 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Soft Robot Adaptability: Implementations, Applications, and Prospects
Jun 24, 2025Soft robots, compared to rigid robots, possess inherent advantages, including higher degrees of freedom, compliance, and enhanced safety, which have contributed to their increasing application across various fields. Among these benefits, adaptability is particularly noteworthy. In this paper, adaptability in soft robots is categorized into external and internal adaptability. External adaptability refers to the robot's ability to adjust, either passively or actively, to variations in environments, object properties, geometries, and task dynamics. Internal adaptability refers to the robot's ability to cope with internal variations, such as manufacturing tolerances or material aging, and to generalize control strategies across different robots. As the field of soft robotics continues to evolve, the significance of adaptability has become increasingly pronounced. In this review, we summarize various approaches to enhancing the adaptability of soft robots, including design, sensing, and control strategies. Additionally, we assess the impact of adaptability on applications such as surgery, wearable devices, locomotion, and manipulation. We also discuss the limitations of soft robotics adaptability and prospective directions for future research. By analyzing adaptability through the lenses of implementation, application, and challenges, this paper aims to provide a comprehensive understanding of this essential characteristic in soft robotics and its implications for diverse applications.
Towards Interpretable Visuo-Tactile Predictive Models for Soft Robot Interactions
Jul 16, 2024



Autonomous systems face the intricate challenge of navigating unpredictable environments and interacting with external objects. The successful integration of robotic agents into real-world situations hinges on their perception capabilities, which involve amalgamating world models and predictive skills. Effective perception models build upon the fusion of various sensory modalities to probe the surroundings. Deep learning applied to raw sensory modalities offers a viable option. However, learning-based perceptive representations become difficult to interpret. This challenge is particularly pronounced in soft robots, where the compliance of structures and materials makes prediction even harder. Our work addresses this complexity by harnessing a generative model to construct a multi-modal perception model for soft robots and to leverage proprioceptive and visual information to anticipate and interpret contact interactions with external objects. A suite of tools to interpret the perception model is furnished, shedding light on the fusion and prediction processes across multiple sensory inputs after the learning phase. We will delve into the outlooks of the perception model and its implications for control purposes.
Soft Synergies: Model Order Reduction of Hybrid Soft-Rigid Robots via Optimal Strain Parameterization
May 21, 2024



Soft robots offer remarkable adaptability and safety advantages over rigid robots, but modeling their complex, nonlinear dynamics remains challenging. Strain-based models have recently emerged as a promising candidate to describe such systems, however, they tend to be high-dimensional and time consuming. This paper presents a novel model order reduction approach for soft and hybrid robots by combining strain-based modeling with Proper Orthogonal Decomposition (POD). The method identifies optimal coupled strain basis functions -- or mechanical synergies -- from simulation data, enabling the description of soft robot configurations with a minimal number of generalized coordinates. The reduced order model (ROM) achieves substantial dimensionality reduction while preserving accuracy. Rigorous testing demonstrates the interpolation and extrapolation capabilities of the ROM for soft manipulators under static and dynamic conditions. The approach is further validated on a snake-like hyper-redundant rigid manipulator and a closed-chain system with soft and rigid components, illustrating its broad applicability. Finally, the approach is leveraged for shape estimation of a real six-actuator soft manipulator using only two position markers, showcasing its practical utility. This POD-based ROM offers significant computational speed-ups, paving the way for real-time simulation and control of complex soft and hybrid robots.
Multi-modal perception for soft robotic interactions using generative models
Apr 05, 2024



Perception is essential for the active interaction of physical agents with the external environment. The integration of multiple sensory modalities, such as touch and vision, enhances this perceptual process, creating a more comprehensive and robust understanding of the world. Such fusion is particularly useful for highly deformable bodies such as soft robots. Developing a compact, yet comprehensive state representation from multi-sensory inputs can pave the way for the development of complex control strategies. This paper introduces a perception model that harmonizes data from diverse modalities to build a holistic state representation and assimilate essential information. The model relies on the causality between sensory input and robotic actions, employing a generative model to efficiently compress fused information and predict the next observation. We present, for the first time, a study on how touch can be predicted from vision and proprioception on soft robots, the importance of the cross-modal generation and why this is essential for soft robotic interactions in unstructured environments.
Multimodel Sensor Fusion for Learning Rich Models for Interacting Soft Robots
May 09, 2022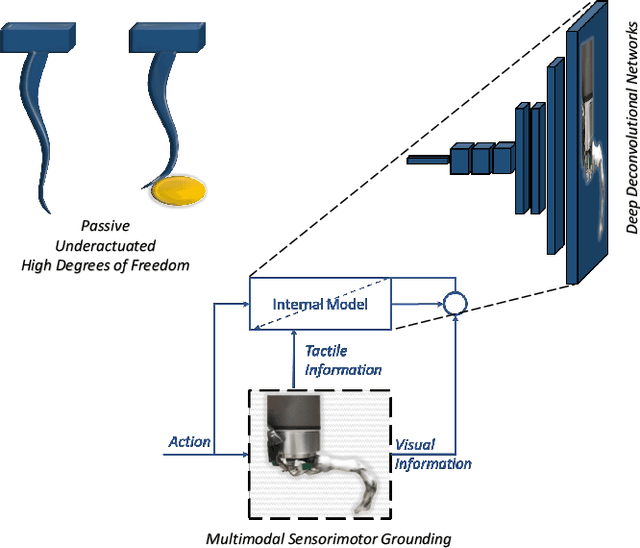
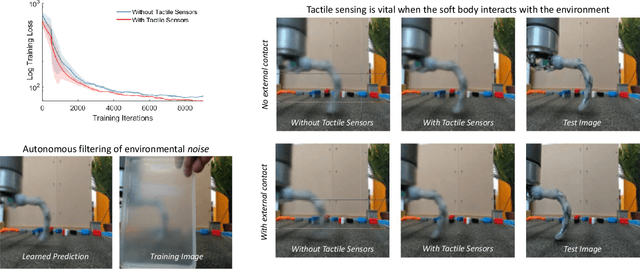
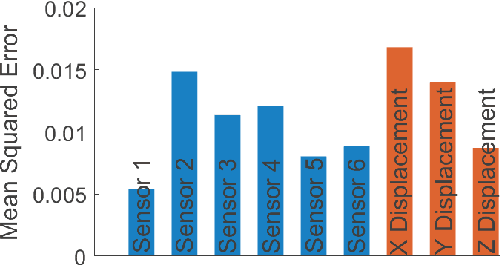
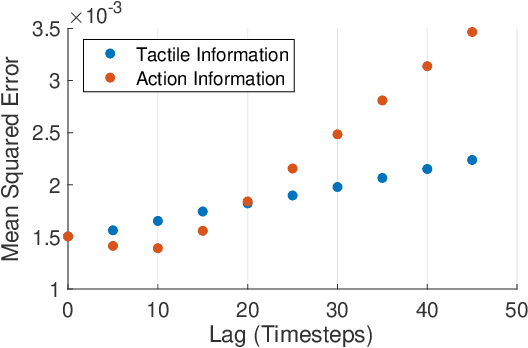
Soft robots are typically approximated as low-dimensional systems, especially when learning-based methods are used. This leads to models that are limited in their capability to predict the large number of deformation modes and interactions that a soft robot can have. In this work, we present a deep-learning methodology to learn high-dimensional visual models of a soft robot combining multimodal sensorimotor information. The models are learned in an end-to-end fashion, thereby requiring no intermediate sensor processing or grounding of data. The capabilities and advantages of such a modelling approach are shown on a soft anthropomorphic finger with embedded soft sensors. We also show that how such an approach can be extended to develop higher level cognitive functions like identification of the self and the external environment and acquiring object manipulation skills. This work is a step towards the integration of soft robotics and developmental robotics architectures to create the next generation of intelligent soft robots.
A bistable soft gripper with mechanically embedded sensing and actuation for fast closed-loop grasping
Feb 13, 2019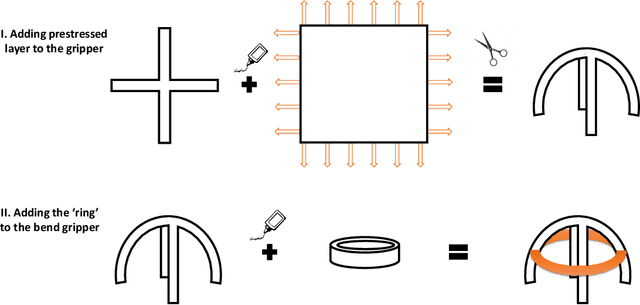
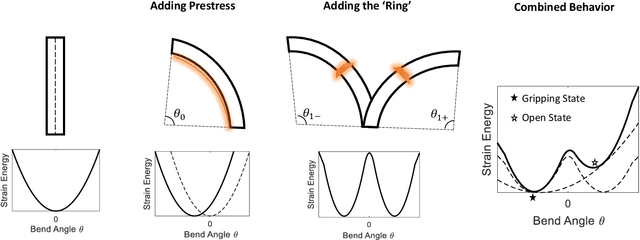

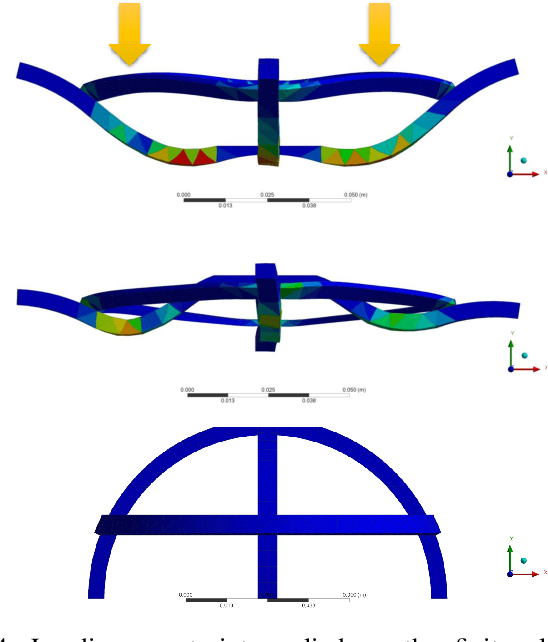
Soft robotic grippers are shown to be high effective for grasping unstructured objects with simple sensing and control strategies. However, they are still limited by their speed, sensing capabilities and actuation mechanism. Hence, their usage have been restricted in highly dynamic grasping tasks. This paper presents a soft robotic gripper with tunable bistable properties for sensor-less dynamic grasping. The bistable mechanism allows us to store arbitrarily large strain energy in the soft system which is then released upon contact. The mechanism also provides flexibility on the type of actuation mechanism as the grasping and sensing phase is completely passive. Theoretical background behind the mechanism is presented with finite element analysis to provide insights into design parameters. Finally, we experimentally demonstrate sensor-less dynamic grasping of an unknown object within 0.02 seconds, including the time to sense and actuate.