 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Designing Effective Inter-Pixel Information Flow for Natural Image Matting
Jul 17, 2017
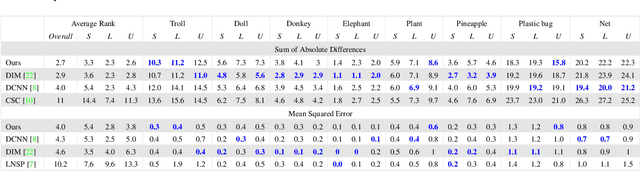


We present a novel, purely affinity-based natural image matting algorithm. Our method relies on carefully defined pixel-to-pixel connections that enable effective use of information available in the image. We control the information flow from the known-opacity regions into the unknown region, as well as within the unknown region itself, by utilizing multiple definitions of pixel affinities. Among other forms of information flow, we introduce color-mixture flow, which builds upon local linear embedding and effectively encapsulates the relation between different pixel opacities. Our resulting novel linear system formulation can be solved in closed-form and is robust against several fundamental challenges of natural matting such as holes and remote intricate structures. Our evaluation using the alpha matting benchmark suggests a significant performance improvement over the current methods. While our method is primarily designed as a standalone matting tool, we show that it can also be used for regularizing mattes obtained by sampling-based methods. We extend our formulation to layer color estimation and show that the use of multiple channels of flow increases the layer color quality. We also demonstrate our performance in green-screen keying and further analyze the characteristics of the affinities used in our method.
High-throughput fast full-color digital pathology based on Fourier ptychographic microscopy via color transfer
Jan 19, 2021

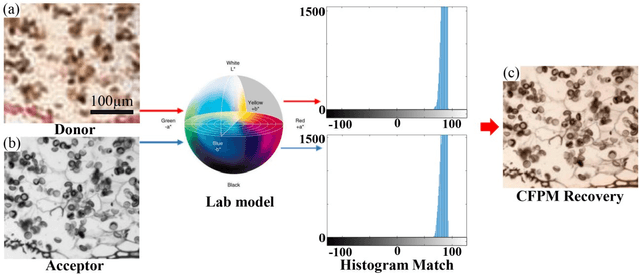
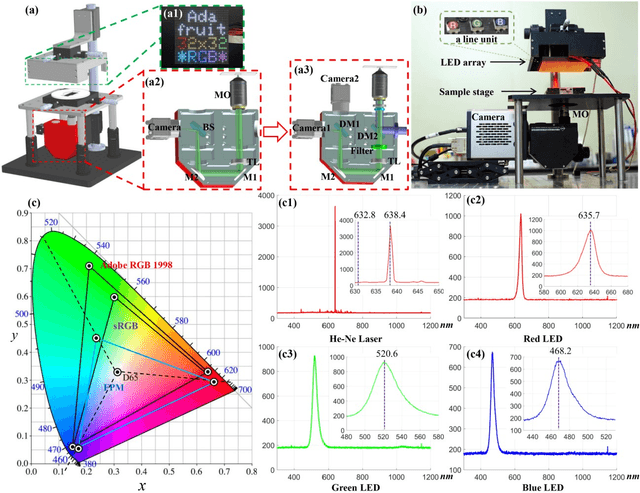
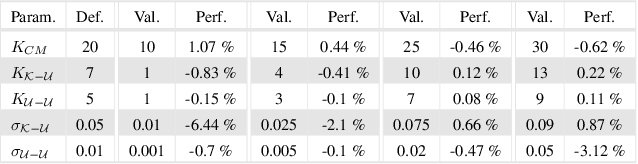
Full-color imaging is significant in digital pathology. Compared with a grayscale image or a pseudo-color image that only contains the contrast information, it can identify and detect the target object better with color texture information. Fourier ptychographic microscopy (FPM) is a high-throughput computational imaging technique that breaks the tradeoff between high resolution (HR) and large field-of-view (FOV), which eliminates the artifacts of scanning and stitching in digital pathology and improves its imaging efficiency. However, the conventional full-color digital pathology based on FPM is still time-consuming due to the repeated experiments with tri-wavelengths. A color transfer FPM approach, termed CFPM was reported. The color texture information of a low resolution (LR) full-color pathologic image is directly transferred to the HR grayscale FPM image captured by only a single wavelength. The color space of FPM based on the standard CIE-XYZ color model and display based on the standard RGB (sRGB) color space were established. Different FPM colorization schemes were analyzed and compared with thirty different biological samples. The average root-mean-square error (RMSE) of the conventional method and CFPM compared with the ground truth is 5.3% and 5.7%, respectively. Therefore, the acquisition time is significantly reduced by 2/3 with the sacrifice of precision of only 0.4%. And CFPM method is also compatible with advanced fast FPM approaches to reduce computation time further.
Class-Wise Principal Component Analysis for hyperspectral image feature extraction
Apr 09, 2021
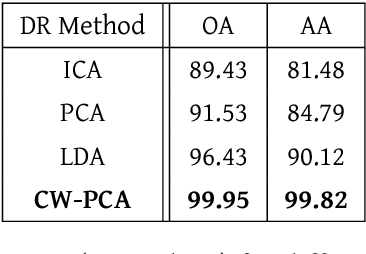
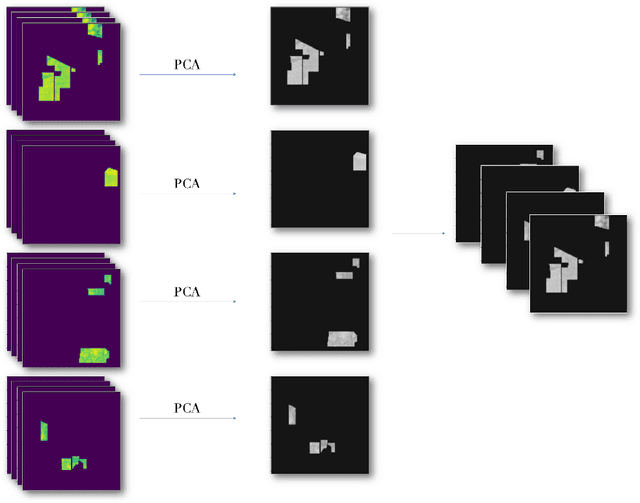
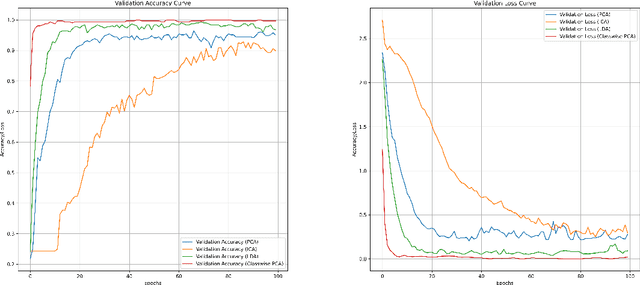
This paper introduces the Class-wise Principal Component Analysis, a supervised feature extraction method for hyperspectral data. Hyperspectral Imaging (HSI) has appeared in various fields in recent years, including Remote Sensing. Realizing that information extraction tasks for hyperspectral images are burdened by data-specific issues, we identify and address two major problems. Those are the Curse of Dimensionality which occurs due to the high-volume of the data cube and the class imbalance problem which is common in hyperspectral datasets. Dimensionality reduction is an essential preprocessing step to complement a hyperspectral image classification task. Therefore, we propose a feature extraction algorithm for dimensionality reduction, based on Principal Component Analysis (PCA). Evaluations are carried out on the Indian Pines dataset to demonstrate that significant improvements are achieved when using the reduced data in a classification task.
Real-time super-resolution mapping of locally anisotropic grain orientations for ultrasonic non-destructive evaluation of crystalline material
May 10, 2021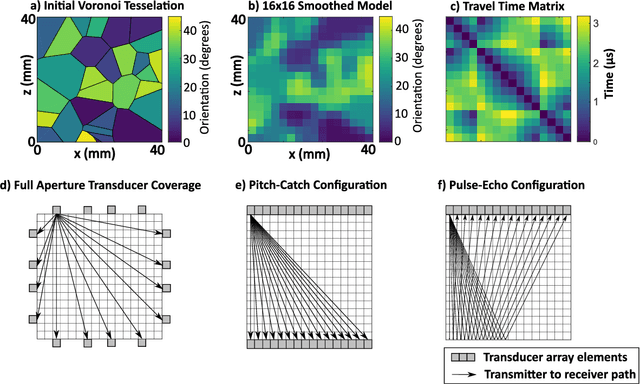
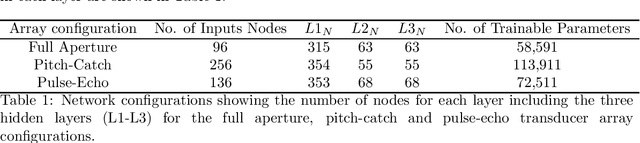
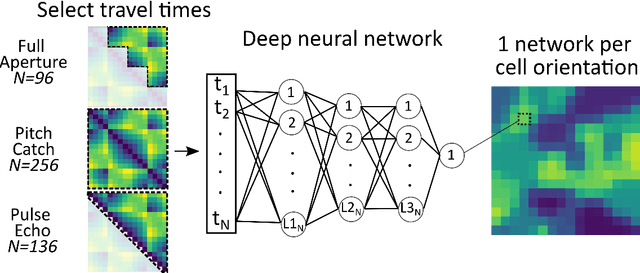
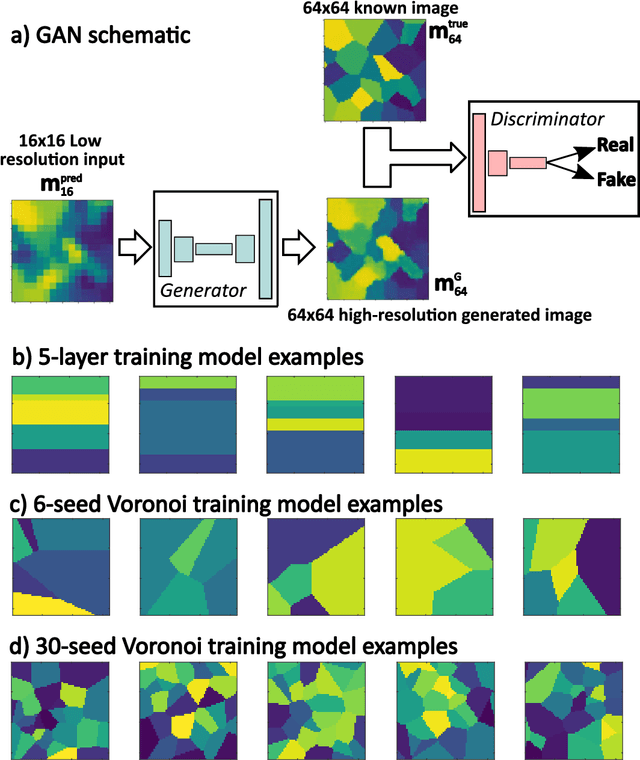
Estimating the spatially varying microstructures of heterogeneous and locally anisotropic media non-destructively is necessary for the accurate detection of flaws and reliable monitoring of manufacturing processes. Conventional algorithms used for solving this inverse problem come with significant computational cost, particularly in the case of high dimensional non-linear tomographic problems. In this paper, we propose a framework which uses deep neural networks (DNNs) with full aperture, pitch-catch and pulse-echo transducer configurations to reconstruct material maps of crystallographic orientation. We also present the first ever application of generative adversarial networks (GANs) to achieve super resolution of ultrasonic tomographic images, providing a factor-four increase in image resolution and up to a 50% increase in structural similarity. The importance of including appropriate prior knowledge in the GAN training dataset to increase inversion accuracy is highlighted; known information about the material's structure should be present in the training data. We show that after a computationally expensive training process, the DNNs and GANs can be used in less that one second (0.9 seconds on a standard desktop computer) to provide a high resolution map of the material's grain orientations.
Massive Wireless Energy Transfer with Statistical CSI Beamforming
Jun 15, 2021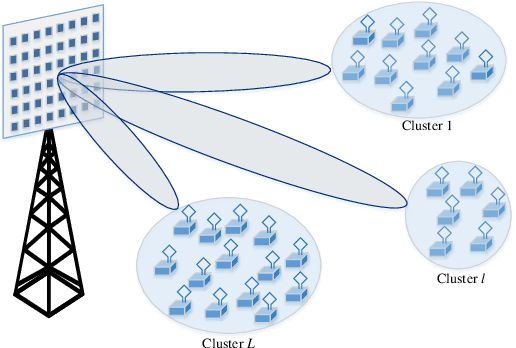
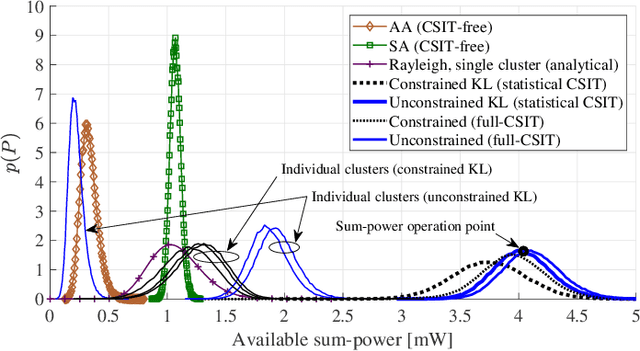
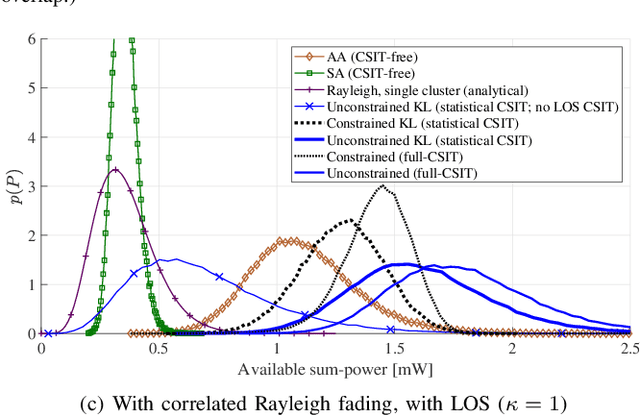
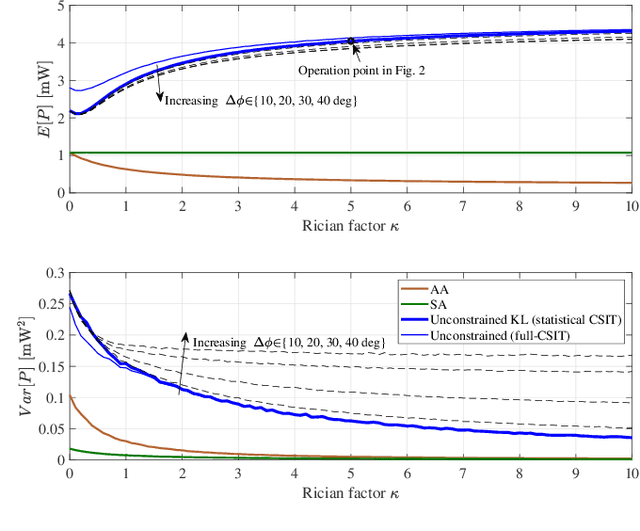
Wireless energy transfer (WET) is a promising solution to enable massive machine-type communications (mMTC) with low-complexity and low-powered wireless devices. Given the energy restrictions of the devices, instant channel state information at the transmitter (CSIT) is not expected to be available in practical WET-enabled mMTC. However, because it is common that the terminals appear spatially clustered, some degree of spatial correlation between their channels to the base station (BS) is expected to occur. The paper considers a massive antenna array at the BS for WET that only has access to i) the first and second order statistics of the Rician channel component of the multiple-input multiple-output (MIMO) channel and also to ii) the line-of-sight MIMO component. The optimal precoding scheme that maximizes the total energy available to the single-antenna devices is derived considering a continuous alphabet for the precoders, permitting any modulated or deterministic waveform. This may lead to some devices in the clusters being assigned a low fraction of the total available power in the cluster, creating a rather uneven situation among them. Consequently, a fairness criterion is introduced, imposing a minimum amount of power allocated to the terminals. A piece-wise linear harvesting circuit is considered at the terminals, with both saturation and a minimum sensitivity, and a constrained version of the precoder is also proposed by solving a non-linear programming problem. A paramount benefit of the constrained precoder is the encompassment of fairness in the power allocation to the different clusters. Moreover, given the polynomial complexity increase of the proposed unconstrained precoder, and the observed linear gain of the system's available sum-power with an increasing number of antennas at the ULA, the use of massive antenna arrays is desirable.
Single Underwater Image Restoration by Contrastive Learning
Mar 17, 2021
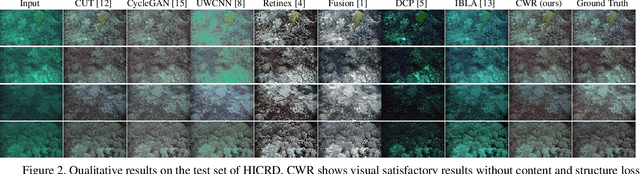
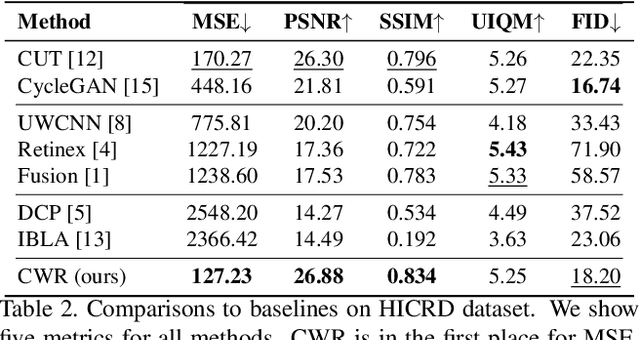
Underwater image restoration attracts significant attention due to its importance in unveiling the underwater world. This paper elaborates on a novel method that achieves state-of-the-art results for underwater image restoration based on the unsupervised image-to-image translation framework. We design our method by leveraging from contrastive learning and generative adversarial networks to maximize mutual information between raw and restored images. Additionally, we release a large-scale real underwater image dataset to support both paired and unpaired training modules. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method.
End-to-End Egospheric Spatial Memory
Feb 15, 2021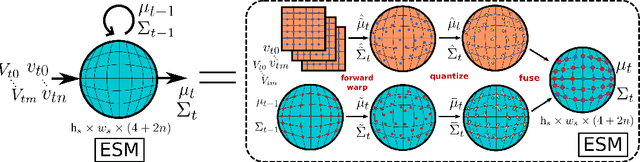
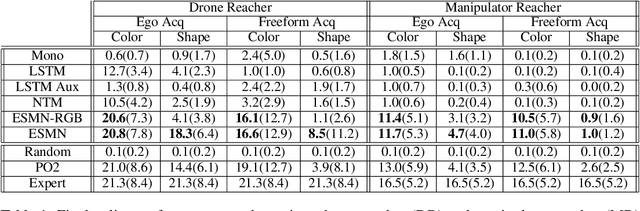
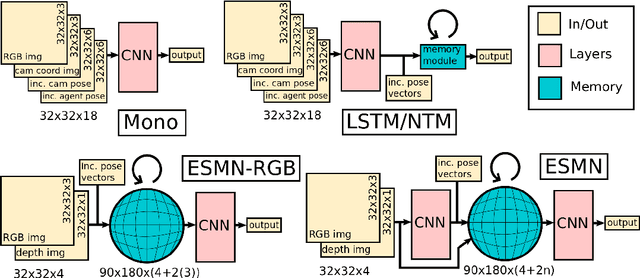
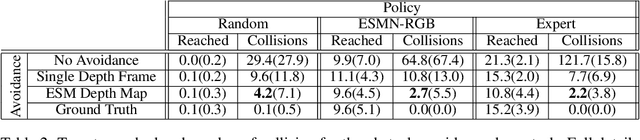
Spatial memory, or the ability to remember and recall specific locations and objects, is central to autonomous agents' ability to carry out tasks in real environments. However, most existing artificial memory modules have difficulty recalling information over long time periods and are not very adept at storing spatial information. We propose a parameter-free module, Egospheric Spatial Memory (ESM), which encodes the memory in an ego-sphere around the agent, enabling expressive 3D representations. ESM can be trained end-to-end via either imitation or reinforcement learning, and improves both training efficiency and final performance against other memory baselines on both drone and manipulator visuomotor control tasks. The explicit egocentric geometry also enables us to seamlessly combine the learned controller with other non-learned modalities, such as local obstacle avoidance. We further show applications to semantic segmentation on the ScanNet dataset, where ESM naturally combines image-level and map-level inference modalities. Through our broad set of experiments, we show that ESM provides a general computation graph for embodied spatial reasoning, and the module forms a bridge between real-time mapping systems and differentiable memory architectures.
Posterior-Aided Regularization for Likelihood-Free Inference
Feb 15, 2021
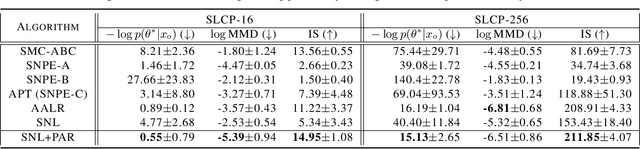
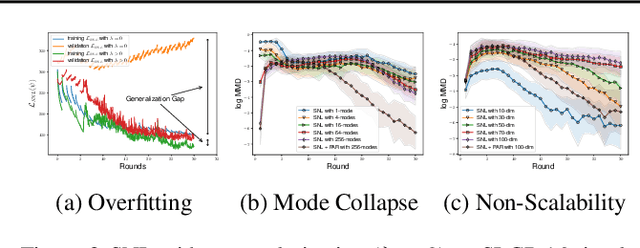
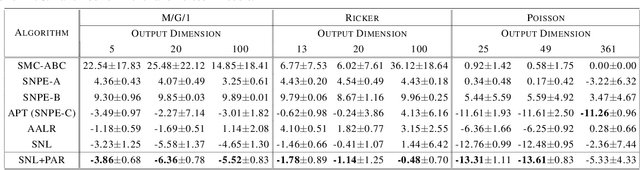
The recent development of likelihood-free inference aims training a flexible density estimator for the target posterior with a set of input-output pairs from simulation. Given the diversity of simulation structures, it is difficult to find a single unified inference method for each simulation model. This paper proposes a universally applicable regularization technique, called Posterior-Aided Regularization (PAR), which is applicable to learning the density estimator, regardless of the model structure. Particularly, PAR solves the mode collapse problem that arises as the output dimension of the simulation increases. PAR resolves this posterior mode degeneracy through a mixture of 1) the reverse KL divergence with the mode seeking property; and 2) the mutual information for the high quality representation on likelihood. Because of the estimation intractability of PAR, we provide a unified estimation method of PAR to estimate both reverse KL term and mutual information term with a single neural network. Afterwards, we theoretically prove the asymptotic convergence of the regularized optimal solution to the unregularized optimal solution as the regularization magnitude converges to zero. Additionally, we empirically show that past sequential neural likelihood inferences in conjunction with PAR present the statistically significant gains on diverse simulation tasks.
Evolutionary Training and Abstraction Yields Algorithmic Generalization of Neural Computers
May 17, 2021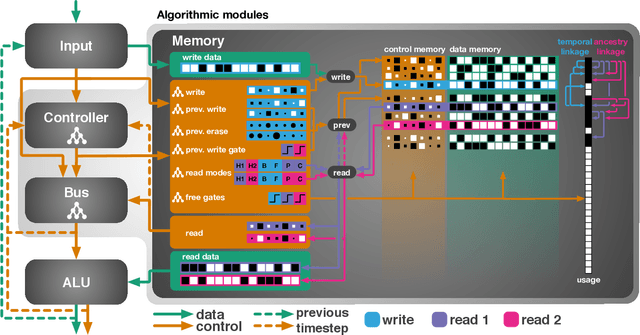
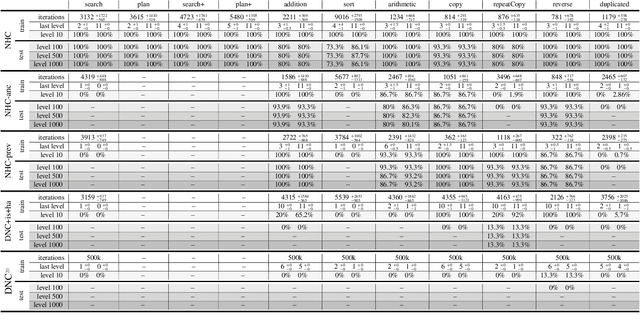
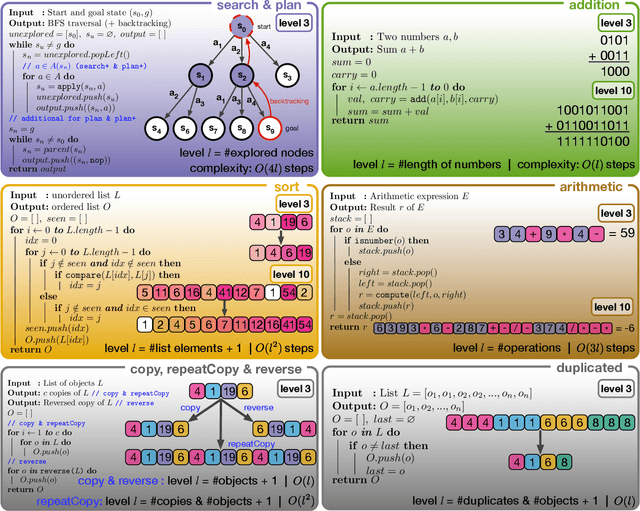
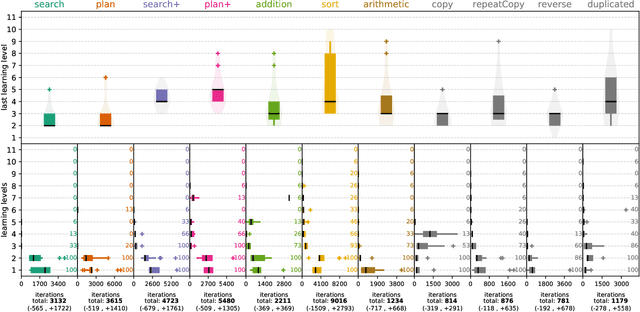
A key feature of intelligent behaviour is the ability to learn abstract strategies that scale and transfer to unfamiliar problems. An abstract strategy solves every sample from a problem class, no matter its representation or complexity -- like algorithms in computer science. Neural networks are powerful models for processing sensory data, discovering hidden patterns, and learning complex functions, but they struggle to learn such iterative, sequential or hierarchical algorithmic strategies. Extending neural networks with external memories has increased their capacities in learning such strategies, but they are still prone to data variations, struggle to learn scalable and transferable solutions, and require massive training data. We present the Neural Harvard Computer (NHC), a memory-augmented network based architecture, that employs abstraction by decoupling algorithmic operations from data manipulations, realized by splitting the information flow and separated modules. This abstraction mechanism and evolutionary training enable the learning of robust and scalable algorithmic solutions. On a diverse set of 11 algorithms with varying complexities, we show that the NHC reliably learns algorithmic solutions with strong generalization and abstraction: perfect generalization and scaling to arbitrary task configurations and complexities far beyond seen during training, and being independent of the data representation and the task domain.
* Nature Machine Intelligence
CSCAD: Correlation Structure-based Collective Anomaly Detection in Complex System
May 30, 2021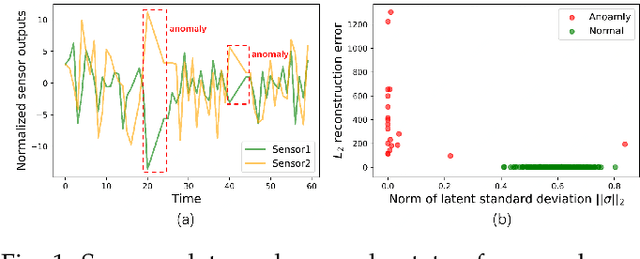
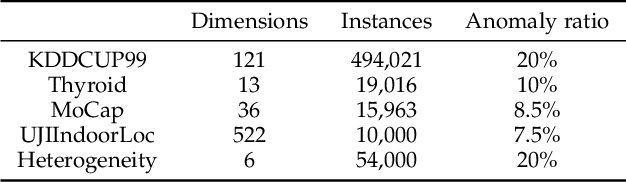
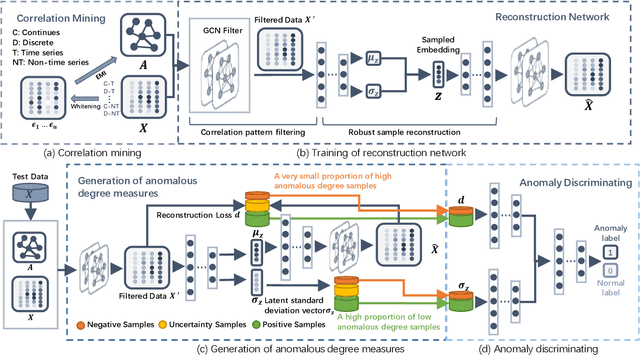
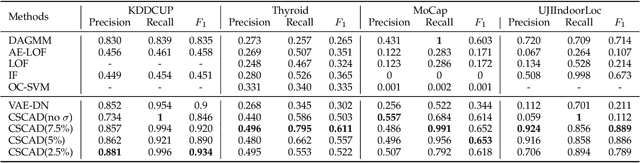
Detecting anomalies in large complex systems is a critical and challenging task. The difficulties arise from several aspects. First, collecting ground truth labels or prior knowledge for anomalies is hard in real-world systems, which often lead to limited or no anomaly labels in the dataset. Second, anomalies in large systems usually occur in a collective manner due to the underlying dependency structure among devices or sensors. Lastly, real-time anomaly detection for high-dimensional data requires efficient algorithms that are capable of handling different types of data (i.e. continuous and discrete). We propose a correlation structure-based collective anomaly detection (CSCAD) model for high-dimensional anomaly detection problem in large systems, which is also generalizable to semi-supervised or supervised settings. Our framework utilize graph convolutional network combining a variational autoencoder to jointly exploit the feature space correlation and reconstruction deficiency of samples to perform anomaly detection. We propose an extended mutual information (EMI) metric to mine the internal correlation structure among different data features, which enhances the data reconstruction capability of CSCAD. The reconstruction loss and latent standard deviation vector of a sample obtained from reconstruction network can be perceived as two natural anomalous degree measures. An anomaly discriminating network can then be trained using low anomalous degree samples as positive samples, and high anomalous degree samples as negative samples. Experimental results on five public datasets demonstrate that our approach consistently outperforms all the competing baselines.