 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwenSafe: Multimodal Content Rating Description Identification via Preference-Aligned VLMs
May 20, 2026Mobile app marketplaces require developers to disclose standardized content rating descriptors (CRDs) to inform users about potentially sensitive or restricted content. Ensuring the accuracy and consistency of these disclosures remains challenging due to the multimodal nature of app content, which spans textual descriptions and visual interfaces. In this paper, we present QwenSafe, a Vision-Language Model (VLM) designed to automatically identify the presence of Apple-defined CRDs by jointly reasoning over app metadata and screenshots. To enable scalable training for this task, we introduce metadata2CRD, a data-construction pipeline that synthesizes descriptor-aligned question-answer pairs by combining app descriptions, screenshots, and formal descriptor definitions. We adapt Qwen3-VL-8B using supervised fine-tuning followed by Direct Preference Optimization (DPO) to align model predictions with descriptor-specific evidence and explanations across visual and textual modalities. We evaluate QwenSafe on 12 Apple-defined content rating descriptors and compare it against state-of-the-art vision-language models, including Qwen3-VL, LLaVA-1.6, and Gemini-2.5-Flash. QwenSafe consistently outperforms all baselines in binary CRD classification, achieving improvements in positive-class recall of 111.8%, 36.1%, and 2.1%, respectively. Our results demonstrate that descriptor-aware multimodal alignment substantially improves automated content classification and highlights the potential of vision-language models to support scalable and consistent content rating in mobile app marketplaces.
Pen-Strategist: A Reasoning Framework for Penetration Testing Strategy Formation and Analysis
May 06, 2026Cyber threats are rapidly increasing, expanding their impact from large-scale enterprises to government services and individual users, making robust security systems increasingly essential. However, a significant shortage of skilled cybersecurity professionals exacerbates this challenge. While recent research has explored automating tasks such as penetration testing using LLM-based agents, existing frameworks often perform poorly due to limited capability in strategy formulation, domain-specific reasoning, and accurate action and tool selection. To overcome these limitations, we propose Pen-Strategist framework, consisting of a novel domain-specific reasoning model that derives pentesting strategies via logical reasoning and a classifier that converts the strategies into actionable steps. First, we construct a reasoning dataset containing logical explanations for both strategy derivation and step selection in pentesting scenarios. We then fine-tune a Qwen-3-14B model for strategy generation using reinforcement learning. Evaluation on the test split of the dataset demonstrates a 87% improvement in strategy derivation performance compared to the baseline. Furthermore, we integrate the fine-tuned Pen-Strategist model into existing automated pentesting frameworks, such as PentestGPT, and evaluate its performance on vulnerable machines, achieving a 47.5% improvement in subtask completion while surpassing the baseline GPT-5. Further experiments on the CTFKnow benchmark show an 18% performance gain over the base model. For step prediction, we train a semantic-based CNN classifier, which outperforms commercial LLMs by 28% and enhances execution stability. Finally, we conduct a user study to qualitatively assess the generated strategies, and Pen-Strategist demonstrates superior performance compared to the Claude-4.6-Sonnet.
SADE: Symptom-Aware Diagnostic Escalation for LLM-Based Network Troubleshooting
May 06, 2026Large language model (LLM) agents are increasingly applied to network troubleshooting, but root-cause localization on public benchmarks remains well below practical deployment thresholds. We argue this is because existing agents do not encode the disciplined, layer-by-layer methodology that human network engineers use, and instead rely on free-form deliberation that conflates evidence acquisition with hypothesis commitment. We present SADE (Symptom-Aware Diagnostic Escalation), an agent that encodes the classical Cisco troubleshooting methodology as an explicit policy. SADE pairs a phase-gated diagnostic workflow, which separates evidence acquisition from hypothesis commitment, with a routed library of fault-family skills and high-yield diagnostic helpers. On a held-out 523 incident set of the public NIKA benchmark covering eleven unseen scenarios, SADE improves root-cause F1 by 37 percentage points over a ReAct + GPT-5 baseline; a model-controlled comparison against the same Claude Sonnet backend without the SADE policy attributes 22 of those points to the diagnostic policy alone, showing that the gain is not a side-effect of the model upgrade.
PrivPRISM: Automatically Detecting Discrepancies Between Google Play Data Safety Declarations and Developer Privacy Policies
Mar 10, 2026End-users seldom read verbose privacy policies, leading app stores like Google Play to mandate simplified data safety declarations as a user-friendly alternative. However, these self-declared disclosures often contradict the full privacy policies, deceiving users about actual data practices and violating regulatory requirements for consistency. To address this, we introduce PrivPRISM, a robust framework that combines encoder and decoder language models to systematically extract and compare fine-grained data practices from privacy policies and to compare against data safety declarations, enabling scalable detection of non-compliance. Evaluating 7,770 popular mobile games uncovers discrepancies in nearly 53% of cases, rising to 61% among 1,711 widely used generic apps. Additionally, static code analysis reveals possible under-disclosures, with privacy policies disclosing just 66.8% of potential accesses to sensitive data like location and financial information, versus only 36.4% in data safety declarations of mobile games. Our findings expose systemic issues, including widespread reuse of generic privacy policies, vague / contradictory statements, and hidden risks in high-profile apps with 100M+ downloads, underscoring the urgent need for automated enforcement to protect platform integrity and for end-users to be vigilant about sensitive data they disclose via popular apps.
Eliciting Least-to-Most Reasoning for Phishing URL Detection
Jan 28, 2026Phishing continues to be one of the most prevalent attack vectors, making accurate classification of phishing URLs essential. Recently, large language models (LLMs) have demonstrated promising results in phishing URL detection. However, their reasoning capabilities that enabled such performance remain underexplored. To this end, in this paper, we propose a Least-to-Most prompting framework for phishing URL detection. In particular, we introduce an "answer sensitivity" mechanism that guides Least-to-Most's iterative approach to enhance reasoning and yield higher prediction accuracy. We evaluate our framework using three URL datasets and four state-of-the-art LLMs, comparing against a one-shot approach and a supervised model. We demonstrate that our framework outperforms the one-shot baseline while achieving performance comparable to that of the supervised model, despite requiring significantly less training data. Furthermore, our in-depth analysis highlights how the iterative reasoning enabled by Least-to-Most, and reinforced by our answer sensitivity mechanism, drives these performance gains. Overall, we show that this simple yet powerful prompting strategy consistently outperforms both one-shot and supervised approaches, despite requiring minimal training or few-shot guidance. Our experimental setup can be found in our Github repository github.sydney.edu.au/htri0928/least-to-most-phishing-detection.
Personalizing Federated Learning for Hierarchical Edge Networks with Non-IID Data
Apr 11, 2025Accommodating edge networks between IoT devices and the cloud server in Hierarchical Federated Learning (HFL) enhances communication efficiency without compromising data privacy. However, devices connected to the same edge often share geographic or contextual similarities, leading to varying edge-level data heterogeneity with different subsets of labels per edge, on top of device-level heterogeneity. This hierarchical non-Independent and Identically Distributed (non-IID) nature, which implies that each edge has its own optimization goal, has been overlooked in HFL research. Therefore, existing edge-accommodated HFL demonstrates inconsistent performance across edges in various hierarchical non-IID scenarios. To ensure robust performance with diverse edge-level non-IID data, we propose a Personalized Hierarchical Edge-enabled Federated Learning (PHE-FL), which personalizes each edge model to perform well on the unique class distributions specific to each edge. We evaluated PHE-FL across 4 scenarios with varying levels of edge-level non-IIDness, with extreme IoT device level non-IIDness. To accurately assess the effectiveness of our personalization approach, we deployed test sets on each edge server instead of the cloud server, and used both balanced and imbalanced test sets. Extensive experiments show that PHE-FL achieves up to 83 percent higher accuracy compared to existing federated learning approaches that incorporate edge networks, given the same number of training rounds. Moreover, PHE-FL exhibits improved stability, as evidenced by reduced accuracy fluctuations relative to the state-of-the-art FedAvg with two-level (edge and cloud) aggregation.
A Framework to Assess Multilingual Vulnerabilities of LLMs
Mar 17, 2025



Large Language Models (LLMs) are acquiring a wider range of capabilities, including understanding and responding in multiple languages. While they undergo safety training to prevent them from answering illegal questions, imbalances in training data and human evaluation resources can make these models more susceptible to attacks in low-resource languages (LRL). This paper proposes a framework to automatically assess the multilingual vulnerabilities of commonly used LLMs. Using our framework, we evaluated six LLMs across eight languages representing varying levels of resource availability. We validated the assessments generated by our automated framework through human evaluation in two languages, demonstrating that the framework's results align with human judgments in most cases. Our findings reveal vulnerabilities in LRL; however, these may pose minimal risk as they often stem from the model's poor performance, resulting in incoherent responses.
Federated Koopman-Reservoir Learning for Large-Scale Multivariate Time-Series Anomaly Detection
Mar 14, 2025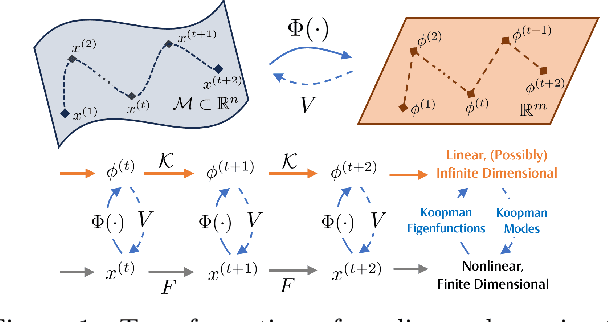
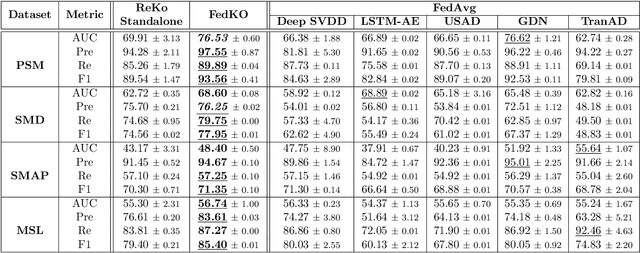
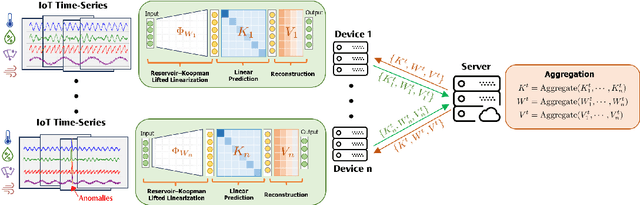
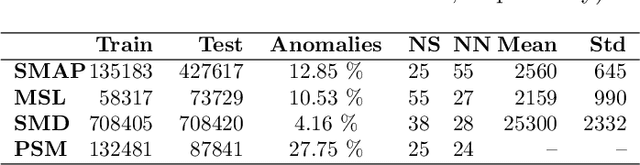
The proliferation of edge devices has dramatically increased the generation of multivariate time-series (MVTS) data, essential for applications from healthcare to smart cities. Such data streams, however, are vulnerable to anomalies that signal crucial problems like system failures or security incidents. Traditional MVTS anomaly detection methods, encompassing statistical and centralized machine learning approaches, struggle with the heterogeneity, variability, and privacy concerns of large-scale, distributed environments. In response, we introduce FedKO, a novel unsupervised Federated Learning framework that leverages the linear predictive capabilities of Koopman operator theory along with the dynamic adaptability of Reservoir Computing. This enables effective spatiotemporal processing and privacy preservation for MVTS data. FedKO is formulated as a bi-level optimization problem, utilizing a specific federated algorithm to explore a shared Reservoir-Koopman model across diverse datasets. Such a model is then deployable on edge devices for efficient detection of anomalies in local MVTS streams. Experimental results across various datasets showcase FedKO's superior performance against state-of-the-art methods in MVTS anomaly detection. Moreover, FedKO reduces up to 8x communication size and 2x memory usage, making it highly suitable for large-scale systems.
An Empirical Study of Code Obfuscation Practices in the Google Play Store
Feb 07, 2025



The Android ecosystem is vulnerable to issues such as app repackaging, counterfeiting, and piracy, threatening both developers and users. To mitigate these risks, developers often employ code obfuscation techniques. However, while effective in protecting legitimate applications, obfuscation also hinders security investigations as it is often exploited for malicious purposes. As such, it is important to understand code obfuscation practices in Android apps. In this paper, we analyze over 500,000 Android APKs from Google Play, spanning an eight-year period, to investigate the evolution and prevalence of code obfuscation techniques. First, we propose a set of classifiers to detect obfuscated code, tools, and techniques and then conduct a longitudinal analysis to identify trends. Our results show a 13% increase in obfuscation from 2016 to 2023, with ProGuard and Allatori as the most commonly used tools. We also show that obfuscation is more prevalent in top-ranked apps and gaming genres such as Casino apps. To our knowledge, this is the first large-scale study of obfuscation adoption in the Google Play Store, providing insights for developers and security analysts.
Entailment-Driven Privacy Policy Classification with LLMs
Sep 25, 2024



While many online services provide privacy policies for end users to read and understand what personal data are being collected, these documents are often lengthy and complicated. As a result, the vast majority of users do not read them at all, leading to data collection under uninformed consent. Several attempts have been made to make privacy policies more user friendly by summarising them, providing automatic annotations or labels for key sections, or by offering chat interfaces to ask specific questions. With recent advances in Large Language Models (LLMs), there is an opportunity to develop more effective tools to parse privacy policies and help users make informed decisions. In this paper, we propose an entailment-driven LLM based framework to classify paragraphs of privacy policies into meaningful labels that are easily understood by users. The results demonstrate that our framework outperforms traditional LLM methods, improving the F1 score in average by 11.2%. Additionally, our framework provides inherently explainable and meaningful predictions.