 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater Image Restoration via Contrastive Learning and a Real-world Dataset
Jun 20, 2021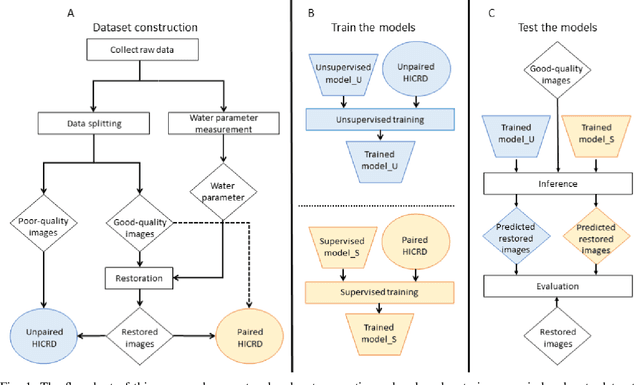
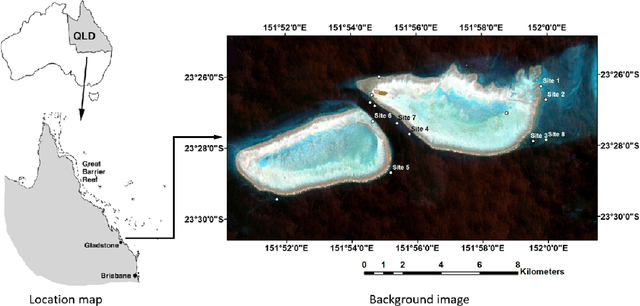
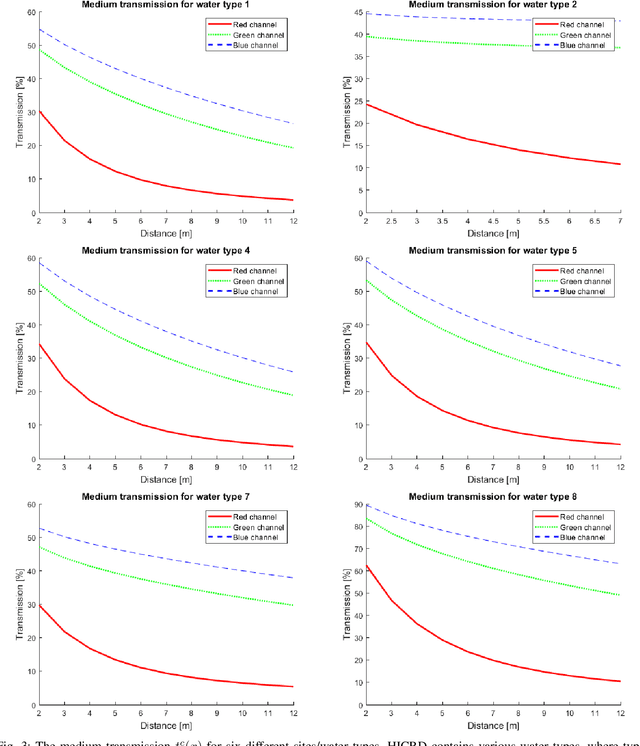
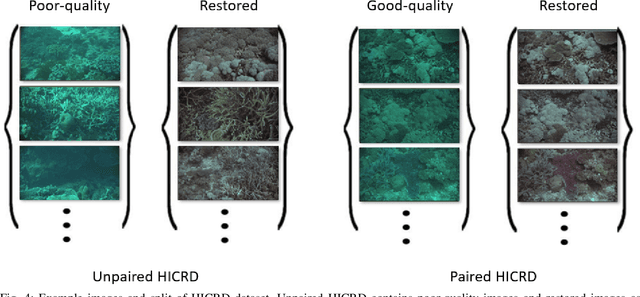
Underwater image restoration is of significant importance in unveiling the underwater world. Numerous techniques and algorithms have been developed in the past decades. However, due to fundamental difficulties associated with imaging/sensing, lighting, and refractive geometric distortions, in capturing clear underwater images, no comprehensive evaluations have been conducted of underwater image restoration. To address this gap, we have constructed a large-scale real underwater image dataset, dubbed `HICRD' (Heron Island Coral Reef Dataset), for the purpose of benchmarking existing methods and supporting the development of new deep-learning based methods. We employ accurate water parameter (diffuse attenuation coefficient) in generating reference images. There are 2000 reference restored images and 6003 original underwater images in the unpaired training set. Further, we present a novel method for underwater image restoration based on unsupervised image-to-image translation framework. Our proposed method leveraged contrastive learning and generative adversarial networks to maximize the mutual information between raw and restored images. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method. Our code and dataset are publicly available at GitHub.
Dual Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 15, 2021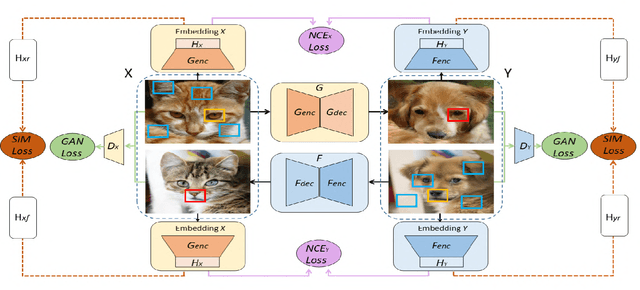
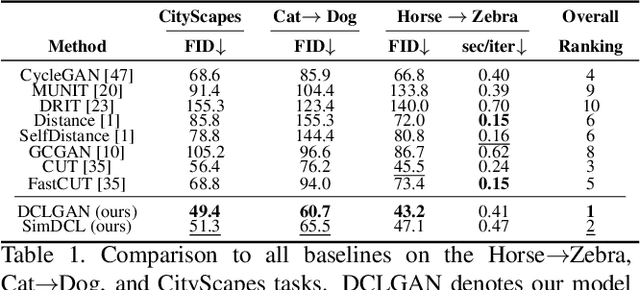


Unsupervised image-to-image translation tasks aim to find a mapping between a source domain X and a target domain Y from unpaired training data. Contrastive learning for Unpaired image-to-image Translation (CUT) yields state-of-the-art results in modeling unsupervised image-to-image translation by maximizing mutual information between input and output patches using only one encoder for both domains. In this paper, we propose a novel method based on contrastive learning and a dual learning setting (exploiting two encoders) to infer an efficient mapping between unpaired data. Additionally, while CUT suffers from mode collapse, a variant of our method efficiently addresses this issue. We further demonstrate the advantage of our approach through extensive ablation studies demonstrating superior performance comparing to recent approaches in multiple challenging image translation tasks. Lastly, we demonstrate that the gap between unsupervised methods and supervised methods can be efficiently closed.
Single Underwater Image Restoration by Contrastive Learning
Apr 15, 2021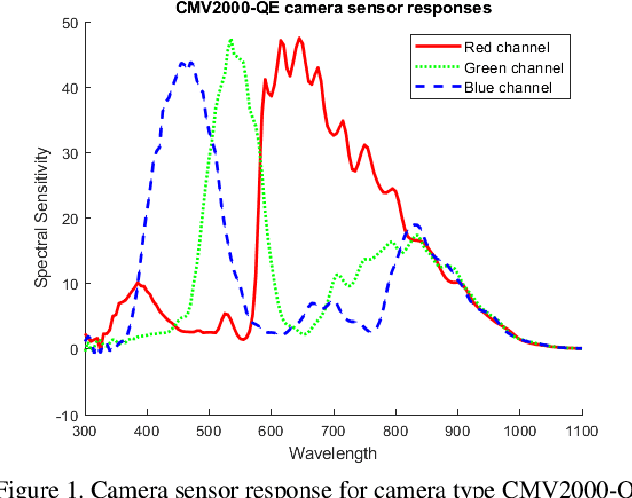
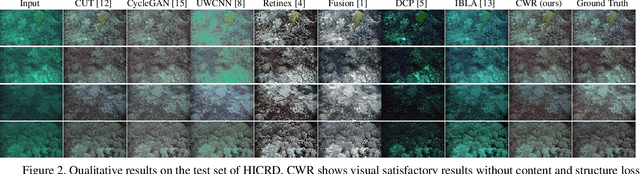
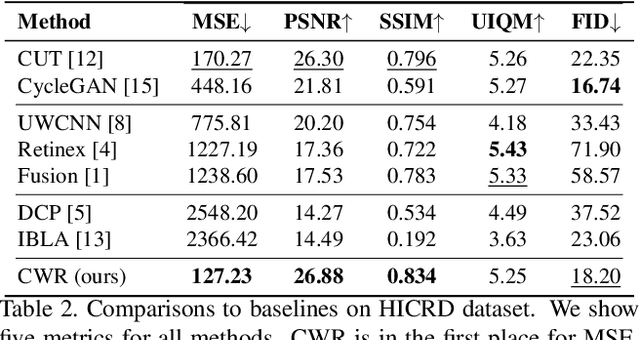
Underwater image restoration attracts significant attention due to its importance in unveiling the underwater world. This paper elaborates on a novel method that achieves state-of-the-art results for underwater image restoration based on the unsupervised image-to-image translation framework. We design our method by leveraging from contrastive learning and generative adversarial networks to maximize mutual information between raw and restored images. Additionally, we release a large-scale real underwater image dataset to support both paired and unpaired training modules. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method.
Mosaic Super-resolution via Sequential Feature Pyramid Networks
Apr 15, 2020
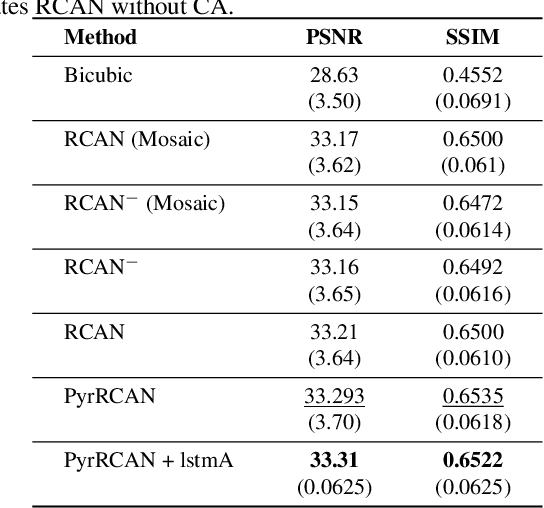
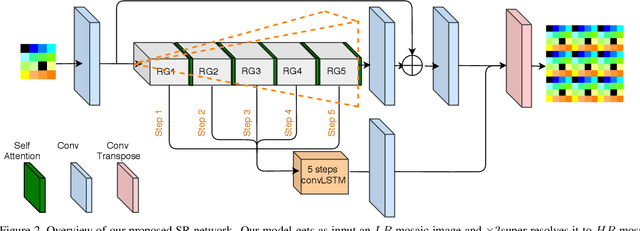
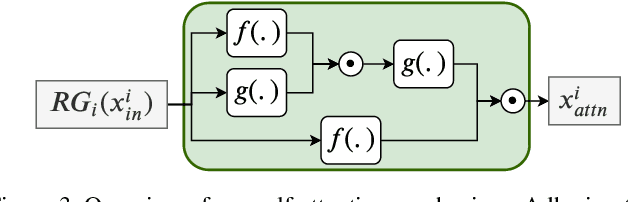
Advances in the design of multi-spectral cameras have led to great interests in a wide range of applications, from astronomy to autonomous driving. However, such cameras inherently suffer from a trade-off between the spatial and spectral resolution. In this paper, we propose to address this limitation by introducing a novel method to carry out super-resolution on raw mosaic images, multi-spectral or RGB Bayer, captured by modern real-time single-shot mosaic sensors. To this end, we design a deep super-resolution architecture that benefits from a sequential feature pyramid along the depth of the network. This, in fact, is achieved by utilizing a convolutional LSTM (ConvLSTM) to learn the inter-dependencies between features at different receptive fields. Additionally, by investigating the effect of different attention mechanisms in our framework, we show that a ConvLSTM inspired module is able to provide superior attention in our context. Our extensive experiments and analyses evidence that our approach yields significant super-resolution quality, outperforming current state-of-the-art mosaic super-resolution methods on both Bayer and multi-spectral images. Additionally, to the best of our knowledge, our method is the first specialized method to super-resolve mosaic images, whether it be multi-spectral or Bayer.
Multi-FAN: Multi-Spectral Mosaic Super-Resolution Via Multi-Scale Feature Aggregation Network
Sep 29, 2019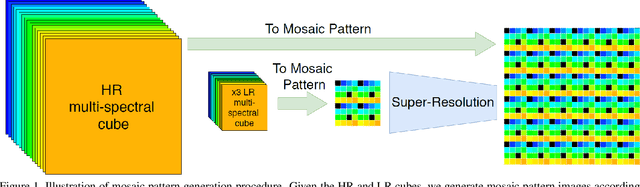

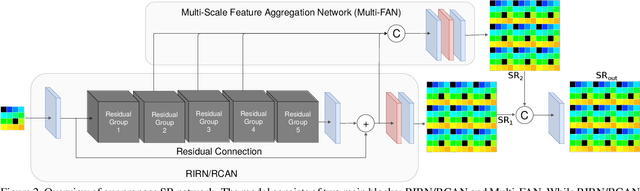
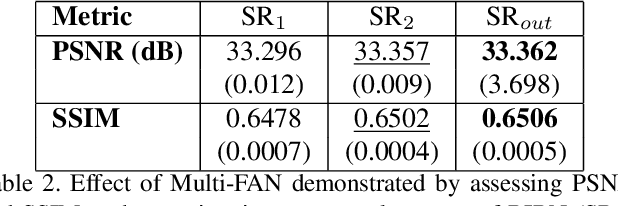
This paper introduces a novel method to super-resolve multi-spectral images captured by modern real-time single-shot mosaic image sensors, also known as multi-spectral cameras. Our contribution is two-fold. Firstly, we super-resolve multi-spectral images from mosaic images rather than image cubes, which helps to take into account the spatial offset of each wavelength. Secondly, we introduce an external multi-scale feature aggregation network (Multi-FAN) which concatenates the feature maps with different levels of semantic information throughout a super-resolution (SR) network. A cascade of convolutional layers then implicitly selects the most valuable feature maps to generate a mosaic image. This mosaic image is then merged with the mosaic image generated by the SR network to produce a quantitatively superior image. We apply our Multi-FAN to RCAN (Residual Channel Attention Network), which is the state-of-the-art SR algorithm. We show that Multi-FAN improves both quantitative results and well as inference time.
Super-resolved Chromatic Mapping of Snapshot Mosaic Image Sensors via a Texture Sensitive Residual Network
Sep 05, 2019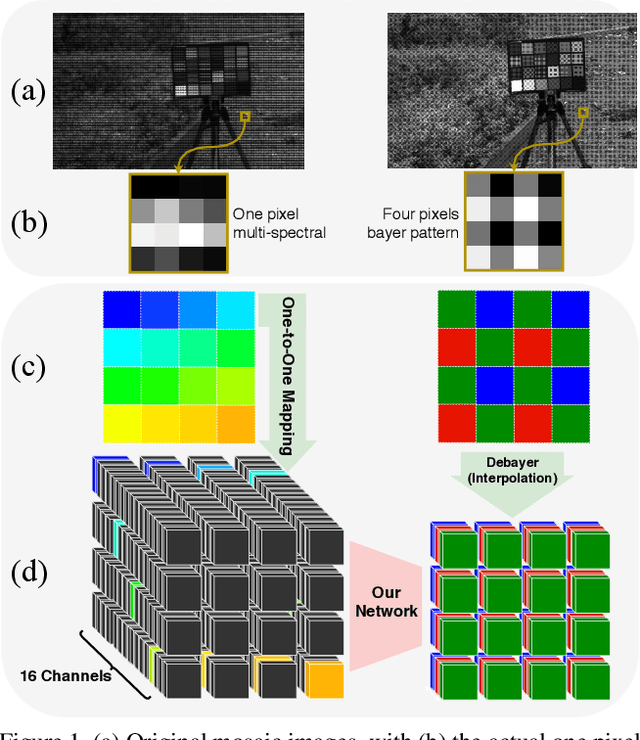
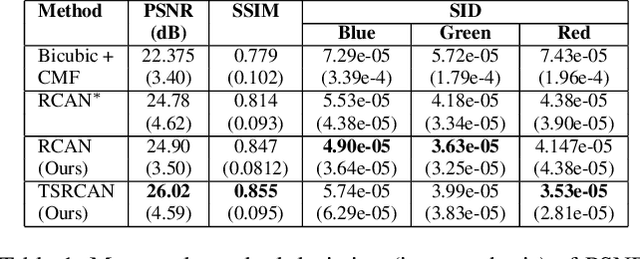
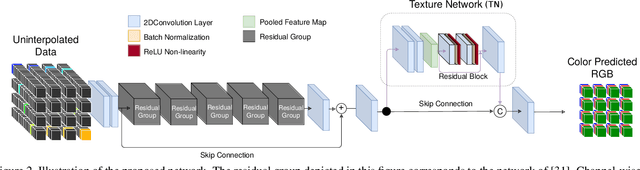
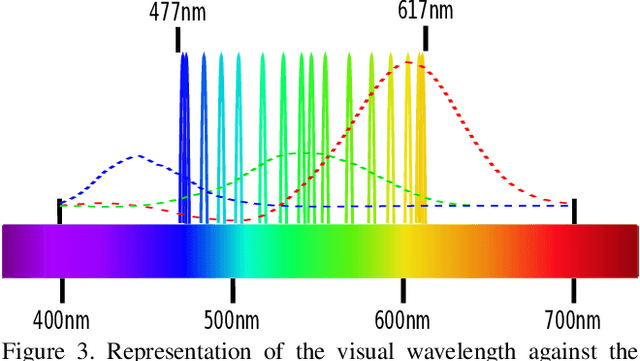
This paper introduces a novel method to simultaneously super-resolve and colour-predict images acquired by snapshot mosaic sensors. These sensors allow for spectral images to be acquired using low-power, small form factor, solid-state CMOS sensors that can operate at video frame rates without the need for complex optical setups. Despite their desirable traits, their main drawback stems from the fact that the spatial resolution of the imagery acquired by these sensors is low. Moreover, chromatic mapping in snapshot mosaic sensors is not straightforward since the bands delivered by the sensor tend to be narrow and unevenly distributed across the range in which they operate. We tackle this drawback as applied to chromatic mapping by using a residual channel attention network equipped with a texture sensitive block. Our method significantly outperforms the traditional approach of interpolating the image and, afterwards, applying a colour matching function. This work establishes state-of-the-art in this domain while also making available to the research community a dataset containing 296 registered stereo multi-spectral/RGB images pairs.
PIRM2018 Challenge on Spectral Image Super-Resolution: Dataset and Study
May 01, 2019


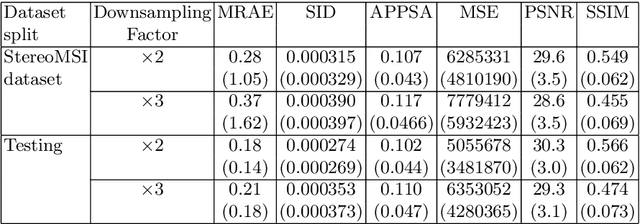
This paper introduces a newly collected and novel dataset (StereoMSI) for example-based single and colour-guided spectral image super-resolution. The dataset was first released and promoted during the PIRM2018 spectral image super-resolution challenge. To the best of our knowledge, the dataset is the first of its kind, comprising 350 registered colour-spectral image pairs. The dataset has been used for the two tracks of the challenge and, for each of these, we have provided a split into training, validation and testing. This arrangement is a result of the challenge structure and phases, with the first track focusing on example-based spectral image super-resolution and the second one aiming at exploiting the registered stereo colour imagery to improve the resolution of the spectral images. Each of the tracks and splits has been selected to be consistent across a number of image quality metrics. The dataset is quite general in nature and can be used for a wide variety of applications in addition to the development of spectral image super-resolution methods.