 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLFTSim: Realistic and Controllable Multi-Agent Traffic Simulation via Reinforcement Learning Fine-Tuning
May 18, 2026Supervised open-loop training has been widely adopted for training traffic simulation models; however, it fails to capture the inherently dynamic, multi-agent interactions common in complex driving scenarios. We introduce RLFTSim, a reinforcement-learning-based fine-tuning framework that enhances scenario realism by aligning simulator rollouts with real-world data distributions and provides a method for distilling goal-conditioned controllability in scenario generation. We instantiate RLFTSim on top of a pre-trained simulation model, design a reward that balances fidelity and controllability, and perform comprehensive experiments on the Waymo Open Motion Dataset. Our results show improvements in realism, achieving state-of-the-art performance. Compared with other heuristic search-based fine-tuning methods, RLFTSim requires significantly fewer samples due to a proposed low-variance and dense reward signal, and it directly addresses the realism alignment issue by design. We also demonstrate the effectiveness of our approach for distilling traffic simulation controllability through goal conditioning. The project page is available at https://ehsan-ami.github.io/rlftsim.
Vectorized Representation Dreamer (VRD): Dreaming-Assisted Multi-Agent Motion-Forecasting
Jun 20, 2024



For an autonomous vehicle to plan a path in its environment, it must be able to accurately forecast the trajectory of all dynamic objects in its proximity. While many traditional methods encode observations in the scene to solve this problem, there are few approaches that consider the effect of the ego vehicle's behavior on the future state of the world. In this paper, we introduce VRD, a vectorized world model-inspired approach to the multi-agent motion forecasting problem. Our method combines a traditional open-loop training regime with a novel dreamed closed-loop training pipeline that leverages a kinematic reconstruction task to imagine the trajectory of all agents, conditioned on the action of the ego vehicle. Quantitative and qualitative experiments are conducted on the Argoverse 2 multi-world forecasting evaluation dataset and the intersection drone (inD) dataset to demonstrate the performance of our proposed model. Our model achieves state-of-the-art performance on the single prediction miss rate metric on the Argoverse 2 dataset and performs on par with the leading models for the single prediction displacement metrics.
Fiducial Marker Detection in Multi-Viewpoint Point Cloud
Sep 02, 2022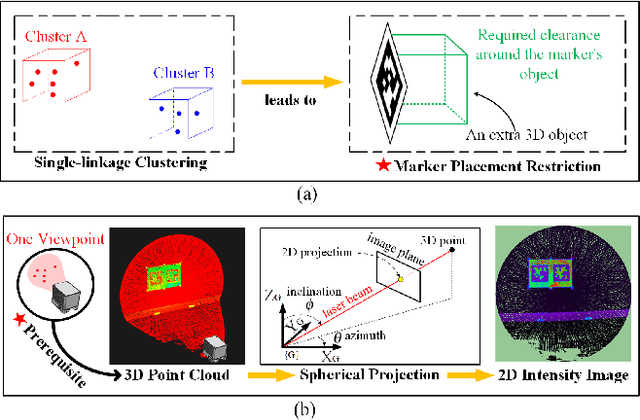
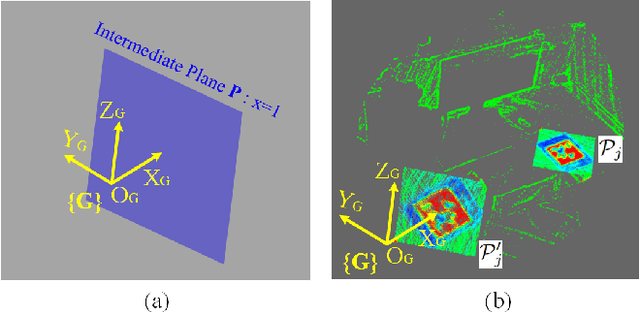
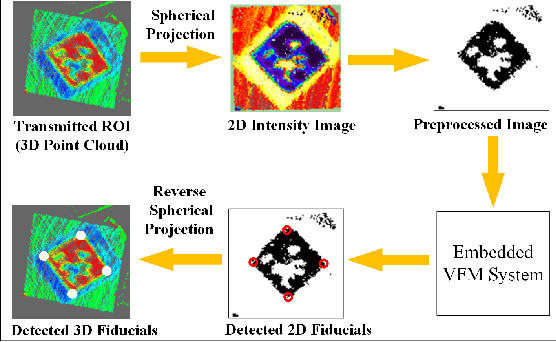
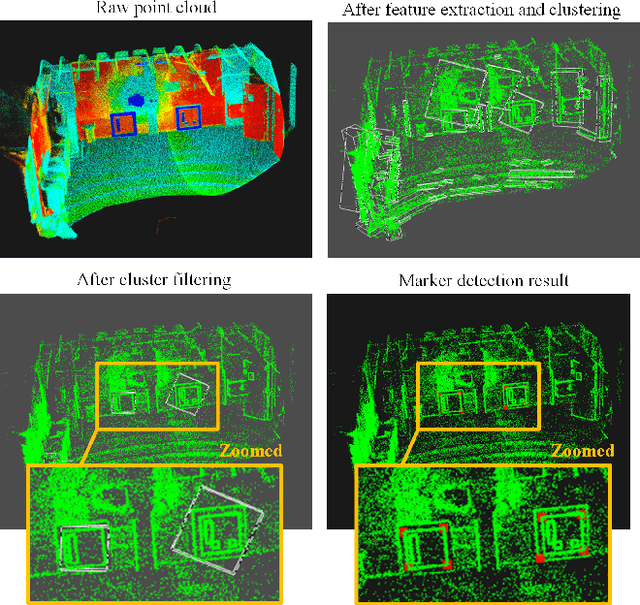
The existing LiDAR fiducial marker systems have usage restrictions. Especially, LiDARTag requires a specific marker placement and Intensity Image-based LiDAR Fiducial Marker demands that the point cloud is sampled from one viewpoint. As a result, with point clouds sampled from multiple viewpoints, fiducial marker detection remains an unsolved problem. In this letter, we develop a novel algorithm to detect the fiducial markers in the multi-viewpoint point cloud. The proposed algorithm includes two stages. First, Regions of Interest (ROIs) detection finds point clusters that could contain fiducial markers. Specifically, a method extracting the ROIs from the intensity perspective is introduced on account of the fact that from the spatial perspective, the markers, which are sheets of paper or thin boards, are non-distinguishable from the planes to which they are attached. Second, marker detection verifies if the candidate ROIs contain fiducial markers and outputs the ID numbers and vertices locations of the markers in the valid ROIs. In particular, the ROIs are transmitted to a predefined intermediate plane for the purpose of adopting a spherical projection to generate the intensity image, and then, marker detection is completed through the intensity image. Qualitative and quantitative experimental results are provided to validate the proposed algorithm. The codes and results are available at: https://github.com/York-SDCNLab/Marker?Detection-General
Intensity Image-based LiDAR Fiducial Marker System
Mar 03, 2022
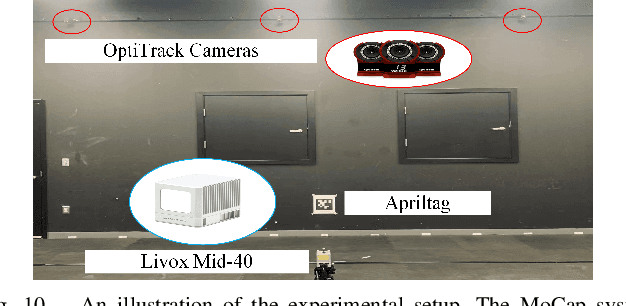
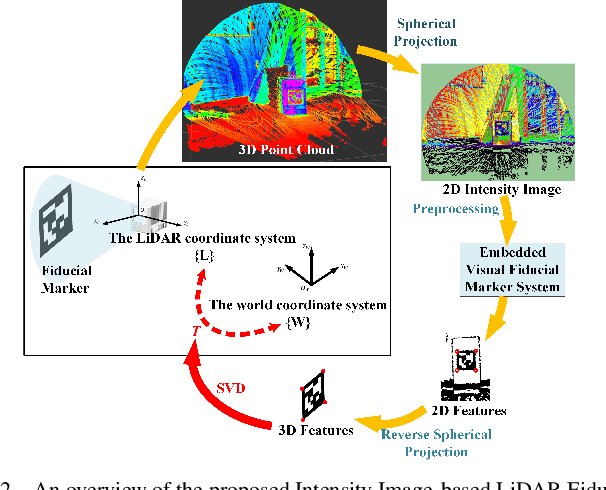
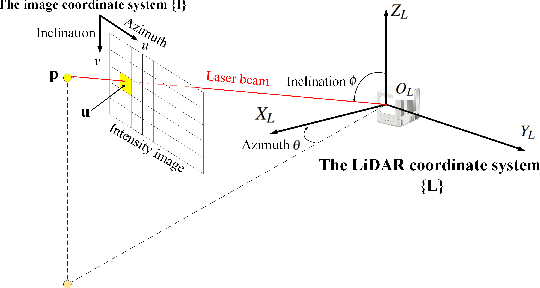
The fiducial marker system for LiDAR is crucial for the robotic application but it is still rare to date. In this paper, an Intensity Image-based LiDAR Fiducial Marker (IILFM) system is developed. This system only requires an unstructured point cloud with intensity as the input and it has no restriction on marker placement and shape. A marker detection method that locates the predefined 3D fiducials in the point cloud through the intensity image is introduced. Then, an approach that utilizes the detected 3D fiducials to estimate the LiDAR 6-DOF pose that describes the transmission from the world coordinate system to the LiDAR coordinate system is developed. Moreover, all these processes run in real-time (approx 40 Hz on Livox Mid-40 and approx 143 Hz on VLP-16). Qualitative and quantitative experiments are conducted to demonstrate that the proposed system has similar convenience and accuracy as the conventional visual fiducial marker system. The codes and results are available at: https://github.com/York-SDCNLab/IILFM.
Ghost-DeblurGAN and Its Application to Fiducial Marker System
Sep 12, 2021
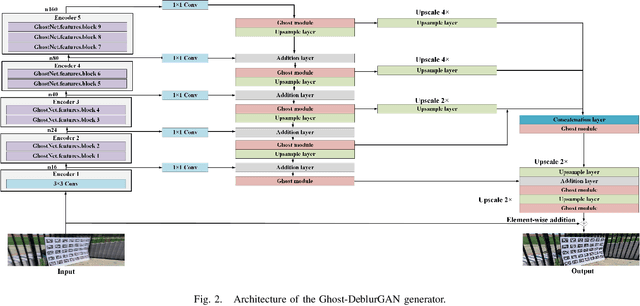
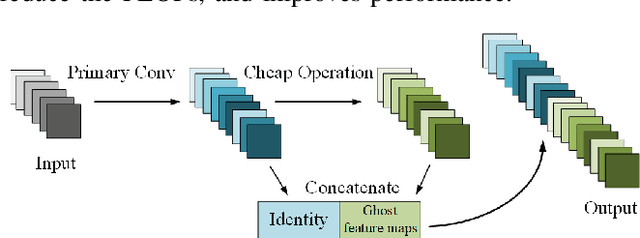
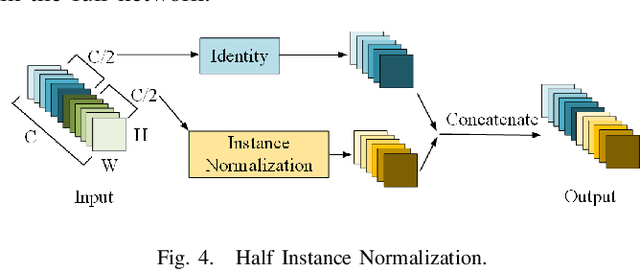
Motion blur can impede marker detection and marker-based pose estimation, which is common in real-world robotic applications involving fiducial markers. To solve this problem, we propose a novel lightweight generative adversarial network (GAN), Ghost-DeblurGAN, for real-time motion deblurring. Furthermore, a new large-scale dataset, YorkTag, provides pairs of sharp/blurred images containing fiducial markers and is proposed to train and qualitatively and quantitatively evaluate our model. Experimental results demonstrate that when applied along with fudicual marker systems to motion-blurred images, Ghost-DeblurGAN improves the marker detection significantly and mitigates the rotational ambiguity problem in marker-based pose estimation.
Navigation of a Self-Driving Vehicle Using One Fiducial Marker
Apr 28, 2021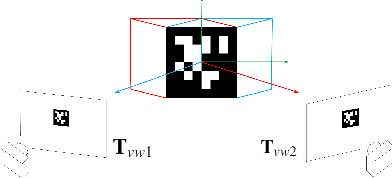
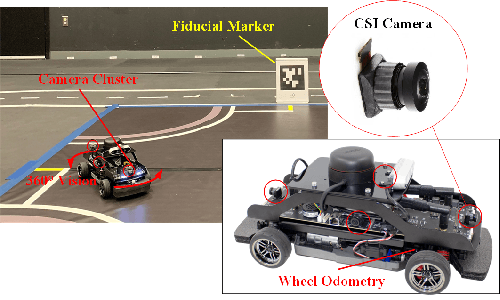
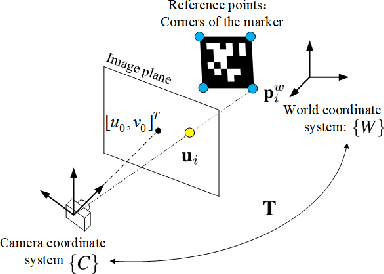
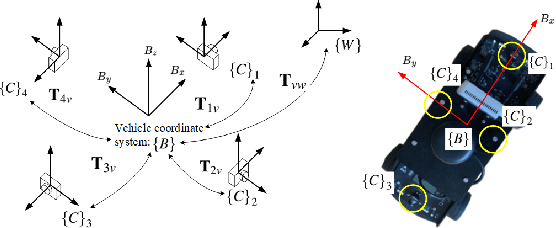
Navigation using only one marker, which contains four artificial features, is a challenging task since camera pose estimation using only four coplanar points suffers from the rotational ambiguity problem in a real-world application. This paper presents a framework of vision-based navigation for a self-driving vehicle equipped with multiple cameras and a wheel odometer. A multiple camera setup is presented for the camera cluster which has 360-degree vision such that our framework solely requires one planar marker. A Kalman-Filter-based fusion method is introduced for the multiple-camera and wheel odometry. Furthermore, an algorithm is proposed to resolve the rotational ambiguity problem using the prediction of the Kalman Filter as additional information. Finally, the lateral and longitudinal controllers are provided. Experiments are conducted to illustrate the effectiveness of the theory.