 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Image Semantic Communication Model for Artificial Intelligent Internet of Things
Nov 08, 2023
With the rapid development of Artificial Intelligent Internet of Things (AIoT), the image data from AIoT devices has been witnessing the explosive increasing. In this paper, a novel deep image semantic communication model is proposed for the efficient image communication in AIoT. Particularly, at the transmitter side, a high-precision image semantic segmentation algorithm is proposed to extract the semantic information of the image to achieve significant compression of the image data. At the receiver side, a semantic image restoration algorithm based on Generative Adversarial Network (GAN) is proposed to convert the semantic image to a real scene image with detailed information. Simulation results demonstrate that the proposed image semantic communication model can improve the image compression ratio and recovery accuracy by 71.93% and 25.07% on average in comparison with WebP and CycleGAN, respectively. More importantly, our demo experiment shows that the proposed model reduces the total delay by 95.26% in the image communication, when comparing with the original image transmission.
What is Lost in Knowledge Distillation?
Nov 07, 2023Deep neural networks (DNNs) have improved NLP tasks significantly, but training and maintaining such networks could be costly. Model compression techniques, such as, knowledge distillation (KD), have been proposed to address the issue; however, the compression process could be lossy. Motivated by this, our work investigates how a distilled student model differs from its teacher, if the distillation process causes any information losses, and if the loss follows a specific pattern. Our experiments aim to shed light on the type of tasks might be less or more sensitive to KD by reporting data points on the contribution of different factors, such as the number of layers or attention heads. Results such as ours could be utilized when determining effective and efficient configurations to achieve optimal information transfers between larger (teacher) and smaller (student) models.
3D Pose Estimation of Tomato Peduncle Nodes using Deep Keypoint Detection and Point Cloud
Nov 08, 2023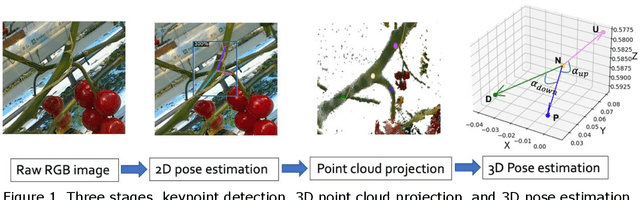
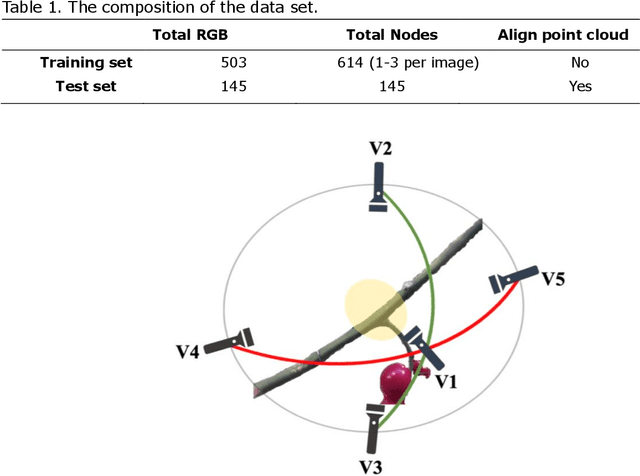


Greenhouse production of fruits and vegetables in developed countries is challenged by labor 12 scarcity and high labor costs. Robots offer a good solution for sustainable and cost-effective 13 production. Acquiring accurate spatial information about relevant plant parts is vital for 14 successful robot operation. Robot perception in greenhouses is challenging due to variations in 15 plant appearance, viewpoints, and illumination. This paper proposes a keypoint-detection-based 16 method using data from an RGB-D camera to estimate the 3D pose of peduncle nodes, which 17 provides essential information to harvest the tomato bunches. 18 19 Specifically, this paper proposes a method that detects four anatomical landmarks in the color 20 image and then integrates 3D point-cloud information to determine the 3D pose. A 21 comprehensive evaluation was conducted in a commercial greenhouse to gain insight into the 22 performance of different parts of the method. The results showed: (1) high accuracy in object 23 detection, achieving an Average Precision (AP) of AP@0.5=0.96; (2) an average Percentage of 24 Detected Joints (PDJ) of the keypoints of PhDJ@0.2=94.31%; and (3) 3D pose estimation 25 accuracy with mean absolute errors (MAE) of 11.38o and 9.93o for the relative upper and lower 26 angles between the peduncle and main stem, respectively. Furthermore, the capability to handle 27 variations in viewpoint was investigated, demonstrating the method was robust to view changes. 28 However, canonical and higher views resulted in slightly higher performance compared to other 29 views. Although tomato was selected as a use case, the proposed method is also applicable to 30 other greenhouse crops like pepper.
Chain of Thought with Explicit Evidence Reasoning for Few-shot Relation Extraction
Nov 15, 2023Few-shot relation extraction involves identifying the type of relationship between two specific entities within a text, using a limited number of annotated samples. A variety of solutions to this problem have emerged by applying meta-learning and neural graph techniques which typically necessitate a training process for adaptation. Recently, the strategy of in-context learning has been demonstrating notable results without the need of training. Few studies have already utilized in-context learning for zero-shot information extraction. Unfortunately, the evidence for inference is either not considered or implicitly modeled during the construction of chain-of-thought prompts. In this paper, we propose a novel approach for few-shot relation extraction using large language models, named CoT-ER, chain-of-thought with explicit evidence reasoning. In particular, CoT-ER first induces large language models to generate evidences using task-specific and concept-level knowledge. Then these evidences are explicitly incorporated into chain-of-thought prompting for relation extraction. Experimental results demonstrate that our CoT-ER approach (with 0% training data) achieves competitive performance compared to the fully-supervised (with 100% training data) state-of-the-art approach on the FewRel1.0 and FewRel2.0 datasets.
Causal Discovery Under Local Privacy
Nov 15, 2023Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
SparseSpikformer: A Co-Design Framework for Token and Weight Pruning in Spiking Transformer
Nov 15, 2023As the third-generation neural network, the Spiking Neural Network (SNN) has the advantages of low power consumption and high energy efficiency, making it suitable for implementation on edge devices. More recently, the most advanced SNN, Spikformer, combines the self-attention module from Transformer with SNN to achieve remarkable performance. However, it adopts larger channel dimensions in MLP layers, leading to an increased number of redundant model parameters. To effectively decrease the computational complexity and weight parameters of the model, we explore the Lottery Ticket Hypothesis (LTH) and discover a very sparse ($\ge$90%) subnetwork that achieves comparable performance to the original network. Furthermore, we also design a lightweight token selector module, which can remove unimportant background information from images based on the average spike firing rate of neurons, selecting only essential foreground image tokens to participate in attention calculation. Based on that, we present SparseSpikformer, a co-design framework aimed at achieving sparsity in Spikformer through token and weight pruning techniques. Experimental results demonstrate that our framework can significantly reduce 90% model parameters and cut down Giga Floating-Point Operations (GFLOPs) by 20% while maintaining the accuracy of the original model.
Beyond PCA: A Probabilistic Gram-Schmidt Approach to Feature Extraction
Nov 15, 2023Linear feature extraction at the presence of nonlinear dependencies among the data is a fundamental challenge in unsupervised learning. We propose using a Probabilistic Gram-Schmidt (PGS) type orthogonalization process in order to detect and map out redundant dimensions. Specifically, by applying the PGS process over any family of functions which presumably captures the nonlinear dependencies in the data, we construct a series of covariance matrices that can either be used to remove those dependencies from the principal components, or to identify new large-variance directions. In the former case, we prove that under certain assumptions the resulting algorithms detect and remove nonlinear dependencies whenever those dependencies lie in the linear span of the chosen function family. In the latter, we provide information-theoretic guarantees in terms of entropy reduction. Both proposed methods extract linear features from the data while removing nonlinear redundancies. We provide simulation results on synthetic and real-world datasets which show improved performance over PCA and state-of-the-art linear feature extraction algorithms, both in terms of variance maximization of the extracted features, and in terms of improved performance of classification algorithms.
A Spectral Diffusion Prior for Hyperspectral Image Super-Resolution
Nov 15, 2023Fusion-based hyperspectral image (HSI) super-resolution aims to produce a high-spatial-resolution HSI by fusing a low-spatial-resolution HSI and a high-spatial-resolution multispectral image. Such a HSI super-resolution process can be modeled as an inverse problem, where the prior knowledge is essential for obtaining the desired solution. Motivated by the success of diffusion models, we propose a novel spectral diffusion prior for fusion-based HSI super-resolution. Specifically, we first investigate the spectrum generation problem and design a spectral diffusion model to model the spectral data distribution. Then, in the framework of maximum a posteriori, we keep the transition information between every two neighboring states during the reverse generative process, and thereby embed the knowledge of trained spectral diffusion model into the fusion problem in the form of a regularization term. At last, we treat each generation step of the final optimization problem as its subproblem, and employ the Adam to solve these subproblems in a reverse sequence. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The code of the proposed approach will be available on https://github.com/liuofficial/SDP.
ActiveDC: Distribution Calibration for Active Finetuning
Nov 15, 2023The pretraining-finetuning paradigm has gained popularity in various computer vision tasks. In this paradigm, the emergence of active finetuning arises due to the abundance of large-scale data and costly annotation requirements. Active finetuning involves selecting a subset of data from an unlabeled pool for annotation, facilitating subsequent finetuning. However, the use of a limited number of training samples can lead to a biased distribution, potentially resulting in model overfitting. In this paper, we propose a new method called ActiveDC for the active finetuning tasks. Firstly, we select samples for annotation by optimizing the distribution similarity between the subset to be selected and the entire unlabeled pool in continuous space. Secondly, we calibrate the distribution of the selected samples by exploiting implicit category information in the unlabeled pool. The feature visualization provides an intuitive sense of the effectiveness of our approach to distribution calibration. We conducted extensive experiments on three image classification datasets with different sampling ratios. The results indicate that ActiveDC consistently outperforms the baseline performance in all image classification tasks. The improvement is particularly significant when the sampling ratio is low, with performance gains of up to 10%. Our code will be released.
How ChatGPT is Solving Vulnerability Management Problem
Nov 11, 2023Recently, ChatGPT has attracted great attention from the code analysis domain. Prior works show that ChatGPT has the capabilities of processing foundational code analysis tasks, such as abstract syntax tree generation, which indicates the potential of using ChatGPT to comprehend code syntax and static behaviors. However, it is unclear whether ChatGPT can complete more complicated real-world vulnerability management tasks, such as the prediction of security relevance and patch correctness, which require an all-encompassing understanding of various aspects, including code syntax, program semantics, and related manual comments. In this paper, we explore ChatGPT's capabilities on 6 tasks involving the complete vulnerability management process with a large-scale dataset containing 78,445 samples. For each task, we compare ChatGPT against SOTA approaches, investigate the impact of different prompts, and explore the difficulties. The results suggest promising potential in leveraging ChatGPT to assist vulnerability management. One notable example is ChatGPT's proficiency in tasks like generating titles for software bug reports. Furthermore, our findings reveal the difficulties encountered by ChatGPT and shed light on promising future directions. For instance, directly providing random demonstration examples in the prompt cannot consistently guarantee good performance in vulnerability management. By contrast, leveraging ChatGPT in a self-heuristic way -- extracting expertise from demonstration examples itself and integrating the extracted expertise in the prompt is a promising research direction. Besides, ChatGPT may misunderstand and misuse the information in the prompt. Consequently, effectively guiding ChatGPT to focus on helpful information rather than the irrelevant content is still an open problem.