 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-supervised Representation Learning with Relative Predictive Coding
Apr 12, 2021

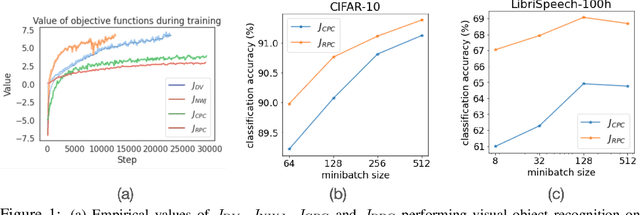
This paper introduces Relative Predictive Coding (RPC), a new contrastive representation learning objective that maintains a good balance among training stability, minibatch size sensitivity, and downstream task performance. The key to the success of RPC is two-fold. First, RPC introduces the relative parameters to regularize the objective for boundedness and low variance. Second, RPC contains no logarithm and exponential score functions, which are the main cause of training instability in prior contrastive objectives. We empirically verify the effectiveness of RPC on benchmark vision and speech self-supervised learning tasks. Lastly, we relate RPC with mutual information (MI) estimation, showing RPC can be used to estimate MI with low variance.
Hierarchical Cell-to-Tissue Graph Representations for Breast Cancer Subtyping in Digital Pathology
Feb 22, 2021
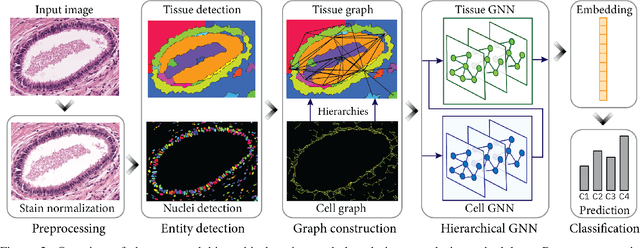
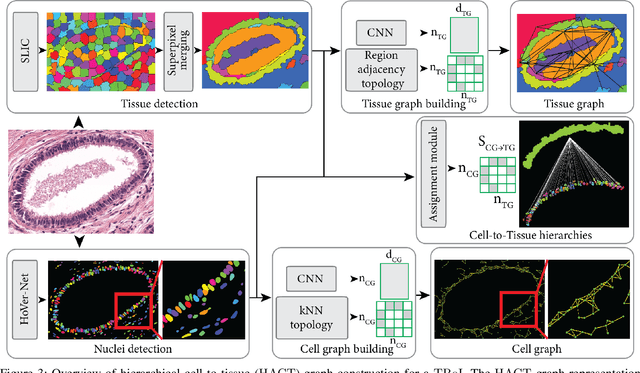
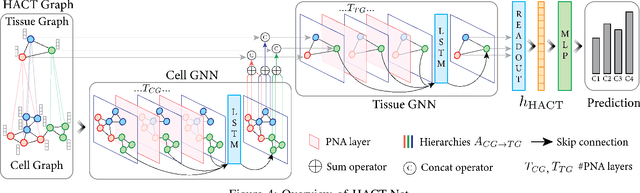
Cancer diagnosis and prognosis for a tissue specimen are heavily influenced by the phenotype and topological distribution of the constituting histological entities. Thus, adequate tissue representation by encoding the histological entities, and quantifying the relationship between the tissue representation and tissue functionality is imperative for computer aided cancer patient care. To this end, several approaches have leveraged cell-graphs, that encode cell morphology and organization, to denote the tissue information, and utilize graph theory and machine learning to map the representation to tissue functionality. Though cellular information is crucial, it is incomplete to comprehensively characterize the tissue. Therefore, we consider a tissue as a hierarchical composition of multiple types of histological entities from fine to coarse level, that depicts multivariate tissue information at multiple levels. We propose a novel hierarchical entity-graph representation to depict a tissue specimen, which encodes multiple pathologically relevant entity types, intra- and inter-level entity-to-entity interactions. Subsequently, a hierarchical graph neural network is proposed to operate on the entity-graph representation to map the tissue structure to tissue functionality. Specifically, we utilize cells and tissue regions in a tissue to build a HierArchical Cell-to-Tissue (HACT) graph representation, and HACT-Net, a graph neural network, to classify histology images. As part of this work, we propose the BReAst Carcinoma Subtyping (BRACS) dataset, a large cohort of Haematoxylin & Eosin stained breast tumor regions-of-interest, to evaluate and benchmark our proposed methodology against pathologists and state-of-the-art computer-aided diagnostic approaches. Thorough comparative assessment and ablation studies demonstrated the superior classification efficacy of the proposed methodology.
An RF-source-free microwave photonic radar with an optically injected semiconductor laser for high-resolution detection and imaging
Jun 11, 2021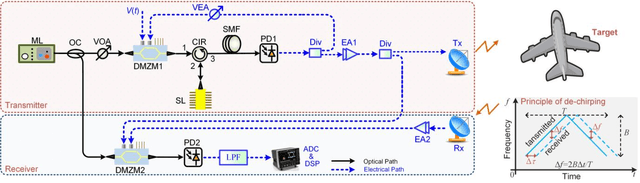
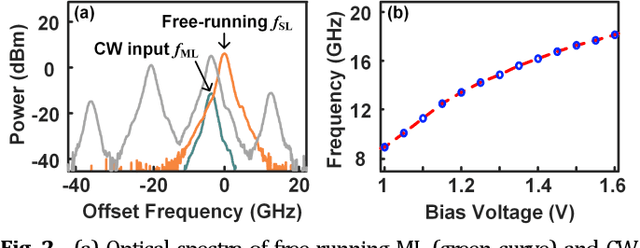
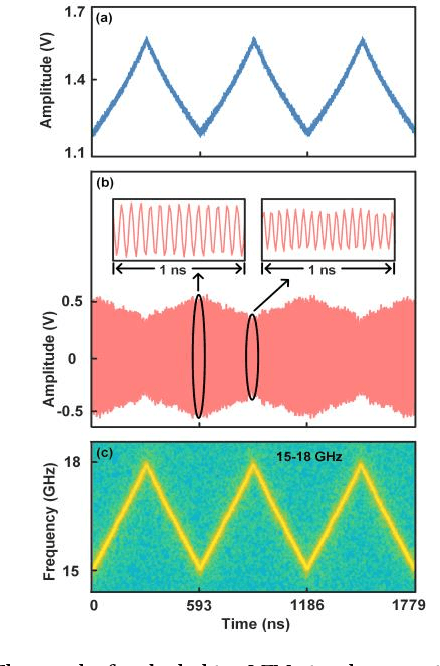
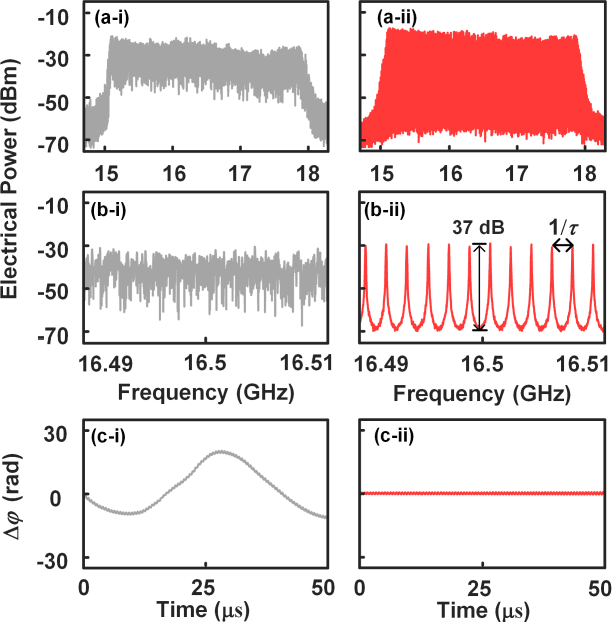
This paper presents a novel microwave photonic (MWP) radar scheme that is capable of optically generating and processing broadband linear frequency-modulated (LFM) microwave signals without using any radio-frequency (RF) sources. In the transmitter, a broadband LFM microwave signal is generated by controlling the period-one (P1) oscillation of an optically injected semiconductor laser. After targets reflection, photonic de-chirping is implemented based on a dual-drive Mach-Zehnder modulator (DMZM), which is followed by a low-speed analog-to-digital converter (ADC) and digital signal processer (DSP) to reconstruct target information. Without the limitations of external RF sources, the proposed radar has an ultra-flexible tunability, and the main operating parameters are adjustable, including central frequency, bandwidth, frequency band, and temporal period. In the experiment, a fully photonics-based Ku-band radar with a bandwidth of 4 GHz is established for high-resolution detection and inverse synthetic aperture radar (ISAR) imaging. Results show that a high range resolution reaching ~1.88 cm, and a two-dimensional (2D) imaging resolution as high as ~1.88 cm x ~2.00 cm are achieved with a sampling rate of 100 MSa/s in the receiver. The flexible tunability of the radar is also experimentally investigated. The proposed radar scheme features low cost, simple structure, and high reconfigurability, which, hopefully, is to be used in future multifunction adaptive and miniaturized radars.
Machine-learning-based investigation on classifying binary and multiclass behavior outcomes of children with PIMD/SMID
May 13, 2021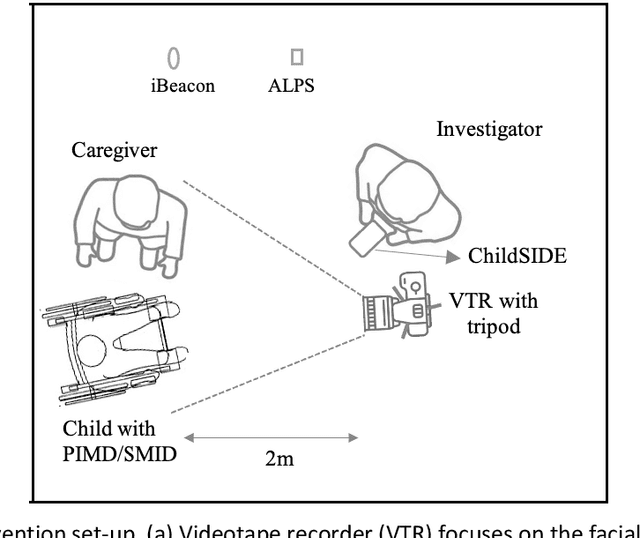
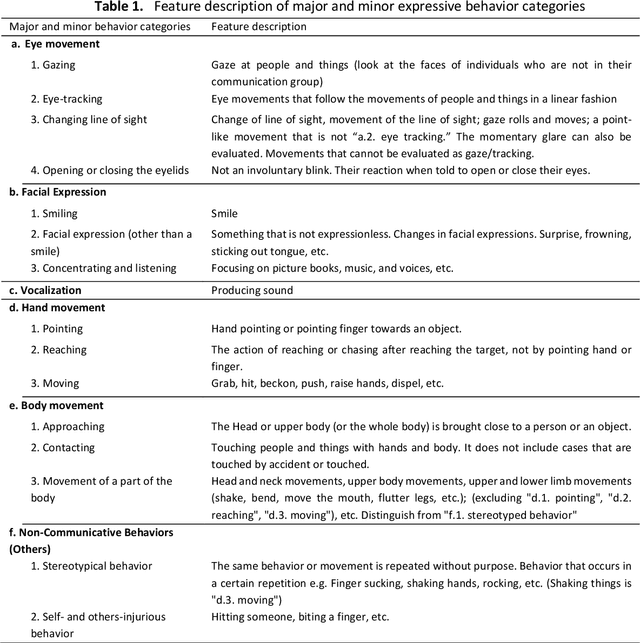
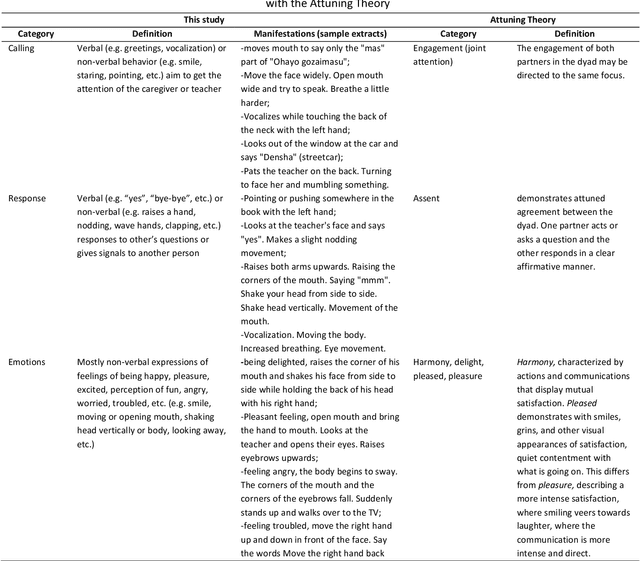
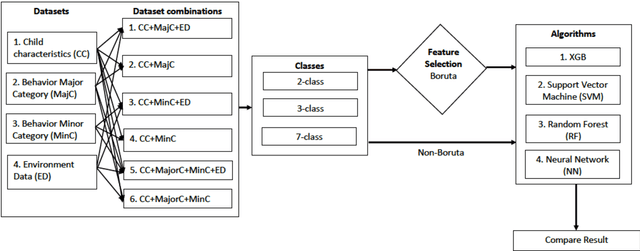
Recently, the importance of weather parameters and location information to better understand the context of the communication of children with profound intellectual and multiple disabilities (PIMD) or severe motor and intellectual disorders (SMID) has been proposed. However, an investigation on whether these data can be used to classify their behavior for system optimization aimed for predicting their behavior for independent communication and mobility has not been done. Thus, this study investigates whether recalibrating the datasets including either minor or major behavior categories or both, combining location and weather data and feature selection method training (Boruta) would allow more accurate classification of behavior discriminated to binary and multiclass classification outcomes using eXtreme Gradient Boosting (XGB), support vector machine (SVM), random forest (RF), and neural network (NN) classifiers. Multiple single-subject face-to-face and video-recorded sessions were conducted among 20 purposively sampled 8 to 10 -year old children diagnosed with PIMD/SMID or severe or profound intellectual disabilities and their caregivers.
Phoneme-Based Ratio Mask Estimation for Reverberant Speech Enhancement in Cochlear Implant Processors
May 28, 2021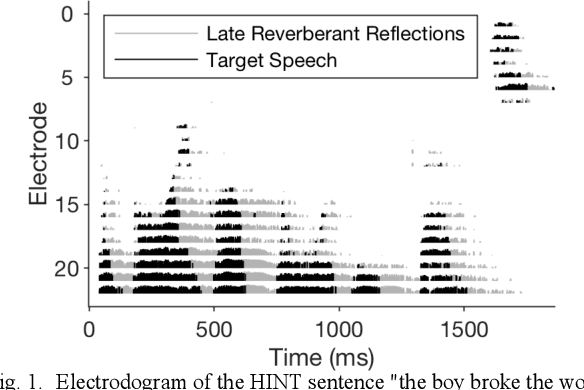
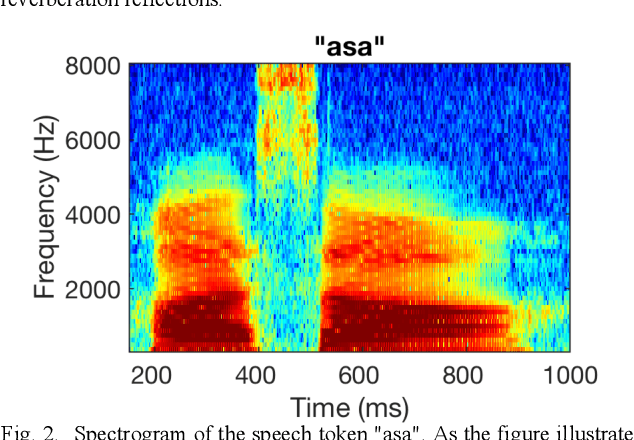
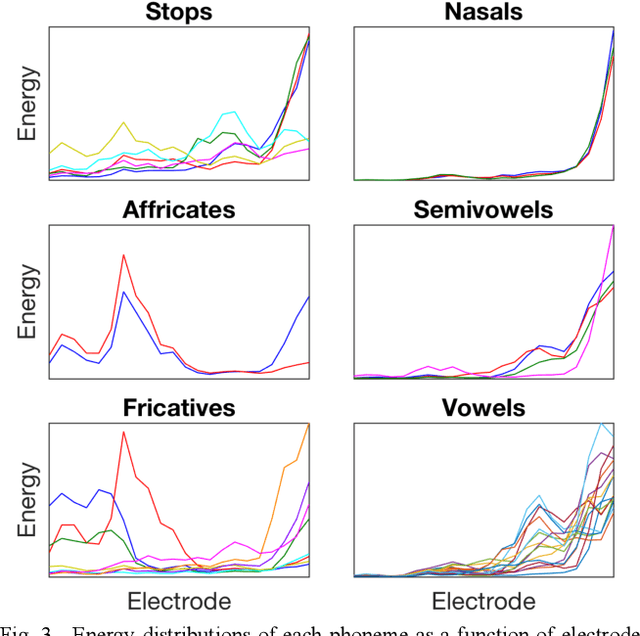
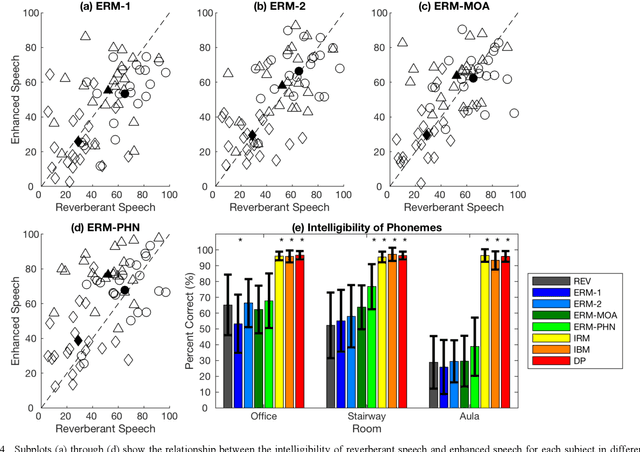
Cochlear implant (CI) users have considerable difficulty in understanding speech in reverberant listening environments. Time-frequency (T-F) masking is a common technique that aims to improve speech intelligibility by multiplying reverberant speech by a matrix of gain values to suppress T-F bins dominated by reverberation. Recently proposed mask estimation algorithms leverage machine learning approaches to distinguish between target speech and reverberant reflections. However, the spectro-temporal structure of speech is highly variable and dependent on the underlying phoneme. One way to potentially overcome this variability is to leverage explicit knowledge of phonemic information during mask estimation. This study proposes a phoneme-based mask estimation algorithm, where separate mask estimation models are trained for each phoneme. Sentence recognition tests were conducted in normal hearing listeners to determine whether a phoneme-based mask estimation algorithm is beneficial in the ideal scenario where perfect knowledge of the phoneme is available. The results showed that the phoneme-based masks improved the intelligibility of vocoded speech when compared to conventional phoneme-independent masks. The results suggest that a phoneme-based speech enhancement strategy may potentially benefit CI users in reverberant listening environments.
A Non-Linear Structural Probe
May 21, 2021
Probes are models devised to investigate the encoding of knowledge -- e.g. syntactic structure -- in contextual representations. Probes are often designed for simplicity, which has led to restrictions on probe design that may not allow for the full exploitation of the structure of encoded information; one such restriction is linearity. We examine the case of a structural probe (Hewitt and Manning, 2019), which aims to investigate the encoding of syntactic structure in contextual representations through learning only linear transformations. By observing that the structural probe learns a metric, we are able to kernelize it and develop a novel non-linear variant with an identical number of parameters. We test on 6 languages and find that the radial-basis function (RBF) kernel, in conjunction with regularization, achieves a statistically significant improvement over the baseline in all languages -- implying that at least part of the syntactic knowledge is encoded non-linearly. We conclude by discussing how the RBF kernel resembles BERT's self-attention layers and speculate that this resemblance leads to the RBF-based probe's stronger performance.
Navigation of a Self-Driving Vehicle Using One Fiducial Marker
Apr 28, 2021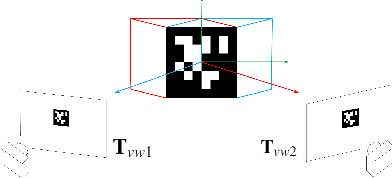
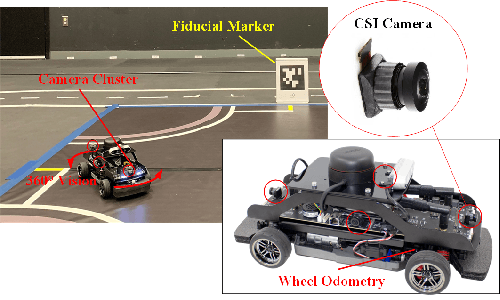
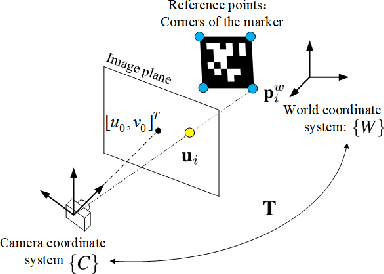
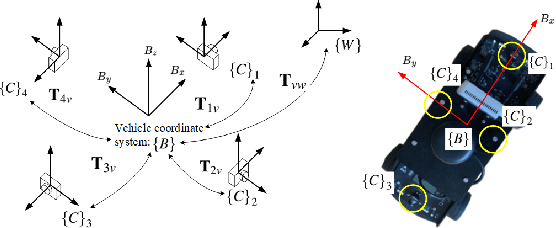
Navigation using only one marker, which contains four artificial features, is a challenging task since camera pose estimation using only four coplanar points suffers from the rotational ambiguity problem in a real-world application. This paper presents a framework of vision-based navigation for a self-driving vehicle equipped with multiple cameras and a wheel odometer. A multiple camera setup is presented for the camera cluster which has 360-degree vision such that our framework solely requires one planar marker. A Kalman-Filter-based fusion method is introduced for the multiple-camera and wheel odometry. Furthermore, an algorithm is proposed to resolve the rotational ambiguity problem using the prediction of the Kalman Filter as additional information. Finally, the lateral and longitudinal controllers are provided. Experiments are conducted to illustrate the effectiveness of the theory.
Directed Acyclic Graph Neural Networks
Jan 20, 2021



Graph-structured data ubiquitously appears in science and engineering. Graph neural networks (GNNs) are designed to exploit the relational inductive bias exhibited in graphs; they have been shown to outperform other forms of neural networks in scenarios where structure information supplements node features. The most common GNN architecture aggregates information from neighborhoods based on message passing. Its generality has made it broadly applicable. In this paper, we focus on a special, yet widely used, type of graphs -- DAGs -- and inject a stronger inductive bias -- partial ordering -- into the neural network design. We propose the \emph{directed acyclic graph neural network}, DAGNN, an architecture that processes information according to the flow defined by the partial order. DAGNN can be considered a framework that entails earlier works as special cases (e.g., models for trees and models updating node representations recurrently), but we identify several crucial components that prior architectures lack. We perform comprehensive experiments, including ablation studies, on representative DAG datasets (i.e., source code, neural architectures, and probabilistic graphical models) and demonstrate the superiority of DAGNN over simpler DAG architectures as well as general graph architectures.
Linear-Time Self Attention with Codeword Histogram for Efficient Recommendation
May 28, 2021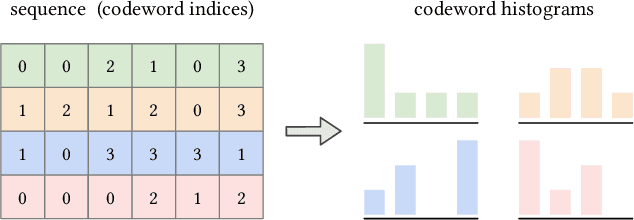
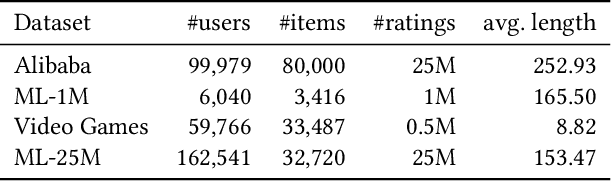
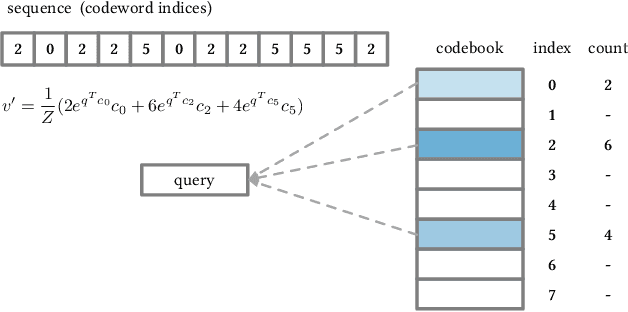
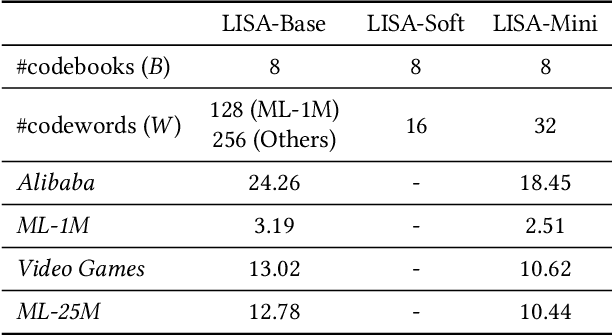
Self-attention has become increasingly popular in a variety of sequence modeling tasks from natural language processing to recommendation, due to its effectiveness. However, self-attention suffers from quadratic computational and memory complexities, prohibiting its applications on long sequences. Existing approaches that address this issue mainly rely on a sparse attention context, either using a local window, or a permuted bucket obtained by locality-sensitive hashing (LSH) or sorting, while crucial information may be lost. Inspired by the idea of vector quantization that uses cluster centroids to approximate items, we propose LISA (LInear-time Self Attention), which enjoys both the effectiveness of vanilla self-attention and the efficiency of sparse attention. LISA scales linearly with the sequence length, while enabling full contextual attention via computing differentiable histograms of codeword distributions. Meanwhile, unlike some efficient attention methods, our method poses no restriction on casual masking or sequence length. We evaluate our method on four real-world datasets for sequential recommendation. The results show that LISA outperforms the state-of-the-art efficient attention methods in both performance and speed; and it is up to 57x faster and 78x more memory efficient than vanilla self-attention.
CounQER: A System for Discovering and Linking Count Information in Knowledge Bases
May 07, 2020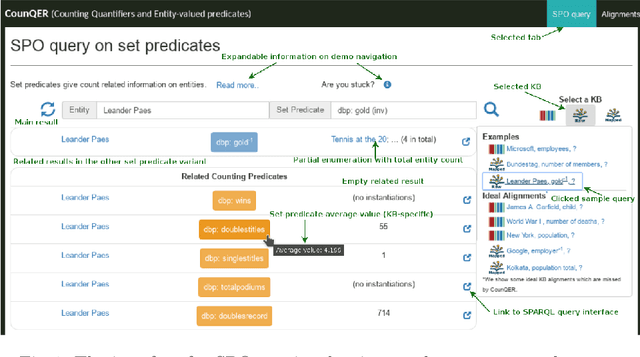
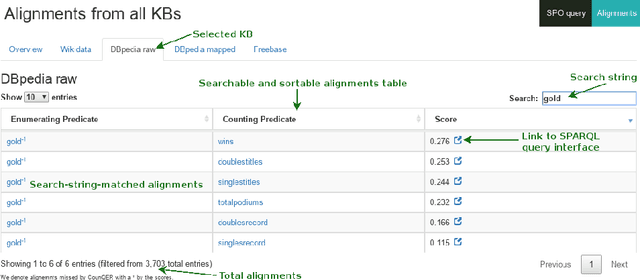
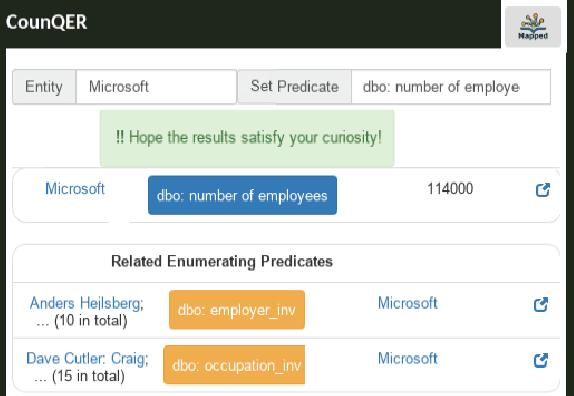
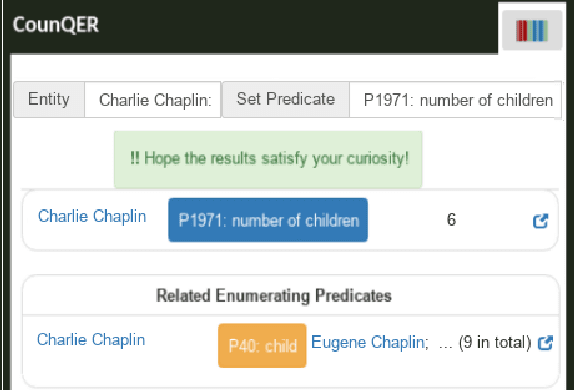
Predicate constraints of general-purpose knowledge bases (KBs) like Wikidata, DBpedia and Freebase are often limited to subproperty, domain and range constraints. In this demo we showcase CounQER, a system that illustrates the alignment of counting predicates, like staffSize, and enumerating predicates, like workInstitution^{-1} . In the demonstration session, attendees can inspect these alignments, and will learn about the importance of these alignments for KB question answering and curation. CounQER is available at https://counqer.mpi-inf.mpg.de/spo.