map observed contexts $X_t$ to actions $A_t$ in an attempt to maximize stochastic rewards $R_t$. This adaptivity raises interesting but hard statistical inference questions, especially counterfactual ones: for example, it is often of interest to estimate the properties of a hypothetical policy that is different from the logging policy that was used to collect the data -- a problem known as "off-policy evaluation" (OPE). Using modern martingale techniques, we present a comprehensive framework for OPE inference that relax many unnecessary assumptions made in past work, significantly improving on them theoretically and empirically. Our methods remain valid in very general settings, and can be employed while the original experiment is still running (that is, not necessarily post-hoc), when the logging policy may be itself changing (due to learning), and even if the context distributions are drifting over time. More concretely, we derive confidence sequences for various functionals of interest in OPE. These include doubly robust ones for time-varying off-policy mean reward values, but also confidence bands for the entire CDF of the off-policy reward distribution. All of our methods (a) are valid at arbitrary stopping times (b) only make nonparametric assumptions, and (c) do not require known bounds on the maximal importance weights, and (d) adapt to the empirical variance of the reward and weight distributions. In summary, our methods enable anytime-valid off-policy inference using adaptively collected contextual bandit data.
Parameterized Exploration
Jul 13, 2019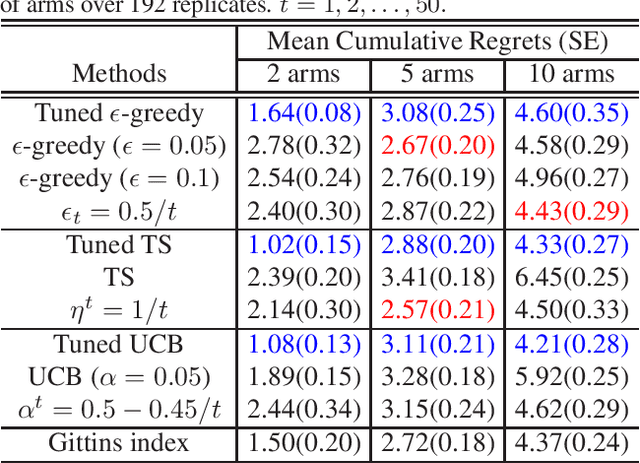
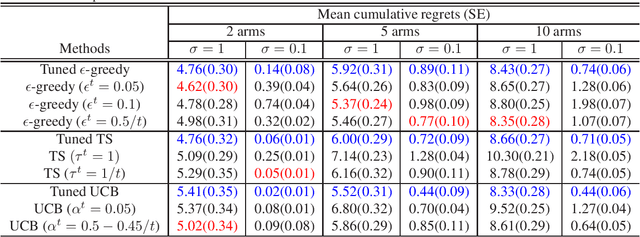

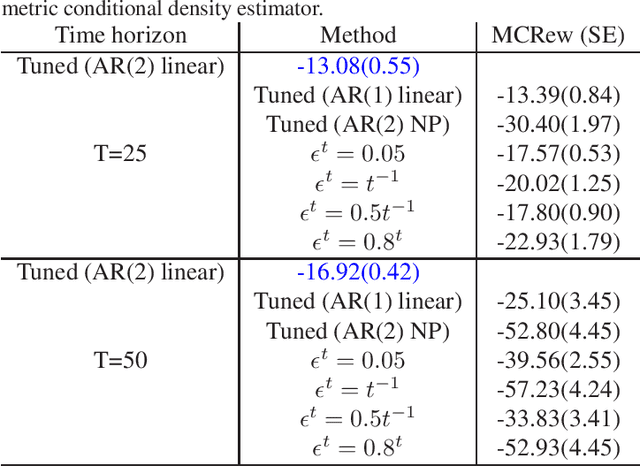
We introduce Parameterized Exploration (PE), a simple family of methods for model-based tuning of the exploration schedule in sequential decision problems. Unlike common heuristics for exploration, our method accounts for the time horizon of the decision problem as well as the agent's current state of knowledge of the dynamics of the decision problem. We show our method as applied to several common exploration techniques has superior performance relative to un-tuned counterparts in Bernoulli and Gaussian multi-armed bandits, contextual bandits, and a Markov decision process based on a mobile health (mHealth) study. We also examine the effects of the accuracy of the estimated dynamics model on the performance of PE.