 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-Time Self Attention with Codeword Histogram for Efficient Recommendation
Paper and Code
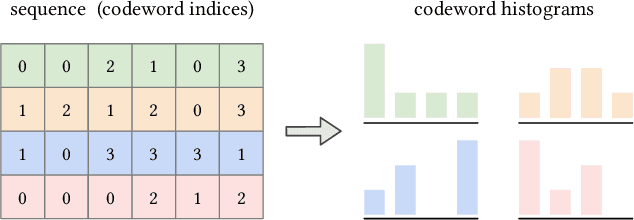
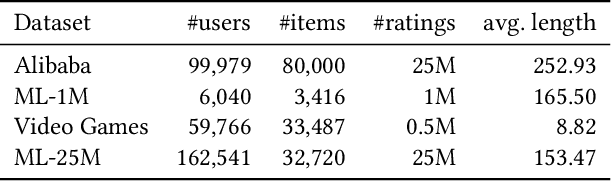
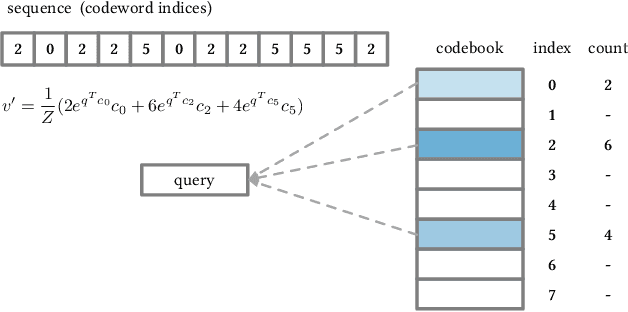
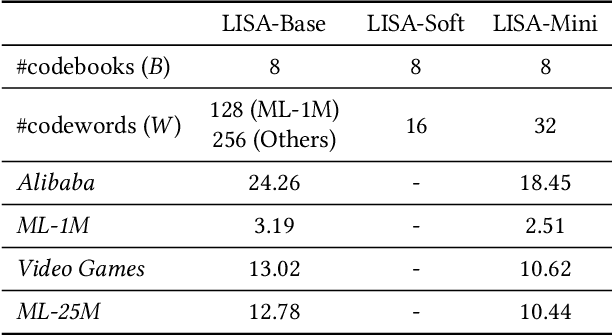
Self-attention has become increasingly popular in a variety of sequence modeling tasks from natural language processing to recommendation, due to its effectiveness. However, self-attention suffers from quadratic computational and memory complexities, prohibiting its applications on long sequences. Existing approaches that address this issue mainly rely on a sparse attention context, either using a local window, or a permuted bucket obtained by locality-sensitive hashing (LSH) or sorting, while crucial information may be lost. Inspired by the idea of vector quantization that uses cluster centroids to approximate items, we propose LISA (LInear-time Self Attention), which enjoys both the effectiveness of vanilla self-attention and the efficiency of sparse attention. LISA scales linearly with the sequence length, while enabling full contextual attention via computing differentiable histograms of codeword distributions. Meanwhile, unlike some efficient attention methods, our method poses no restriction on casual masking or sequence length. We evaluate our method on four real-world datasets for sequential recommendation. The results show that LISA outperforms the state-of-the-art efficient attention methods in both performance and speed; and it is up to 57x faster and 78x more memory efficient than vanilla self-attention.