 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell2Adapt: A Unified Framework for Source Free Unsupervised Domain Adaptation via Vision Foundation Model
Mar 05, 2026Source Free Unsupervised Domain Adaptation (SFUDA) is critical for deploying deep learning models across diverse clinical settings. However, existing methods are typically designed for low-gap, specific domain shifts and cannot generalize into a unified, multi-modalities, and multi-target framework, which presents a major barrier to real-world application. To overcome this issue, we introduce Tell2Adapt, a novel SFUDA framework that harnesses the vast, generalizable knowledge of the Vision Foundation Model (VFM). Our approach ensures high-fidelity VFM prompts through Context-Aware Prompts Regularization (CAPR), which robustly translates varied text prompts into canonical instructions. This enables the generation of high-quality pseudo-labels for efficiently adapting the lightweight student model to target domain. To guarantee clinical reliability, the framework incorporates Visual Plausibility Refinement (VPR), which leverages the VFM's anatomical knowledge to re-ground the adapted model's predictions in target image's low-level visual features, effectively removing noise and false positives. We conduct one of the most extensive SFUDA evaluations to date, validating our framework across 10 domain adaptation directions and 22 anatomical targets, including brain, cardiac, polyp, and abdominal targets. Our results demonstrate that Tell2Adapt consistently outperforms existing approaches, achieving SOTA for a unified SFUDA framework in medical image segmentation. Code are avaliable at https://github.com/derekshiii/Tell2Adapt.
FViT: A Focal Vision Transformer with Gabor Filter
Feb 27, 2024Vision transformers have achieved encouraging progress in various computer vision tasks. A common belief is that this is attributed to the competence of self-attention in modeling the global dependencies among feature tokens. Unfortunately, self-attention still faces some challenges in dense prediction tasks, such as the high computational complexity and absence of desirable inductive bias. To address these issues, we revisit the potential benefits of integrating vision transformer with Gabor filter, and propose a Learnable Gabor Filter (LGF) by using convolution. As an alternative to self-attention, we employ LGF to simulate the response of simple cells in the biological visual system to input images, prompting models to focus on discriminative feature representations of targets from various scales and orientations. Additionally, we design a Bionic Focal Vision (BFV) block based on the LGF. This block draws inspiration from neuroscience and introduces a Multi-Path Feed Forward Network (MPFFN) to emulate the working way of biological visual cortex processing information in parallel. Furthermore, we develop a unified and efficient pyramid backbone network family called Focal Vision Transformers (FViTs) by stacking BFV blocks. Experimental results show that FViTs exhibit highly competitive performance in various vision tasks. Especially in terms of computational efficiency and scalability, FViTs show significant advantages compared with other counterparts. Code is available at https://github.com/nkusyl/FViT
EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention
Oct 22, 2023



Thanks to the advancement of deep learning technology, vision transformer has demonstrated competitive performance in various computer vision tasks. Unfortunately, vision transformer still faces some challenges such as high computational complexity and absence of desirable inductive bias. To alleviate these problems, a novel Bi-Fovea Self-Attention (BFSA) is proposed, inspired by the physiological structure and characteristics of bi-fovea vision in eagle eyes. This BFSA can simulate the shallow fovea and deep fovea functions of eagle vision, enable the network to extract feature representations of targets from coarse to fine, facilitate the interaction of multi-scale feature representations. Additionally, a Bionic Eagle Vision (BEV) block based on BFSA is designed in this study. It combines the advantages of CNNs and Vision Transformers to enhance the ability of global and local feature representations of networks. Furthermore, a unified and efficient general pyramid backbone network family is developed by stacking the BEV blocks in this study, called Eagle Vision Transformers (EViTs). Experimental results on various computer vision tasks including image classification, object detection, instance segmentation and other transfer learning tasks show that the proposed EViTs perform effectively by comparing with the baselines under same model size and exhibit higher speed on graphics processing unit than other models. Code is available at https://github.com/nkusyl/EViT.
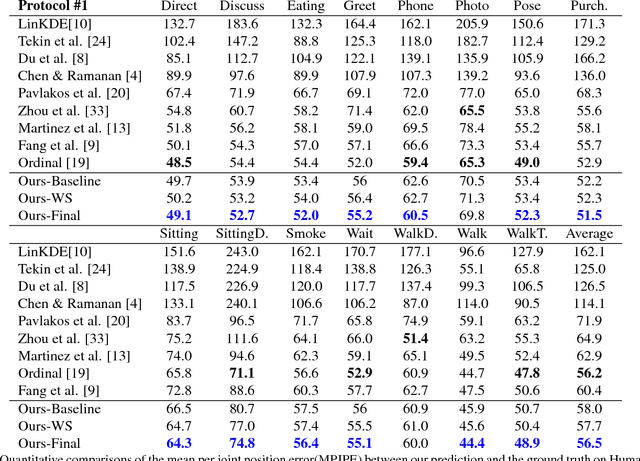
Adversarial 3D Human Pose Estimation via Multimodal Depth Supervision
Sep 21, 2018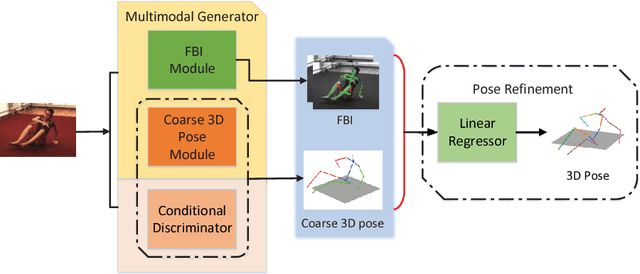

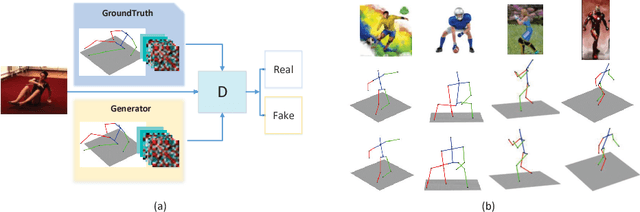
In this paper, a novel deep-learning based framework is proposed to infer 3D human poses from a single image. Specifically, a two-phase approach is developed. We firstly utilize a generator with two branches for the extraction of explicit and implicit depth information respectively. During the training process, an adversarial scheme is also employed to further improve the performance. The implicit and explicit depth information with the estimated 2D joints generated by a widely used estimator, in the second step, are together fed into a deep 3D pose regressor for the final pose generation. Our method achieves MPJPE of 58.68mm on the ECCV2018 3D Human Pose Estimation Challenge.
FBI-Pose: Towards Bridging the Gap between 2D Images and 3D Human Poses using Forward-or-Backward Information
Jun 25, 2018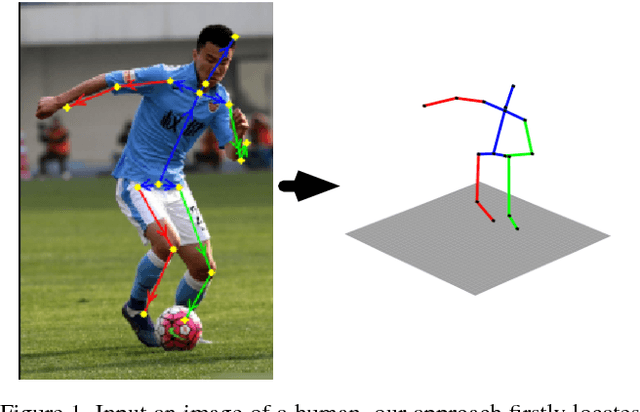
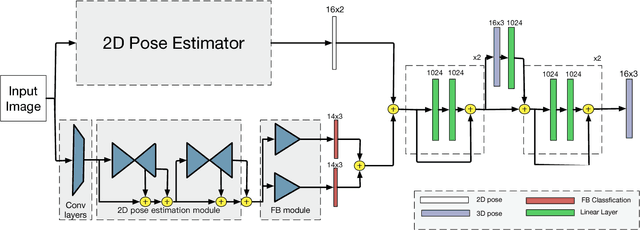
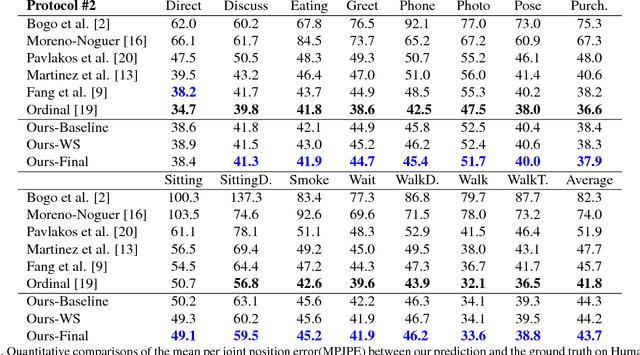
Although significant advances have been made in the area of human poses estimation from images using deep Convolutional Neural Network (ConvNet), it remains a big challenge to perform 3D pose inference in-the-wild. This is due to the difficulty to obtain 3D pose groundtruth for outdoor environments. In this paper, we propose a novel framework to tackle this problem by exploiting the information of each bone indicating if it is forward or backward with respect to the view of the camera(we term it Forwardor-Backward Information abbreviated as FBI). Our method firstly trains a ConvNet with two branches which maps an image of a human to both the 2D joint locations and the FBI of bones. These information is further fed into a deep regression network to predict the 3D positions of joints. To support the training, we also develop an annotation user interface and labeled such FBI for around 12K in-the-wild images which are randomly selected from MPII (a public dataset of 2D pose annotation). Our experimental results on the standard benchmarks demonstrate that our approach outperforms state-of-the-art methods both qualitatively and quantitatively.