 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Tactile Sensing Foot for Single Robot Leg Stabilization
Mar 26, 2021

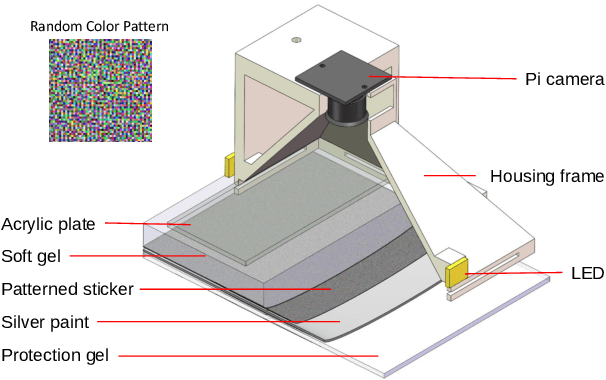

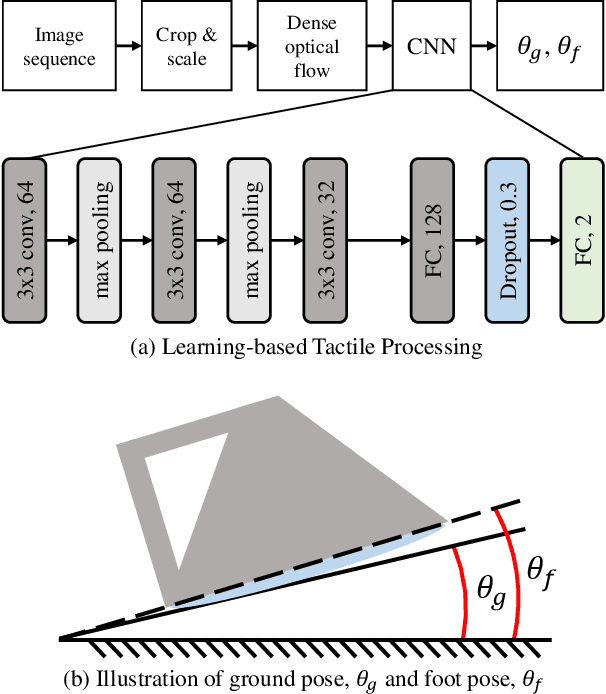
Tactile sensing on human feet is crucial for motion control, however, has not been explored in robotic counterparts. This work is dedicated to endowing tactile sensing to legged robot's feet and showing that a single-legged robot can be stabilized with only tactile sensing signals from its foot. We propose a robot leg with a novel vision-based tactile sensing foot system and implement a processing algorithm to extract contact information for feedback control in stabilizing tasks. A pipeline to convert images of the foot skin into high-level contact information using a deep learning framework is presented. The leg was quantitatively evaluated in a stabilization task on a tilting surface to show that the tactile foot was able to estimate both the surface tilting angle and the foot poses. Feasibility and effectiveness of the tactile system were investigated qualitatively in comparison with conventional single-legged robotic systems using inertia measurement units (IMU). Experiments demonstrate the capability of vision-based tactile sensors in assisting legged robots to maintain stability on unknown terrains and the potential for regulating more complex motions for humanoid robots.
* 7 pages, 9 figures, ICRA2021
E-PDDL: A Standardized Way of Defining Epistemic Planning Problems
Jul 19, 2021Epistemic Planning (EP) refers to an automated planning setting where the agent reasons in the space of knowledge states and tries to find a plan to reach a desirable state from the current state. Its general form, the Multi-agent Epistemic Planning (MEP) problem involves multiple agents who need to reason about both the state of the world and the information flow between agents. In a MEP problem, multiple approaches have been developed recently with varying restrictions, such as considering only the concept of knowledge while not allowing the idea of belief, or not allowing for ``complex" modal operators such as those needed to handle dynamic common knowledge. While the diversity of approaches has led to a deeper understanding of the problem space, the lack of a standardized way to specify MEP problems independently of solution approaches has created difficulties in comparing performance of planners, identifying promising techniques, exploring new strategies like ensemble methods, and making it easy for new researchers to contribute to this research area. To address the situation, we propose a unified way of specifying EP problems - the Epistemic Planning Domain Definition Language, E-PDDL. We show that E-PPDL can be supported by leading MEP planners and provide corresponding parser code that translates EP problems specified in E-PDDL into (M)EP problems that can be handled by several planners. This work is also useful in building more general epistemic planning environments where we envision a meta-cognitive module that takes a planning problem in E-PDDL, identifies and assesses some of its features, and autonomously decides which planner is the best one to solve it.
A Comprehensive Review on Non-Neural Networks Collaborative Filtering Recommendation Systems
Jun 20, 2021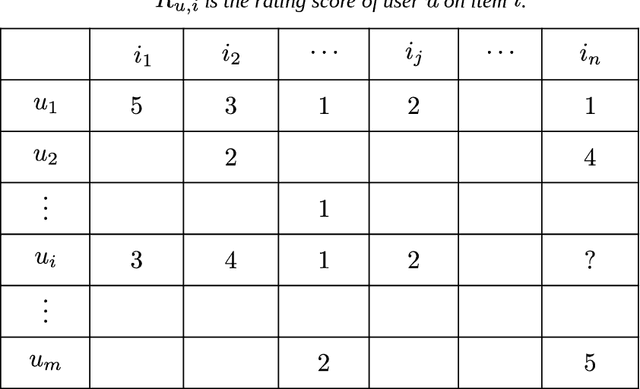
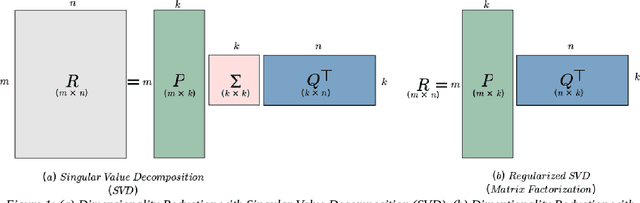
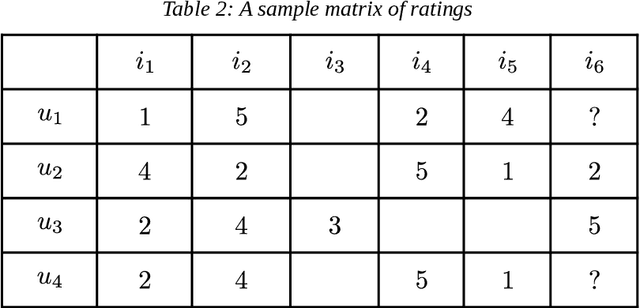
Over the past two decades, recommender systems have attracted a lot of interest due to the explosion in the amount of data in online applications. A particular attention has been paid to collaborative filtering, which is the most widely used in applications that involve information recommendations. Collaborative filtering (CF) uses the known preference of a group of users to make predictions and recommendations about the unknown preferences of other users (recommendations are made based on the past behavior of users). First introduced in the 1990s, a wide variety of increasingly successful models have been proposed. Due to the success of machine learning techniques in many areas, there has been a growing emphasis on the application of such algorithms in recommendation systems. In this article, we present an overview of the CF approaches for recommender systems, their two main categories, and their evaluation metrics. We focus on the application of classical Machine Learning algorithms to CF recommender systems by presenting their evolution from their first use-cases to advanced Machine Learning models. We attempt to provide a comprehensive and comparative overview of CF systems (with python implementations) that can serve as a guideline for research and practice in this area.
Markov Neural Operators for Learning Chaotic Systems
Jun 13, 2021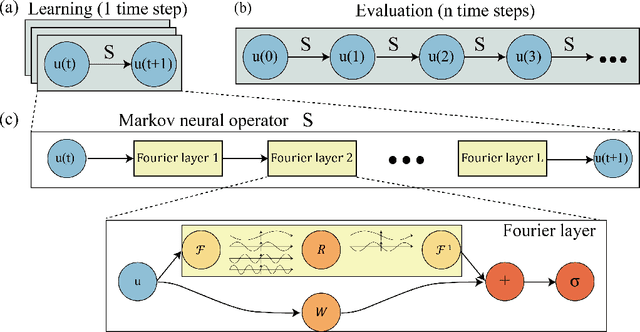
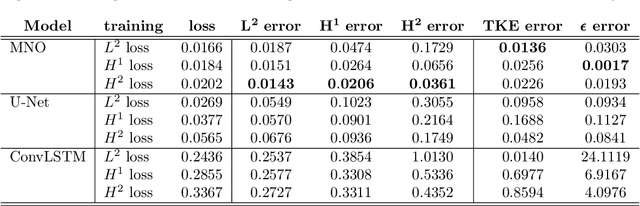
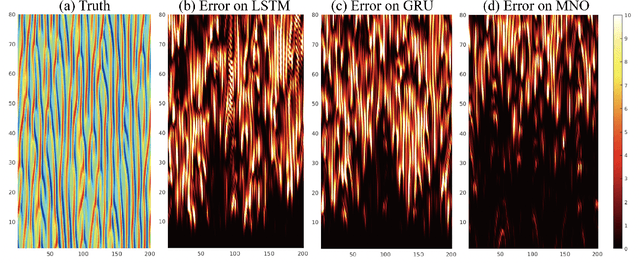
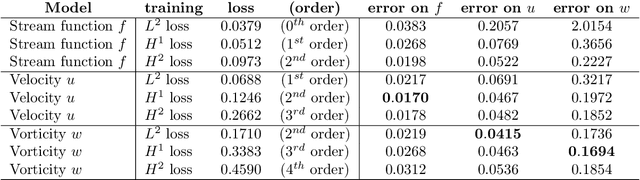
Chaotic systems are notoriously challenging to predict because of their instability. Small errors accumulate in the simulation of each time step, resulting in completely different trajectories. However, the trajectories of many prominent chaotic systems live in a low-dimensional subspace (attractor). If the system is Markovian, the attractor is uniquely determined by the Markov operator that maps the evolution of infinitesimal time steps. This makes it possible to predict the behavior of the chaotic system by learning the Markov operator even if we cannot predict the exact trajectory. Recently, a new framework for learning resolution-invariant solution operators for PDEs was proposed, known as neural operators. In this work, we train a Markov neural operator (MNO) with only the local one-step evolution information. We then compose the learned operator to obtain the global attractor and invariant measure. Such a Markov neural operator forms a discrete semigroup and we empirically observe that does not collapse or blow up. Experiments show neural operators are more accurate and stable compared to previous methods on chaotic systems such as the Kuramoto-Sivashinsky and Navier-Stokes equations.
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
Jun 27, 2021
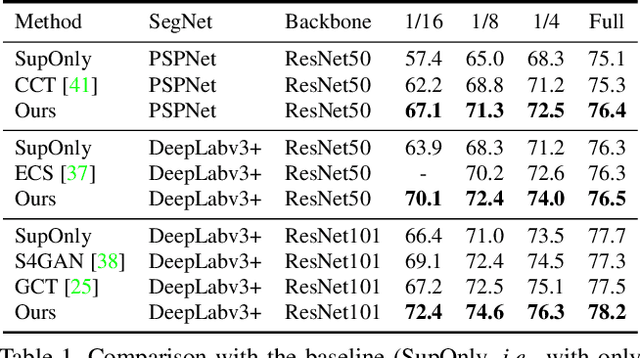
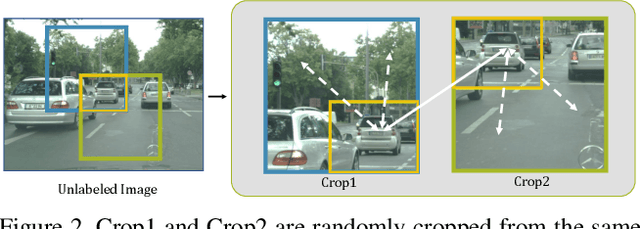
Semantic segmentation has made tremendous progress in recent years. However, satisfying performance highly depends on a large number of pixel-level annotations. Therefore, in this paper, we focus on the semi-supervised segmentation problem where only a small set of labeled data is provided with a much larger collection of totally unlabeled images. Nevertheless, due to the limited annotations, models may overly rely on the contexts available in the training data, which causes poor generalization to the scenes unseen before. A preferred high-level representation should capture the contextual information while not losing self-awareness. Therefore, we propose to maintain the context-aware consistency between features of the same identity but with different contexts, making the representations robust to the varying environments. Moreover, we present the Directional Contrastive Loss (DC Loss) to accomplish the consistency in a pixel-to-pixel manner, only requiring the feature with lower quality to be aligned towards its counterpart. In addition, to avoid the false-negative samples and filter the uncertain positive samples, we put forward two sampling strategies. Extensive experiments show that our simple yet effective method surpasses current state-of-the-art methods by a large margin and also generalizes well with extra image-level annotations.
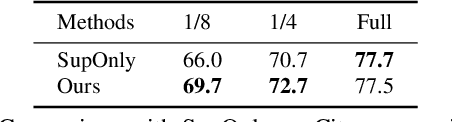
Hyperspectral and Multispectral Classification for Coastal Wetland Using Depthwise Feature Interaction Network
Jun 13, 2021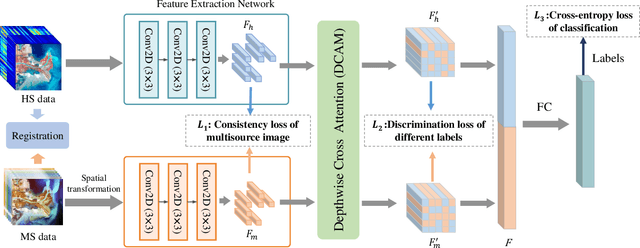
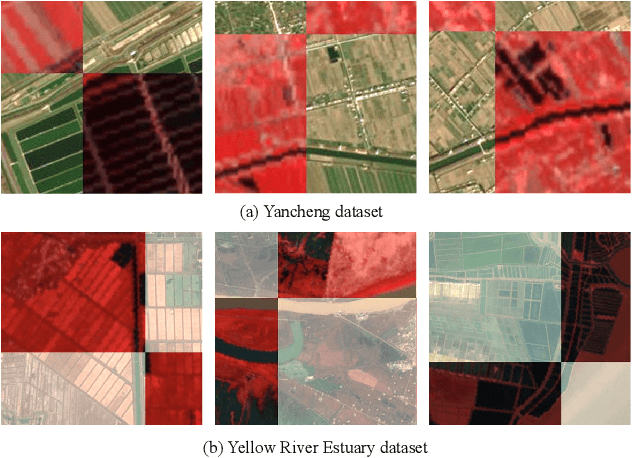
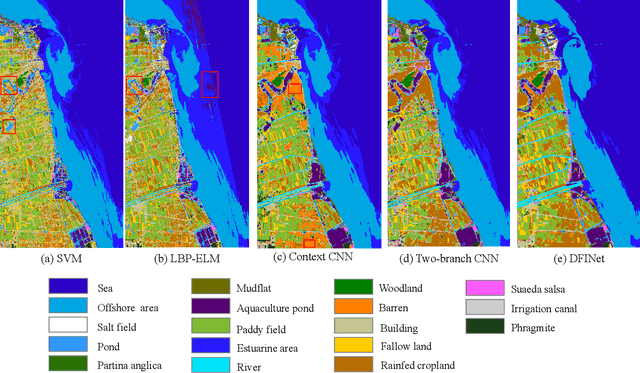
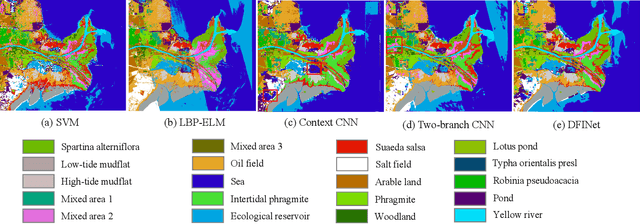
The monitoring of coastal wetlands is of great importance to the protection of marine and terrestrial ecosystems. However, due to the complex environment, severe vegetation mixture, and difficulty of access, it is impossible to accurately classify coastal wetlands and identify their species with traditional classifiers. Despite the integration of multisource remote sensing data for performance enhancement, there are still challenges with acquiring and exploiting the complementary merits from multisource data. In this paper, the Deepwise Feature Interaction Network (DFINet) is proposed for wetland classification. A depthwise cross attention module is designed to extract self-correlation and cross-correlation from multisource feature pairs. In this way, meaningful complementary information is emphasized for classification. DFINet is optimized by coordinating consistency loss, discrimination loss, and classification loss. Accordingly, DFINet reaches the standard solution-space under the regularity of loss functions, while the spatial consistency and feature discrimination are preserved. Comprehensive experimental results on two hyperspectral and multispectral wetland datasets demonstrate that the proposed DFINet outperforms other competitive methods in terms of overall accuracy.
Oriented Bounding Boxes for Small and Freely Rotated Objects
Apr 24, 2021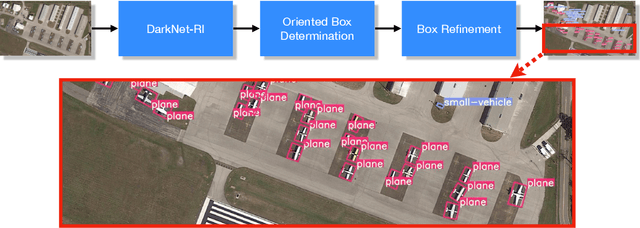
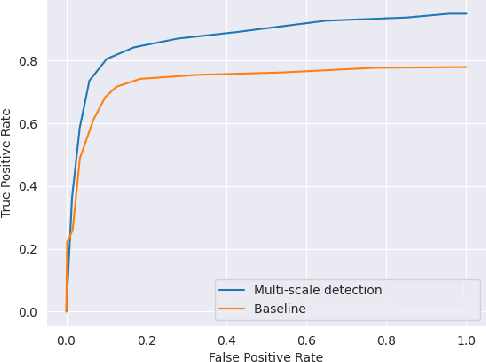
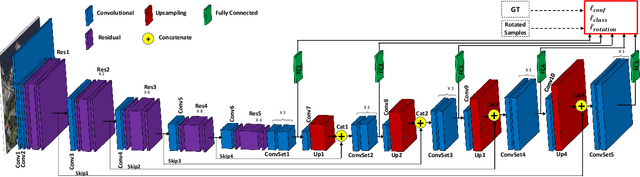
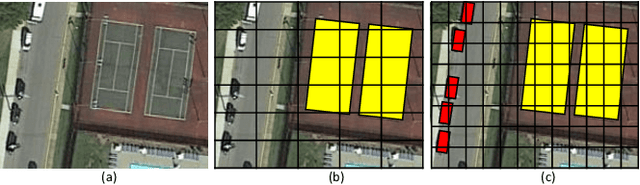
A novel object detection method is presented that handles freely rotated objects of arbitrary sizes, including tiny objects as small as $2\times 2$ pixels. Such tiny objects appear frequently in remotely sensed images, and present a challenge to recent object detection algorithms. More importantly, current object detection methods have been designed originally to accommodate axis-aligned bounding box detection, and therefore fail to accurately localize oriented boxes that best describe freely rotated objects. In contrast, the proposed CNN-based approach uses potential pixel information at multiple scale levels without the need for any external resources, such as anchor boxes.The method encodes the precise location and orientation of features of the target objects at grid cell locations. Unlike existing methods which regress the bounding box location and dimension,the proposed method learns all the required information by classification, which has the added benefit of enabling oriented bounding box detection without any extra computation. It thus infers the bounding boxes only at inference time by finding the minimum surrounding box for every set of the same predicted class labels. Moreover, a rotation-invariant feature representation is applied to each scale, which imposes a regularization constraint to enforce covering the 360 degree range of in-plane rotation of the training samples to share similar features. Evaluations on the xView and DOTA datasets show that the proposed method uniformly improves performance over existing state-of-the-art methods.
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 16, 2021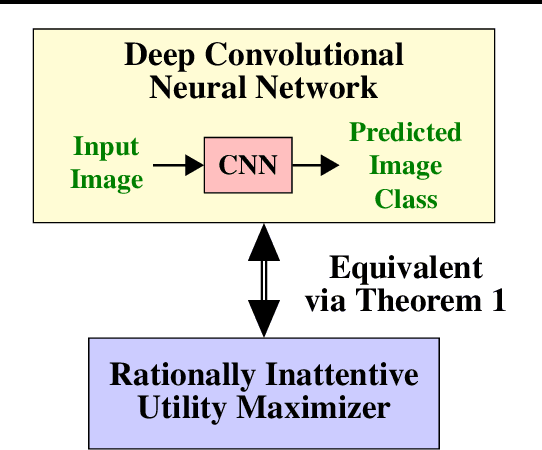

Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
AdaptCL: Efficient Collaborative Learning with Dynamic and Adaptive Pruning
Jun 27, 2021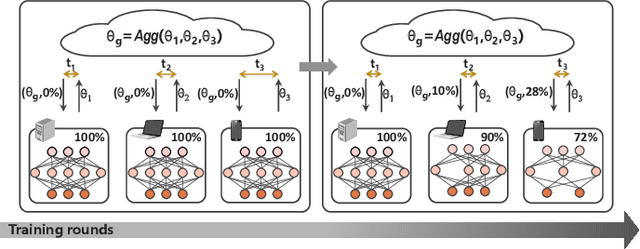
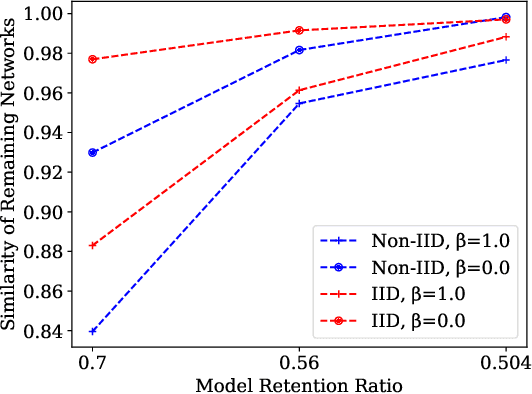
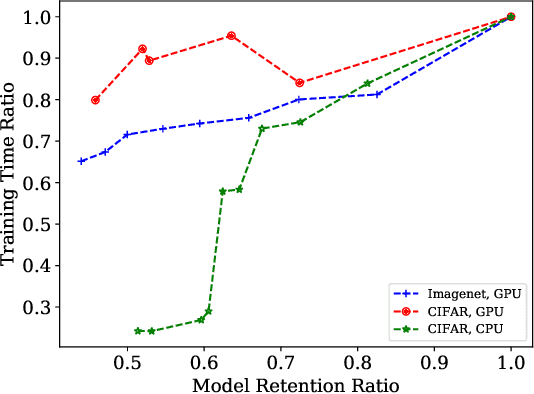

In multi-party collaborative learning, the parameter server sends a global model to each data holder for local training and then aggregates committed models globally to achieve privacy protection. However, both the dragger issue of synchronous collaborative learning and the staleness issue of asynchronous collaborative learning make collaborative learning inefficient in real-world heterogeneous environments. We propose a novel and efficient collaborative learning framework named AdaptCL, which generates an adaptive sub-model dynamically from the global base model for each data holder, without any prior information about worker capability. All workers (data holders) achieve approximately identical update time as the fastest worker by equipping them with capability-adapted pruned models. Thus the training process can be dramatically accelerated. Besides, we tailor the efficient pruned rate learning algorithm and pruning approach for AdaptCL. Meanwhile, AdaptCL provides a mechanism for handling the trade-off between accuracy and time overhead and can be combined with other techniques to accelerate training further. Empirical results show that AdaptCL introduces little computing and communication overhead. AdaptCL achieves time savings of more than 41\% on average and improves accuracy in a low heterogeneous environment. In a highly heterogeneous environment, AdaptCL achieves a training speedup of 6.2x with a slight loss of accuracy.
An AutoML-based Approach to Multimodal Image Sentiment Analysis
Feb 16, 2021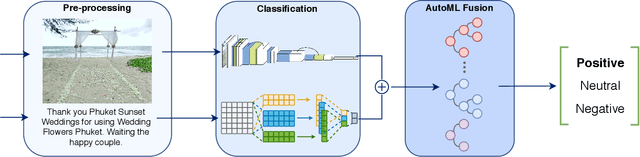

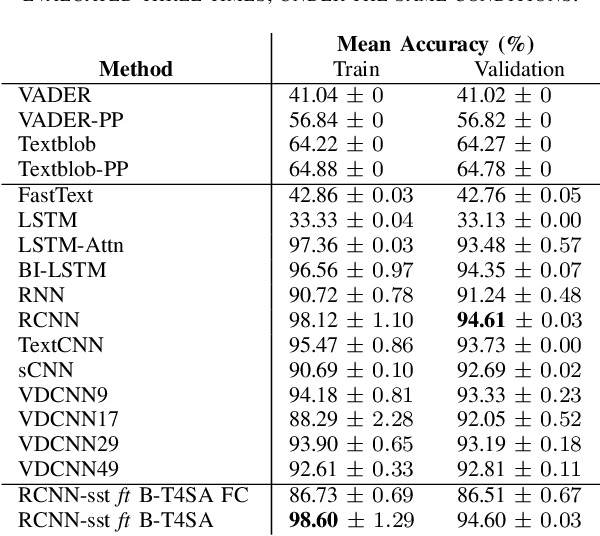
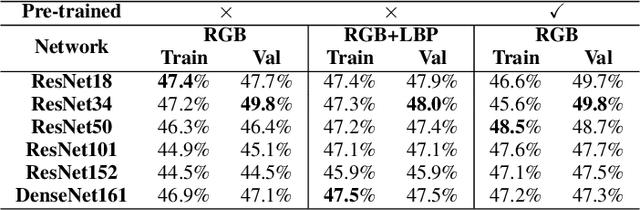
Sentiment analysis is a research topic focused on analysing data to extract information related to the sentiment that it causes. Applications of sentiment analysis are wide, ranging from recommendation systems, and marketing to customer satisfaction. Recent approaches evaluate textual content using Machine Learning techniques that are trained over large corpora. However, as social media grown, other data types emerged in large quantities, such as images. Sentiment analysis in images has shown to be a valuable complement to textual data since it enables the inference of the underlying message polarity by creating context and connections. Multimodal sentiment analysis approaches intend to leverage information of both textual and image content to perform an evaluation. Despite recent advances, current solutions still flounder in combining both image and textual information to classify social media data, mainly due to subjectivity, inter-class homogeneity and fusion data differences. In this paper, we propose a method that combines both textual and image individual sentiment analysis into a final fused classification based on AutoML, that performs a random search to find the best model. Our method achieved state-of-the-art performance in the B-T4SA dataset, with 95.19% accuracy.