 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Demographic Aware Probabilistic Medical Knowledge Graph Embeddings of Electronic Medical Records
Mar 22, 2021
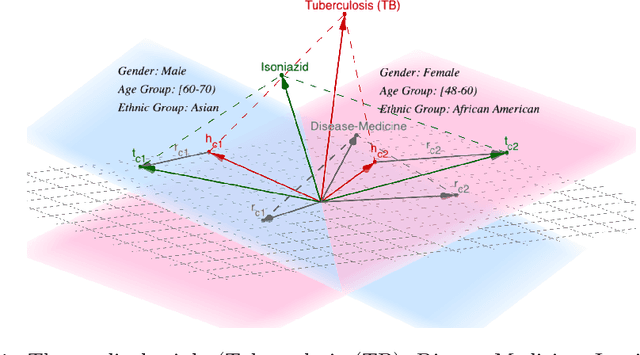
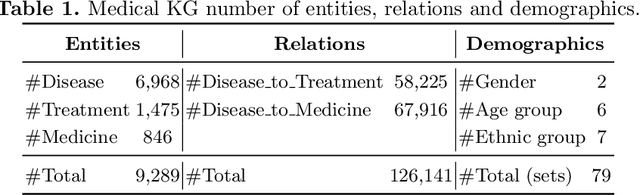
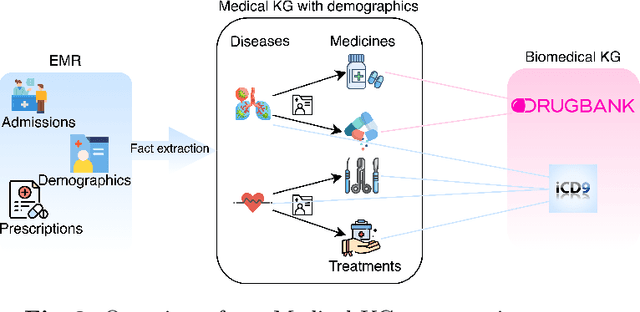
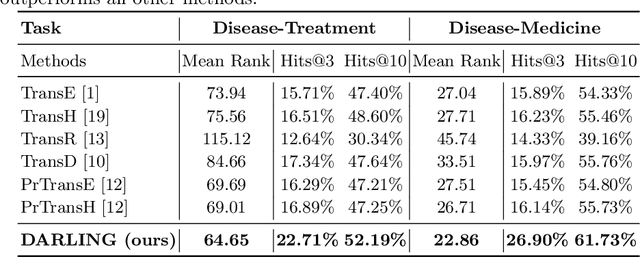
Medical knowledge graphs (KGs) constructed from Electronic Medical Records (EMR) contain abundant information about patients and medical entities. The utilization of KG embedding models on these data has proven to be efficient for different medical tasks. However, existing models do not properly incorporate patient demographics and most of them ignore the probabilistic features of the medical KG. In this paper, we propose DARLING (Demographic Aware pRobabiListic medIcal kNowledge embeddinG), a demographic-aware medical KG embedding framework that explicitly incorporates demographics in the medical entities space by associating patient demographics with a corresponding hyperplane. Our framework leverages the probabilistic features within the medical entities for learning their representations through demographic guidance. We evaluate DARLING through link prediction for treatments and medicines, on a medical KG constructed from EMR data, and illustrate its superior performance compared to existing KG embedding models.
Representation, Analysis of Bayesian Refinement Approximation Network: A Survey
Mar 27, 2021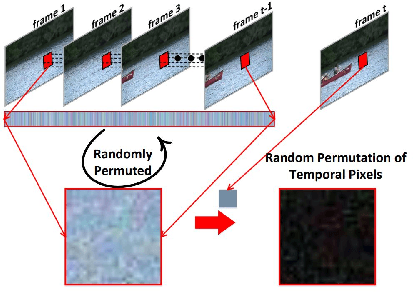
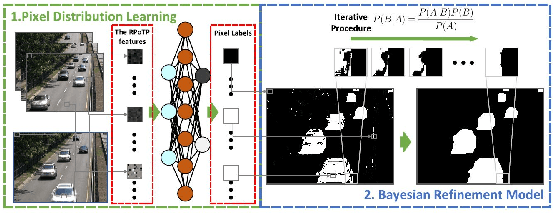

After an artificial model background subtraction, the pixels have been labelled as foreground and background. Previous approaches to secondary processing the output for denoising usually use traditional methods such as the Bayesian refinement method. In this paper, we focus on using a modified U-Net model to approximate the result of the Bayesian refinement method and improve the result. In our modified U-Net model, the result of background subtraction from other models will be combined with the source image as input for learning the statistical distribution. Thus, the losing information caused by the background subtraction model can be restored from the source image. Moreover, since the part of the input image is already the output of the other background subtraction model, the feature extraction should be convenient, it only needs to change the labels of the noise pixels. Compare with traditional methods, using deep learning methods superiority in keeping details.
Can NLI Models Verify QA Systems' Predictions?
Apr 18, 2021
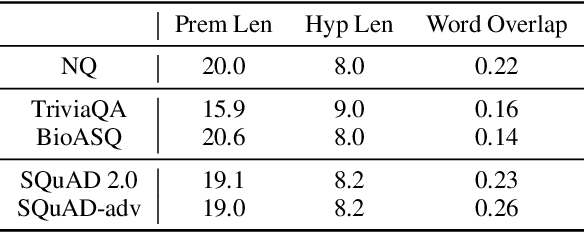

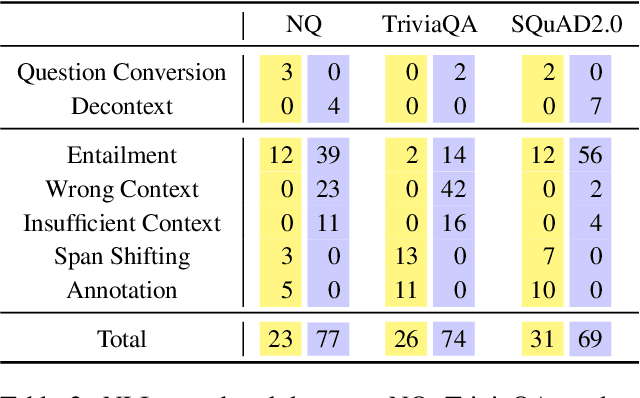
To build robust question answering systems, we need the ability to verify whether answers to questions are truly correct, not just "good enough" in the context of imperfect QA datasets. We explore the use of natural language inference (NLI) as a way to achieve this goal, as NLI inherently requires the premise (document context) to contain all necessary information to support the hypothesis (proposed answer to the question). We leverage large pre-trained models and recent prior datasets to construct powerful question converter and decontextualization modules, which can reformulate QA instances as premise-hypothesis pairs with very high reliability. Then, by combining standard NLI datasets with NLI examples automatically derived from QA training data, we can train NLI models to judge the correctness of QA models' proposed answers. We show that our NLI approach can generally improve the confidence estimation of a QA model across different domains, evaluated in a selective QA setting. Careful manual analysis over the predictions of our NLI model shows that it can further identify cases where the QA model produces the right answer for the wrong reason, or where the answer cannot be verified as addressing all aspects of the question.
Anomaly Detection on Attributed Networks via Contrastive Self-Supervised Learning
Feb 27, 2021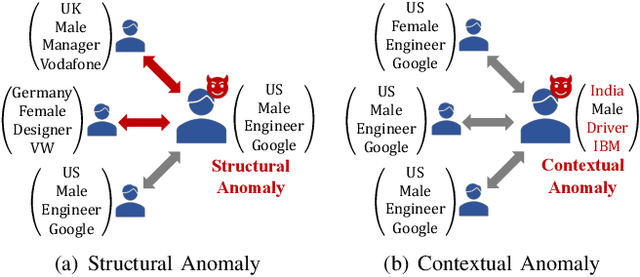
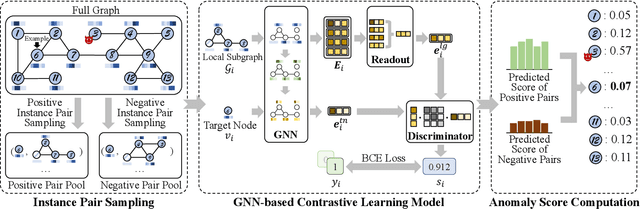
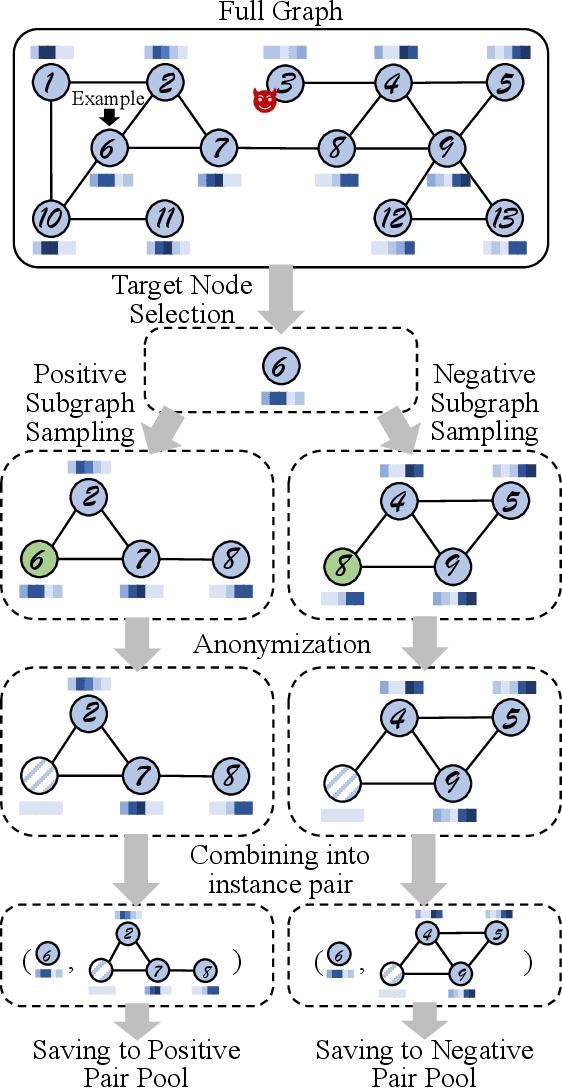
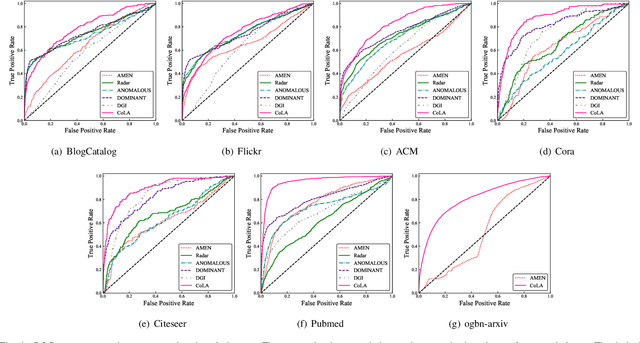
Anomaly detection on attributed networks attracts considerable research interests due to wide applications of attributed networks in modeling a wide range of complex systems. Recently, the deep learning-based anomaly detection methods have shown promising results over shallow approaches, especially on networks with high-dimensional attributes and complex structures. However, existing approaches, which employ graph autoencoder as their backbone, do not fully exploit the rich information of the network, resulting in suboptimal performance. Furthermore, these methods do not directly target anomaly detection in their learning objective and fail to scale to large networks due to the full graph training mechanism. To overcome these limitations, in this paper, we present a novel contrastive self-supervised learning framework for anomaly detection on attributed networks. Our framework fully exploits the local information from network data by sampling a novel type of contrastive instance pair, which can capture the relationship between each node and its neighboring substructure in an unsupervised way. Meanwhile, a well-designed graph neural network-based contrastive learning model is proposed to learn informative embedding from high-dimensional attributes and local structure and measure the agreement of each instance pairs with its outputted scores. The multi-round predicted scores by the contrastive learning model are further used to evaluate the abnormality of each node with statistical estimation. In this way, the learning model is trained by a specific anomaly detection-aware target. Furthermore, since the input of the graph neural network module is batches of instance pairs instead of the full network, our framework can adapt to large networks flexibly. Experimental results show that our proposed framework outperforms the state-of-the-art baseline methods on all seven benchmark datasets.
Successful Nash Equilibrium Agent for a 3-Player Imperfect-Information Game
Apr 13, 2018
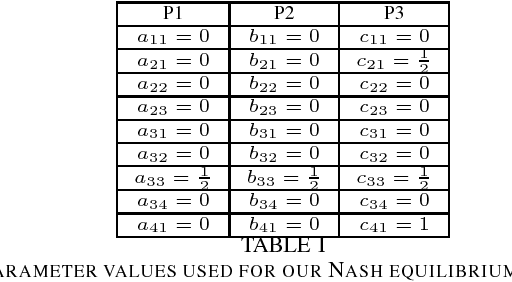
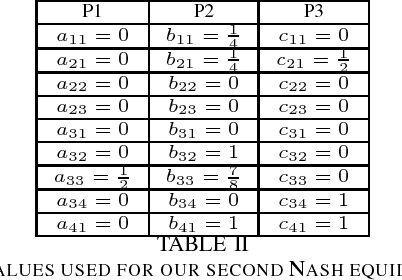
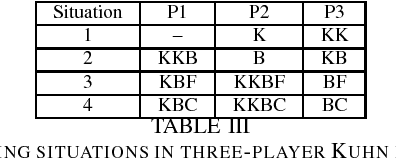
Creating strong agents for games with more than two players is a major open problem in AI. Common approaches are based on approximating game-theoretic solution concepts such as Nash equilibrium, which have strong theoretical guarantees in two-player zero-sum games, but no guarantees in non-zero-sum games or in games with more than two players. We describe an agent that is able to defeat a variety of realistic opponents using an exact Nash equilibrium strategy in a 3-player imperfect-information game. This shows that, despite a lack of theoretical guarantees, agents based on Nash equilibrium strategies can be successful in multiplayer games after all.
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Apr 18, 2021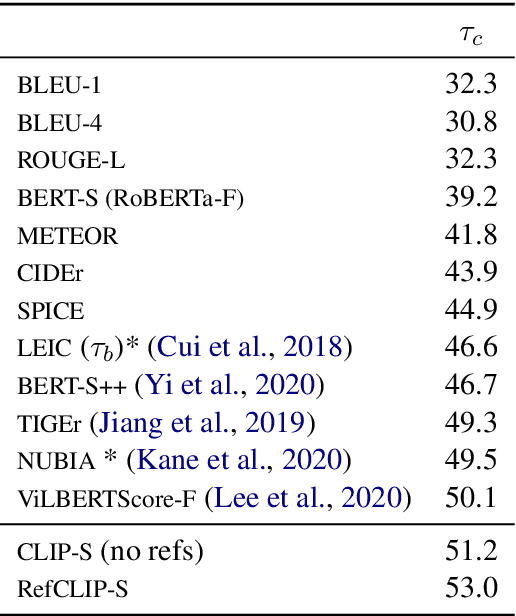
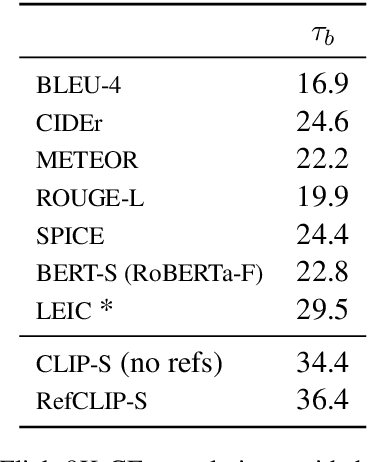
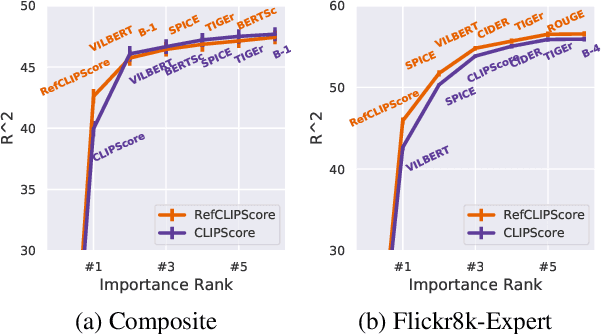

Image captioning has conventionally relied on reference-based automatic evaluations, where machine captions are compared against captions written by humans. This is in stark contrast to the reference-free manner in which humans assess caption quality. In this paper, we report the surprising empirical finding that CLIP (Radford et al., 2021), a cross-modal model pretrained on 400M image+caption pairs from the web, can be used for robust automatic evaluation of image captioning without the need for references. Experiments spanning several corpora demonstrate that our new reference-free metric, CLIPScore, achieves the highest correlation with human judgements, outperforming existing reference-based metrics like CIDEr and SPICE. Information gain experiments demonstrate that CLIPScore, with its tight focus on image-text compatibility, is complementary to existing reference-based metrics that emphasize text-text similarities. Thus, we also present a reference-augmented version, RefCLIPScore, which achieves even higher correlation. Beyond literal description tasks, several case studies reveal domains where CLIPScore performs well (clip-art images, alt-text rating), but also where it is relatively weaker vs reference-based metrics, e.g., news captions that require richer contextual knowledge.
Learning from Context or Names? An Empirical Study on Neural Relation Extraction
Oct 05, 2020
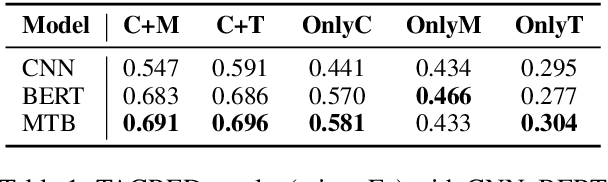

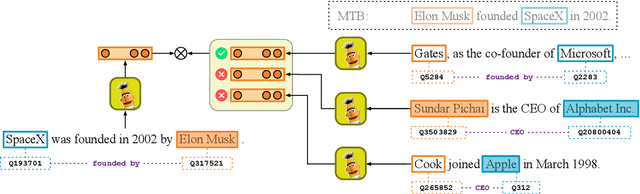
Neural models have achieved remarkable success on relation extraction (RE) benchmarks. However, there is no clear understanding which type of information affects existing RE models to make decisions and how to further improve the performance of these models. To this end, we empirically study the effect of two main information sources in text: textual context and entity mentions (names). We find that (i) while context is the main source to support the predictions, RE models also heavily rely on the information from entity mentions, most of which is type information, and (ii) existing datasets may leak shallow heuristics via entity mentions and thus contribute to the high performance on RE benchmarks. Based on the analyses, we propose an entity-masked contrastive pre-training framework for RE to gain a deeper understanding on both textual context and type information while avoiding rote memorization of entities or use of superficial cues in mentions. We carry out extensive experiments to support our views, and show that our framework can improve the effectiveness and robustness of neural models in different RE scenarios. All the code and datasets are released at https://github.com/thunlp/RE-Context-or-Names.
Potential Idiomatic Expression (PIE)-English: Corpus for Classes of Idioms
Apr 25, 2021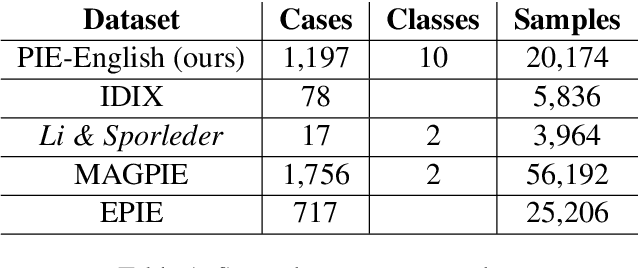
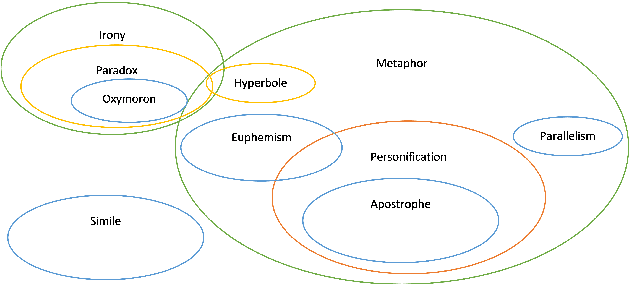
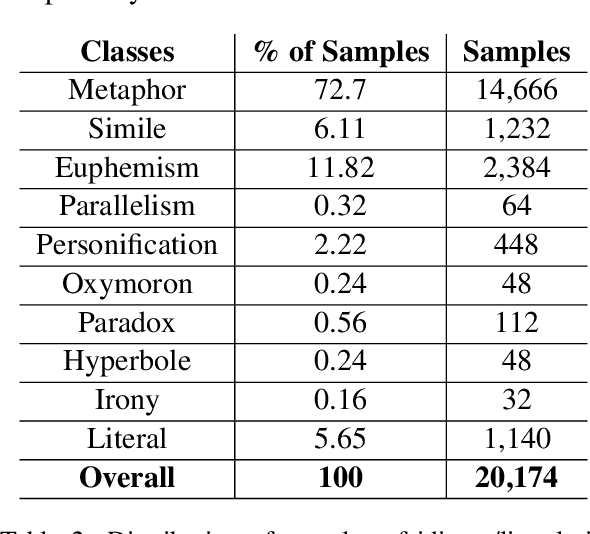
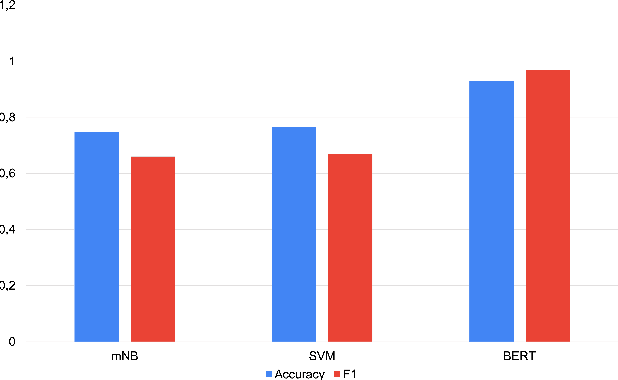
We present a fairly large, Potential Idiomatic Expression (PIE) dataset for Natural Language Processing (NLP) in English. The challenges with NLP systems with regards to tasks such as Machine Translation (MT), word sense disambiguation (WSD) and information retrieval make it imperative to have a labelled idioms dataset with classes such as it is in this work. To the best of the authors' knowledge, this is the first idioms corpus with classes of idioms beyond the literal and the general idioms classification. In particular, the following classes are labelled in the dataset: metaphor, simile, euphemism, parallelism, personification, oxymoron, paradox, hyperbole, irony and literal. Many past efforts have been limited in the corpus size and classes of samples but this dataset contains over 20,100 samples with almost 1,200 cases of idioms (with their meanings) from 10 classes (or senses). The corpus may also be extended by researchers to meet specific needs. The corpus has part of speech (PoS) tagging from the NLTK library. Classification experiments performed on the corpus to obtain a baseline and comparison among three common models, including the BERT model, give good results. We also make publicly available the corpus and the relevant codes for working with it for NLP tasks.
Fusing RGBD Tracking and Segmentation Tree Sampling for Multi-Hypothesis Volumetric Segmentation
Apr 01, 2021
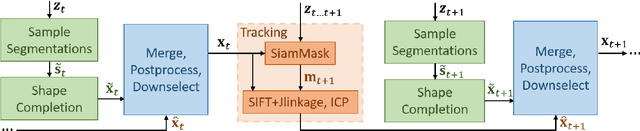


Despite rapid progress in scene segmentation in recent years, 3D segmentation methods are still limited when there is severe occlusion. The key challenge is estimating the segment boundaries of (partially) occluded objects, which are inherently ambiguous when considering only a single frame. In this work, we propose Multihypothesis Segmentation Tracking (MST), a novel method for volumetric segmentation in changing scenes, which allows scene ambiguity to be tracked and our estimates to be adjusted over time as we interact with the scene. Two main innovations allow us to tackle this difficult problem: 1) A novel way to sample possible segmentations from a segmentation tree; and 2) A novel approach to fusing tracking results with multiple segmentation estimates. These methods allow MST to track the segmentation state over time and incorporate new information, such as new objects being revealed. We evaluate our method on several cluttered tabletop environments in simulation and reality. Our results show that MST outperforms baselines in all tested scenes.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021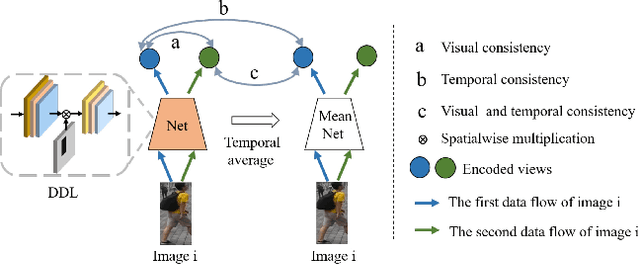
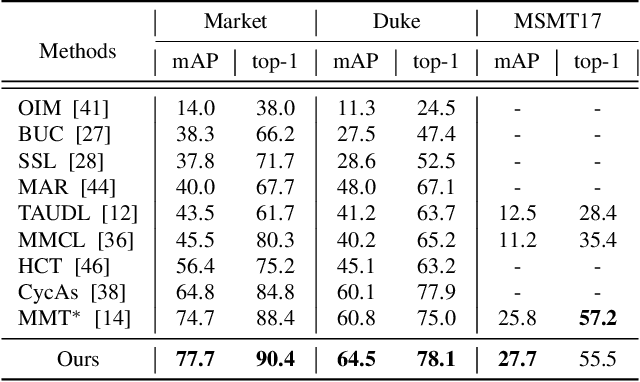
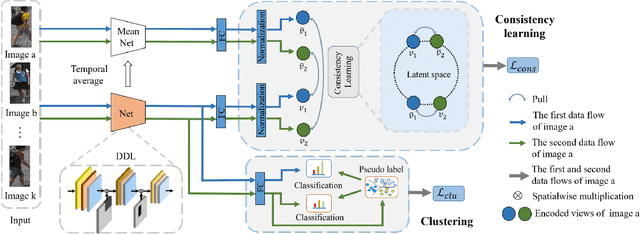
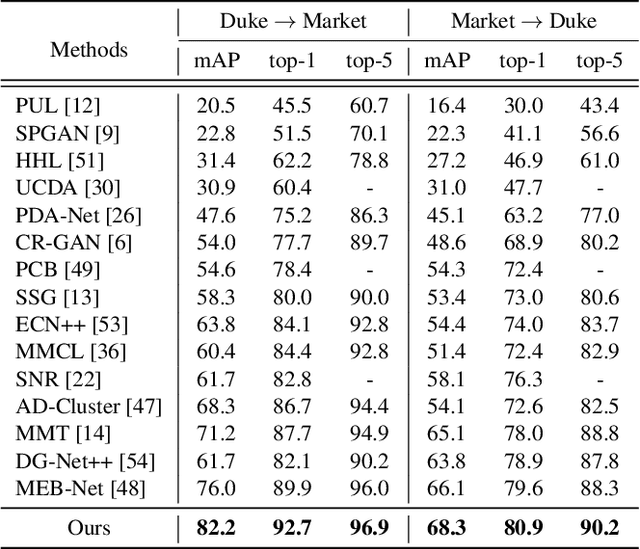
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.