 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Adaptive Explainer for Faithful Dictionary-Based Interpretability under Distribution Shift
May 21, 2026Mechanistic interpretability aims to explain a model's behavior by identifying causally responsible internal structures. Dictionary-based explainers such as sparse autoencoders and transcoders are a primary tool, but their faithfulness under out-of-distribution (OOD) shift has received little systematic attention. We show that distribution shift rotates the subspace that the model actively uses, misaligning the explainer's dictionary trained on in-distribution (ID) activations. We formalize this misalignment as the faithfulness gap, a geometric distance between the ID dictionary and the OOD-active subspace, and show that it controls OOD faithfulness degradation. To reduce this gap, we propose the Geometry-Adaptive Explainer (GAE), which realigns the explainer's dictionary with the OOD-active subspace while preserving the original feature structure. This requires only unlabeled OOD activations and no gradient updates. We prove that GAE improves over the unadapted ID explainer, with excess loss bounded quadratically by the second-moment shift. Empirically, GAE even matches or surpasses all training-based baselines in causal faithfulness across multiple models and OOD settings.
Multi-LLM Adaptive Conformal Inference for Reliable LLM Responses
Feb 01, 2026Ensuring factuality is essential for the safe use of Large Language Models (LLMs) in high-stakes domains such as medicine and law. Conformal inference provides distribution-free guarantees, but existing approaches are either overly conservative, discarding many true-claims, or rely on adaptive error rates and simple linear models that fail to capture complex group structures. To address these challenges, we reformulate conformal inference in a multiplicative filtering setting, modeling factuality as a product of claim-level scores. Our method, Multi-LLM Adaptive Conformal Inference (MACI), leverages ensembles to produce more accurate factuality-scores, which in our experiments led to higher retention, while validity is preserved through group-conditional calibration. Experiments show that MACI consistently achieves user-specified coverage with substantially higher retention and lower time cost than baselines. Our repository is available at https://github.com/MLAI-Yonsei/MACI
MIDUS: Memory-Infused Depth Up-Scaling
Dec 15, 2025



Scaling large language models (LLMs) demands approaches that increase capacity without incurring excessive parameter growth or inference cost. Depth Up-Scaling (DUS) has emerged as a promising strategy by duplicating layers and applying Continual Pre-training (CPT), but its reliance on feed-forward networks (FFNs) limits efficiency and attainable gains. We introduce Memory-Infused Depth Up-Scaling (MIDUS), which replaces FFNs in duplicated blocks with a head-wise memory (HML) layer. Motivated by observations that attention heads have distinct roles both across and within layers, MIDUS assigns an independent memory bank to each head, enabling head-wise retrieval and injecting information into subsequent layers while preserving head-wise functional structure. This design combines sparse memory access with head-wise representations and incorporates an efficient per-head value factorization module, thereby relaxing the usual efficiency-performance trade-off. Across our CPT experiments, MIDUS exhibits robust performance improvements over strong DUS baselines while maintaining a highly efficient parameter footprint. Our findings establish MIDUS as a compelling and resource-efficient alternative to conventional FFN replication for depth up-scaling by leveraging its head-wise memory design.
Spurious Correlation-Aware Embedding Regularization for Worst-Group Robustness
Nov 06, 2025Deep learning models achieve strong performance across various domains but often rely on spurious correlations, making them vulnerable to distribution shifts. This issue is particularly severe in subpopulation shift scenarios, where models struggle in underrepresented groups. While existing methods have made progress in mitigating this issue, their performance gains are still constrained. They lack a rigorous theoretical framework connecting the embedding space representations with worst-group error. To address this limitation, we propose Spurious Correlation-Aware Embedding Regularization for Worst-Group Robustness (SCER), a novel approach that directly regularizes feature representations to suppress spurious cues. We show theoretically that worst-group error is influenced by how strongly the classifier relies on spurious versus core directions, identified from differences in group-wise mean embeddings across domains and classes. By imposing theoretical constraints at the embedding level, SCER encourages models to focus on core features while reducing sensitivity to spurious patterns. Through systematic evaluation on multiple vision and language, we show that SCER outperforms prior state-of-the-art studies in worst-group accuracy. Our code is available at \href{https://github.com/MLAI-Yonsei/SCER}{https://github.com/MLAI-Yonsei/SCER}.
Generating Accurate and Detailed Captions for High-Resolution Images
Oct 31, 2025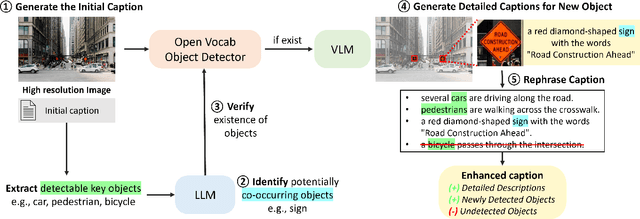
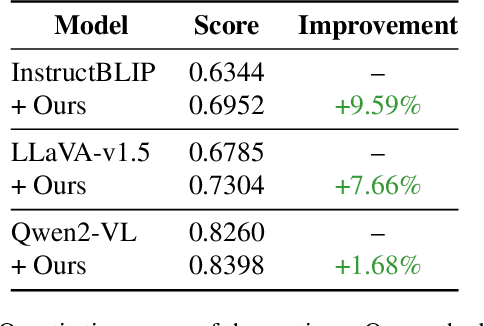
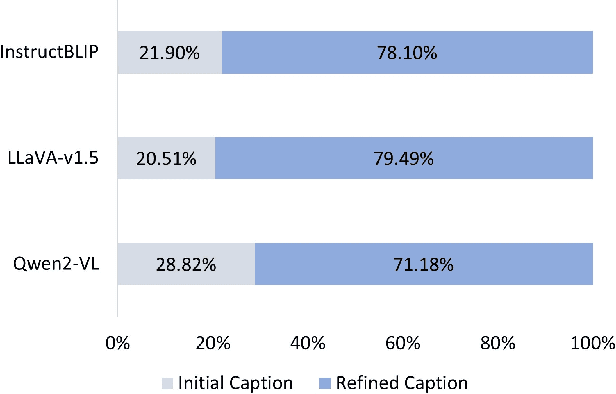
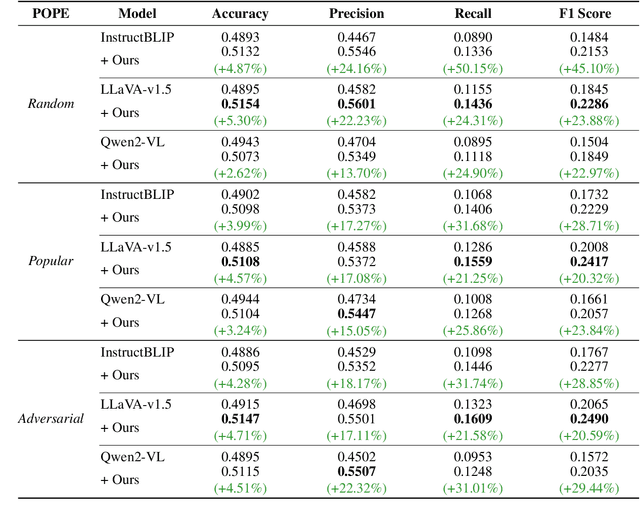
Vision-language models (VLMs) often struggle to generate accurate and detailed captions for high-resolution images since they are typically pre-trained on low-resolution inputs (e.g., 224x224 or 336x336 pixels). Downscaling high-resolution images to these dimensions may result in the loss of visual details and the omission of important objects. To address this limitation, we propose a novel pipeline that integrates vision-language models, large language models (LLMs), and object detection systems to enhance caption quality. Our proposed pipeline refines captions through a novel, multi-stage process. Given a high-resolution image, an initial caption is first generated using a VLM, and key objects in the image are then identified by an LLM. The LLM predicts additional objects likely to co-occur with the identified key objects, and these predictions are verified by object detection systems. Newly detected objects not mentioned in the initial caption undergo focused, region-specific captioning to ensure they are incorporated. This process enriches caption detail while reducing hallucinations by removing references to undetected objects. We evaluate the enhanced captions using pairwise comparison and quantitative scoring from large multimodal models, along with a benchmark for hallucination detection. Experiments on a curated dataset of high-resolution images demonstrate that our pipeline produces more detailed and reliable image captions while effectively minimizing hallucinations.
Uncertainty-driven Embedding Convolution
Jul 28, 2025Text embeddings are essential components in modern NLP pipelines. While numerous embedding models have been proposed, their performance varies across domains, and no single model consistently excels across all tasks. This variability motivates the use of ensemble techniques to combine complementary strengths. However, most existing ensemble methods operate on deterministic embeddings and fail to account for model-specific uncertainty, limiting their robustness and reliability in downstream applications. To address these limitations, we propose Uncertainty-driven Embedding Convolution (UEC). UEC first transforms deterministic embeddings into probabilistic ones in a post-hoc manner. It then computes adaptive ensemble weights based on embedding uncertainty, grounded in a Bayes-optimal solution under a surrogate loss. Additionally, UEC introduces an uncertainty-aware similarity function that directly incorporates uncertainty into similarity scoring. Extensive experiments on retrieval, classification, and semantic similarity benchmarks demonstrate that UEC consistently improves both performance and robustness by leveraging principled uncertainty modeling.
Enhancing Visual Classification using Comparative Descriptors
Nov 08, 2024



The performance of vision-language models (VLMs), such as CLIP, in visual classification tasks, has been enhanced by leveraging semantic knowledge from large language models (LLMs), including GPT. Recent studies have shown that in zero-shot classification tasks, descriptors incorporating additional cues, high-level concepts, or even random characters often outperform those using only the category name. In many classification tasks, while the top-1 accuracy may be relatively low, the top-5 accuracy is often significantly higher. This gap implies that most misclassifications occur among a few similar classes, highlighting the model's difficulty in distinguishing between classes with subtle differences. To address this challenge, we introduce a novel concept of comparative descriptors. These descriptors emphasize the unique features of a target class against its most similar classes, enhancing differentiation. By generating and integrating these comparative descriptors into the classification framework, we refine the semantic focus and improve classification accuracy. An additional filtering process ensures that these descriptors are closer to the image embeddings in the CLIP space, further enhancing performance. Our approach demonstrates improved accuracy and robustness in visual classification tasks by addressing the specific challenge of subtle inter-class differences.
Benchmarking Foundation Models on Exceptional Cases: Dataset Creation and Validation
Oct 23, 2024Foundation models (FMs) have achieved significant success across various tasks, leading to research on benchmarks for reasoning abilities. However, there is a lack of studies on FMs performance in exceptional scenarios, which we define as out-of-distribution (OOD) reasoning tasks. This paper is the first to address these cases, developing a novel dataset for evaluation of FMs across multiple modalities, including graphic novels, calligraphy, news articles, and lyrics. It includes tasks for instance classification, character recognition, token prediction, and text generation. The paper also proposes prompt engineering techniques like Chain-of-Thought (CoT) and CoT+Few-Shot to enhance performance. Validation of FMs using various methods revealed improvements. The code repository is accessible at: https://github.com/MLAI-Yonsei/ExceptionalBenchmark
DaWin: Training-free Dynamic Weight Interpolation for Robust Adaptation
Oct 03, 2024Adapting a pre-trained foundation model on downstream tasks should ensure robustness against distribution shifts without the need to retrain the whole model. Although existing weight interpolation methods are simple yet effective, we argue their static nature limits downstream performance while achieving efficiency. In this work, we propose DaWin, a training-free dynamic weight interpolation method that leverages the entropy of individual models over each unlabeled test sample to assess model expertise, and compute per-sample interpolation coefficients dynamically. Unlike previous works that typically rely on additional training to learn such coefficients, our approach requires no training. Then, we propose a mixture modeling approach that greatly reduces inference overhead raised by dynamic interpolation. We validate DaWin on the large-scale visual recognition benchmarks, spanning 14 tasks across robust fine-tuning -- ImageNet and derived five distribution shift benchmarks -- and multi-task learning with eight classification tasks. Results demonstrate that DaWin achieves significant performance gain in considered settings, with minimal computational overhead. We further discuss DaWin's analytic behavior to explain its empirical success.
Online Continuous Generalized Category Discovery
Aug 24, 2024



With the advancement of deep neural networks in computer vision, artificial intelligence (AI) is widely employed in real-world applications. However, AI still faces limitations in mimicking high-level human capabilities, such as novel category discovery, for practical use. While some methods utilizing offline continual learning have been proposed for novel category discovery, they neglect the continuity of data streams in real-world settings. In this work, we introduce Online Continuous Generalized Category Discovery (OCGCD), which considers the dynamic nature of data streams where data can be created and deleted in real time. Additionally, we propose a novel method, DEAN, Discovery via Energy guidance and feature AugmentatioN, which can discover novel categories in an online manner through energy-guided discovery and facilitate discriminative learning via energy-based contrastive loss. Furthermore, DEAN effectively pseudo-labels unlabeled data through variance-based feature augmentation. Experimental results demonstrate that our proposed DEAN achieves outstanding performance in proposed OCGCD scenario.