 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Utility of Multimodal Conversational Technology and Audiovisual Analytic Measures for the Assessment and Monitoring of Amyotrophic Lateral Sclerosis at Scale
Apr 15, 2021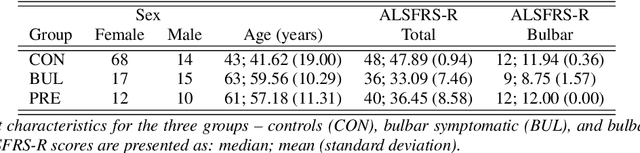
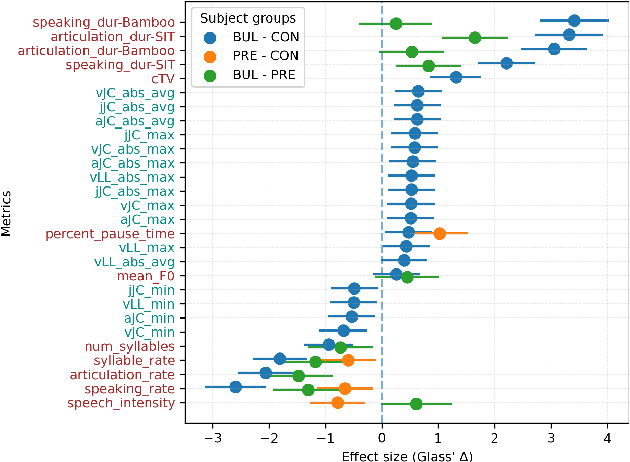

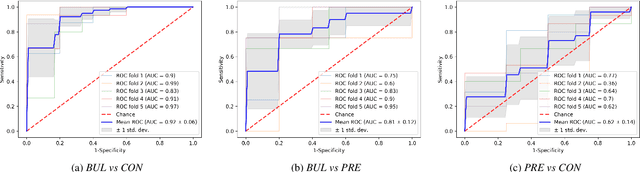
We propose a cloud-based multimodal dialog platform for the remote assessment and monitoring of Amyotrophic Lateral Sclerosis (ALS) at scale. This paper presents our vision, technology setup, and an initial investigation of the efficacy of the various acoustic and visual speech metrics automatically extracted by the platform. 82 healthy controls and 54 people with ALS (pALS) were instructed to interact with the platform and completed a battery of speaking tasks designed to probe the acoustic, articulatory, phonatory, and respiratory aspects of their speech. We find that multiple acoustic (rate, duration, voicing) and visual (higher order statistics of the jaw and lip) speech metrics show statistically significant differences between controls, bulbar symptomatic and bulbar pre-symptomatic patients. We report on the sensitivity and specificity of these metrics using five-fold cross-validation. We further conducted a LASSO-LARS regression analysis to uncover the relative contributions of various acoustic and visual features in predicting the severity of patients' ALS (as measured by their self-reported ALSFRS-R scores). Our results provide encouraging evidence of the utility of automatically extracted audiovisual analytics for scalable remote patient assessment and monitoring in ALS.
Investigations on Audiovisual Emotion Recognition in Noisy Conditions
Mar 02, 2021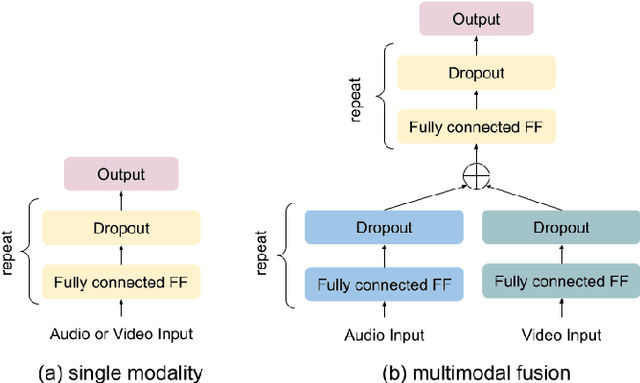

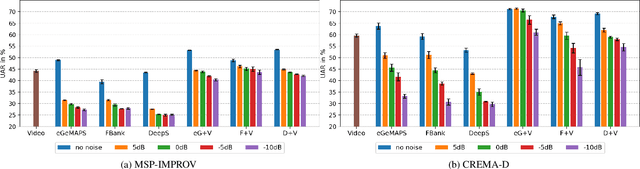
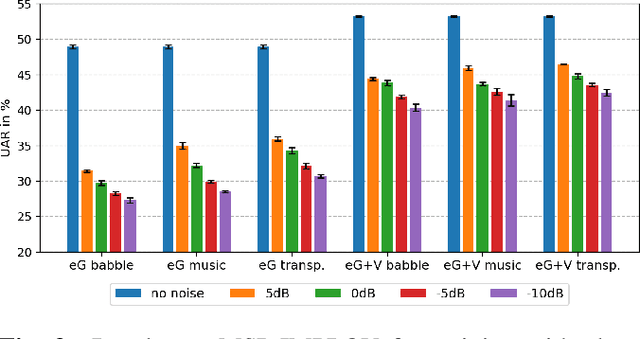
In this paper we explore audiovisual emotion recognition under noisy acoustic conditions with a focus on speech features. We attempt to answer the following research questions: (i) How does speech emotion recognition perform on noisy data? and (ii) To what extend does a multimodal approach improve the accuracy and compensate for potential performance degradation at different noise levels? We present an analytical investigation on two emotion datasets with superimposed noise at different signal-to-noise ratios, comparing three types of acoustic features. Visual features are incorporated with a hybrid fusion approach: The first neural network layers are separate modality-specific ones, followed by at least one shared layer before the final prediction. The results show a significant performance decrease when a model trained on clean audio is applied to noisy data and that the addition of visual features alleviates this effect.
URoboSim -- An Episodic Simulation Framework for Prospective Reasoning in Robotic Agents
Dec 08, 2020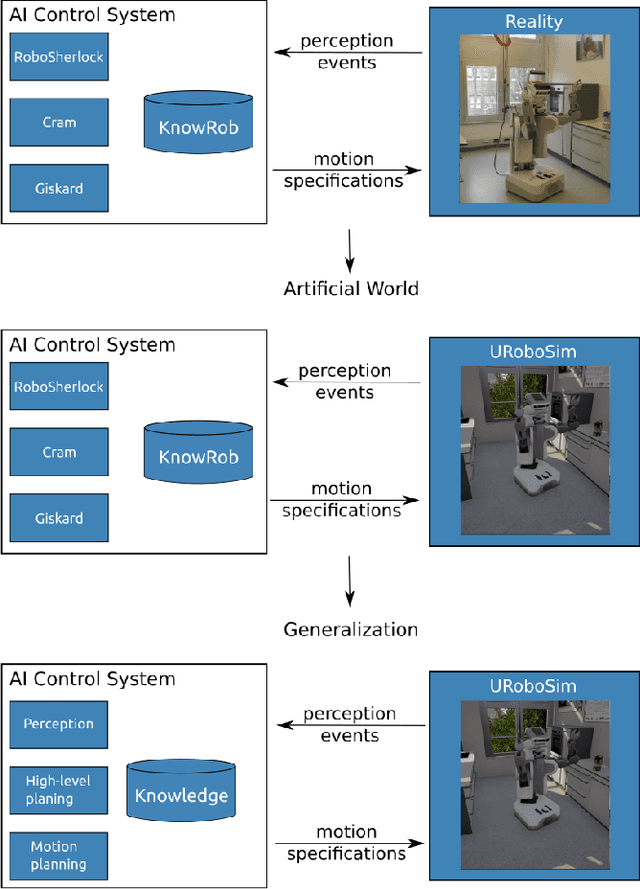

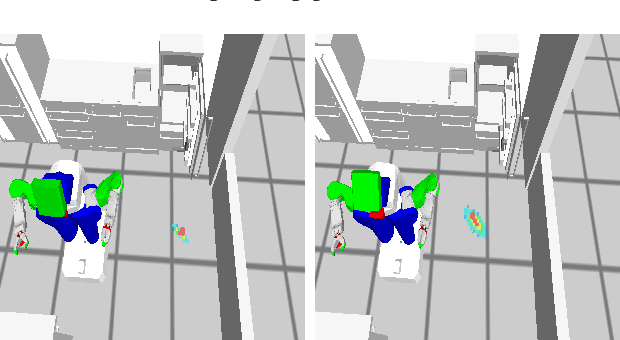
Anticipating what might happen as a result of an action is an essential ability humans have in order to perform tasks effectively. On the other hand, robots capabilities in this regard are quite lacking. While machine learning is used to increase the ability of prospection it is still limiting for novel situations. A possibility to improve the prospection ability of robots is through simulation of imagined motions and the physical results of these actions. Therefore, we present URoboSim, a robot simulator that allows robots to perform tasks as mental simulation before performing this task in reality. We show the capabilities of URoboSim in form of mental simulations, generating data for machine learning and the usage as belief state for a real robot.
Imagination-enabled Robot Perception
Nov 27, 2020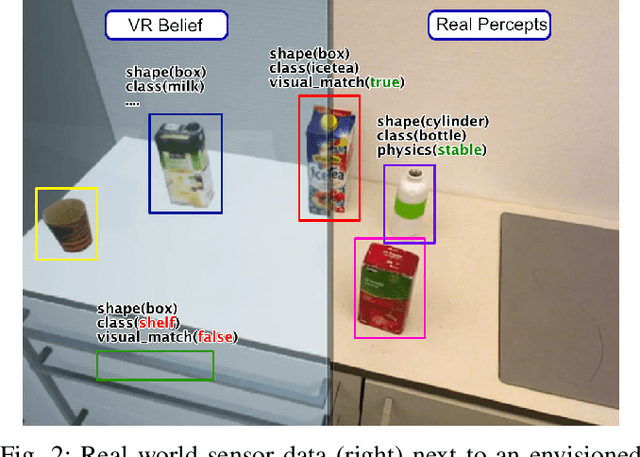
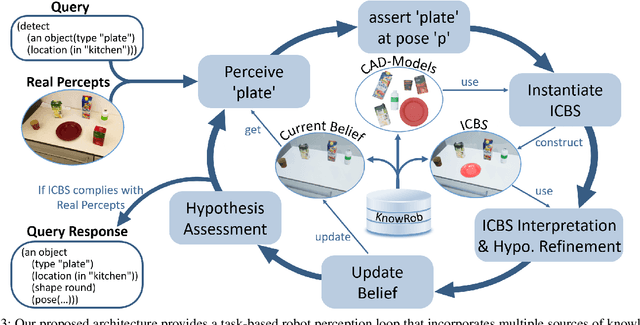
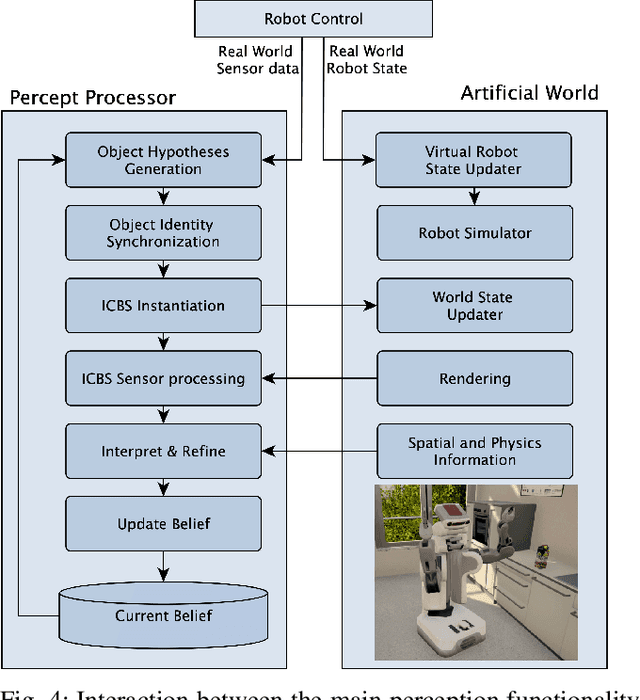
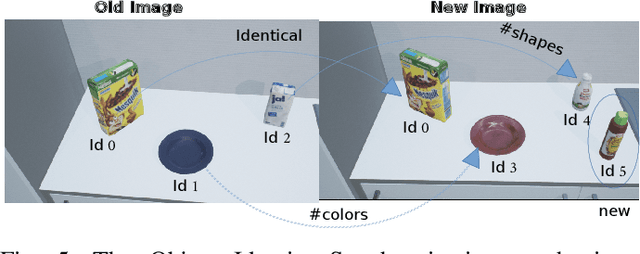
Many of today's robot perception systems aim at accomplishing perception tasks that are too simplistic and too hard. They are too simplistic because they do not require the perception systems to provide all the information needed to accomplish manipulation tasks. Typically the perception results do not include information about the part structure of objects, articulation mechanisms and other attributes needed for adapting manipulation behavior. On the other hand, the perception problems stated are also too hard because -- unlike humans -- the perception systems cannot leverage the expectations about what they will see to their full potential. Therefore, we investigate a variation of robot perception tasks suitable for robots accomplishing everyday manipulation tasks, such as household robots or a robot in a retail store. In such settings it is reasonable to assume that robots know most objects and have detailed models of them. We propose a perception system that maintains its beliefs about its environment as a scene graph with physics simulation and visual rendering. When detecting objects, the perception system retrieves the model of the object and places it at the corresponding place in a VR-based environment model. The physics simulation ensures that object detections that are physically not possible are rejected and scenes can be rendered to generate expectations at the image level. The result is a perception system that can provide useful information for manipulation tasks.
ADVISER: A Toolkit for Developing Multi-modal, Multi-domain and Socially-engaged Conversational Agents
May 04, 2020
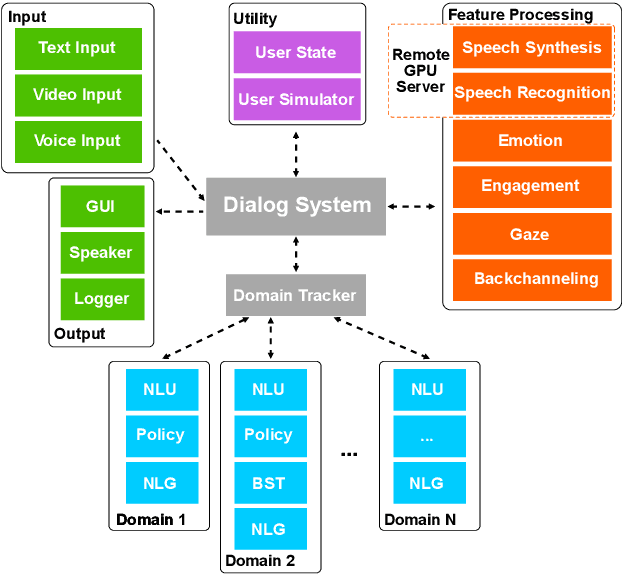
We present ADVISER - an open-source, multi-domain dialog system toolkit that enables the development of multi-modal (incorporating speech, text and vision), socially-engaged (e.g. emotion recognition, engagement level prediction and backchanneling) conversational agents. The final Python-based implementation of our toolkit is flexible, easy to use, and easy to extend not only for technically experienced users, such as machine learning researchers, but also for less technically experienced users, such as linguists or cognitive scientists, thereby providing a flexible platform for collaborative research. Link to open-source code: https://github.com/DigitalPhonetics/adviser
Cross-lingual and Multilingual Speech Emotion Recognition on English and French
Mar 01, 2018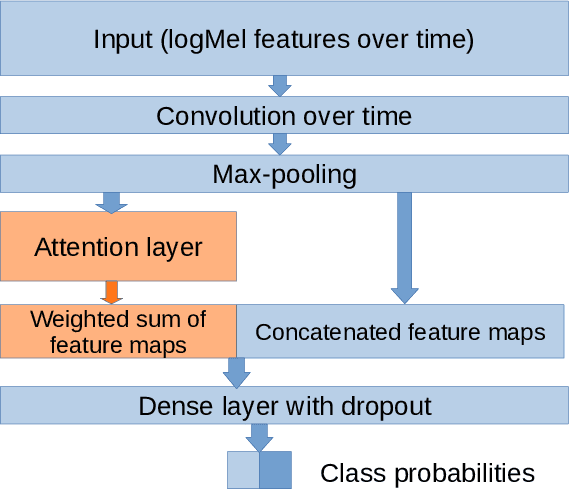
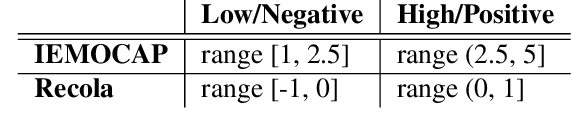
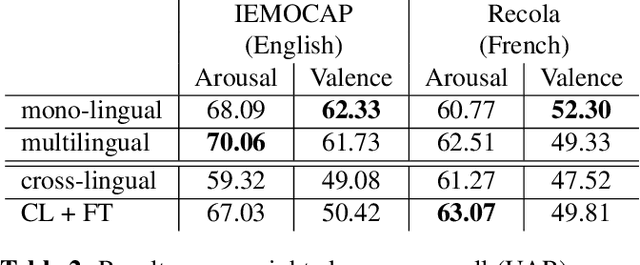
Research on multilingual speech emotion recognition faces the problem that most available speech corpora differ from each other in important ways, such as annotation methods or interaction scenarios. These inconsistencies complicate building a multilingual system. We present results for cross-lingual and multilingual emotion recognition on English and French speech data with similar characteristics in terms of interaction (human-human conversations). Further, we explore the possibility of fine-tuning a pre-trained cross-lingual model with only a small number of samples from the target language, which is of great interest for low-resource languages. To gain more insights in what is learned by the deployed convolutional neural network, we perform an analysis on the attention mechanism inside the network.
Attentive Convolutional Neural Network based Speech Emotion Recognition: A Study on the Impact of Input Features, Signal Length, and Acted Speech
Jun 02, 2017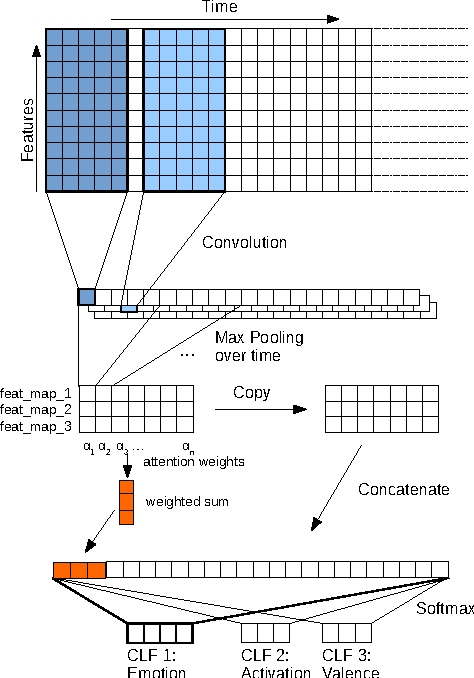
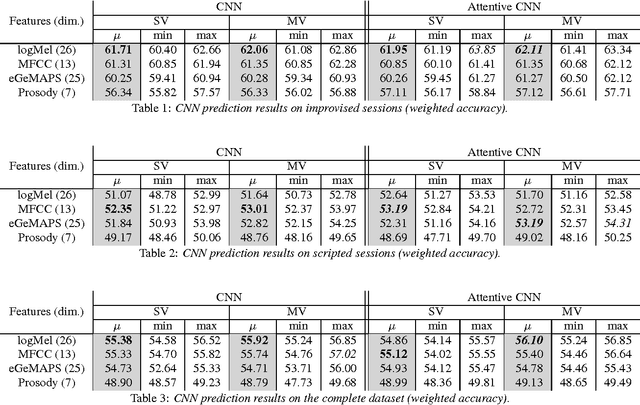
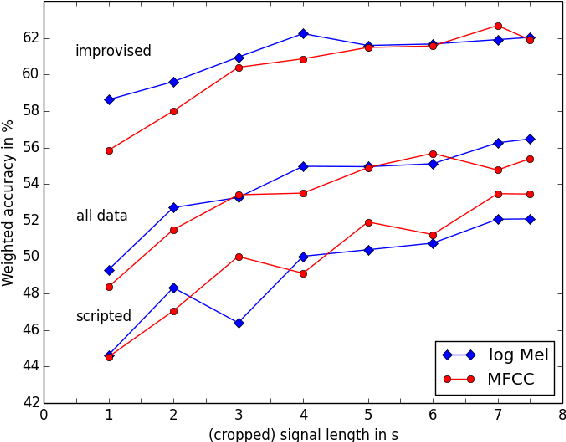
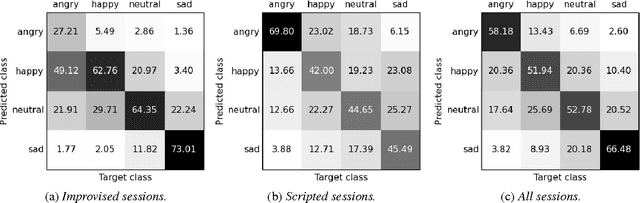
Speech emotion recognition is an important and challenging task in the realm of human-computer interaction. Prior work proposed a variety of models and feature sets for training a system. In this work, we conduct extensive experiments using an attentive convolutional neural network with multi-view learning objective function. We compare system performance using different lengths of the input signal, different types of acoustic features and different types of emotion speech (improvised/scripted). Our experimental results on the Interactive Emotional Motion Capture (IEMOCAP) database reveal that the recognition performance strongly depends on the type of speech data independent of the choice of input features. Furthermore, we achieved state-of-the-art results on the improvised speech data of IEMOCAP.