 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGPP: Trajectory-Guided Plug-and-Play Priors for Sparse Radio Map Reconstruction
May 07, 2026Radio map (RM) reconstruction is essential for environment-aware wireless networks, but practical measurements are often collected along mobility trajectories rather than randomly scattered over the target region. Such trajectory-sampled observations induce spatially heterogeneous uncertainty: near-trajectory regions are directly constrained, whereas distant or occluded regions remain weakly observed, leading to degraded reconstruction accuracy in under-constrained areas. To address this problem, we propose Trajectory-Guided Plug-and-Play Priors (TGPP), a general guidance module for sparse RM reconstruction. TGPP learns an explicit guidance map as an interpretable input-space risk prior, and an implicit guide feature that is projected and fused with backbone hidden representations. TGPP can be attached to different reconstruction backbones without changing their original task formulation. We further introduce RadioFlow-LDM, a latent flow-based generative backbone, and apply TGPP to deterministic, adversarial, graph-based, and latent generative reconstruction models. Experiments on RadioMapSeer with five trajectory sampling rates show that trajectory-sampled reconstruction differs substantially from random sparse interpolation. TGPP improves most reconstruction metrics across backbones, achieving up to 43.1% NMSE reduction relative to the corresponding base backbone without trajectory-guided priors.
LLM-as-Judge Framework for Evaluating Tone-Induced Hallucination in Vision-Language Models
Apr 22, 2026Vision-Language Models (VLMs) are increasingly deployed in settings where reliable visual grounding carries operational consequences, yet their behavior under progressively coercive prompt phrasing remains undercharacterized. Existing hallucination benchmarks predominantly rely on neutral prompts and binary detection, leaving open how both the incidence and the intensity of fabrication respond to graded linguistic pressure across structurally distinct task types. We present Ghost-100, a procedurally constructed benchmark of 800 synthetically generated images spanning eight categories across three task families: text-illegibility, time-reading, and object-absence, each designed under a negative-ground-truth principle that guarantees the queried target is absent, illegible, or indeterminate by construction. Every image is paired with five prompts drawn from a structured 5-Level Prompt Intensity Framework, holding the image and task identity fixed while varying only directive force, so that tone is isolated as the sole independent variable. We adopt a dual-track evaluation protocol: a rule-based H-Rate measuring the proportion of responses in which a model crosses from grounded refusal into unsupported positive commitment, and a GPT-4o-mini-judged H-Score on a 1-5 scale characterizing the confidence and specificity of fabrication once it occurs. We additionally release a three-stage automated validation workflow, which retrospectively confirms 717 of 800 images as strictly compliant. Evaluating nine open-weight VLMs, we find that H-Rate and H-Score dissociate substantially across model families, reading-style and presence-detection subsets respond to prompt pressure in qualitatively different ways, and several models exhibit non-monotonic sensitivity peaking at intermediate tone levels: patterns that aggregate metrics obscure.
Tone Matters: The Impact of Linguistic Tone on Hallucination in VLMs
Jan 10, 2026Vision-Language Models (VLMs) are increasingly used in safety-critical applications that require reliable visual grounding. However, these models often hallucinate details that are not present in the image to satisfy user prompts. While recent datasets and benchmarks have been introduced to evaluate systematic hallucinations in VLMs, many hallucination behaviors remain insufficiently characterized. In particular, prior work primarily focuses on object presence or absence, leaving it unclear how prompt phrasing and structural constraints can systematically induce hallucinations. In this paper, we investigate how different forms of prompt pressure influence hallucination behavior. We introduce Ghost-100, a procedurally generated dataset of synthetic scenes in which key visual details are deliberately removed, enabling controlled analysis of absence-based hallucinations. Using a structured 5-Level Prompt Intensity Framework, we vary prompts from neutral queries to toxic demands and rigid formatting constraints. We evaluate three representative open-weight VLMs: MiniCPM-V 2.6-8B, Qwen2-VL-7B, and Qwen3-VL-8B. Across all three models, hallucination rates do not increase monotonically with prompt intensity. All models exhibit reductions at higher intensity levels at different thresholds, though not all show sustained reduction under maximum coercion. These results suggest that current safety alignment is more effective at detecting semantic hostility than structural coercion, revealing model-specific limitations in handling compliance pressure. Our dataset is available at: https://github.com/bli1/tone-matters
Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
A Hierarchical Dataflow-Driven Heterogeneous Architecture for Wireless Baseband Processing
Feb 28, 2024Wireless baseband processing (WBP) is a key element of wireless communications, with a series of signal processing modules to improve data throughput and counter channel fading. Conventional hardware solutions, such as digital signal processors (DSPs) and more recently, graphic processing units (GPUs), provide various degrees of parallelism, yet they both fail to take into account the cyclical and consecutive character of WBP. Furthermore, the large amount of data in WBPs cannot be processed quickly in symmetric multiprocessors (SMPs) due to the unpredictability of memory latency. To address this issue, we propose a hierarchical dataflow-driven architecture to accelerate WBP. A pack-and-ship approach is presented under a non-uniform memory access (NUMA) architecture to allow the subordinate tiles to operate in a bundled access and execute manner. We also propose a multi-level dataflow model and the related scheduling scheme to manage and allocate the heterogeneous hardware resources. Experiment results demonstrate that our prototype achieves $2\times$ and $2.3\times$ speedup in terms of normalized throughput and single-tile clock cycles compared with GPU and DSP counterparts in several critical WBP benchmarks. Additionally, a link-level throughput of $288$ Mbps can be achieved with a $45$-core configuration.
A Hard and Soft Hybrid Slicing Framework for Service Level Agreement Guarantee via Deep Reinforcement Learning
Mar 06, 2022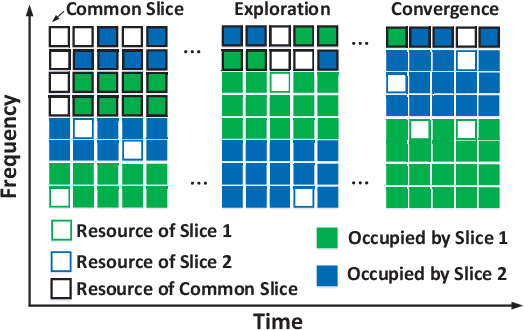
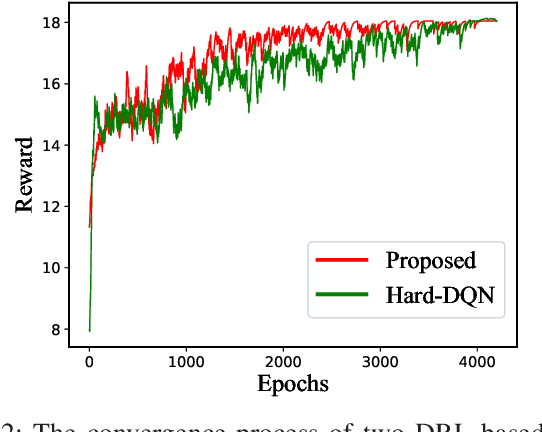
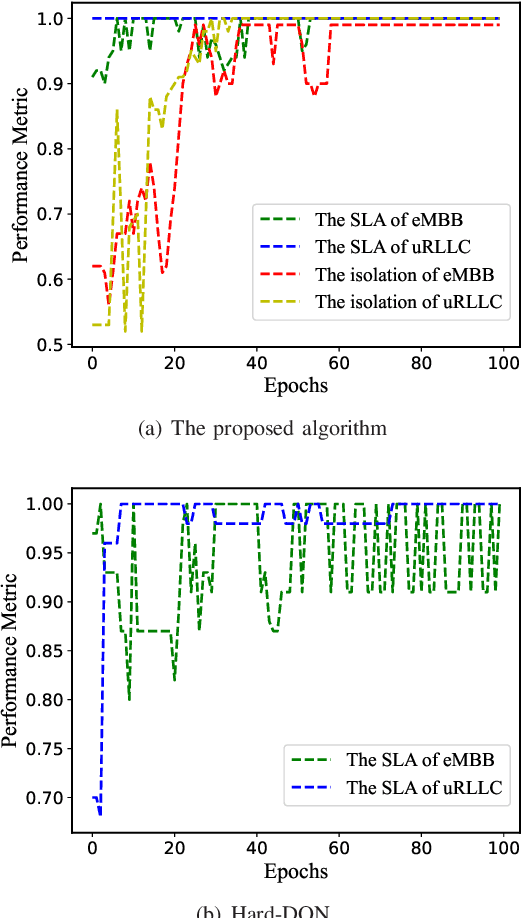
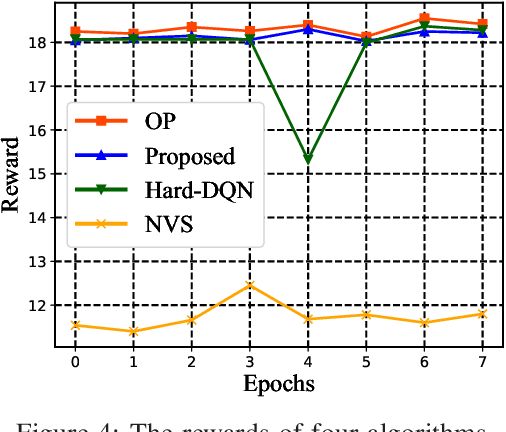
Network slicing is a critical driver for guaranteeing the diverse service level agreements (SLA) in 5G and future networks. Recently, deep reinforcement learning (DRL) has been widely utilized for resource allocation in network slicing. However, existing related works do not consider the performance loss associated with the initial exploration phase of DRL. This paper proposes a new performance-guaranteed slicing strategy with a soft and hard hybrid slicing setting. Mainly, a common slice setting is applied to guarantee slices' SLA when training the neural network. Moreover, the resource of the common slice tends to precisely redistribute to slices with the training of DRL until it converges. Furthermore, experiment results confirm the effectiveness of our proposed slicing framework: the slices' SLA of the training phase can be guaranteed, and the proposed algorithm can achieve the near-optimal performance in terms of the SLA satisfaction ratio, isolation degree and spectrum maximization after convergence.
Deep Reinforcement Learning-Based Beam Tracking for Low-Latency Services in Vehicular Networks
Feb 13, 2020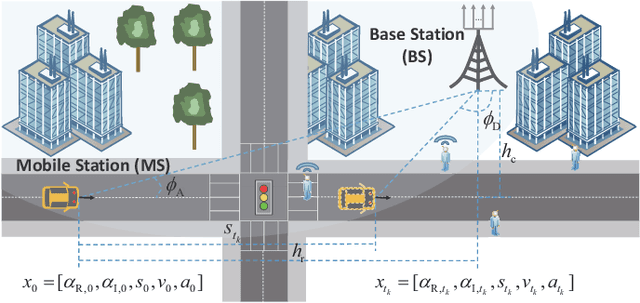
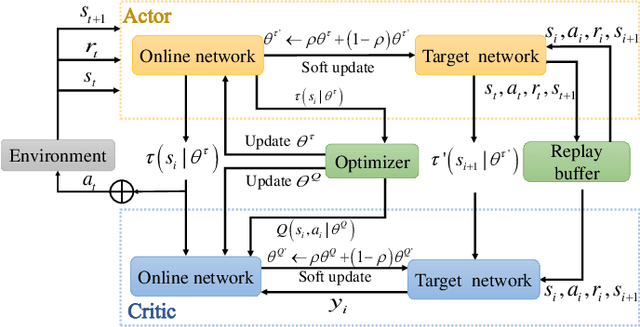
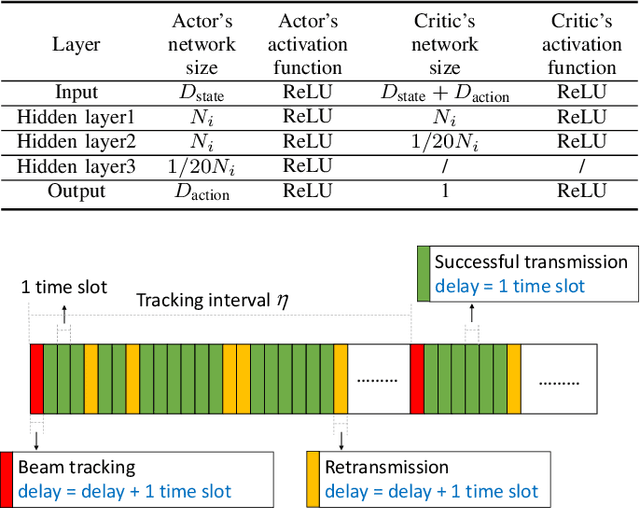
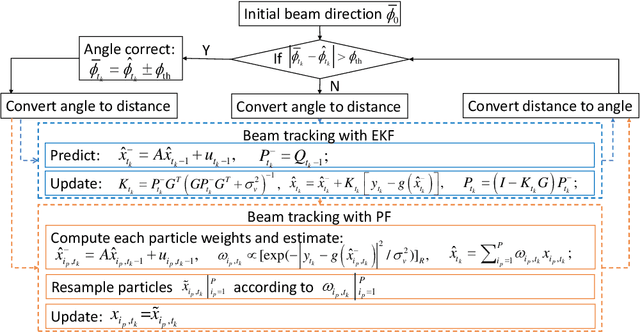
Ultra-Reliable and Low-Latency Communications (URLLC) services in vehicular networks on millimeter-wave bands present a significant challenge, considering the necessity of constantly adjusting the beam directions. Conventional methods are mostly based on classical control theory, e.g., Kalman filter and its variations, which mainly deal with stationary scenarios. Therefore, severe application limitations exist, especially with complicated, dynamic Vehicle-to-Everything (V2X) channels. This paper gives a thorough study of this subject, by first modifying the classical approaches, e.g., Extended Kalman Filter (EKF) and Particle Filter (PF), for non-stationary scenarios, and then proposing a Reinforcement Learning (RL)-based approach that can achieve the URLLC requirements in a typical intersection scenario. Simulation results based on a commercial ray-tracing simulator show that enhanced EKF and PF methods achieve packet delay more than $10$ ms, whereas the proposed deep RL-based method can reduce the latency to about $6$ ms, by extracting context information from the training data.
Distributed Policy Learning Based Random Access for Diversified QoS Requirements
Mar 06, 2019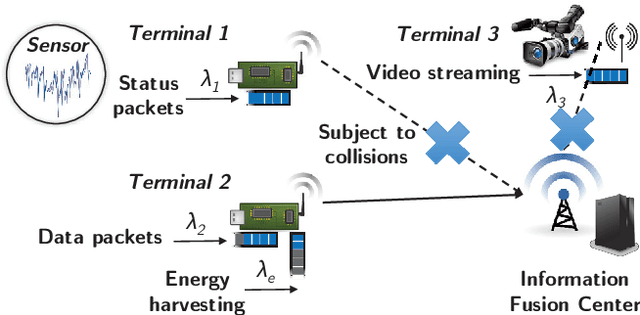
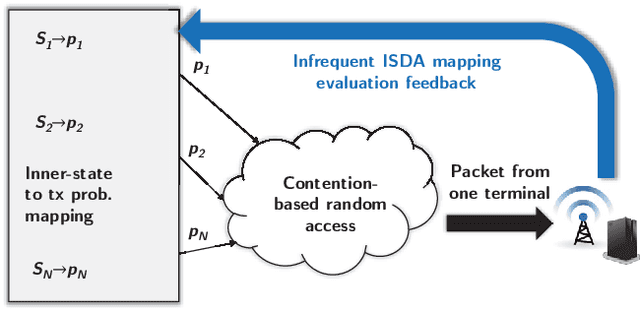
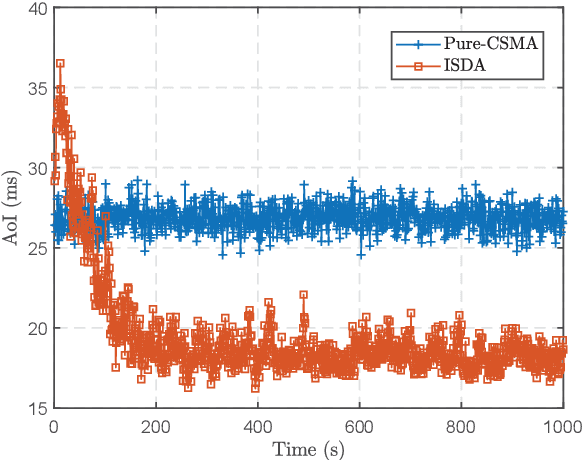
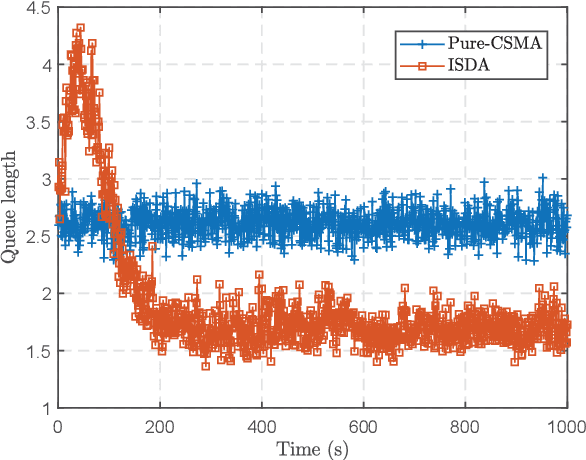
Future wireless access networks need to support diversified quality of service (QoS) metrics required by various types of Internet-of-Things (IoT) devices, e.g., age of information (AoI) for status generating sources and ultra low latency for safety information in vehicular networks. In this paper, a novel inner-state driven random access (ISDA) framework is proposed based on distributed policy learning, in particular a cross-entropy method. Conventional random access schemes, e.g., $p$-CSMA, assume state-less terminals, and thus assigning equal priorities to all. In ISDA, the inner-states of terminals are described by a time-varying state vector, and the transmission probabilities of terminals in the contention period are determined by their respective inner-states. Neural networks are leveraged to approximate the function mappings from inner-states to transmission probabilities, and an iterative approach is adopted to improve these mappings in a distributed manner. Experiment results show that ISDA can improve the QoS of heterogeneous terminals simultaneously compared to conventional CSMA schemes.
A Two-Step Learning and Interpolation Method for Location-Based Channel Database
Dec 04, 2018
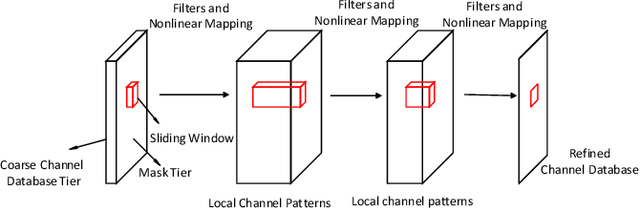

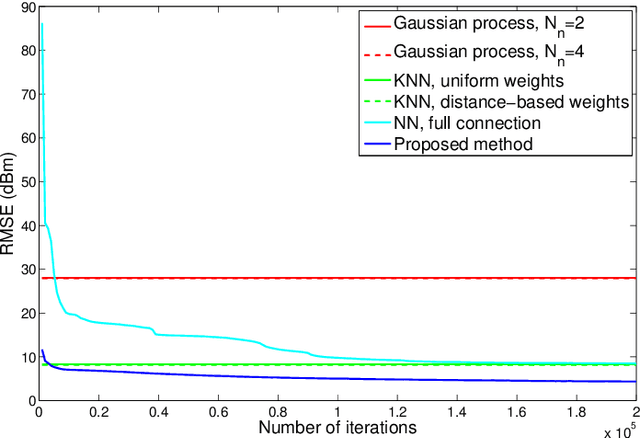
Timely and accurate knowledge of channel state information (CSI) is necessary to support scheduling operations at both physical and network layers. In order to support pilot-free channel estimation in cell sleeping scenarios, we propose to adopt a channel database that stores the CSI as a function of geographic locations. Such a channel database is generated from historical user records, which usually can not cover all the locations in the cell. Therefore, we develop a two-step interpolation method to infer the channels at the uncovered locations. The method firstly applies the K-nearest-neighbor method to form a coarse database and then refines it with a deep convolutional neural network. When applied to the channel data generated by ray tracing software, our method shows a great advantage in performance over the conventional interpolation methods.