 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Time-Series Representations by Hierarchical Uniformity-Tolerance Latent Balancing
Oct 02, 2025We propose TimeHUT, a novel method for learning time-series representations by hierarchical uniformity-tolerance balancing of contrastive representations. Our method uses two distinct losses to learn strong representations with the aim of striking an effective balance between uniformity and tolerance in the embedding space. First, TimeHUT uses a hierarchical setup to learn both instance-wise and temporal information from input time-series. Next, we integrate a temperature scheduler within the vanilla contrastive loss to balance the uniformity and tolerance characteristics of the embeddings. Additionally, a hierarchical angular margin loss enforces instance-wise and temporal contrast losses, creating geometric margins between positive and negative pairs of temporal sequences. This approach improves the coherence of positive pairs and their separation from the negatives, enhancing the capture of temporal dependencies within a time-series sample. We evaluate our approach on a wide range of tasks, namely 128 UCR and 30 UAE datasets for univariate and multivariate classification, as well as Yahoo and KPI datasets for anomaly detection. The results demonstrate that TimeHUT outperforms prior methods by considerable margins on classification, while obtaining competitive results for anomaly detection. Finally, detailed sensitivity and ablation studies are performed to evaluate different components and hyperparameters of our method.
DLTPose: 6DoF Pose Estimation From Accurate Dense Surface Point Estimates
Apr 09, 2025We propose DLTPose, a novel method for 6DoF object pose estimation from RGB-D images that combines the accuracy of sparse keypoint methods with the robustness of dense pixel-wise predictions. DLTPose predicts per-pixel radial distances to a set of minimally four keypoints, which are then fed into our novel Direct Linear Transform (DLT) formulation to produce accurate 3D object frame surface estimates, leading to better 6DoF pose estimation. Additionally, we introduce a novel symmetry-aware keypoint ordering approach, designed to handle object symmetries that otherwise cause inconsistencies in keypoint assignments. Previous keypoint-based methods relied on fixed keypoint orderings, which failed to account for the multiple valid configurations exhibited by symmetric objects, which our ordering approach exploits to enhance the model's ability to learn stable keypoint representations. Extensive experiments on the benchmark LINEMOD, Occlusion LINEMOD and YCB-Video datasets show that DLTPose outperforms existing methods, especially for symmetric and occluded objects, demonstrating superior Mean Average Recall values of 86.5% (LM), 79.7% (LM-O) and 89.5% (YCB-V). The code is available at https://anonymous.4open.science/r/DLTPose_/ .
Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training
Dec 16, 2024



In this paper, we propose a novel approach, Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training (FedSB), to address the challenges of data heterogeneity within a federated learning framework. FedSB utilizes label smoothing at the client level to prevent overfitting to domain-specific features, thereby enhancing generalization capabilities across diverse domains when aggregating local models into a global model. Additionally, FedSB incorporates a decentralized budgeting mechanism which balances training among clients, which is shown to improve the performance of the aggregated global model. Extensive experiments on four commonly used multi-domain datasets, PACS, VLCS, OfficeHome, and TerraInc, demonstrate that FedSB outperforms competing methods, achieving state-of-the-art results on three out of four datasets, indicating the effectiveness of FedSB in addressing data heterogeneity.
Socially-Informed Reconstruction for Pedestrian Trajectory Forecasting
Dec 05, 2024



Pedestrian trajectory prediction remains a challenge for autonomous systems, particularly due to the intricate dynamics of social interactions. Accurate forecasting requires a comprehensive understanding not only of each pedestrian's previous trajectory but also of their interaction with the surrounding environment, an important part of which are other pedestrians moving dynamically in the scene. To learn effective socially-informed representations, we propose a model that uses a reconstructor alongside a conditional variational autoencoder-based trajectory forecasting module. This module generates pseudo-trajectories, which we use as augmentations throughout the training process. To further guide the model towards social awareness, we propose a novel social loss that aids in forecasting of more stable trajectories. We validate our approach through extensive experiments, demonstrating strong performances in comparison to state of-the-art methods on the ETH/UCY and SDD benchmarks.
CycleCrash: A Dataset of Bicycle Collision Videos for Collision Prediction and Analysis
Sep 30, 2024



Self-driving research often underrepresents cyclist collisions and safety. To address this, we present CycleCrash, a novel dataset consisting of 3,000 dashcam videos with 436,347 frames that capture cyclists in a range of critical situations, from collisions to safe interactions. This dataset enables 9 different cyclist collision prediction and classification tasks focusing on potentially hazardous conditions for cyclists and is annotated with collision-related, cyclist-related, and scene-related labels. Next, we propose VidNeXt, a novel method that leverages a ConvNeXt spatial encoder and a non-stationary transformer to capture the temporal dynamics of videos for the tasks defined in our dataset. To demonstrate the effectiveness of our method and create additional baselines on CycleCrash, we apply and compare 7 models along with a detailed ablation. We release the dataset and code at https://github.com/DeSinister/CycleCrash/ .
Federated Unsupervised Domain Generalization using Global and Local Alignment of Gradients
May 25, 2024



We address the problem of federated domain generalization in an unsupervised setting for the first time. We first theoretically establish a connection between domain shift and alignment of gradients in unsupervised federated learning and show that aligning the gradients at both client and server levels can facilitate the generalization of the model to new (target) domains. Building on this insight, we propose a novel method named FedGaLA, which performs gradient alignment at the client level to encourage clients to learn domain-invariant features, as well as global gradient alignment at the server to obtain a more generalized aggregated model. To empirically evaluate our method, we perform various experiments on four commonly used multi-domain datasets, PACS, OfficeHome, DomainNet, and TerraInc. The results demonstrate the effectiveness of our method which outperforms comparable baselines. Ablation and sensitivity studies demonstrate the impact of different components and parameters in our approach. The source code will be available online upon publication.
Pseudo-keypoint RKHS Learning for Self-supervised 6DoF Pose Estimation
Nov 18, 2023



This paper addresses the simulation-to-real domain gap in 6DoF PE, and proposes a novel self-supervised keypoint radial voting-based 6DoF PE framework, effectively narrowing this gap using a learnable kernel in RKHS. We formulate this domain gap as a distance in high-dimensional feature space, distinct from previous iterative matching methods. We propose an adapter network, which evolves the network parameters from the source domain, which has been massively trained on synthetic data with synthetic poses, to the target domain, which is trained on real data. Importantly, the real data training only uses pseudo-poses estimated by pseudo-keypoints, and thereby requires no real groundtruth data annotations. RKHSPose achieves state-of-the-art performance on three commonly used 6DoF PE datasets including LINEMOD (+4.2%), Occlusion LINEMOD (+2%), and YCB-Video (+3%). It also compares favorably to fully supervised methods on all six applicable BOP core datasets, achieving within -10.8% to -0.3% of the top fully supervised results.
Diffusion Models with Deterministic Normalizing Flow Priors
Sep 03, 2023



For faster sampling and higher sample quality, we propose DiNof ($\textbf{Di}$ffusion with $\textbf{No}$rmalizing $\textbf{f}$low priors), a technique that makes use of normalizing flows and diffusion models. We use normalizing flows to parameterize the noisy data at any arbitrary step of the diffusion process and utilize it as the prior in the reverse diffusion process. More specifically, the forward noising process turns a data distribution into partially noisy data, which are subsequently transformed into a Gaussian distribution by a nonlinear process. The backward denoising procedure begins with a prior created by sampling from the Gaussian distribution and applying the invertible normalizing flow transformations deterministically. To generate the data distribution, the prior then undergoes the remaining diffusion stochastic denoising procedure. Through the reduction of the number of total diffusion steps, we are able to speed up both the forward and backward processes. More importantly, we improve the expressive power of diffusion models by employing both deterministic and stochastic mappings. Experiments on standard image generation datasets demonstrate the advantage of the proposed method over existing approaches. On the unconditional CIFAR10 dataset, for example, we achieve an FID of 2.01 and an Inception score of 9.96. Our method also demonstrates competitive performance on CelebA-HQ-256 dataset as it obtains an FID score of 7.11. Code is available at https://github.com/MohsenZand/DiNof.
Multiscale Residual Learning of Graph Convolutional Sequence Chunks for Human Motion Prediction
Aug 31, 2023



A new method is proposed for human motion prediction by learning temporal and spatial dependencies. Recently, multiscale graphs have been developed to model the human body at higher abstraction levels, resulting in more stable motion prediction. Current methods however predetermine scale levels and combine spatially proximal joints to generate coarser scales based on human priors, even though movement patterns in different motion sequences vary and do not fully comply with a fixed graph of spatially connected joints. Another problem with graph convolutional methods is mode collapse, in which predicted poses converge around a mean pose with no discernible movements, particularly in long-term predictions. To tackle these issues, we propose ResChunk, an end-to-end network which explores dynamically correlated body components based on the pairwise relationships between all joints in individual sequences. ResChunk is trained to learn the residuals between target sequence chunks in an autoregressive manner to enforce the temporal connectivities between consecutive chunks. It is hence a sequence-to-sequence prediction network which considers dynamic spatio-temporal features of sequences at multiple levels. Our experiments on two challenging benchmark datasets, CMU Mocap and Human3.6M, demonstrate that our proposed method is able to effectively model the sequence information for motion prediction and outperform other techniques to set a new state-of-the-art. Our code is available at https://github.com/MohsenZand/ResChunk.
Learning Better Keypoints for Multi-Object 6DoF Pose Estimation
Aug 15, 2023
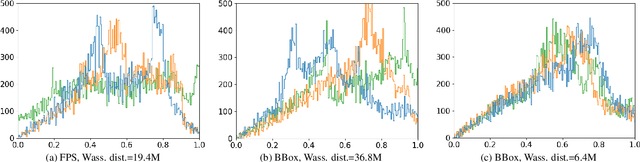
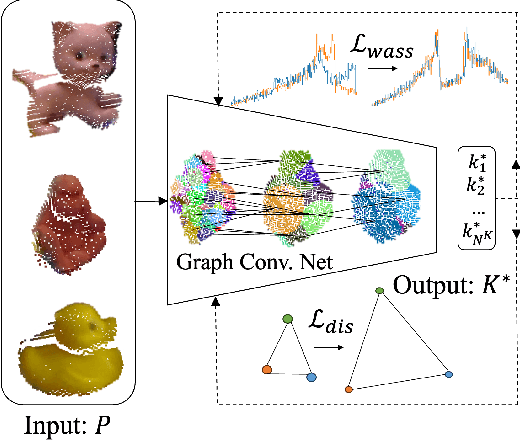
We investigate the impact of pre-defined keypoints for pose estimation, and found that accuracy and efficiency can be improved by training a graph network to select a set of disperse keypoints with similarly distributed votes. These votes, learned by a regression network to accumulate evidence for the keypoint locations, can be regressed more accurately compared to previous heuristic keypoint algorithms. The proposed KeyGNet, supervised by a combined loss measuring both Wassserstein distance and dispersion, learns the color and geometry features of the target objects to estimate optimal keypoint locations. Experiments demonstrate the keypoints selected by KeyGNet improved the accuracy for all evaluation metrics of all seven datasets tested, for three keypoint voting methods. The challenging Occlusion LINEMOD dataset notably improved ADD(S) by +16.4% on PVN3D, and all core BOP datasets showed an AR improvement for all objects, of between +1% and +21.5%. There was also a notable increase in performance when transitioning from single object to multiple object training using KeyGNet keypoints, essentially eliminating the SISO-MIMO gap for Occlusion LINEMOD.