 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Context or Names? An Empirical Study on Neural Relation Extraction
Paper and Code

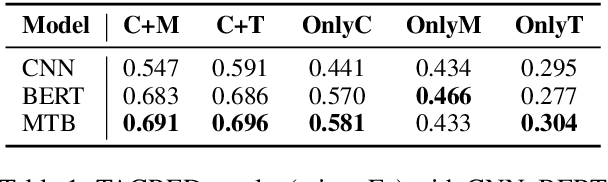

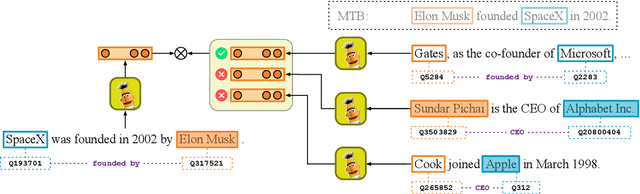
Neural models have achieved remarkable success on relation extraction (RE) benchmarks. However, there is no clear understanding which type of information affects existing RE models to make decisions and how to further improve the performance of these models. To this end, we empirically study the effect of two main information sources in text: textual context and entity mentions (names). We find that (i) while context is the main source to support the predictions, RE models also heavily rely on the information from entity mentions, most of which is type information, and (ii) existing datasets may leak shallow heuristics via entity mentions and thus contribute to the high performance on RE benchmarks. Based on the analyses, we propose an entity-masked contrastive pre-training framework for RE to gain a deeper understanding on both textual context and type information while avoiding rote memorization of entities or use of superficial cues in mentions. We carry out extensive experiments to support our views, and show that our framework can improve the effectiveness and robustness of neural models in different RE scenarios. All the code and datasets are released at https://github.com/thunlp/RE-Context-or-Names.