 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-objective Contextual Bandit Problem with Similarity Information
Mar 11, 2018

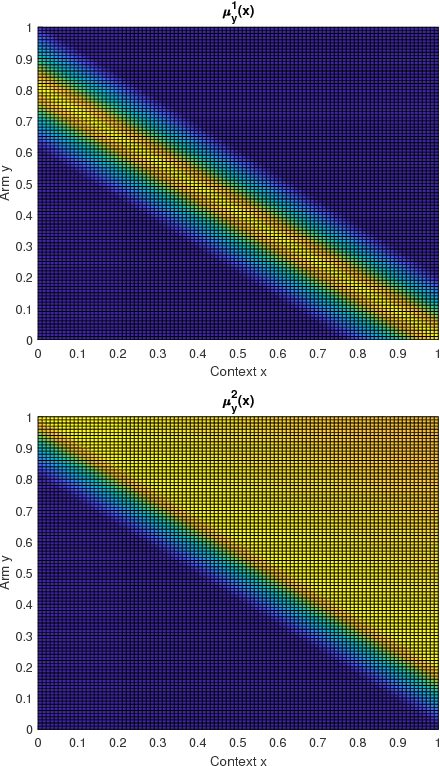
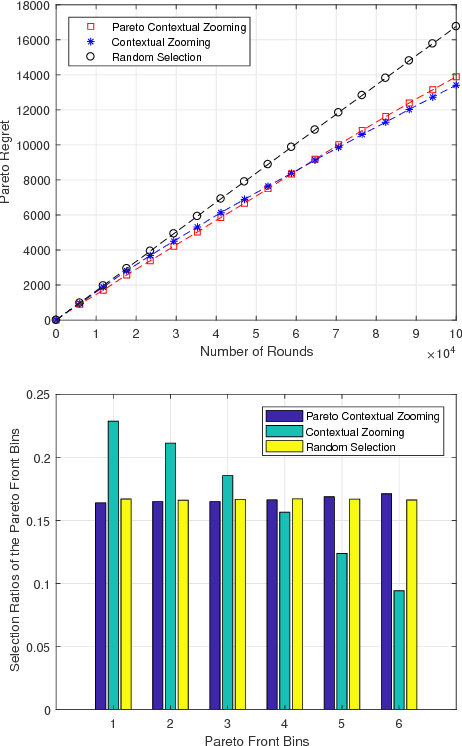
In this paper we propose the multi-objective contextual bandit problem with similarity information. This problem extends the classical contextual bandit problem with similarity information by introducing multiple and possibly conflicting objectives. Since the best arm in each objective can be different given the context, learning the best arm based on a single objective can jeopardize the rewards obtained from the other objectives. In order to evaluate the performance of the learner in this setup, we use a performance metric called the contextual Pareto regret. Essentially, the contextual Pareto regret is the sum of the distances of the arms chosen by the learner to the context dependent Pareto front. For this problem, we develop a new online learning algorithm called Pareto Contextual Zooming (PCZ), which exploits the idea of contextual zooming to learn the arms that are close to the Pareto front for each observed context by adaptively partitioning the joint context-arm set according to the observed rewards and locations of the context-arm pairs selected in the past. Then, we prove that PCZ achieves $\tilde O (T^{(1+d_p)/(2+d_p)})$ Pareto regret where $d_p$ is the Pareto zooming dimension that depends on the size of the set of near-optimal context-arm pairs. Moreover, we show that this regret bound is nearly optimal by providing an almost matching $\Omega (T^{(1+d_p)/(2+d_p)})$ lower bound.
How could Neural Networks understand Programs?
May 10, 2021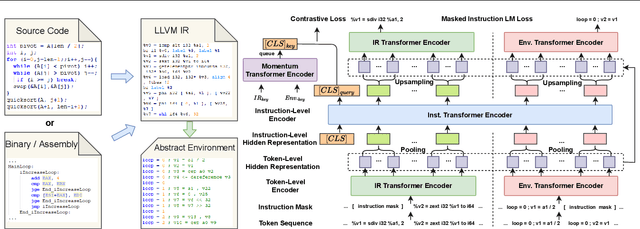
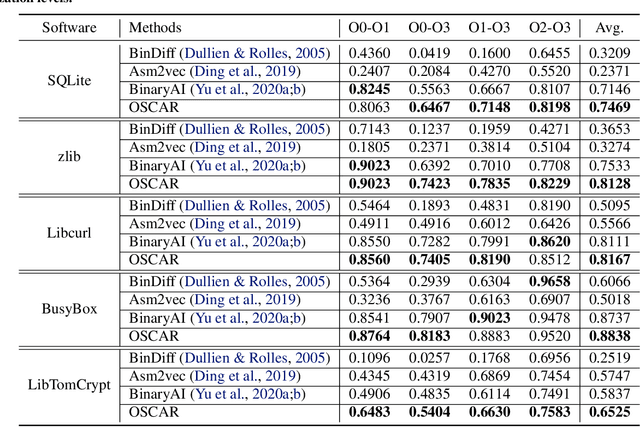


Semantic understanding of programs is a fundamental problem for programming language processing (PLP). Recent works that learn representations of code based on pre-training techniques in NLP have pushed the frontiers in this direction. However, the semantics of PL and NL have essential differences. These being ignored, we believe it is difficult to build a model to better understand programs, by either directly applying off-the-shelf NLP pre-training techniques to the source code, or adding features to the model by the heuristic. In fact, the semantics of a program can be rigorously defined by formal semantics in PL theory. For example, the operational semantics, describes the meaning of a valid program as updating the environment (i.e., the memory address-value function) through fundamental operations, such as memory I/O and conditional branching. Inspired by this, we propose a novel program semantics learning paradigm, that the model should learn from information composed of (1) the representations which align well with the fundamental operations in operational semantics, and (2) the information of environment transition, which is indispensable for program understanding. To validate our proposal, we present a hierarchical Transformer-based pre-training model called OSCAR to better facilitate the understanding of programs. OSCAR learns from intermediate representation (IR) and an encoded representation derived from static analysis, which are used for representing the fundamental operations and approximating the environment transitions respectively. OSCAR empirically shows the outstanding capability of program semantics understanding on many practical software engineering tasks.
Part2Word: Learning Joint Embedding of Point Clouds and Text by Matching Parts to Words
Jul 05, 2021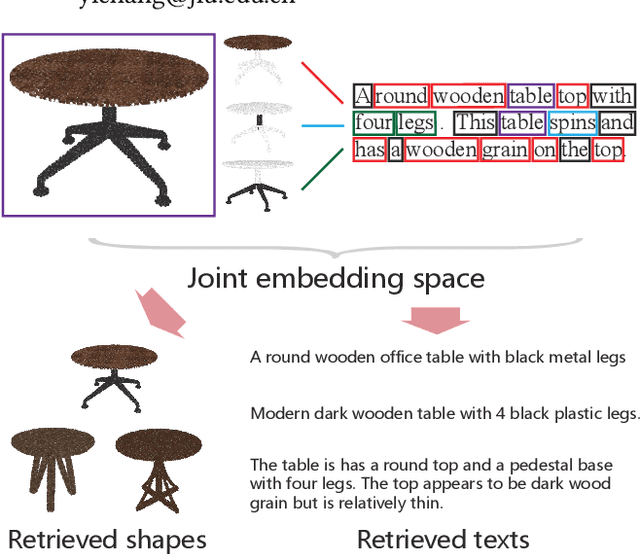
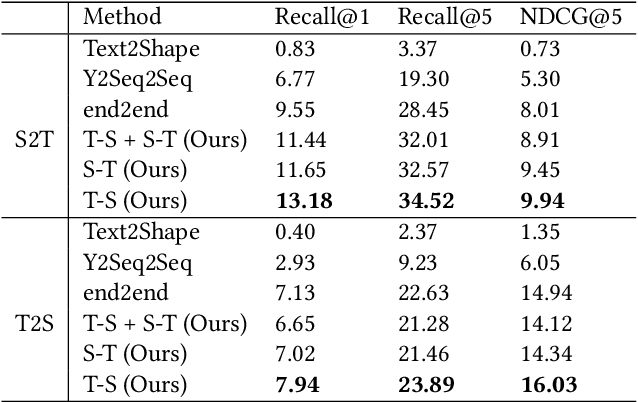
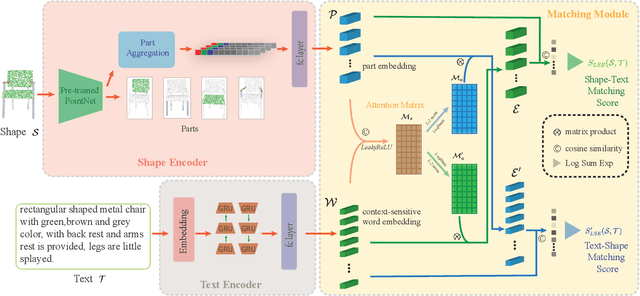
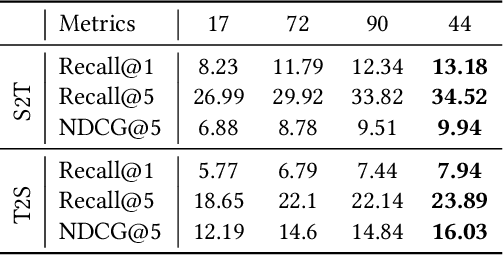
It is important to learn joint embedding for 3D shapes and text in different shape understanding tasks, such as shape-text matching, retrieval, and shape captioning. Current multi-view based methods learn a mapping from multiple rendered views to text. However, these methods can not analyze 3D shapes well due to the self-occlusion and limitation of learning manifolds. To resolve this issue, we propose a method to learn joint embedding of point clouds and text by matching parts from shapes to words from sentences in a common space. Specifically, we first learn segmentation prior to segment point clouds into parts. Then, we map parts and words into an optimized space, where the parts and words can be matched with each other. In the optimized space, we represent a part by aggregating features of all points within the part, while representing each word with its context information, where we train our network to minimize the triplet ranking loss. Moreover, we also introduce cross-modal attention to capture the relationship of part-word in this matching procedure, which enhances joint embedding learning. Our experimental results outperform the state-of-the-art in multi-modal retrieval under the widely used benchmark.
Icebreaker: Element-wise Active Information Acquisition with Bayesian Deep Latent Gaussian Model
Aug 14, 2019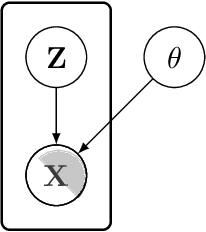
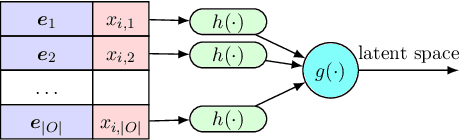
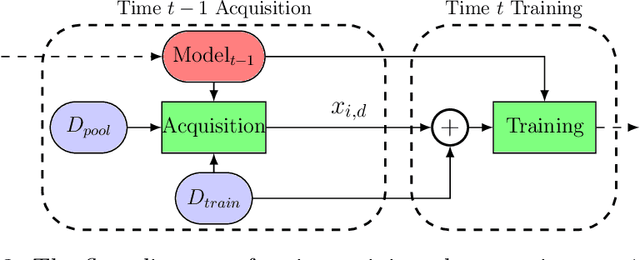
In this paper we introduce the ice-start problem, i.e., the challenge of deploying machine learning models when only little or no training data is initially available, and acquiring each feature element of data is associated with costs. This setting is representative for the real-world machine learning applications. For instance, in the health-care domain, when training an AI system for predicting patient metrics from lab tests, obtaining every single measurement comes with a high cost. Active learning, where only the label is associated with a cost does not apply to such problem, because performing all possible lab tests to acquire a new training datum would be costly, as well as unnecessary due to redundancy. We propose Icebreaker, a principled framework to approach the ice-start problem. Icebreaker uses a full Bayesian Deep Latent Gaussian Model (BELGAM) with a novel inference method. Our proposed method combines recent advances in amortized inference and stochastic gradient MCMC to enable fast and accurate posterior inference. By utilizing BELGAM's ability to fully quantify model uncertainty, we also propose two information acquisition functions for imputation and active prediction problems. We demonstrate that BELGAM performs significantly better than the previous VAE (Variational autoencoder) based models, when the data set size is small, using both machine learning benchmarks and real-world recommender systems and health-care applications. Moreover, based on BELGAM, Icebreaker further improves the performance and demonstrate the ability to use minimum amount of the training data to obtain the highest test time performance.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Jul 28, 2021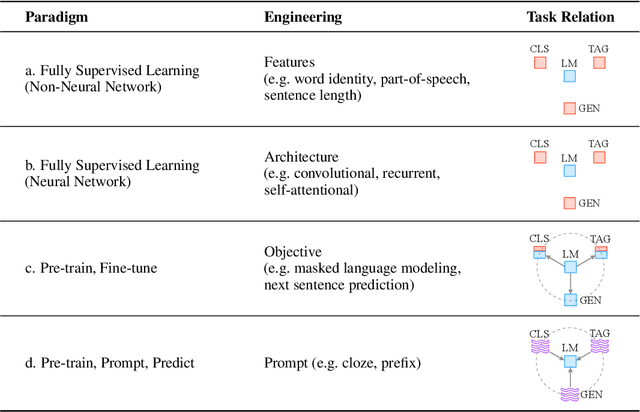
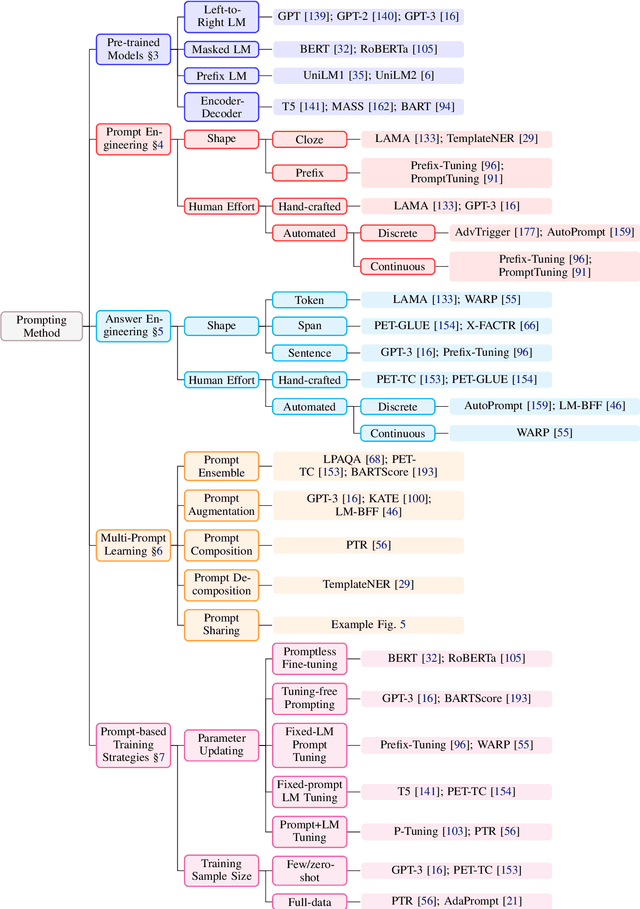
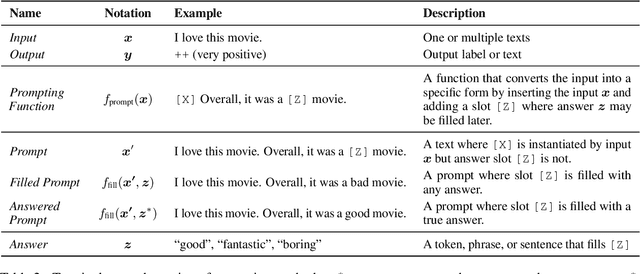
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website http://pretrain.nlpedia.ai/ including constantly-updated survey, and paperlist.
Exploring Discourse Structures for Argument Impact Classification
Jun 02, 2021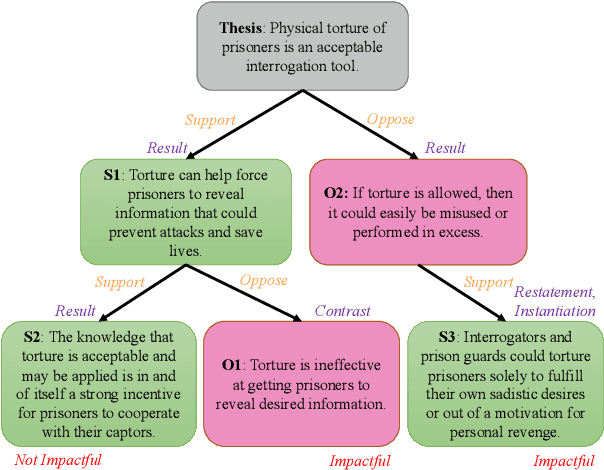
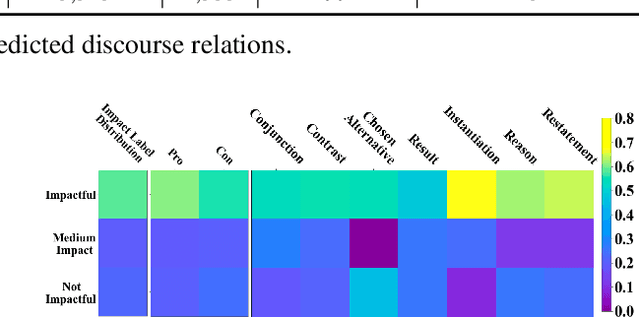

Discourse relations among arguments reveal logical structures of a debate conversation. However, no prior work has explicitly studied how the sequence of discourse relations influence a claim's impact. This paper empirically shows that the discourse relations between two arguments along the context path are essential factors for identifying the persuasive power of an argument. We further propose DisCOC to inject and fuse the sentence-level structural discourse information with contextualized features derived from large-scale language models. Experimental results and extensive analysis show that the attention and gate mechanisms that explicitly model contexts and texts can indeed help the argument impact classification task defined by Durmus et al. (2019), and discourse structures among the context path of the claim to be classified can further boost the performance.
Interpretable Deep Feature Propagation for Early Action Recognition
Jul 11, 2021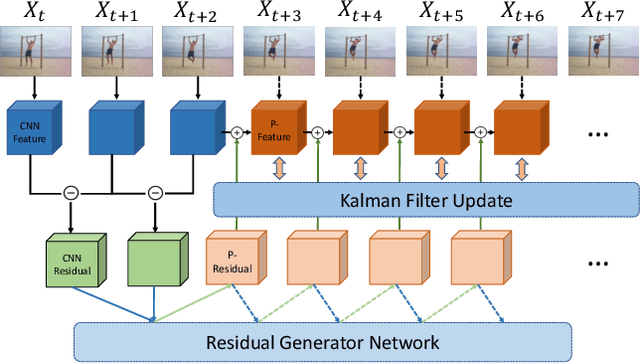
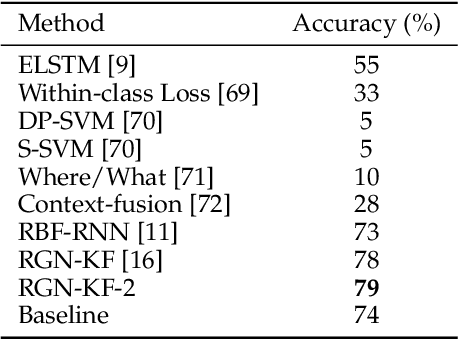
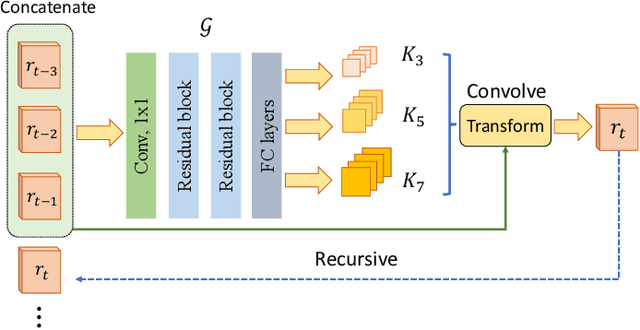
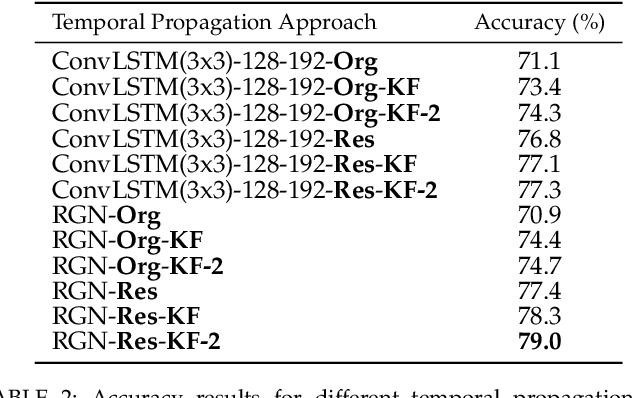
Early action recognition (action prediction) from limited preliminary observations plays a critical role for streaming vision systems that demand real-time inference, as video actions often possess elongated temporal spans which cause undesired latency. In this study, we address action prediction by investigating how action patterns evolve over time in a spatial feature space. There are three key components to our system. First, we work with intermediate-layer ConvNet features, which allow for abstraction from raw data, while retaining spatial layout. Second, instead of propagating features per se, we propagate their residuals across time, which allows for a compact representation that reduces redundancy. Third, we employ a Kalman filter to combat error build-up and unify across prediction start times. Extensive experimental results on multiple benchmarks show that our approach leads to competitive performance in action prediction. Notably, we investigate the learned components of our system to shed light on their otherwise opaque natures in two ways. First, we document that our learned feature propagation module works as a spatial shifting mechanism under convolution to propagate current observations into the future. Thus, it captures flow-based image motion information. Second, the learned Kalman filter adaptively updates prior estimation to aid the sequence learning process.
Siamese Labels Auxiliary Network(SiLaNet)
Mar 06, 2021
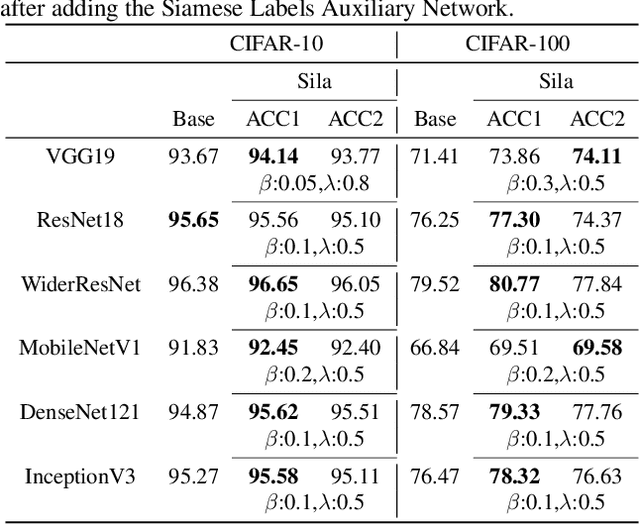
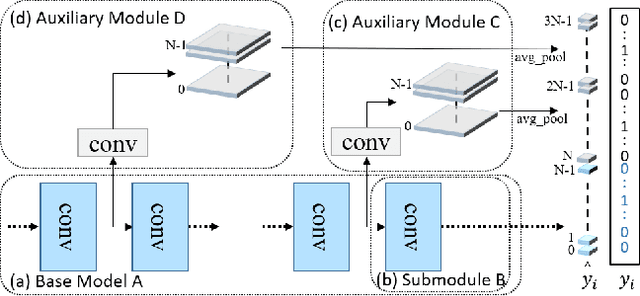
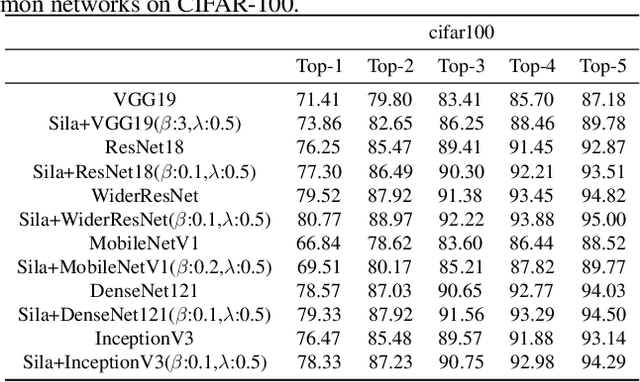
Auxiliary information attracts more and more attention in the area of machine learning. Attempts so far to include such auxiliary information in state-of-the-art learning process have often been based on simply appending these auxiliary features to the data level or feature level. In this paper, we intend to propose a novel training method with new options and architectures. Siamese labels, which were used in the training phase as auxiliary modules. While in the testing phase, the auxiliary module should be removed. Siamese label module makes it easier to train and improves the performance in testing process. In general, the main contributions can be summarized as, 1) Siamese Labels are firstly proposed as auxiliary information to improve the learning efficiency; 2) We establish a new architecture, Siamese Labels Auxiliary Network (SilaNet), which is to assist the training of the model; 3) Siamese Labels Auxiliary Network is applied to compress the model parameters by 50% and ensure the high accuracy at the same time. For the purpose of comparison, we tested the network on CIFAR-10 and CIFAR100 using some common models. The proposed SilaNet performs excellent efficiency both on the accuracy and robustness.
AoI-Aware Resource Allocation for Platoon-Based C-V2X Networks via Multi-Agent Multi-Task Reinforcement Learning
May 10, 2021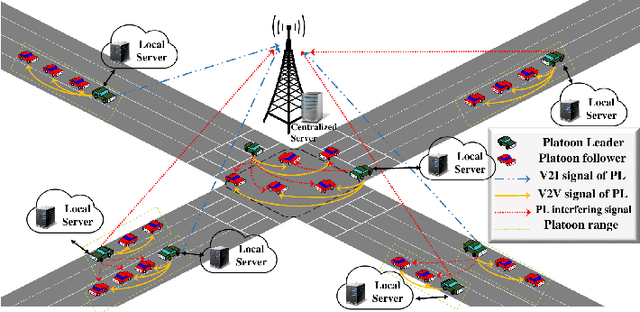
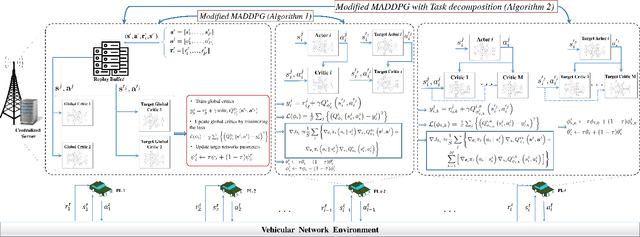
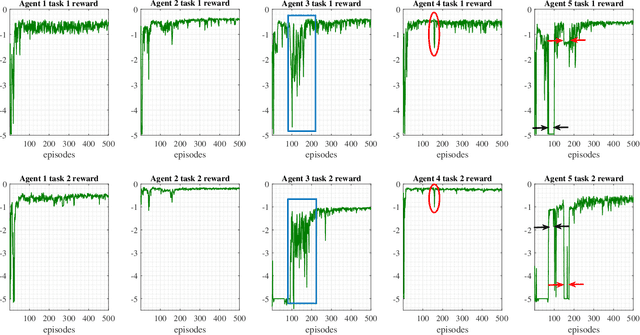
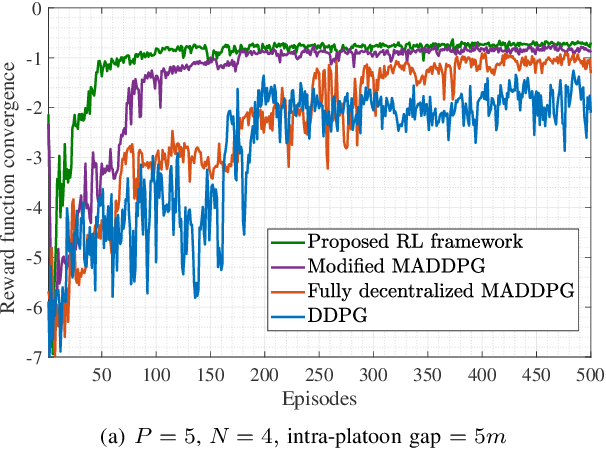
This paper investigates the problem of age of information (AoI) aware radio resource management for a platooning system. Multiple autonomous platoons exploit the cellular wireless vehicle-to-everything (C-V2X) communication technology to disseminate the cooperative awareness messages (CAMs) to their followers while ensuring timely delivery of safety-critical messages to the Road-Side Unit (RSU). Due to the challenges of dynamic channel conditions, centralized resource management schemes that require global information are inefficient and lead to large signaling overheads. Hence, we exploit a distributed resource allocation framework based on multi-agent reinforcement learning (MARL), where each platoon leader (PL) acts as an agent and interacts with the environment to learn its optimal policy. Existing MARL algorithms consider a holistic reward function for the group's collective success, which often ends up with unsatisfactory results and cannot guarantee an optimal policy for each agent. Consequently, motivated by the existing literature in RL, we propose a novel MARL framework that trains two critics with the following goals: A global critic which estimates the global expected reward and motivates the agents toward a cooperating behavior and an exclusive local critic for each agent that estimates the local individual reward. Furthermore, based on the tasks each agent has to accomplish, the individual reward of each agent is decomposed into multiple sub-reward functions where task-wise value functions are learned separately. Numerical results indicate our proposed algorithm's effectiveness compared with the conventional RL methods applied in this area.
The Role of Information Complexity and Randomization in Representation Learning
Feb 14, 2018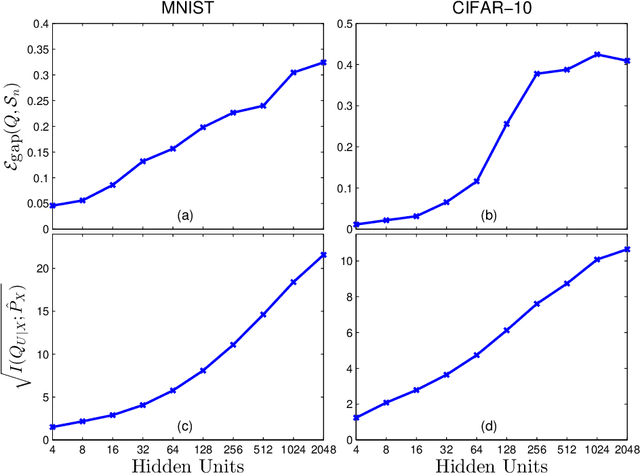
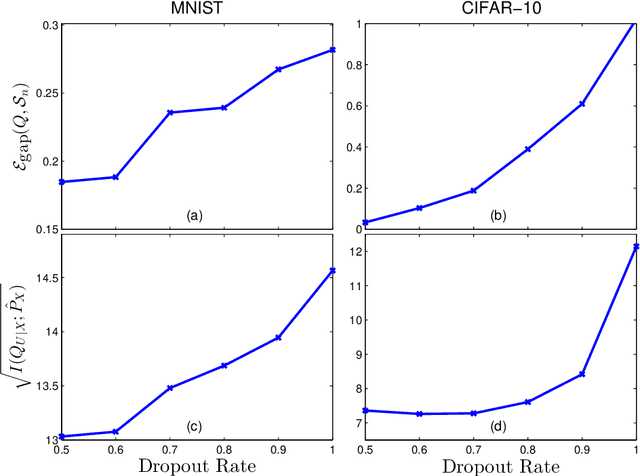
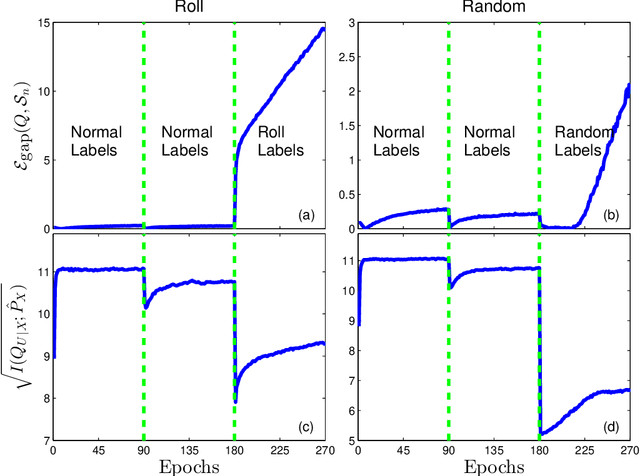
A grand challenge in representation learning is to learn the different explanatory factors of variation behind the high dimen- sional data. Encoder models are often determined to optimize performance on training data when the real objective is to generalize well to unseen data. Although there is enough numerical evidence suggesting that noise injection (during training) at the representation level might improve the generalization ability of encoders, an information-theoretic understanding of this principle remains elusive. This paper presents a sample-dependent bound on the generalization gap of the cross-entropy loss that scales with the information complexity (IC) of the representations, meaning the mutual information between inputs and their representations. The IC is empirically investigated for standard multi-layer neural networks with SGD on MNIST and CIFAR-10 datasets; the behaviour of the gap and the IC appear to be in direct correlation, suggesting that SGD selects encoders to implicitly minimize the IC. We specialize the IC to study the role of Dropout on the generalization capacity of deep encoders which is shown to be directly related to the encoder capacity, being a measure of the distinguishability among samples from their representations. Our results support some recent regularization methods.