 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombinatorial Multi-Objective Multi-Armed Bandit Problem
Mar 11, 2018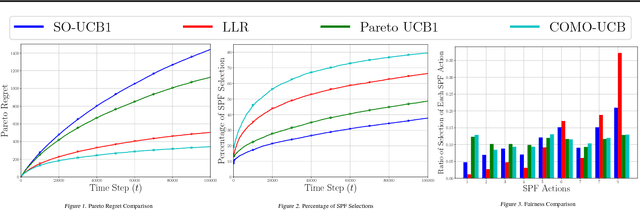
In this paper, we introduce the COmbinatorial Multi-Objective Multi-Armed Bandit (COMO-MAB) problem that captures the challenges of combinatorial and multi-objective online learning simultaneously. In this setting, the goal of the learner is to choose an action at each time, whose reward vector is a linear combination of the reward vectors of the arms in the action, to learn the set of super Pareto optimal actions, which includes the Pareto optimal actions and actions that become Pareto optimal after adding an arbitrary small positive number to their expected reward vectors. We define the Pareto regret performance metric and propose a fair learning algorithm whose Pareto regret is $O(N L^3 \log T)$, where $T$ is the time horizon, $N$ is the number of arms and $L$ is the maximum number of arms in an action. We show that COMO-MAB has a wide range of applications, including recommending bundles of items to users and network routing, and focus on a resource-allocation application for multi-user communication in the presence of multidimensional performance metrics, where we show that our algorithm outperforms existing MAB algorithms.
Multi-objective Contextual Bandit Problem with Similarity Information
Mar 11, 2018
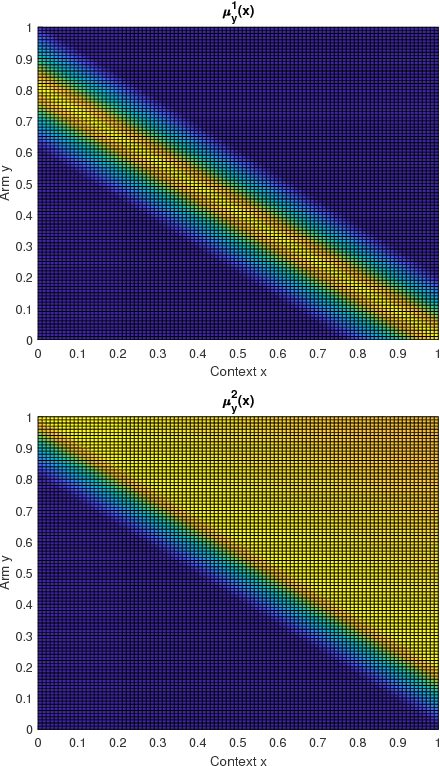
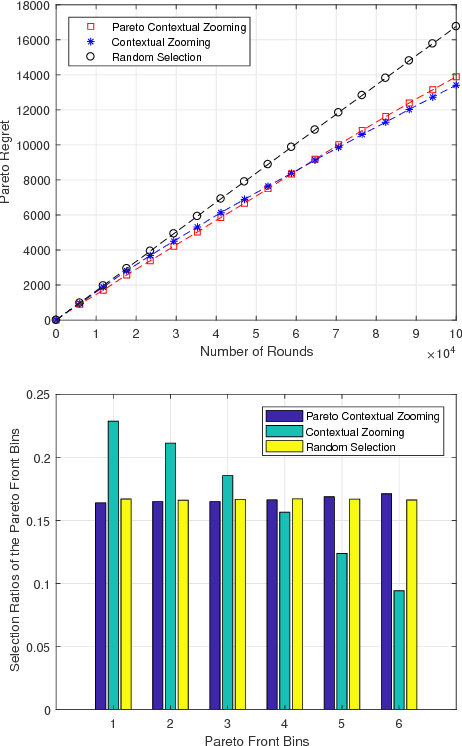
In this paper we propose the multi-objective contextual bandit problem with similarity information. This problem extends the classical contextual bandit problem with similarity information by introducing multiple and possibly conflicting objectives. Since the best arm in each objective can be different given the context, learning the best arm based on a single objective can jeopardize the rewards obtained from the other objectives. In order to evaluate the performance of the learner in this setup, we use a performance metric called the contextual Pareto regret. Essentially, the contextual Pareto regret is the sum of the distances of the arms chosen by the learner to the context dependent Pareto front. For this problem, we develop a new online learning algorithm called Pareto Contextual Zooming (PCZ), which exploits the idea of contextual zooming to learn the arms that are close to the Pareto front for each observed context by adaptively partitioning the joint context-arm set according to the observed rewards and locations of the context-arm pairs selected in the past. Then, we prove that PCZ achieves $\tilde O (T^{(1+d_p)/(2+d_p)})$ Pareto regret where $d_p$ is the Pareto zooming dimension that depends on the size of the set of near-optimal context-arm pairs. Moreover, we show that this regret bound is nearly optimal by providing an almost matching $\Omega (T^{(1+d_p)/(2+d_p)})$ lower bound.