 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
W2WNet: a two-module probabilistic Convolutional Neural Network with embedded data cleansing functionality
Mar 24, 2021
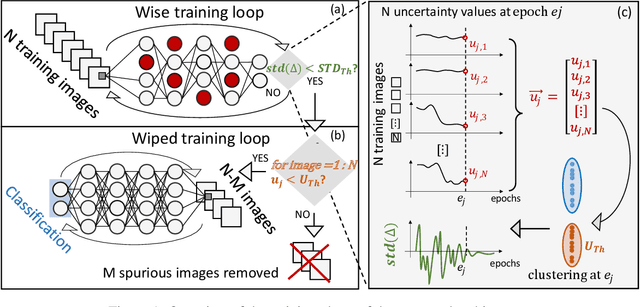
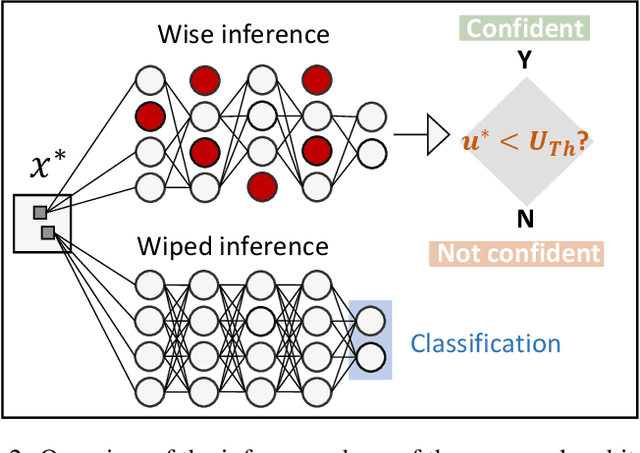
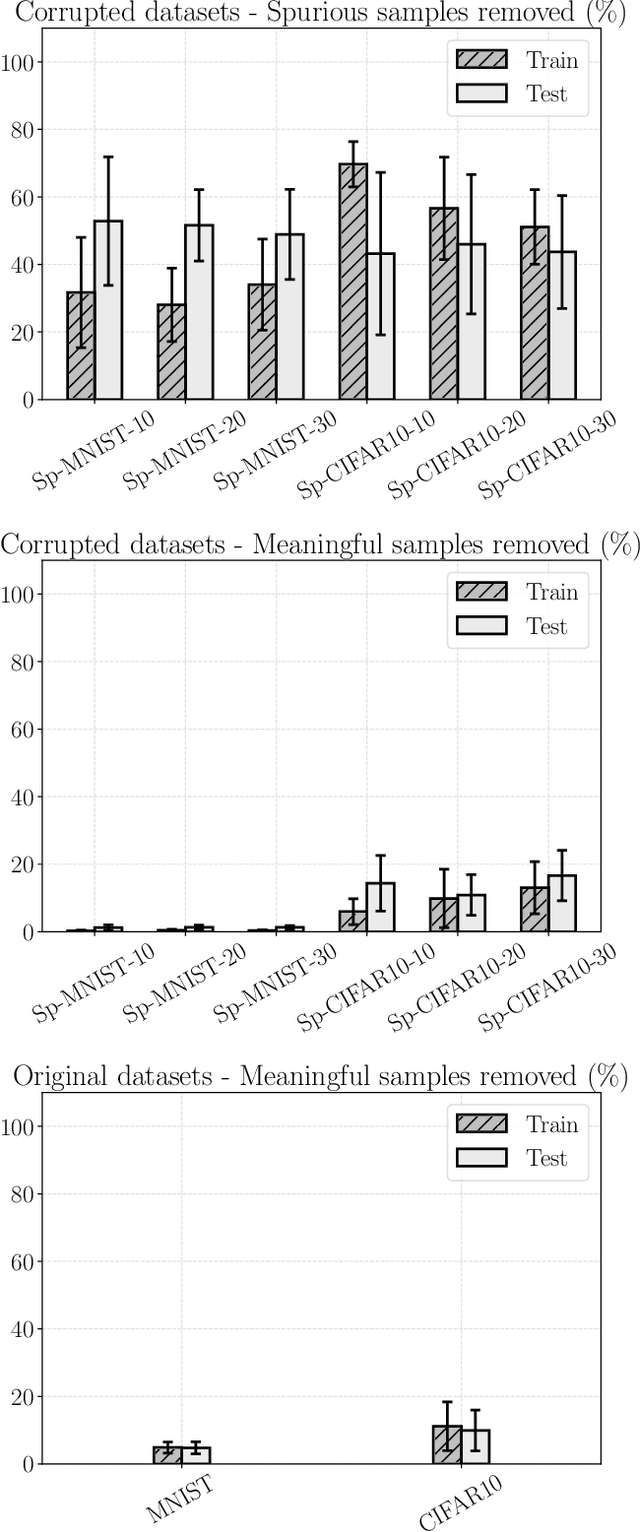
Convolutional Neural Networks (CNNs) are supposed to be fed with only high-quality annotated datasets. Nonetheless, in many real-world scenarios, such high quality is very hard to obtain, and datasets may be affected by any sort of image degradation and mislabelling issues. This negatively impacts the performance of standard CNNs, both during the training and the inference phase. To address this issue we propose Wise2WipedNet (W2WNet), a new two-module Convolutional Neural Network, where a Wise module exploits Bayesian inference to identify and discard spurious images during the training, and a Wiped module takes care of the final classification while broadcasting information on the prediction confidence at inference time. The goodness of our solution is demonstrated on a number of public benchmarks addressing different image classification tasks, as well as on a real-world case study on histological image analysis. Overall, our experiments demonstrate that W2WNet is able to identify image degradation and mislabelling issues both at training and at inference time, with a positive impact on the final classification accuracy.
Greedy-Based Feature Selection for Efficient LiDAR SLAM
Mar 24, 2021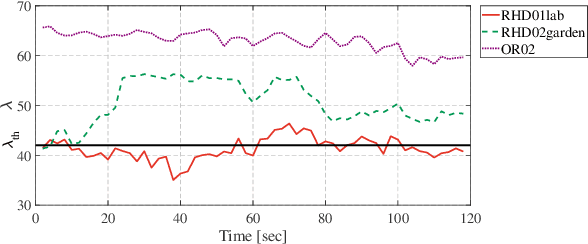
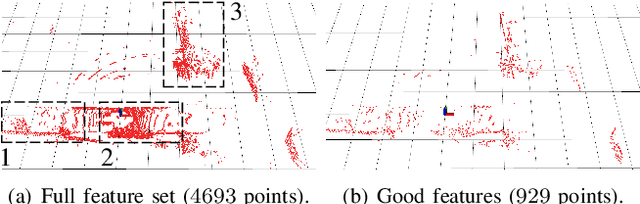
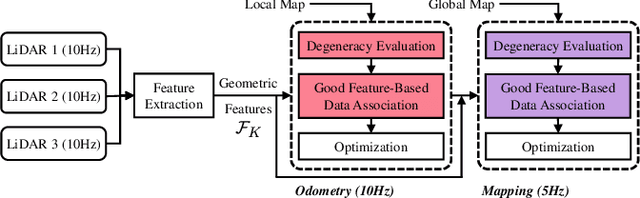
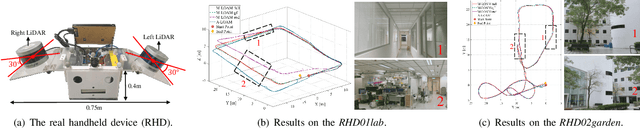
Modern LiDAR-SLAM (L-SLAM) systems have shown excellent results in large-scale, real-world scenarios. However, they commonly have a high latency due to the expensive data association and nonlinear optimization. This paper demonstrates that actively selecting a subset of features significantly improves both the accuracy and efficiency of an L-SLAM system. We formulate the feature selection as a combinatorial optimization problem under a cardinality constraint to preserve the information matrix's spectral attributes. The stochastic-greedy algorithm is applied to approximate the optimal results in real-time. To avoid ill-conditioned estimation, we also propose a general strategy to evaluate the environment's degeneracy and modify the feature number online. The proposed feature selector is integrated into a multi-LiDAR SLAM system. We validate this enhanced system with extensive experiments covering various scenarios on two sensor setups and computation platforms. We show that our approach exhibits low localization error and speedup compared to the state-of-the-art L-SLAM systems. To benefit the community, we have released the source code: https://ram-lab.com/file/site/m-loam.
Reliability updating with equality information
Mar 24, 2012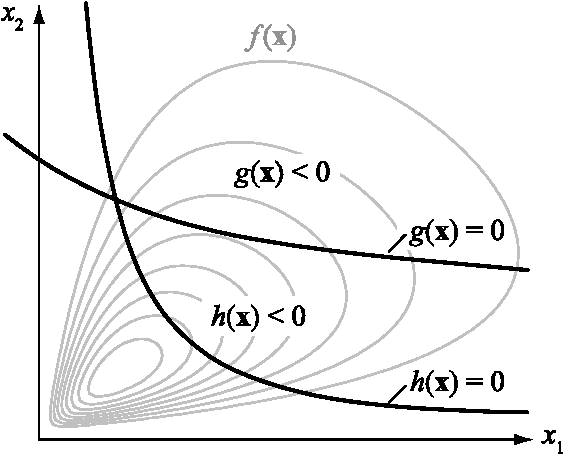
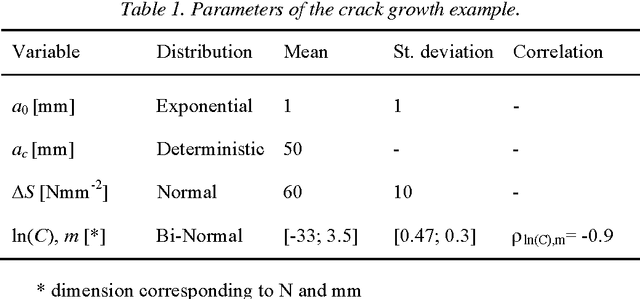
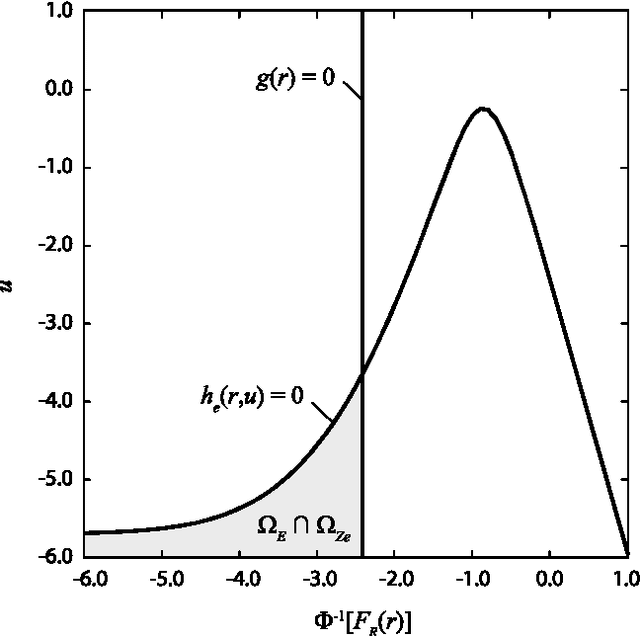
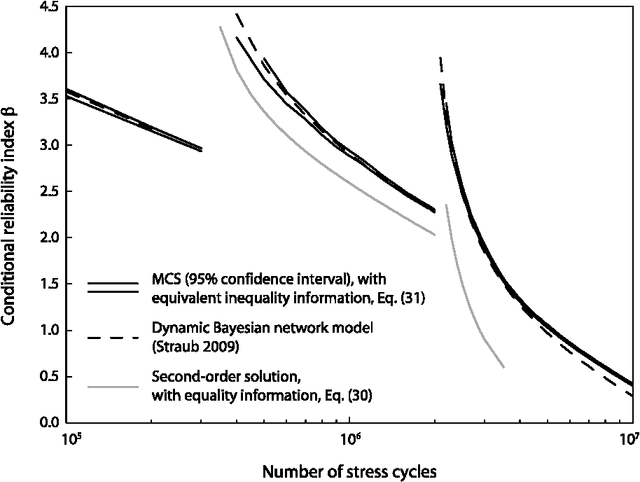
In many instances, information on engineering systems can be obtained through measurements, monitoring or direct observations of system performances and can be used to update the system reliability estimate. In structural reliability analysis, such information is expressed either by inequalities (e.g. for the observation that no defect is present) or by equalities (e.g. for quantitative measurements of system characteristics). When information Z is of the equality type, the a-priori probability of Z is zero and most structural reliability methods (SRM) are not directly applicable to the computation of the updated reliability. Hitherto, the computation of the reliability of engineering systems conditional on equality information was performed through first- and second order approximations. In this paper, it is shown how equality information can be transformed into inequality information, which enables reliability updating by solving a standard structural system reliability problem. This approach enables the use of any SRM, including those based on simulation, for reliability updating with equality information. It is demonstrated on three numerical examples, including an application to fatigue reliability.
Regularized target encoding outperforms traditional methods in supervised machine learning with high cardinality features
Apr 01, 2021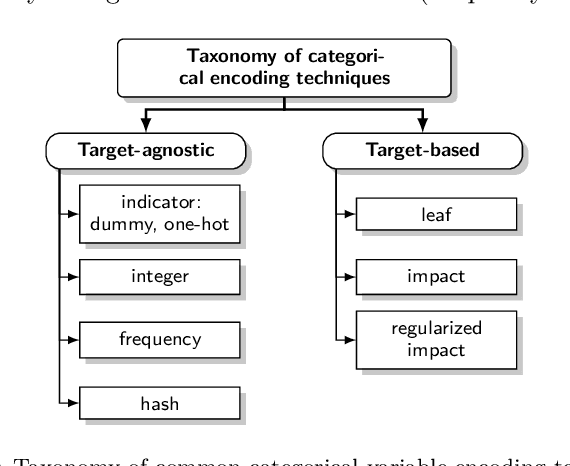
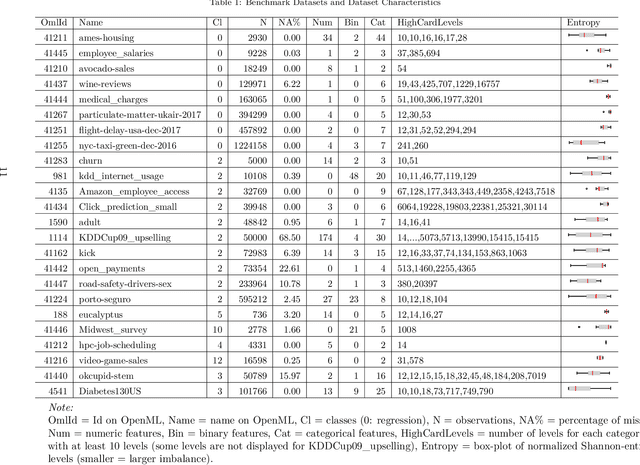
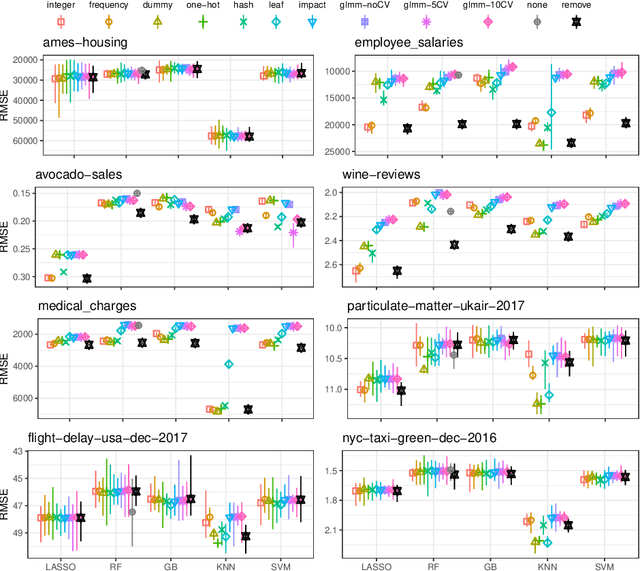
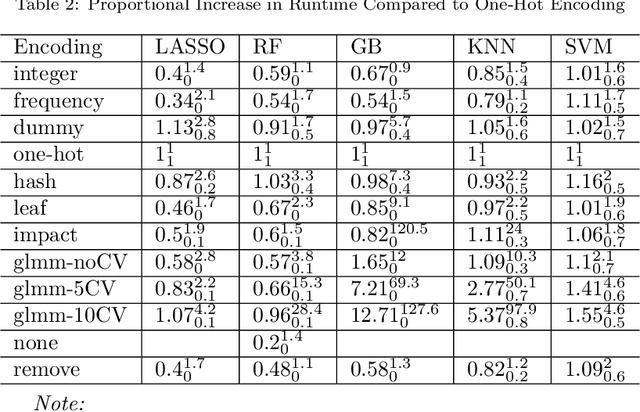
Because most machine learning (ML) algorithms are designed for numerical inputs, efficiently encoding categorical variables is a crucial aspect during data analysis. An often encountered problem are high cardinality features, i.e. unordered categorical predictor variables with a high number of levels. We study techniques that yield numeric representations of categorical variables which can then be used in subsequent ML applications. We focus on the impact of those techniques on a subsequent algorithm's predictive performance, and -- if possible -- derive best practices on when to use which technique. We conducted a large-scale benchmark experiment, where we compared different encoding strategies together with five ML algorithms (lasso, random forest, gradient boosting, k-nearest neighbours, support vector machine) using datasets from regression, binary- and multiclass- classification settings. Throughout our study, regularized versions of target encoding (i.e. using target predictions based on the feature levels in the training set as a new numerical feature) consistently provided the best results. Traditional encodings that make unreasonable assumptions to map levels to integers (e.g. integer encoding) or to reduce the number of levels (possibly based on target information, e.g. leaf encoding) before creating binary indicator variables (one-hot or dummy encoding) were not as effective.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021
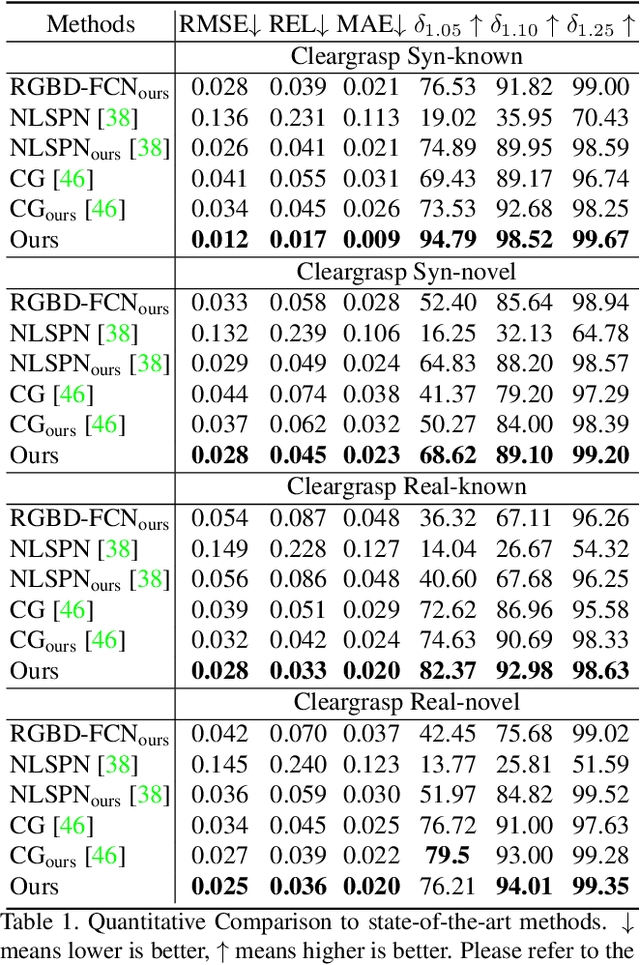


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Representation Learning of Reconstructed Graphs Using Random Walk Graph Convolutional Network
Jan 02, 2021
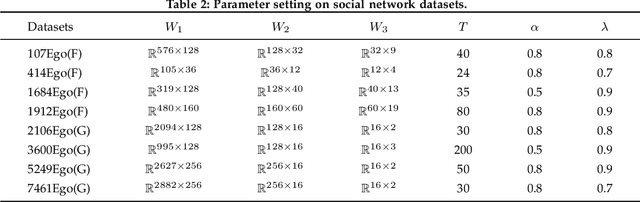
Graphs are often used to organize data because of their simple topological structure, and therefore play a key role in machine learning. And it turns out that the low-dimensional embedded representation obtained by graph representation learning are extremely useful in various typical tasks, such as node classification, content recommendation and link prediction. However, the existing methods mostly start from the microstructure (i.e., the edges) in the graph, ignoring the mesoscopic structure (high-order local structure). Here, we propose wGCN -- a novel framework that utilizes random walk to obtain the node-specific mesoscopic structures of the graph, and utilizes these mesoscopic structures to reconstruct the graph And organize the characteristic information of the nodes. Our method can effectively generate node embeddings for previously unseen data, which has been proven in a series of experiments conducted on citation networks and social networks (our method has advantages over baseline methods). We believe that combining high-order local structural information can more efficiently explore the potential of the network, which will greatly improve the learning efficiency of graph neural network and promote the establishment of new learning models.
On the relationship between a Gamma distributed precision parameter and the associated standard deviation in the context of Bayesian parameter inference
Jan 15, 2021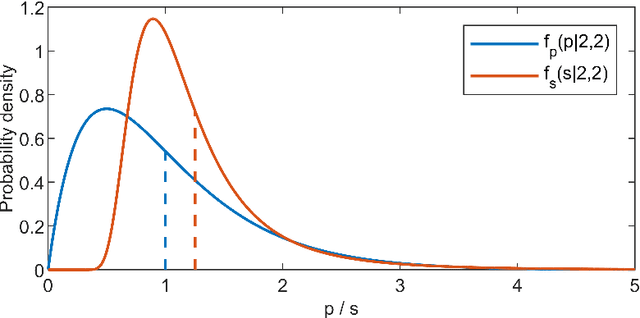
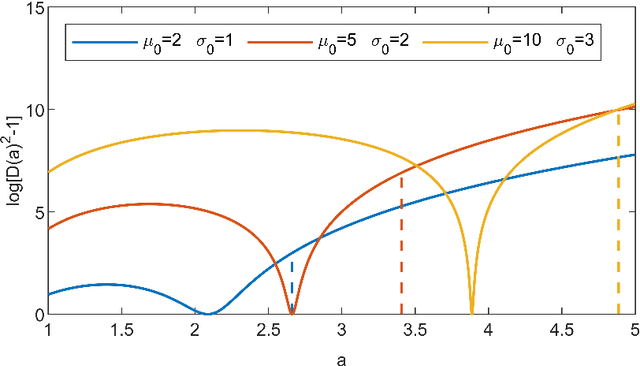
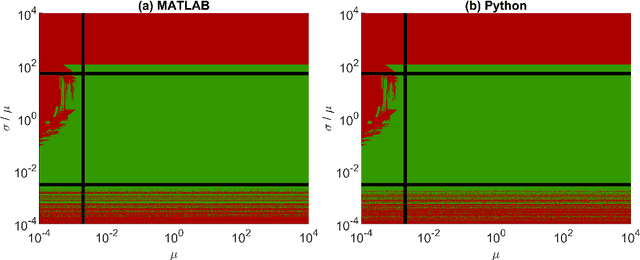
In Bayesian inference, an unknown measurement uncertainty is often quantified in terms of a Gamma distributed precision parameter, which is impractical when prior information on the standard deviation of the measurement uncertainty shall be utilised during inference. This paper thus introduces a method for transforming between a gamma distributed precision parameter and the distribution of the associated standard deviation. The proposed method is based on numerical optimisation and shows adequate results for a wide range of scenarios.
Generalizable Limited-Angle CT Reconstruction via Sinogram Extrapolation
Mar 15, 2021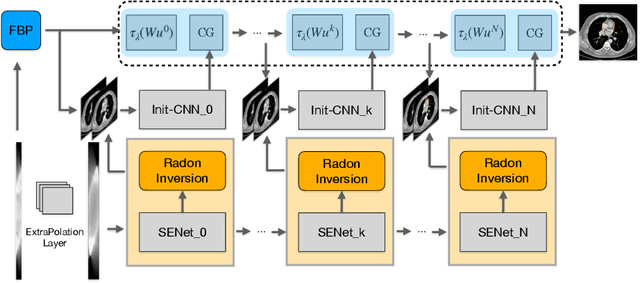

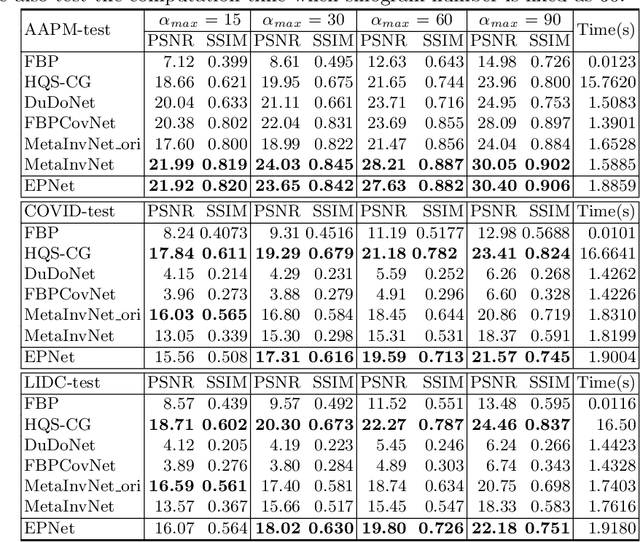
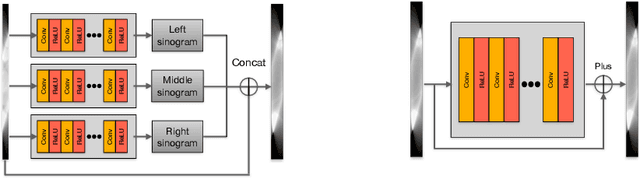
Computed tomography (CT) reconstruction from X-ray projections acquired within a limited angle range is challenging, especially when the angle range is extremely small. Both analytical and iterative models need more projections for effective modeling. Deep learning methods have gained prevalence due to their excellent reconstruction performances, but such success is mainly limited within the same dataset and does not generalize across datasets with different distributions. Hereby we propose ExtraPolationNetwork for limited-angle CT reconstruction via the introduction of a sinogram extrapolation module, which is theoretically justified. The module complements extra sinogram information and boots model generalizability. Extensive experimental results show that our reconstruction model achieves state-of-the-art performance on NIH-AAPM dataset, similar to existing approaches. More importantly, we show that using such a sinogram extrapolation module significantly improves the generalization capability of the model on unseen datasets (e.g., COVID-19 and LIDC datasets) when compared to existing approaches.
HAMMER: Multi-Level Coordination of Reinforcement Learning Agents via Learned Messaging
Jan 18, 2021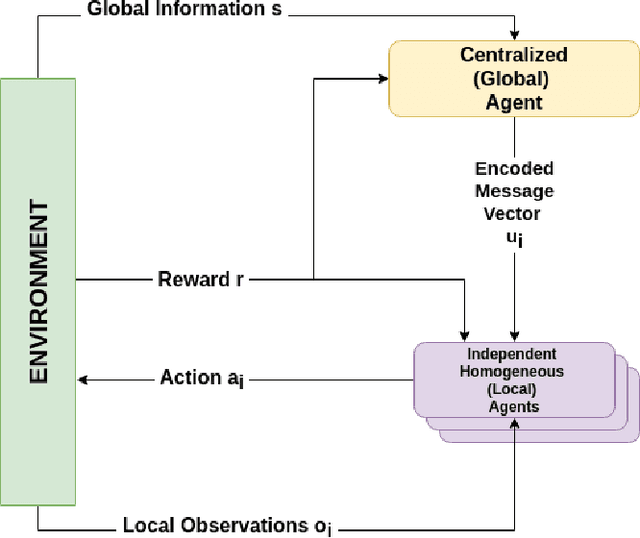
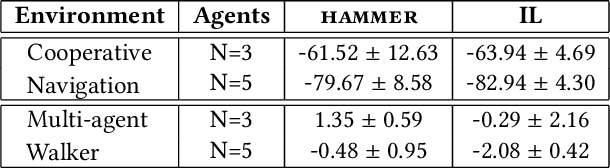


Cooperative multi-agent reinforcement learning (MARL) has achieved significant results, most notably by leveraging the representation learning abilities of deep neural networks. However, large centralized approaches quickly become infeasible as the number of agents scale, and fully decentralized approaches can miss important opportunities for information sharing and coordination. Furthermore, not all agents are equal - in some cases, individual agents may not even have the ability to send communication to other agents or explicitly model other agents. This paper considers the case where there is a single, powerful, central agent that can observe the entire observation space, and there are multiple, low powered, local agents that can only receive local observations and cannot communicate with each other. The job of the central agent is to learn what message to send to different local agents, based on the global observations, not by centrally solving the entire problem and sending action commands, but by determining what additional information an individual agent should receive so that it can make a better decision. After explaining our MARL algorithm, hammer, and where it would be most applicable, we implement it in the cooperative navigation and multi-agent walker domains. Empirical results show that 1) learned communication does indeed improve system performance, 2) results generalize to multiple numbers of agents, and 3) results generalize to different reward structures.
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021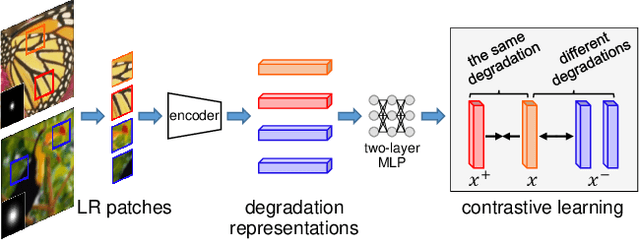

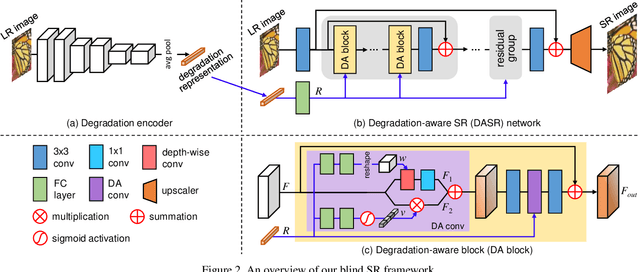
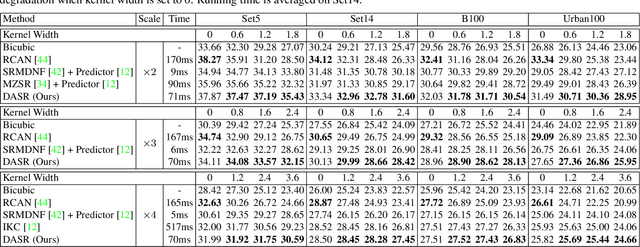
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.