 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenED-SC: Generative Editing Semantic Communication with Integrated Multi-Modal LLMs
May 31, 2026Deep learning-based joint source-channel coding has recently demonstrated strong potential for semantic communication (SemComm). However, most existing approaches focus on optimizing visual-fidelity metrics, which can lead to reduced perceptual quality. Generative model-based SemComm leverages rich prior knowledge from large-scale pre-training to enhance perceptual quality, but often at the cost of increased distortion and unreliability. This paper addresses the above issues by proposing a two-stage semantic image transmission framework, integrating a multimodal large language model (MLLM) for generative editing. In the first stage, a JSCC-based discriminative transmission selectively prioritizes semantically important regions, preserving scene layout and object integrity under limited bandwidth. In the second phase, MLLM-driven generative editing refines missing details based on the textual descriptions, enhancing semantic fidelity and perceptual quality. Extensive experiments show that the proposed framework achieves state-of-the-art performance in semantic preservation, perceptual quality, and visual fidelity across a wide range of channel conditions, especially in low-SNR regimes.
Deep Image Semantic Communication Model for Artificial Intelligent Internet of Things
Nov 08, 2023With the rapid development of Artificial Intelligent Internet of Things (AIoT), the image data from AIoT devices has been witnessing the explosive increasing. In this paper, a novel deep image semantic communication model is proposed for the efficient image communication in AIoT. Particularly, at the transmitter side, a high-precision image semantic segmentation algorithm is proposed to extract the semantic information of the image to achieve significant compression of the image data. At the receiver side, a semantic image restoration algorithm based on Generative Adversarial Network (GAN) is proposed to convert the semantic image to a real scene image with detailed information. Simulation results demonstrate that the proposed image semantic communication model can improve the image compression ratio and recovery accuracy by 71.93% and 25.07% on average in comparison with WebP and CycleGAN, respectively. More importantly, our demo experiment shows that the proposed model reduces the total delay by 95.26% in the image communication, when comparing with the original image transmission.
Visualizing Deep Learning-based Radio Modulation Classifier
May 03, 2020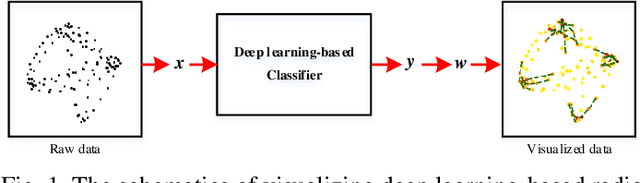
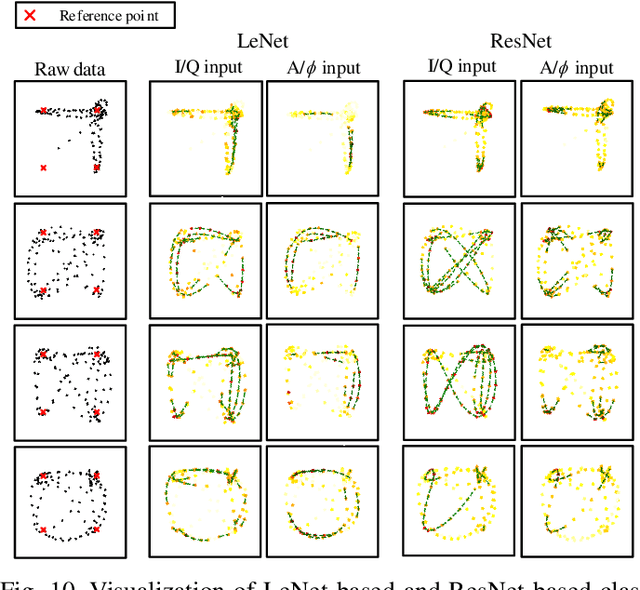
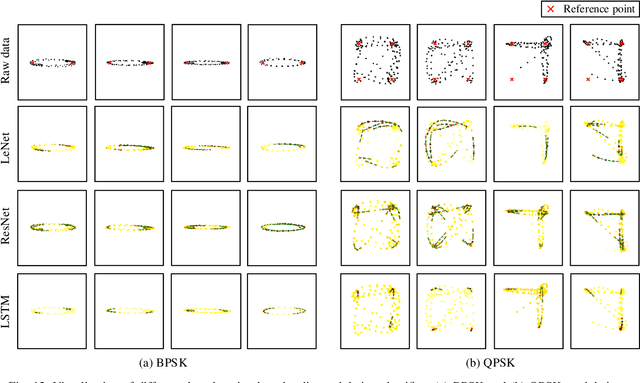
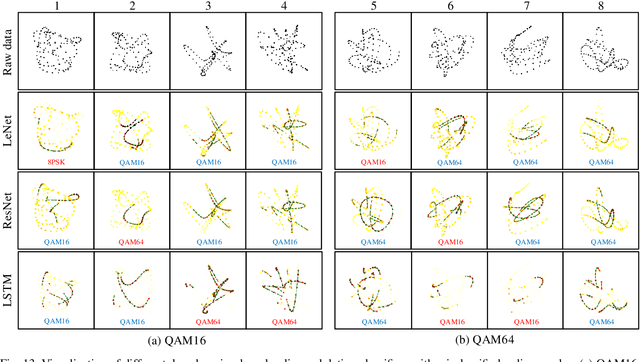
Deep learning has recently been successfully applied in automatic modulation classification by extracting and classifying radio features in an end-to-end way. However, deep learning-based radio modulation classifiers are lack of interpretability, and there is little explanation or visibility into what kinds of radio features are extracted and chosen for classification. In this paper, we visualize different deep learning-based radio modulation classifiers by introducing a class activation vector. Specifically, both convolutional neural networks (CNN) based classifier and long short-term memory (LSTM) based classifier are separately studied, and their extracted radio features are visualized. Extensive numerical results show both the CNN-based classifier and LSTM-based classifier extract similar radio features relating to modulation reference points. In particular, for the LSTM-based classifier, its obtained radio features are similar to the knowledge of human experts. Our numerical results indicate the radio features extracted by deep learning-based classifiers greatly depend on the contents carried by radio signals, and a short radio sample may lead to misclassification.