 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neighbor Oblivious Learning (NObLe) for Device Localization and Tracking
Nov 23, 2020
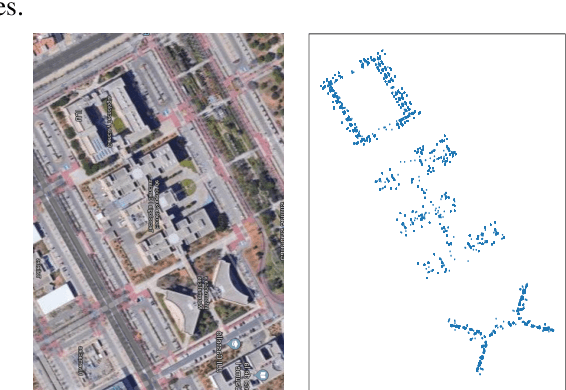

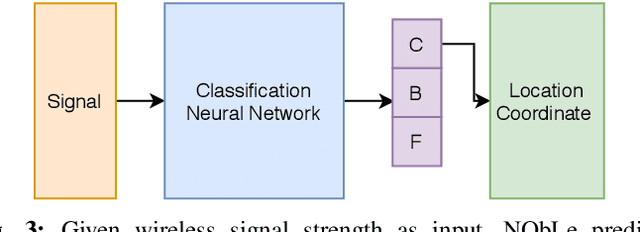
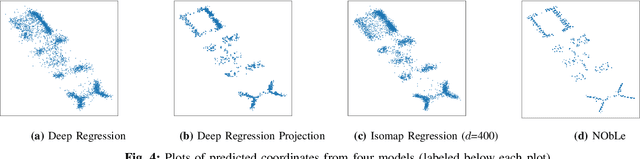
On-device localization and tracking are increasingly crucial for various applications. Along with a rapidly growing amount of location data, machine learning (ML) techniques are becoming widely adopted. A key reason is that ML inference is significantly more energy-efficient than GPS query at comparable accuracy, and GPS signals can become extremely unreliable for specific scenarios. To this end, several techniques such as deep neural networks have been proposed. However, during training, almost none of them incorporate the known structural information such as floor plan, which can be especially useful in indoor or other structured environments. In this paper, we argue that the state-of-the-art-systems are significantly worse in terms of accuracy because they are incapable of utilizing these essential structural information. The problem is incredibly hard because the structural properties are not explicitly available, making most structural learning approaches inapplicable. Given that both input and output space potentially contain rich structures, we study our method through the intuitions from manifold-projection. Whereas existing manifold based learning methods actively utilized neighborhood information, such as Euclidean distances, our approach performs Neighbor Oblivious Learning (NObLe). We demonstrate our approach's effectiveness on two orthogonal applications, including WiFi-based fingerprint localization and inertial measurement unit(IMU) based device tracking, and show that it gives significant improvement over state-of-art prediction accuracy.
FBI-Pose: Towards Bridging the Gap between 2D Images and 3D Human Poses using Forward-or-Backward Information
Jun 25, 2018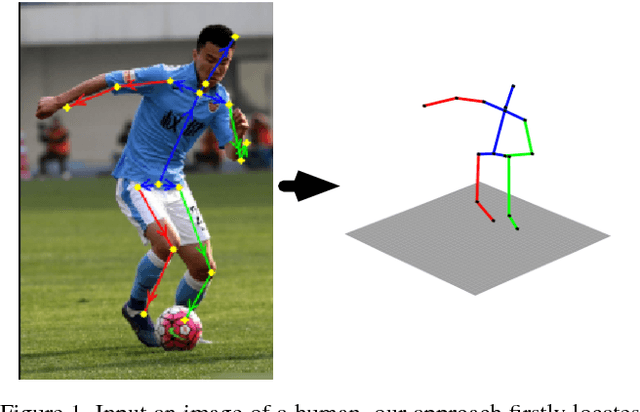
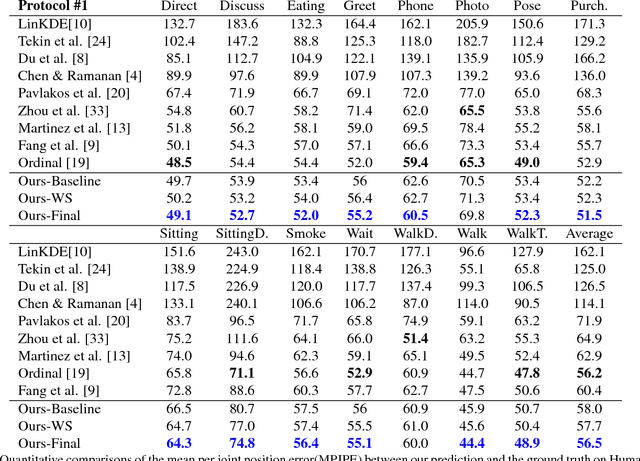
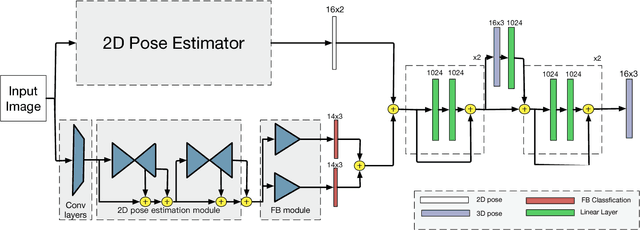
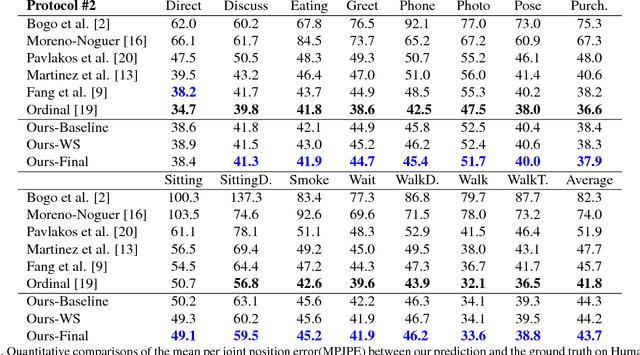
Although significant advances have been made in the area of human poses estimation from images using deep Convolutional Neural Network (ConvNet), it remains a big challenge to perform 3D pose inference in-the-wild. This is due to the difficulty to obtain 3D pose groundtruth for outdoor environments. In this paper, we propose a novel framework to tackle this problem by exploiting the information of each bone indicating if it is forward or backward with respect to the view of the camera(we term it Forwardor-Backward Information abbreviated as FBI). Our method firstly trains a ConvNet with two branches which maps an image of a human to both the 2D joint locations and the FBI of bones. These information is further fed into a deep regression network to predict the 3D positions of joints. To support the training, we also develop an annotation user interface and labeled such FBI for around 12K in-the-wild images which are randomly selected from MPII (a public dataset of 2D pose annotation). Our experimental results on the standard benchmarks demonstrate that our approach outperforms state-of-the-art methods both qualitatively and quantitatively.
Inferring Remote Channel State Information: Cramér-Rao Lower Bound and Deep Learning Implementation
Dec 04, 2018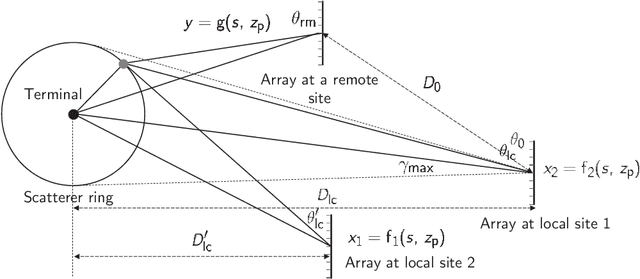
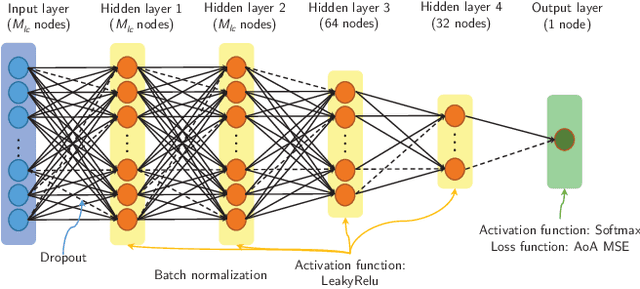
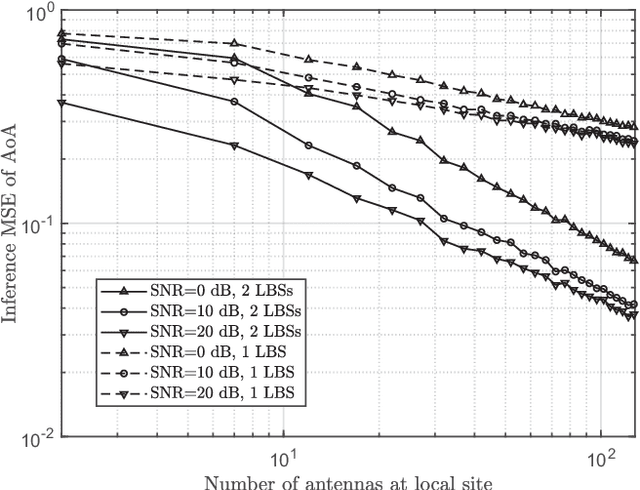
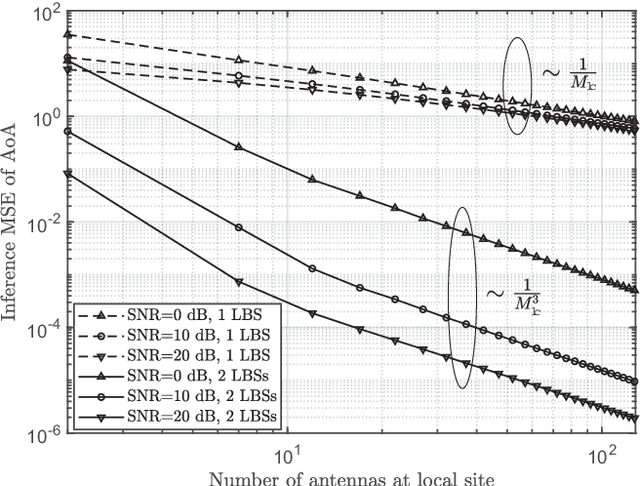
Channel state information (CSI) is of vital importance in wireless communication systems. Existing CSI acquisition methods usually rely on pilot transmissions, and geographically separated base stations (BSs) with non-correlated CSI need to be assigned with orthogonal pilots which occupy excessive system resources. Our previous work adopts a data-driven deep learning based approach which leverages the CSI at a local BS to infer the CSI remotely, however the relevance of CSI between separated BSs is not specified explicitly. In this paper, we exploit a model-based methodology to derive the Cram\'er-Rao lower bound (CRLB) of remote CSI inference given the local CSI. Although the model is simplified, the derived CRLB explicitly illustrates the relationship between the inference performance and several key system parameters, e.g., terminal distance and antenna array size. In particular, it shows that by leveraging multiple local BSs, the inference error exhibits a larger power-law decay rate (w.r.t. number of antennas), compared with a single local BS; this explains and validates our findings in evaluating the deep-neural-network-based (DNN-based) CSI inference. We further improve on the DNN-based method by employing dropout and deeper networks, and show an inference performance of approximately $90\%$ accuracy in a realistic scenario with CSI generated by a ray-tracing simulator.
Learning Domain Invariant Representations for Generalizable Person Re-Identification
Mar 29, 2021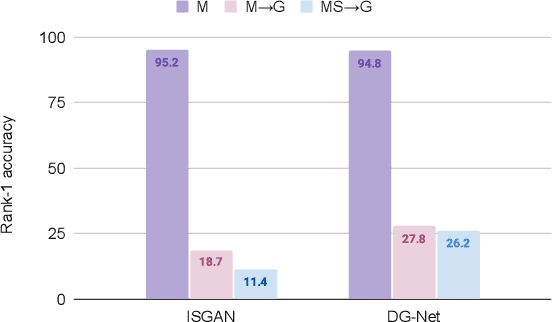
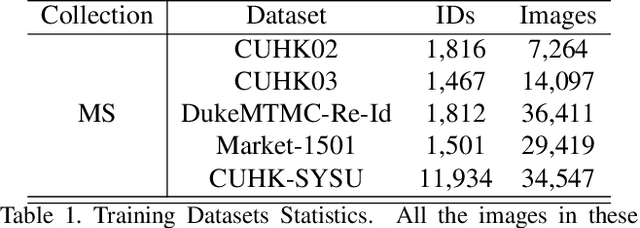
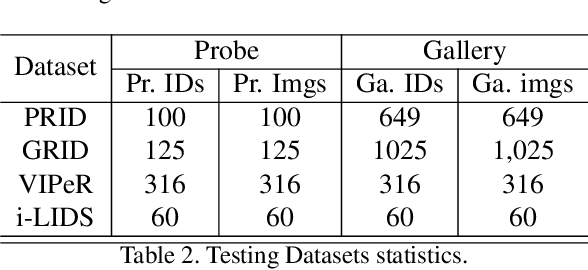
Generalizable person Re-Identification (ReID) has attracted growing attention in recent computer vision community, as it offers ready-to-use ReID models without the need for model retraining in new environments. In this work, we introduce causality into person ReID and propose a novel generalizable framework, named Domain Invariant Representations for generalizable person Re-Identification (DIR-ReID). We assume the data generation process is controlled by two sets of factors, i.e. identity-specific factors containing identity related cues, and domain-specific factors describing other scene-related information which cause distribution shifts across domains. With the assumption above, a novel Multi-Domain Disentangled Adversarial Network (MDDAN) is designed to disentangle these two sets of factors. Furthermore, a Causal Data Augmentation (CDA) block is proposed to perform feature-level data augmentation for better domain-invariant representations, which can be explained as interventions on latent factors from a causal learning perspective. Extensive experiments have been conducted, showing that DIR-ReID outperforms state-of-the-art methods on large-scale domain generalization (DG) ReID benchmarks. Moreover, a theoretical analysis is provided for a better understanding of our method.
Imagination-enabled Robot Perception
Nov 23, 2020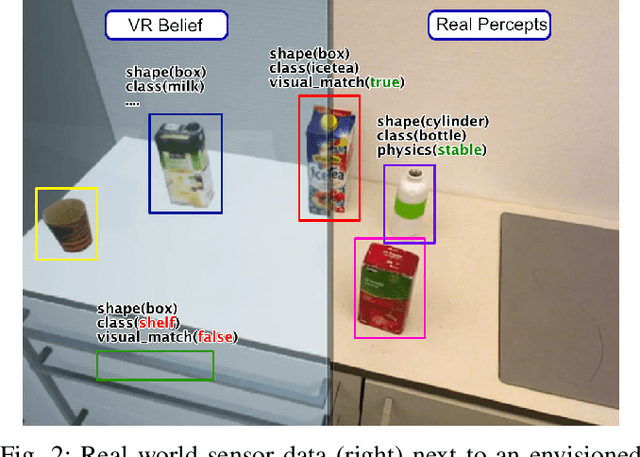
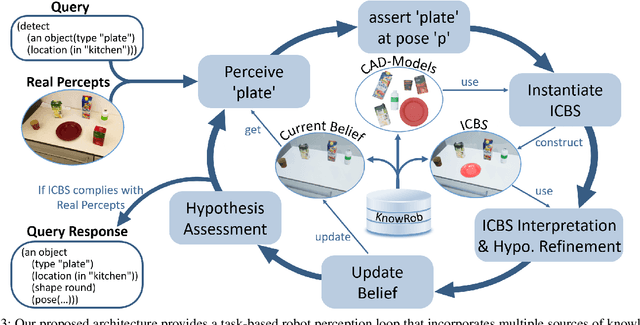
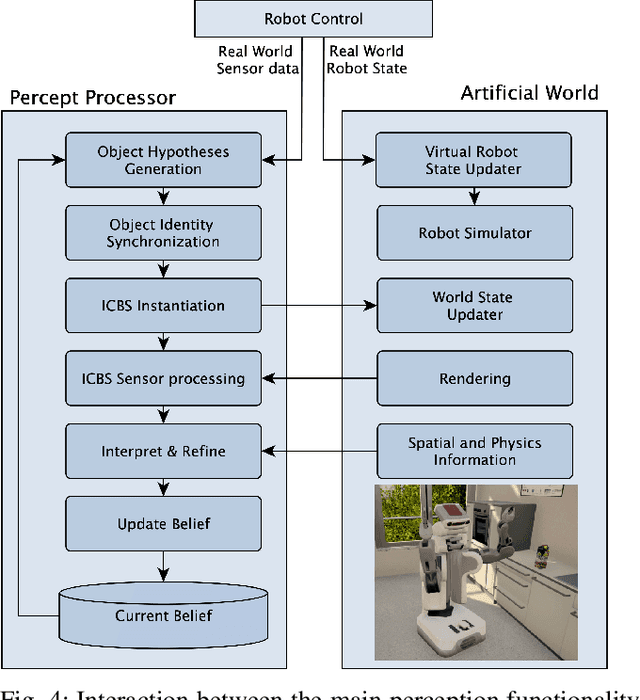
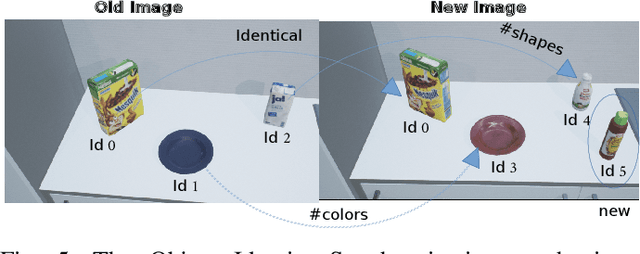
Many of today's robot perception systems aim at accomplishing perception tasks that are too simplistic and too hard. They are too simplistic because they do not require the perception systems to provide all the information needed to accomplish manipulation tasks. Typically the perception results do not include information about the part structure of objects, articulation mechanisms and other attributes needed for adapting manipulation behavior. On the other hand, the perception problems stated are also too hard because -- unlike humans -- the perception systems cannot leverage the expectations about what they will see to their full potential. Therefore, we investigate a variation of robot perception tasks suitable for robots accomplishing everyday manipulation tasks, such as household robots or a robot in a retail store. In such settings it is reasonable to assume that robots know most objects and have detailed models of them. We propose a perception system that maintains its beliefs about its environment as a scene graph with physics simulation and visual rendering. When detecting objects, the perception system retrieves the model of the object and places it at the corresponding place in a VR-based environment model. The physics simulation ensures that object detections that are physically not possible are rejected and scenes can be rendered to generate expectations at the image level. The result is a perception system that can provide useful information for manipulation tasks.
Improving Perceptual Quality by Phone-Fortified Perceptual Loss for Speech Enhancement
Oct 30, 2020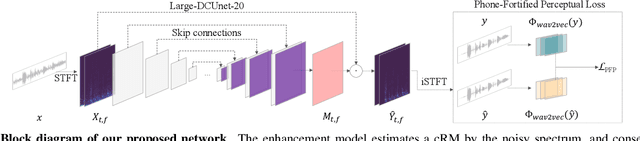
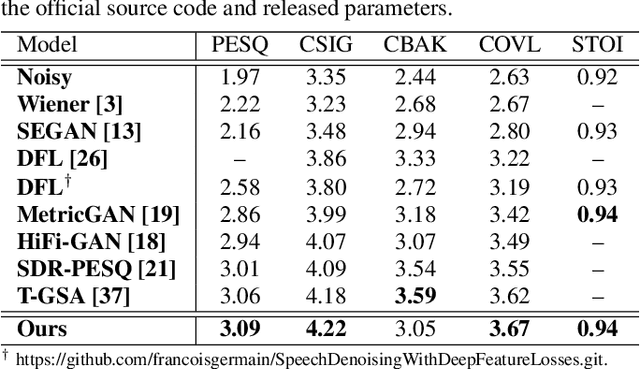
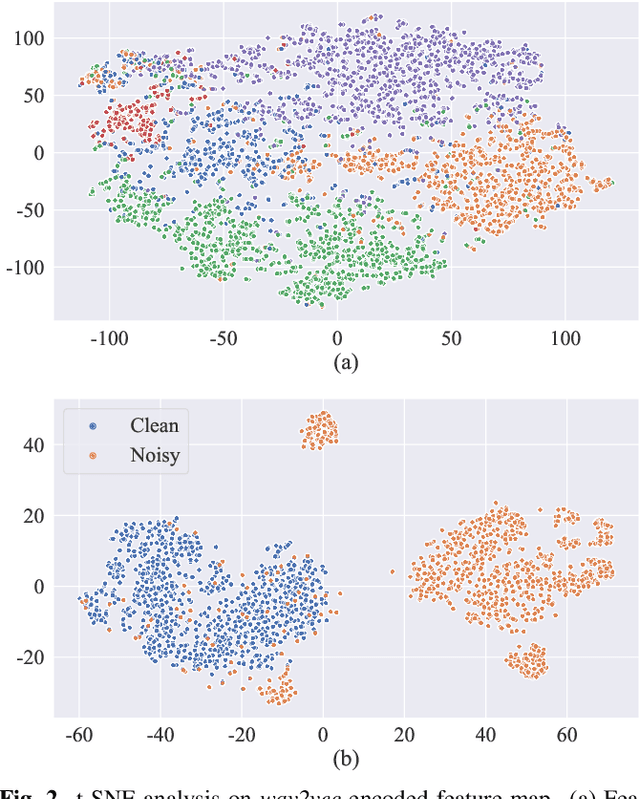
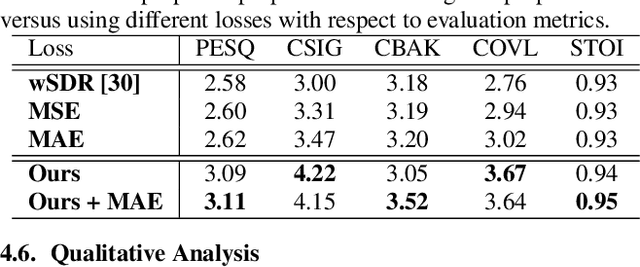
Speech enhancement (SE) aims to improve speech quality and intelligibility, which are both related to a smooth transition in speech segments that may carry linguistic information, e.g. phones and syllables. In this study, we took phonetic characteristics into account in the SE training process. Hence, we designed a phone-fortified perceptual (PFP) loss, and the training of our SE model was guided by PFP loss. In PFP loss, phonetic characteristics are extracted by wav2vec, an unsupervised learning model based on the contrastive predictive coding (CPC) criterion. Different from previous deep-feature-based approaches, the proposed approach explicitly uses the phonetic information in the deep feature extraction process to guide the SE model training. To test the proposed approach, we first confirmed that the wav2vec representations carried clear phonetic information using a t-distributed stochastic neighbor embedding (t-SNE) analysis. Next, we observed that the proposed PFP loss was more strongly correlated with the perceptual evaluation metrics than point-wise and signal-level losses, thus achieving higher scores for standardized quality and intelligibility evaluation metrics in the Voice Bank-DEMAND dataset.
Gaussian Process for Tomography
Mar 29, 2021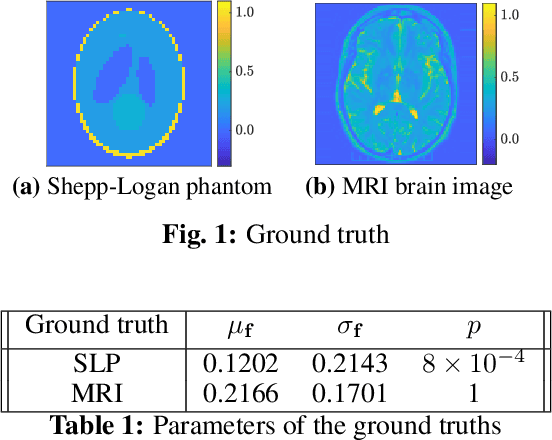
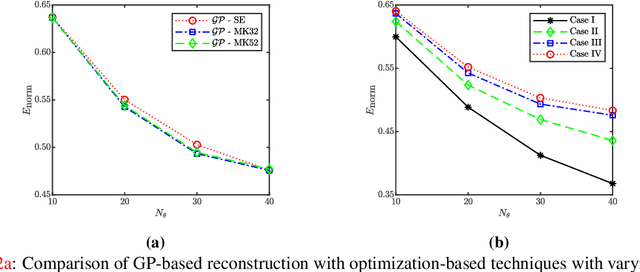
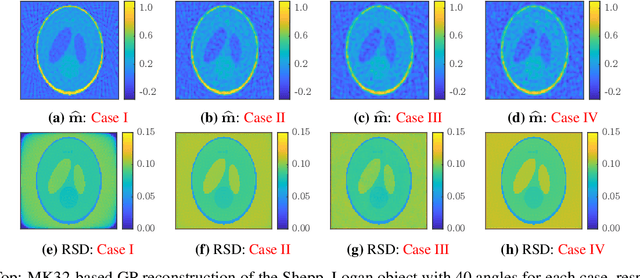
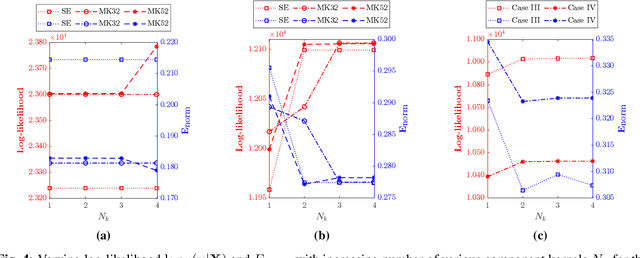
Tomographic reconstruction, despite its revolutionary impact on a wide range of applications, suffers from its ill-posed nature in that there is no unique solution because of limited and noisy measurements. Traditional optimization-based reconstruction relies on regularization to address this issue; however, it faces its own challenge because the type of regularizer and choice of regularization parameter are a critical but difficult decision. Moreover, traditional reconstruction yields point estimates for the reconstruction with no further indication of the quality of the solution. In this work we address these challenges by exploring Gaussian processes (GPs). Our proposed GP approach yields not only the reconstructed object through the posterior mean but also a quantification of the solution uncertainties through the posterior covariance. Furthermore, we explore the flexibility of the GP framework to provide a robust model of the information across various length scales in the object, as well as the complex noise in the measurements. We illustrate the proposed approach on both synthetic and real tomography images and show its unique capability of uncertainty quantification in the presence of various types of noise, as well as reconstruction comparison with existing methods.
Understanding Negations in Information Processing: Learning from Replicating Human Behavior
Apr 18, 2017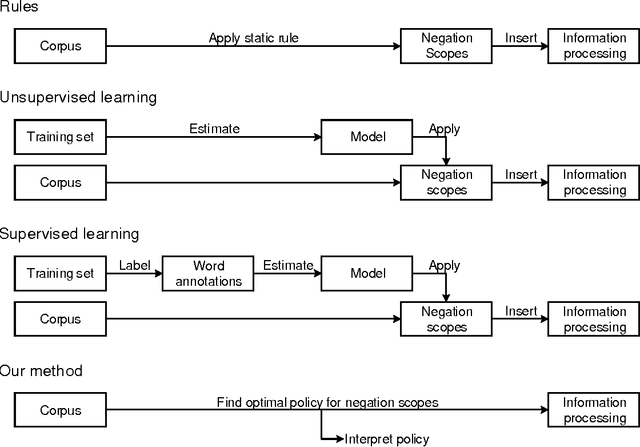

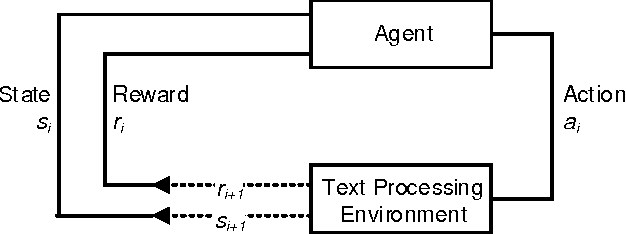

Information systems experience an ever-growing volume of unstructured data, particularly in the form of textual materials. This represents a rich source of information from which one can create value for people, organizations and businesses. For instance, recommender systems can benefit from automatically understanding preferences based on user reviews or social media. However, it is difficult for computer programs to correctly infer meaning from narrative content. One major challenge is negations that invert the interpretation of words and sentences. As a remedy, this paper proposes a novel learning strategy to detect negations: we apply reinforcement learning to find a policy that replicates the human perception of negations based on an exogenous response, such as a user rating for reviews. Our method yields several benefits, as it eliminates the former need for expensive and subjective manual labeling in an intermediate stage. Moreover, the inferred policy can be used to derive statistical inferences and implications regarding how humans process and act on negations.
Explainable AI For COVID-19 CT Classifiers: An Initial Comparison Study
Apr 25, 2021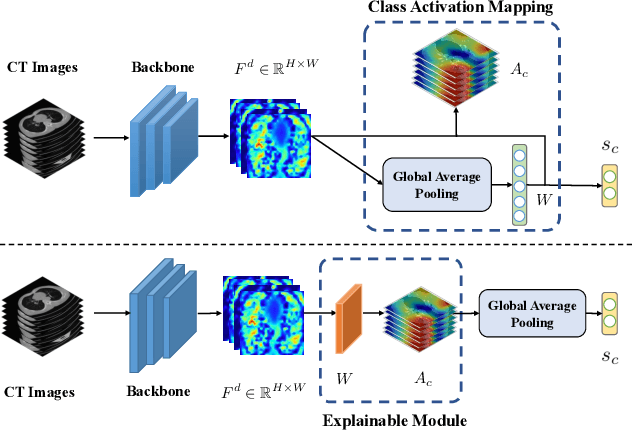
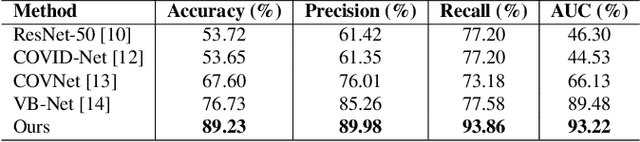
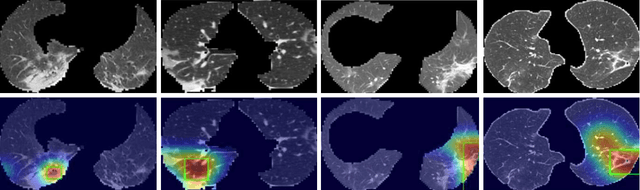
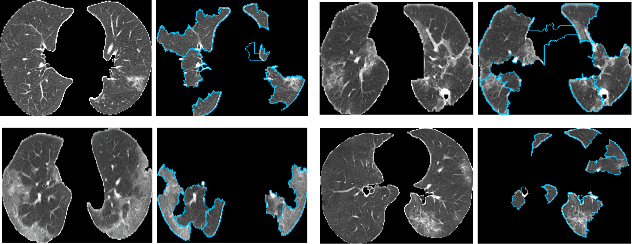
Artificial Intelligence (AI) has made leapfrogs in development across all the industrial sectors especially when deep learning has been introduced. Deep learning helps to learn the behaviour of an entity through methods of recognising and interpreting patterns. Despite its limitless potential, the mystery is how deep learning algorithms make a decision in the first place. Explainable AI (XAI) is the key to unlocking AI and the black-box for deep learning. XAI is an AI model that is programmed to explain its goals, logic, and decision making so that the end users can understand. The end users can be domain experts, regulatory agencies, managers and executive board members, data scientists, users that use AI, with or without awareness, or someone who is affected by the decisions of an AI model. Chest CT has emerged as a valuable tool for the clinical diagnostic and treatment management of the lung diseases associated with COVID-19. AI can support rapid evaluation of CT scans to differentiate COVID-19 findings from other lung diseases. However, how these AI tools or deep learning algorithms reach such a decision and which are the most influential features derived from these neural networks with typically deep layers are not clear. The aim of this study is to propose and develop XAI strategies for COVID-19 classification models with an investigation of comparison. The results demonstrate promising quantification and qualitative visualisations that can further enhance the clinician's understanding and decision making with more granular information from the results given by the learned XAI models.
Building a Parallel Universe Image Synthesis from Land Cover Maps and Auxiliary Raster Data
Nov 23, 2020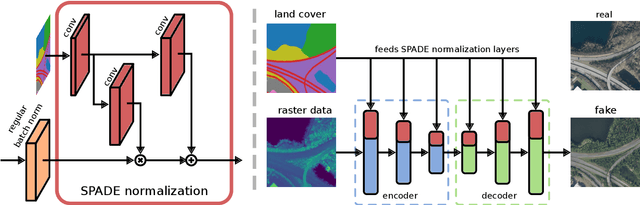


We synthesize both optical RGB and SAR remote sensing images from land cover maps and auxiliary raster data using GANs. In remote sensing many types of data, such as digital elevation models or precipitation maps, are often not reflected in land cover maps but still influence image content or structure. Including such data in the synthesis process increases the quality of the generated images and exerts more control on their characteristics. Our method fuses both inputs by spatially adaptive normalization layers, previously published as SPADE semantic image synthesis. In contrast to SPADE, these normalization layers are applied to a full-blown generator architecture consisting of encoder and decoder, to take full advantage of the information content in the auxiliary raster data. Our method successfully synthesizes medium (10m) and high (1m) resolution images, when trained with the corresponding dataset. We show the advantage of data fusion of land cover maps and auxiliary information using mean intersection over union, pixel accuracy and FID using pre-trained U-Net segmentation models. Handpicked images exemplify how fusing information avoids ambiguities in the synthesized images. By slightly editing the input our method can be used to synthesize realistic changes, i.e., raising the water levels. The source code is available at https://github.com/gbaier/rs_img_synth and we published the newly created high-resolution dataset at https://ieee-dataport.org/open-access/geonrw.