 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Regularized Conditional Diffusion Model for Multi-Task Preference Alignment
Apr 07, 2024
Sequential decision-making is desired to align with human intents and exhibit versatility across various tasks. Previous methods formulate it as a conditional generation process, utilizing return-conditioned diffusion models to directly model trajectory distributions. Nevertheless, the return-conditioned paradigm relies on pre-defined reward functions, facing challenges when applied in multi-task settings characterized by varying reward functions (versatility) and showing limited controllability concerning human preferences (alignment). In this work, we adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels. The learned representations are used to guide the conditional generation process of diffusion models, and we introduce an auxiliary objective to maximize the mutual information between representations and corresponding generated trajectories, improving alignment between trajectories and preferences. Extensive experiments in D4RL and Meta-World demonstrate that our method presents favorable performance in single- and multi-task scenarios, and exhibits superior alignment with preferences.
GauU-Scene V2: Expanse Lidar Image Dataset Shows Unreliable Geometric Reconstruction Using Gaussian Splatting and NeRF
Apr 07, 2024We introduce a novel large-scale scene reconstruction benchmark that utilizes newly developed 3D representation approaches: Gaussian Splatting and Neural Radiance Fields, on our expansive GauU-Scene V2 dataset. GauU-Scene V2 encompasses over 6.5 square kilometers and features a comprehensive RGB dataset coupled with LiDAR ground truth. This dataset offers a unique blend of urban and academic environments for advanced spatial analysis, covering more than 6.5 km2. We also provide detailed supplementary information on data collection protocols. Furthermore, we present an easy-to-follow pipeline to align the COLMAP sparse point cloud with the detailed LiDAR dataset. Our evaluation of U-Scene, which includes a detailed analysis across various novel viewpoints using image-based metrics such as SSIM, LPIPS, and PSNR, shows contradictory results when applying geometric-based metrics, such as Chamfer distance. This leads to doubts about the reliability of current image-based measurement matrices and geometric extraction methods on Gaussian Splatting. We also make the dataset available on the following anonymous project page
Signal-noise separation using unsupervised reservoir computing
Apr 07, 2024Removing noise from a signal without knowing the characteristics of the noise is a challenging task. This paper introduces a signal-noise separation method based on time series prediction. We use Reservoir Computing (RC) to extract the maximum portion of "predictable information" from a given signal. Reproducing the deterministic component of the signal using RC, we estimate the noise distribution from the difference between the original signal and reconstructed one. The method is based on a machine learning approach and requires no prior knowledge of either the deterministic signal or the noise distribution. It provides a way to identify additivity/multiplicativity of noise and to estimate the signal-to-noise ratio (SNR) indirectly. The method works successfully for combinations of various signal and noise, including chaotic signal and highly oscillating sinusoidal signal which are corrupted by non-Gaussian additive/ multiplicative noise. The separation performances are robust and notably outstanding for signals with strong noise, even for those with negative SNR.
From Two-Stream to One-Stream: Efficient RGB-T Tracking via Mutual Prompt Learning and Knowledge Distillation
Apr 07, 2024Due to the complementary nature of visible light and thermal infrared modalities, object tracking based on the fusion of visible light images and thermal images (referred to as RGB-T tracking) has received increasing attention from researchers in recent years. How to achieve more comprehensive fusion of information from the two modalities at a lower cost has been an issue that researchers have been exploring. Inspired by visual prompt learning, we designed a novel two-stream RGB-T tracking architecture based on cross-modal mutual prompt learning, and used this model as a teacher to guide a one-stream student model for rapid learning through knowledge distillation techniques. Extensive experiments have shown that, compared to similar RGB-T trackers, our designed teacher model achieved the highest precision rate, while the student model, with comparable precision rate to the teacher model, realized an inference speed more than three times faster than the teacher model.(Codes will be available if accepted.)
Multi-modal perception for soft robotic interactions using generative models
Apr 05, 2024Perception is essential for the active interaction of physical agents with the external environment. The integration of multiple sensory modalities, such as touch and vision, enhances this perceptual process, creating a more comprehensive and robust understanding of the world. Such fusion is particularly useful for highly deformable bodies such as soft robots. Developing a compact, yet comprehensive state representation from multi-sensory inputs can pave the way for the development of complex control strategies. This paper introduces a perception model that harmonizes data from diverse modalities to build a holistic state representation and assimilate essential information. The model relies on the causality between sensory input and robotic actions, employing a generative model to efficiently compress fused information and predict the next observation. We present, for the first time, a study on how touch can be predicted from vision and proprioception on soft robots, the importance of the cross-modal generation and why this is essential for soft robotic interactions in unstructured environments.
Willkommens-Merkel, Chaos-Johnson, and Tore-Klose: Modeling the Evaluative Meaning of German Personal Name Compounds
Apr 05, 2024We present a comprehensive computational study of the under-investigated phenomenon of personal name compounds (PNCs) in German such as Willkommens-Merkel ('Welcome-Merkel'). Prevalent in news, social media, and political discourse, PNCs are hypothesized to exhibit an evaluative function that is reflected in a more positive or negative perception as compared to the respective personal full name (such as Angela Merkel). We model 321 PNCs and their corresponding full names at discourse level, and show that PNCs bear an evaluative nature that can be captured through a variety of computational methods. Specifically, we assess through valence information whether a PNC is more positively or negatively evaluative than the person's name, by applying and comparing two approaches using (i) valence norms and (ii) pretrained language models (PLMs). We further enrich our data with personal, domain-specific, and extra-linguistic information and perform a range of regression analyses revealing that factors including compound and modifier valence, domain, and political party membership influence how a PNC is evaluated.
Multi-Modal Hallucination Control by Visual Information Grounding
Mar 20, 2024
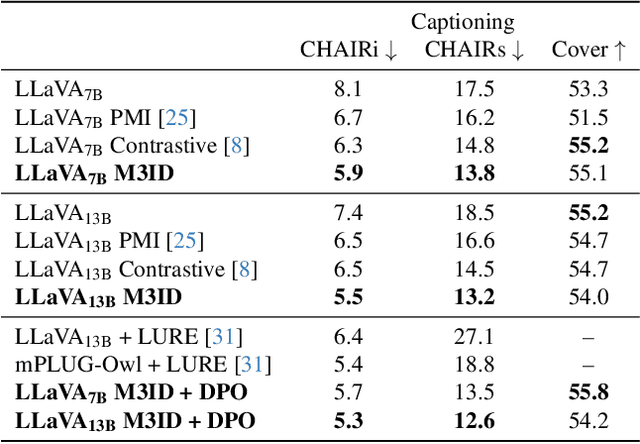
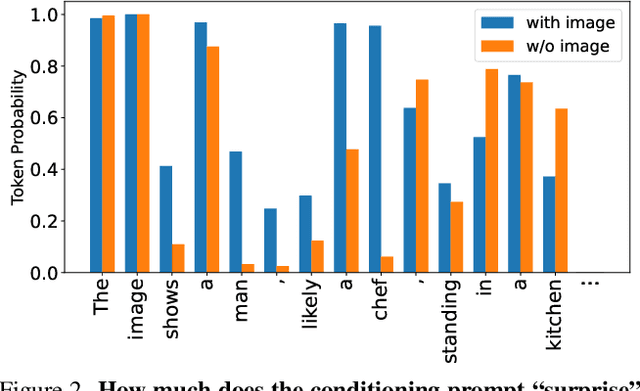
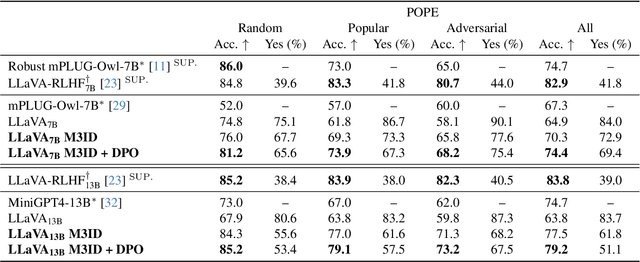
Generative Vision-Language Models (VLMs) are prone to generate plausible-sounding textual answers that, however, are not always grounded in the input image. We investigate this phenomenon, usually referred to as "hallucination" and show that it stems from an excessive reliance on the language prior. In particular, we show that as more tokens are generated, the reliance on the visual prompt decreases, and this behavior strongly correlates with the emergence of hallucinations. To reduce hallucinations, we introduce Multi-Modal Mutual-Information Decoding (M3ID), a new sampling method for prompt amplification. M3ID amplifies the influence of the reference image over the language prior, hence favoring the generation of tokens with higher mutual information with the visual prompt. M3ID can be applied to any pre-trained autoregressive VLM at inference time without necessitating further training and with minimal computational overhead. If training is an option, we show that M3ID can be paired with Direct Preference Optimization (DPO) to improve the model's reliance on the prompt image without requiring any labels. Our empirical findings show that our algorithms maintain the fluency and linguistic capabilities of pre-trained VLMs while reducing hallucinations by mitigating visually ungrounded answers. Specifically, for the LLaVA 13B model, M3ID and M3ID+DPO reduce the percentage of hallucinated objects in captioning tasks by 25% and 28%, respectively, and improve the accuracy on VQA benchmarks such as POPE by 21% and 24%.
Progressive Alignment with VLM-LLM Feature to Augment Defect Classification for the ASE Dataset
Apr 08, 2024Traditional defect classification approaches are facing with two barriers. (1) Insufficient training data and unstable data quality. Collecting sufficient defective sample is expensive and time-costing, consequently leading to dataset variance. It introduces the difficulty on recognition and learning. (2) Over-dependence on visual modality. When the image pattern and texture is monotonic for all defect classes in a given dataset, the performance of conventional AOI system cannot be guaranteed. In scenarios where image quality is compromised due to mechanical failures or when defect information is inherently difficult to discern, the performance of deep models cannot be guaranteed. A main question is, "how to solve those two problems when they occur at the same time?" The feasible strategy is to explore another feature within dataset and combine an eminent vision-language model (VLM) and Large-Language model (LLM) with their astonishing zero-shot capability. In this work, we propose the special ASE dataset, including rich data description recorded on image, for defect classification, but the defect feature is uneasy to learn directly. Secondly, We present the prompting for VLM-LLM against defect classification with the proposed ASE dataset to activate extra-modality feature from images to enhance performance. Then, We design the novel progressive feature alignment (PFA) block to refine image-text feature to alleviate the difficulty of alignment under few-shot scenario. Finally, the proposed Cross-modality attention fusion (CMAF) module can effectively fuse different modality feature. Experiment results have demonstrated our method's effectiveness over several defect classification methods for the ASE dataset.
Inferring the Phylogeny of Large Language Models and Predicting their Performances in Benchmarks
Apr 06, 2024This paper introduces PhyloLM, a method applying phylogenetic algorithms to Large Language Models to explore their finetuning relationships, and predict their performance characteristics. By leveraging the phylogenetic distance metric, we construct dendrograms, which satisfactorily capture distinct LLM families (across a set of 77 open-source and 22 closed models). Furthermore, phylogenetic distance predicts performances in benchmarks (we test MMLU and ARC), thus enabling a time and cost-effective estimation of LLM capabilities. The approach translates genetic concepts to machine learning, offering tools to infer LLM development, relationships, and capabilities, even in the absence of transparent training information.
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
Apr 05, 2024Multi-modal semantic segmentation significantly enhances AI agents' perception and scene understanding, especially under adverse conditions like low-light or overexposed environments. Leveraging additional modalities (X-modality) like thermal and depth alongside traditional RGB provides complementary information, enabling more robust and reliable segmentation. In this work, we introduce Sigma, a Siamese Mamba network for multi-modal semantic segmentation, utilizing the Selective Structured State Space Model, Mamba. Unlike conventional methods that rely on CNNs, with their limited local receptive fields, or Vision Transformers (ViTs), which offer global receptive fields at the cost of quadratic complexity, our model achieves global receptive fields coverage with linear complexity. By employing a Siamese encoder and innovating a Mamba fusion mechanism, we effectively select essential information from different modalities. A decoder is then developed to enhance the channel-wise modeling ability of the model. Our method, Sigma, is rigorously evaluated on both RGB-Thermal and RGB-Depth segmentation tasks, demonstrating its superiority and marking the first successful application of State Space Models (SSMs) in multi-modal perception tasks. Code is available at https://github.com/zifuwan/Sigma.