 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLFTSim: Realistic and Controllable Multi-Agent Traffic Simulation via Reinforcement Learning Fine-Tuning
May 18, 2026Supervised open-loop training has been widely adopted for training traffic simulation models; however, it fails to capture the inherently dynamic, multi-agent interactions common in complex driving scenarios. We introduce RLFTSim, a reinforcement-learning-based fine-tuning framework that enhances scenario realism by aligning simulator rollouts with real-world data distributions and provides a method for distilling goal-conditioned controllability in scenario generation. We instantiate RLFTSim on top of a pre-trained simulation model, design a reward that balances fidelity and controllability, and perform comprehensive experiments on the Waymo Open Motion Dataset. Our results show improvements in realism, achieving state-of-the-art performance. Compared with other heuristic search-based fine-tuning methods, RLFTSim requires significantly fewer samples due to a proposed low-variance and dense reward signal, and it directly addresses the realism alignment issue by design. We also demonstrate the effectiveness of our approach for distilling traffic simulation controllability through goal conditioning. The project page is available at https://ehsan-ami.github.io/rlftsim.
SEP-NMPC: Safety Enhanced Passivity-Based Nonlinear Model Predictive Control for a UAV Slung Payload System
Mar 09, 2026Model Predictive Control (MPC) is widely adopted for agile multirotor vehicles, yet achieving both stability and obstacle-free flight is particularly challenging when a payload is suspended beneath the airframe. This paper introduces a Safety Enhanced Passivity-Based Nonlinear MPC (SEP-NMPC) that provides formal guarantees of stability and safety for a quadrotor transporting a slung payload through cluttered environments. Stability is enforced by embedding a strict passivity inequality, which is derived from a shaped energy storage function with adaptive damping, directly into the NMPC. This formulation dissipates excess energy and ensures asymptotic convergence despite payload swings. Safety is guaranteed through high-order control barrier functions (HOCBFs) that render user-defined clearance sets forward-invariant, obliging both the quadrotor and the swinging payload to maintain separation while interacting with static and dynamic obstacles. The optimization remains quadratic-program compatible and is solved online at each sampling time without gain scheduling or heuristic switching. Extensive simulations and real-world experiments confirm stable payload transport, collision-free trajectories, and real-time feasibility across all tested scenarios. The SEP-NMPC framework therefore unifies passivity-based closed-loop stability with HOCBF-based safety guarantees for UAV slung-payload transportation.
STaR: Scalable Task-Conditioned Retrieval for Long-Horizon Multimodal Robot Memory
Feb 12, 2026Mobile robots are often deployed over long durations in diverse open, dynamic scenes, including indoor setting such as warehouses and manufacturing facilities, and outdoor settings such as agricultural and roadway operations. A core challenge is to build a scalable long-horizon memory that supports an agentic workflow for planning, retrieval, and reasoning over open-ended instructions at variable granularity, while producing precise, actionable answers for navigation. We present STaR, an agentic reasoning framework that (i) constructs a task-agnostic, multimodal long-term memory that generalizes to unseen queries while preserving fine-grained environmental semantics (object attributes, spatial relations, and dynamic events), and (ii) introduces a Scalable Task Conditioned Retrieval algorithm based on the Information Bottleneck principle to extract from long-term memory a compact, non-redundant, information-rich set of candidate memories for contextual reasoning. We evaluate STaR on NaVQA (mixed indoor/outdoor campus scenes) and WH-VQA, a customized warehouse benchmark with many visually similar objects built with Isaac Sim, emphasizing contextual reasoning. Across the two datasets, STaR consistently outperforms strong baselines, achieving higher success rates and markedly lower spatial error. We further deploy STaR on a real Husky wheeled robot in both indoor and outdoor environments, demonstrating robust long horizon reasoning, scalability, and practical utility. Project Website: https://trailab.github.io/STaR-website/
VQA-Diff: Exploiting VQA and Diffusion for Zero-Shot Image-to-3D Vehicle Asset Generation in Autonomous Driving
Jul 10, 2024



Generating 3D vehicle assets from in-the-wild observations is crucial to autonomous driving. Existing image-to-3D methods cannot well address this problem because they learn generation merely from image RGB information without a deeper understanding of in-the-wild vehicles (such as car models, manufacturers, etc.). This leads to their poor zero-shot prediction capability to handle real-world observations with occlusion or tricky viewing angles. To solve this problem, in this work, we propose VQA-Diff, a novel framework that leverages in-the-wild vehicle images to create photorealistic 3D vehicle assets for autonomous driving. VQA-Diff exploits the real-world knowledge inherited from the Large Language Model in the Visual Question Answering (VQA) model for robust zero-shot prediction and the rich image prior knowledge in the Diffusion model for structure and appearance generation. In particular, we utilize a multi-expert Diffusion Models strategy to generate the structure information and employ a subject-driven structure-controlled generation mechanism to model appearance information. As a result, without the necessity to learn from a large-scale image-to-3D vehicle dataset collected from the real world, VQA-Diff still has a robust zero-shot image-to-novel-view generation ability. We conduct experiments on various datasets, including Pascal 3D+, Waymo, and Objaverse, to demonstrate that VQA-Diff outperforms existing state-of-the-art methods both qualitatively and quantitatively.
Vectorized Representation Dreamer (VRD): Dreaming-Assisted Multi-Agent Motion-Forecasting
Jun 20, 2024



For an autonomous vehicle to plan a path in its environment, it must be able to accurately forecast the trajectory of all dynamic objects in its proximity. While many traditional methods encode observations in the scene to solve this problem, there are few approaches that consider the effect of the ego vehicle's behavior on the future state of the world. In this paper, we introduce VRD, a vectorized world model-inspired approach to the multi-agent motion forecasting problem. Our method combines a traditional open-loop training regime with a novel dreamed closed-loop training pipeline that leverages a kinematic reconstruction task to imagine the trajectory of all agents, conditioned on the action of the ego vehicle. Quantitative and qualitative experiments are conducted on the Argoverse 2 multi-world forecasting evaluation dataset and the intersection drone (inD) dataset to demonstrate the performance of our proposed model. Our model achieves state-of-the-art performance on the single prediction miss rate metric on the Argoverse 2 dataset and performs on par with the leading models for the single prediction displacement metrics.
L-PR: Exploiting LiDAR Fiducial Marker for Unordered Low Overlap Multiview Point Cloud Registration
Jun 05, 2024



Point cloud registration is a prerequisite for many applications in computer vision and robotics. Most existing methods focus on pairwise registration of two point clouds with high overlap. Although there have been some methods for low overlap cases, they struggle in degraded scenarios. This paper introduces a novel framework named L-PR, designed to register unordered low overlap multiview point clouds leveraging LiDAR fiducial markers. We refer to them as LiDAR fiducial markers, but they are the same as the popular AprilTag and ArUco markers, thin sheets of paper that do not affect the 3D geometry of the environment. We first propose an improved adaptive threshold marker detection method to provide robust detection results when the viewpoints among point clouds change dramatically. Then, we formulate the unordered multiview point cloud registration problem as a maximum a-posteriori (MAP) problem and develop a framework consisting of two levels of graphs to address it. The first-level graph, constructed as a weighted graph, is designed to efficiently and optimally infer initial values of scan poses from the unordered set. The second-level graph is constructed as a factor graph. By globally optimizing the variables on the graph, including scan poses, marker poses, and marker corner positions, we tackle the MAP problem. We conduct qualitative and quantitative experiments to demonstrate that the proposed method exhibits superiority over competitors in four aspects: registration accuracy, instance reconstruction quality, localization accuracy, and robustness to the degraded scene. To benefit the community, we open-source our method and dataset at https://github.com/yorklyb/LiDAR-SFM.
A Factor Graph Model of Trust for a Collaborative Multi-Agent System
Feb 10, 2024



In the field of Multi-Agent Systems (MAS), known for their openness, dynamism, and cooperative nature, the ability to trust the resources and services of other agents is crucial. Trust, in this setting, is the reliance and confidence an agent has in the information, behaviors, intentions, truthfulness, and capabilities of others within the system. Our paper introduces a new graphical approach that utilizes factor graphs to represent the interdependent behaviors and trustworthiness among agents. This includes modeling the behavior of robots as a trajectory of actions using a Gaussian process factor graph, which accounts for smoothness, obstacle avoidance, and trust-related factors. Our method for evaluating trust is decentralized and considers key interdependent sub-factors such as proximity safety, consistency, and cooperation. The overall system comprises a network of factor graphs that interact through trust-related factors and employs a Bayesian inference method to dynamically assess trust-based decisions with informed consent. The effectiveness of this method is validated via simulations and empirical tests with autonomous robots navigating unsignalized intersections.
GPT-4 and Safety Case Generation: An Exploratory Analysis
Dec 09, 2023In the ever-evolving landscape of software engineering, the emergence of large language models (LLMs) and conversational interfaces, exemplified by ChatGPT, is nothing short of revolutionary. While their potential is undeniable across various domains, this paper sets out on a captivating expedition to investigate their uncharted territory, the exploration of generating safety cases. In this paper, our primary objective is to delve into the existing knowledge base of GPT-4, focusing specifically on its understanding of the Goal Structuring Notation (GSN), a well-established notation allowing to visually represent safety cases. Subsequently, we perform four distinct experiments with GPT-4. These experiments are designed to assess its capacity for generating safety cases within a defined system and application domain. To measure the performance of GPT-4 in this context, we compare the results it generates with ground-truth safety cases created for an X-ray system system and a Machine-Learning (ML)-enabled component for tire noise recognition (TNR) in a vehicle. This allowed us to gain valuable insights into the model's generative capabilities. Our findings indicate that GPT-4 demonstrates the capacity to produce safety arguments that are moderately accurate and reasonable. Furthermore, it exhibits the capability to generate safety cases that closely align with the semantic content of the reference safety cases used as ground-truths in our experiments.
Fiducial Marker Detection in Multi-Viewpoint Point Cloud
Sep 02, 2022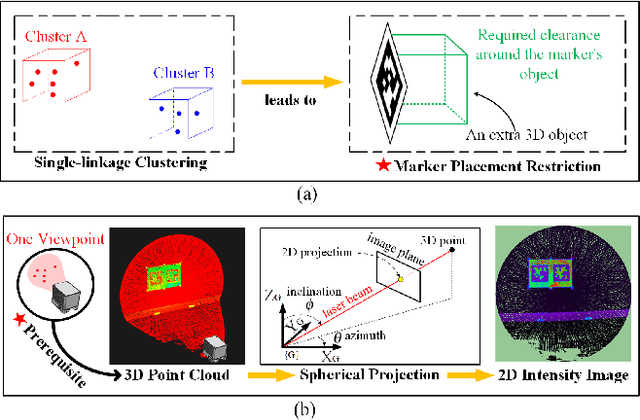
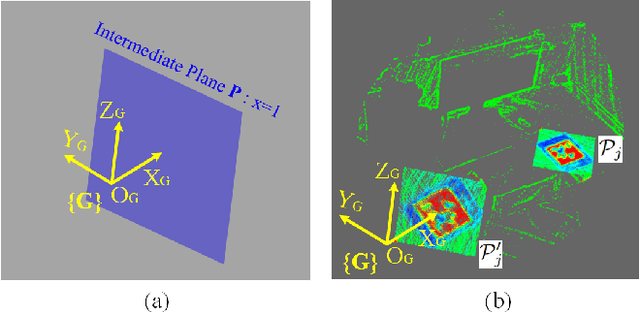
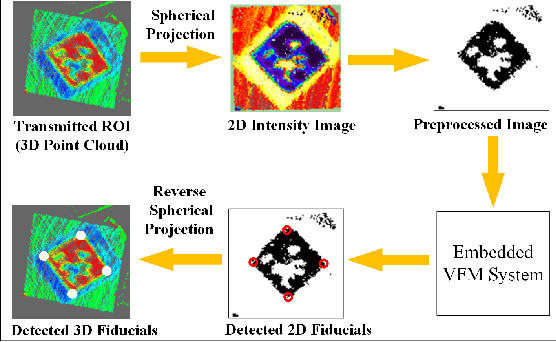
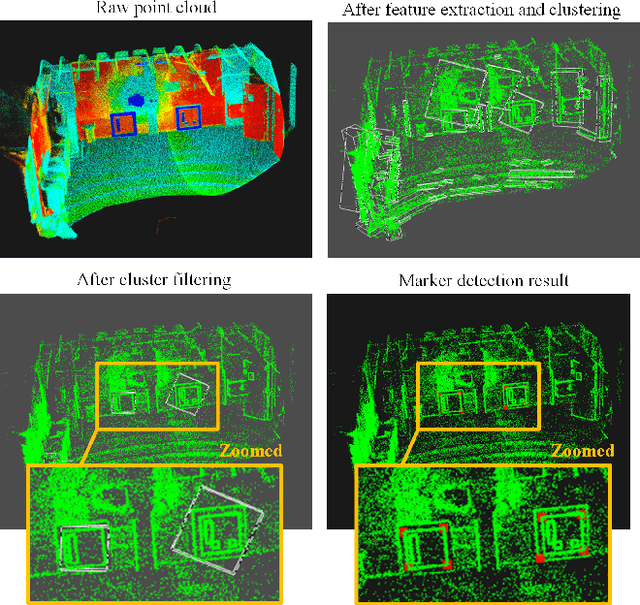
The existing LiDAR fiducial marker systems have usage restrictions. Especially, LiDARTag requires a specific marker placement and Intensity Image-based LiDAR Fiducial Marker demands that the point cloud is sampled from one viewpoint. As a result, with point clouds sampled from multiple viewpoints, fiducial marker detection remains an unsolved problem. In this letter, we develop a novel algorithm to detect the fiducial markers in the multi-viewpoint point cloud. The proposed algorithm includes two stages. First, Regions of Interest (ROIs) detection finds point clusters that could contain fiducial markers. Specifically, a method extracting the ROIs from the intensity perspective is introduced on account of the fact that from the spatial perspective, the markers, which are sheets of paper or thin boards, are non-distinguishable from the planes to which they are attached. Second, marker detection verifies if the candidate ROIs contain fiducial markers and outputs the ID numbers and vertices locations of the markers in the valid ROIs. In particular, the ROIs are transmitted to a predefined intermediate plane for the purpose of adopting a spherical projection to generate the intensity image, and then, marker detection is completed through the intensity image. Qualitative and quantitative experimental results are provided to validate the proposed algorithm. The codes and results are available at: https://github.com/York-SDCNLab/Marker?Detection-General
Intensity Image-based LiDAR Fiducial Marker System
Mar 03, 2022
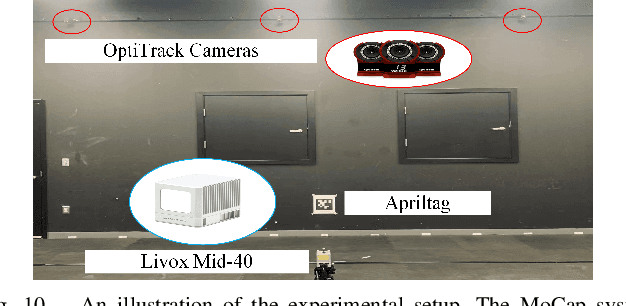
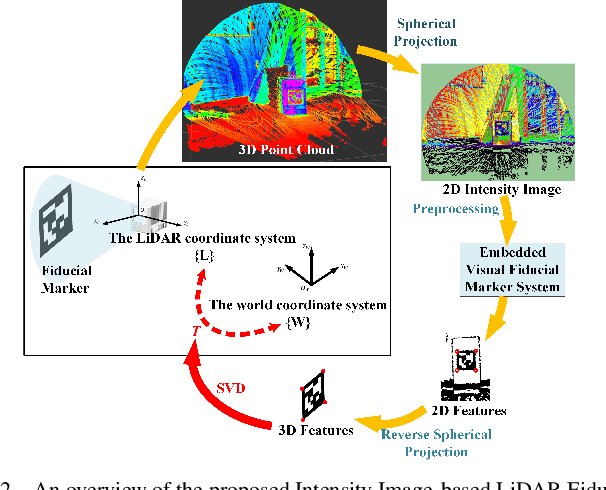
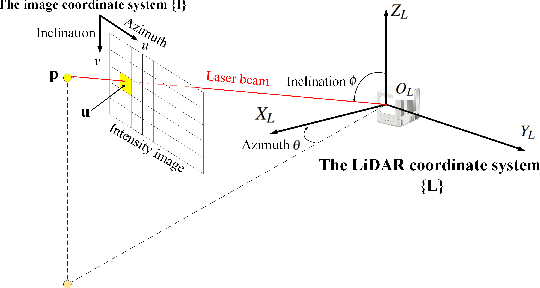
The fiducial marker system for LiDAR is crucial for the robotic application but it is still rare to date. In this paper, an Intensity Image-based LiDAR Fiducial Marker (IILFM) system is developed. This system only requires an unstructured point cloud with intensity as the input and it has no restriction on marker placement and shape. A marker detection method that locates the predefined 3D fiducials in the point cloud through the intensity image is introduced. Then, an approach that utilizes the detected 3D fiducials to estimate the LiDAR 6-DOF pose that describes the transmission from the world coordinate system to the LiDAR coordinate system is developed. Moreover, all these processes run in real-time (approx 40 Hz on Livox Mid-40 and approx 143 Hz on VLP-16). Qualitative and quantitative experiments are conducted to demonstrate that the proposed system has similar convenience and accuracy as the conventional visual fiducial marker system. The codes and results are available at: https://github.com/York-SDCNLab/IILFM.