 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
Jan 02, 2024
This work elicits LLMs' inherent ability to handle long contexts without fine-tuning. The limited length of the training sequence during training may limit the application of Large Language Models (LLMs) on long input sequences for inference. In this work, we argue that existing LLMs themselves have inherent capabilities for handling long contexts. Based on this argument, we suggest extending LLMs' context window by themselves to fully utilize the inherent ability.We propose Self-Extend to stimulate LLMs' long context handling potential. The basic idea is to construct bi-level attention information: the group level and the neighbor level. The two levels are computed by the original model's self-attention, which means the proposed does not require any training. With only four lines of code modification, the proposed method can effortlessly extend existing LLMs' context window without any fine-tuning. We conduct comprehensive experiments and the results show that the proposed method can effectively extend existing LLMs' context window's length.
ExCeL : Combined Extreme and Collective Logit Information for Enhancing Out-of-Distribution Detection
Nov 23, 2023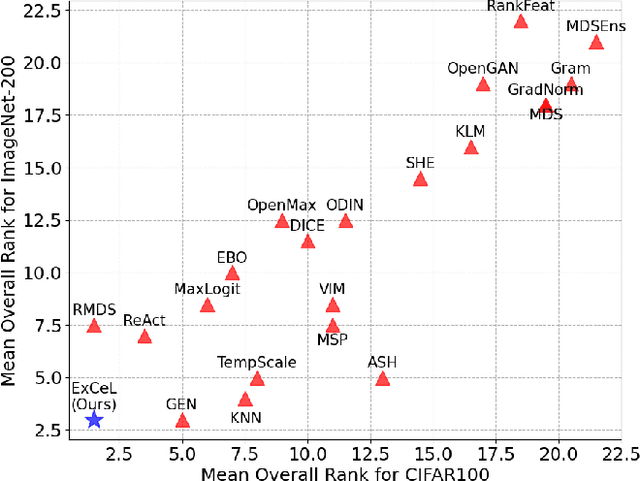
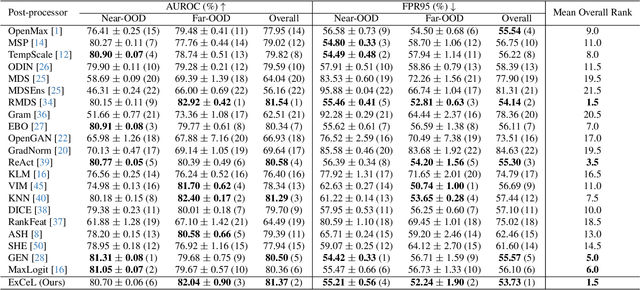
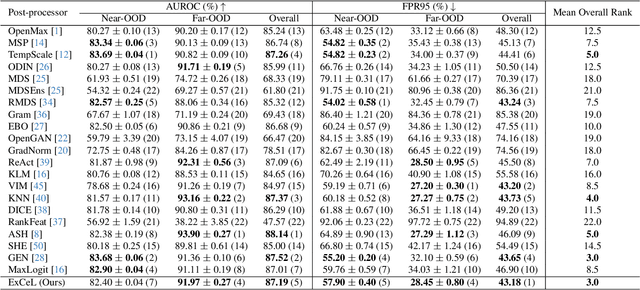
Deep learning models often exhibit overconfidence in predicting out-of-distribution (OOD) data, underscoring the crucial role of OOD detection in ensuring reliability in predictions. Among various OOD detection approaches, post-hoc detectors have gained significant popularity, primarily due to their ease of use and implementation. However, the effectiveness of most post-hoc OOD detectors has been constrained as they rely solely either on extreme information, such as the maximum logit, or on the collective information (i.e., information spanned across classes or training samples) embedded within the output layer. In this paper, we propose ExCeL that combines both extreme and collective information within the output layer for enhanced accuracy in OOD detection. We leverage the logit of the top predicted class as the extreme information (i.e., the maximum logit), while the collective information is derived in a novel approach that involves assessing the likelihood of other classes appearing in subsequent ranks across various training samples. Our idea is motivated by the observation that, for in-distribution (ID) data, the ranking of classes beyond the predicted class is more deterministic compared to that in OOD data. Experiments conducted on CIFAR100 and ImageNet-200 datasets demonstrate that ExCeL consistently is among the five top-performing methods out of twenty-one existing post-hoc baselines when the joint performance on near-OOD and far-OOD is considered (i.e., in terms of AUROC and FPR95). Furthermore, ExCeL shows the best overall performance across both datasets, unlike other baselines that work best on one dataset but has a performance drop in the other.
Text2MDT: Extracting Medical Decision Trees from Medical Texts
Jan 04, 2024Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to build clinical decision support systems. However, the current MDT construction methods rely heavily on time-consuming and laborious manual annotation. In this work, we propose a novel task, Text2MDT, to explore the automatic extraction of MDTs from medical texts such as medical guidelines and textbooks. We normalize the form of the MDT and create an annotated Text-to-MDT dataset in Chinese with the participation of medical experts. We investigate two different methods for the Text2MDT tasks: (a) an end-to-end framework which only relies on a GPT style large language models (LLM) instruction tuning to generate all the node information and tree structures. (b) The pipeline framework which decomposes the Text2MDT task to three subtasks. Experiments on our Text2MDT dataset demonstrate that: (a) the end-to-end method basd on LLMs (7B parameters or larger) show promising results, and successfully outperform the pipeline methods. (b) The chain-of-thought (COT) prompting method \cite{Wei2022ChainOT} can improve the performance of the fine-tuned LLMs on the Text2MDT test set. (c) the lightweight pipelined method based on encoder-based pretrained models can perform comparably with LLMs with model complexity two magnititudes smaller. Our Text2MDT dataset is open-sourced at \url{https://tianchi.aliyun.com/dataset/95414}, and the source codes are open-sourced at \url{https://github.com/michael-wzhu/text2dt}.
Robust bilinear factor analysis based on the matrix-variate $t$ distribution
Jan 04, 2024Factor Analysis based on multivariate $t$ distribution ($t$fa) is a useful robust tool for extracting common factors on heavy-tailed or contaminated data. However, $t$fa is only applicable to vector data. When $t$fa is applied to matrix data, it is common to first vectorize the matrix observations. This introduces two challenges for $t$fa: (i) the inherent matrix structure of the data is broken, and (ii) robustness may be lost, as vectorized matrix data typically results in a high data dimension, which could easily lead to the breakdown of $t$fa. To address these issues, starting from the intrinsic matrix structure of matrix data, a novel robust factor analysis model, namely bilinear factor analysis built on the matrix-variate $t$ distribution ($t$bfa), is proposed in this paper. The novelty is that it is capable to simultaneously extract common factors for both row and column variables of interest on heavy-tailed or contaminated matrix data. Two efficient algorithms for maximum likelihood estimation of $t$bfa are developed. Closed-form expression for the Fisher information matrix to calculate the accuracy of parameter estimates are derived. Empirical studies are conducted to understand the proposed $t$bfa model and compare with related competitors. The results demonstrate the superiority and practicality of $t$bfa. Importantly, $t$bfa exhibits a significantly higher breakdown point than $t$fa, making it more suitable for matrix data.
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Jan 04, 2024The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this "bag-level" image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We plan to release the benchmark, consisting of 7 datasets, which will contribute to future research in zero-shot recognition.
Towards Mitigating Dimensional Collapse of Representations in Collaborative Filtering
Dec 29, 2023Contrastive Learning (CL) has shown promising performance in collaborative filtering. The key idea is to generate augmentation-invariant embeddings by maximizing the Mutual Information between different augmented views of the same instance. However, we empirically observe that existing CL models suffer from the \textsl{dimensional collapse} issue, where user/item embeddings only span a low-dimension subspace of the entire feature space. This suppresses other dimensional information and weakens the distinguishability of embeddings. Here we propose a non-contrastive learning objective, named nCL, which explicitly mitigates dimensional collapse of representations in collaborative filtering. Our nCL aims to achieve geometric properties of \textsl{Alignment} and \textsl{Compactness} on the embedding space. In particular, the alignment tries to push together representations of positive-related user-item pairs, while compactness tends to find the optimal coding length of user/item embeddings, subject to a given distortion. More importantly, our nCL does not require data augmentation nor negative sampling during training, making it scalable to large datasets. Experimental results demonstrate the superiority of our nCL.
Machine learning phase transitions: Connections to the Fisher information
Nov 17, 2023Despite the widespread use and success of machine-learning techniques for detecting phase transitions from data, their working principle and fundamental limits remain elusive. Here, we explain the inner workings and identify potential failure modes of these techniques by rooting popular machine-learning indicators of phase transitions in information-theoretic concepts. Using tools from information geometry, we prove that several machine-learning indicators of phase transitions approximate the square root of the system's (quantum) Fisher information from below -- a quantity that is known to indicate phase transitions but is often difficult to compute from data. We numerically demonstrate the quality of these bounds for phase transitions in classical and quantum systems.
Paragraph-to-Image Generation with Information-Enriched Diffusion Model
Nov 29, 2023Text-to-image (T2I) models have recently experienced rapid development, achieving astonishing performance in terms of fidelity and textual alignment capabilities. However, given a long paragraph (up to 512 words), these generation models still struggle to achieve strong alignment and are unable to generate images depicting complex scenes. In this paper, we introduce an information-enriched diffusion model for paragraph-to-image generation task, termed ParaDiffusion, which delves into the transference of the extensive semantic comprehension capabilities of large language models to the task of image generation. At its core is using a large language model (e.g., Llama V2) to encode long-form text, followed by fine-tuning with LORA to alignthe text-image feature spaces in the generation task. To facilitate the training of long-text semantic alignment, we also curated a high-quality paragraph-image pair dataset, namely ParaImage. This dataset contains a small amount of high-quality, meticulously annotated data, and a large-scale synthetic dataset with long text descriptions being generated using a vision-language model. Experiments demonstrate that ParaDiffusion outperforms state-of-the-art models (SD XL, DeepFloyd IF) on ViLG-300 and ParaPrompts, achieving up to 15% and 45% human voting rate improvements for visual appeal and text faithfulness, respectively. The code and dataset will be released to foster community research on long-text alignment.
DGDNN: Decoupled Graph Diffusion Neural Network for Stock Movement Prediction
Jan 03, 2024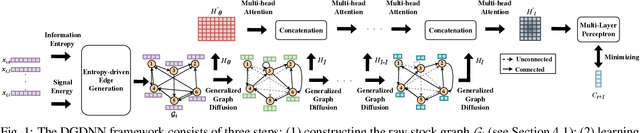
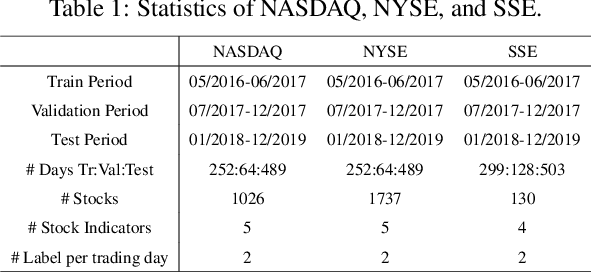
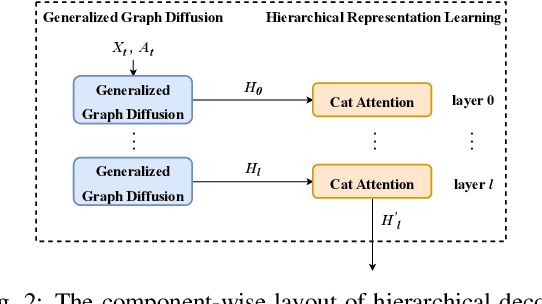
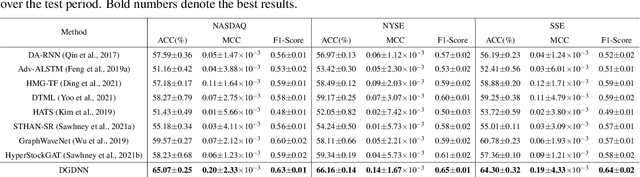
Forecasting future stock trends remains challenging for academia and industry due to stochastic inter-stock dynamics and hierarchical intra-stock dynamics influencing stock prices. In recent years, graph neural networks have achieved remarkable performance in this problem by formulating multiple stocks as graph-structured data. However, most of these approaches rely on artificially defined factors to construct static stock graphs, which fail to capture the intrinsic interdependencies between stocks that rapidly evolve. In addition, these methods often ignore the hierarchical features of the stocks and lose distinctive information within. In this work, we propose a novel graph learning approach implemented without expert knowledge to address these issues. First, our approach automatically constructs dynamic stock graphs by entropy-driven edge generation from a signal processing perspective. Then, we further learn task-optimal dependencies between stocks via a generalized graph diffusion process on constructed stock graphs. Last, a decoupled representation learning scheme is adopted to capture distinctive hierarchical intra-stock features. Experimental results demonstrate substantial improvements over state-of-the-art baselines on real-world datasets. Moreover, the ablation study and sensitivity study further illustrate the effectiveness of the proposed method in modeling the time-evolving inter-stock and intra-stock dynamics.
Many-Objective-Optimized Semi-Automated Robotic Disassembly Sequences
Jan 03, 2024This study tasckles the problem of many-objective sequence optimization for semi-automated robotic disassembly operations. To this end, we employ a many-objective genetic algorithm (MaOGA) algorithm inspired by the Non-dominated Sorting Genetic Algorithm (NSGA)-III, along with robotic-disassembly-oriented constraints and objective functions derived from geometrical and robot simulations using 3-dimensional (3D) geometrical information stored in a 3D Computer-Aided Design (CAD) model of the target product. The MaOGA begins by generating a set of initial chromosomes based on a contact and connection graph (CCG), rather than random chromosomes, to avoid falling into a local minimum and yield repeatable convergence. The optimization imposes constraints on feasibility and stability as well as objective functions regarding difficulty, efficiency, prioritization, and allocability to generate a sequence that satisfies many preferred conditions under mandatory requirements for semi-automated robotic disassembly. The NSGA-III-inspired MaOGA also utilizes non-dominated sorting and niching with reference lines to further encourage steady and stable exploration and uniformly lower the overall evaluation values. Our sequence generation experiments for a complex product (36 parts) demonstrated that the proposed method can consistently produce feasible and stable sequences with a 100% success rate, bringing the multiple preferred conditions closer to the optimal solution required for semi-automated robotic disassembly operations.