 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Efficient Multitask Neural Network for Face Alignment, Head Pose Estimation and Face Tracking
Mar 13, 2021
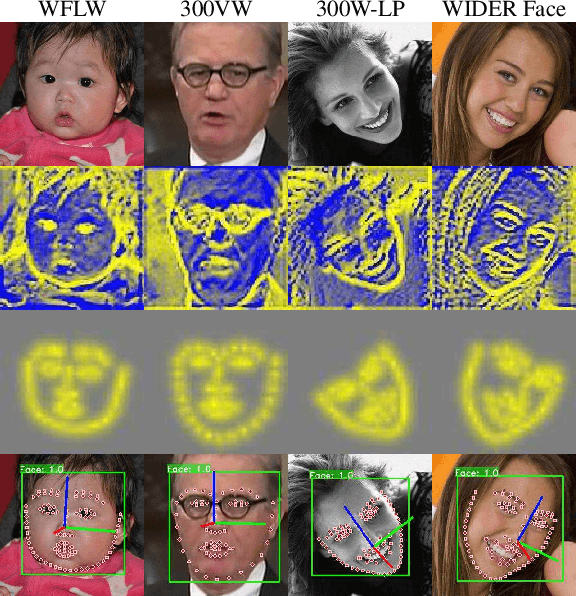
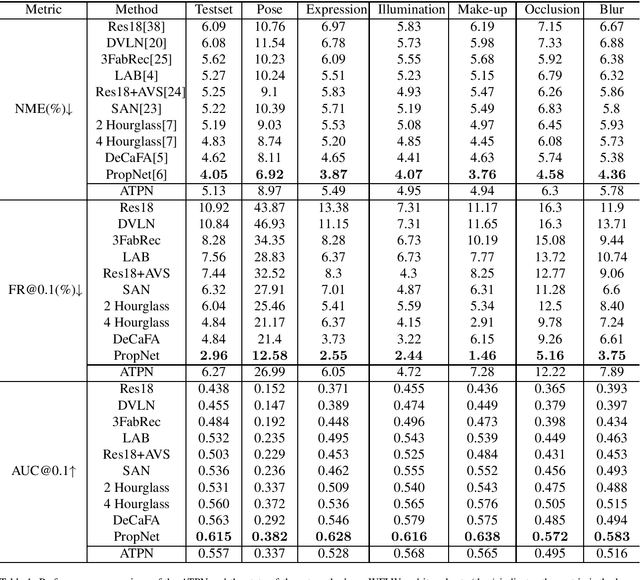
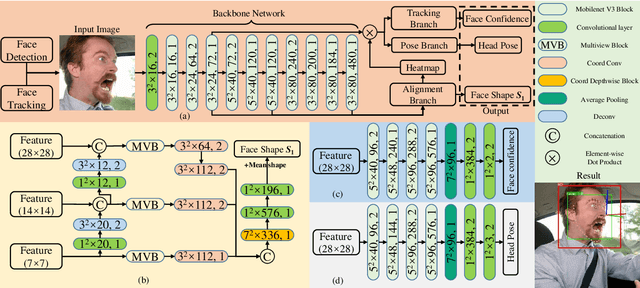
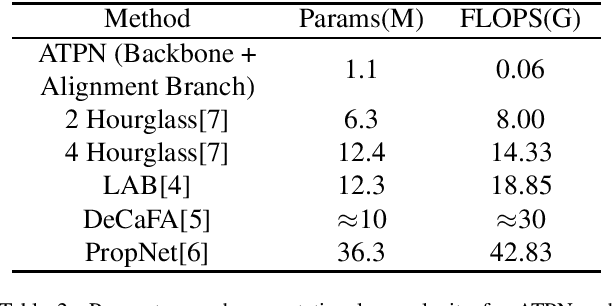
While convolutional neural networks (CNNs) have significantly boosted the performance of face related algorithms, maintaining accuracy and efficiency simultaneously in practical use remains challenging. Recent study shows that using a cascade of hourglass modules which consist of a number of bottom-up and top-down convolutional layers can extract facial structural information for face alignment to improve accuracy. However, previous studies have shown that features produced by shallow convolutional layers are highly correspond to edges. These features could be directly used to provide the structural information without addition cost. Motivated by this intuition, we propose an efficient multitask face alignment, face tracking and head pose estimation network (ATPN). Specifically, we introduce a shortcut connection between shallow-layer features and deep-layer features to provide the structural information for face alignment and apply the CoordConv to the last few layers to provide coordinate information. The predicted facial landmarks enable us to generate a cheap heatmap which contains both geometric and appearance information for head pose estimation and it also provides attention clues for face tracking. Moreover, the face tracking task saves us the face detection procedure for each frame, which is significant to boost performance for video-based tasks. The proposed framework is evaluated on four benchmark datasets, WFLW, 300VW, WIDER Face and 300W-LP. The experimental results show that the ATPN achieves improved performance compared to previous state-of-the-art methods while having less number of parameters and FLOPS.
ST-HOI: A Spatial-Temporal Baseline for Human-Object Interaction Detection in Videos
May 25, 2021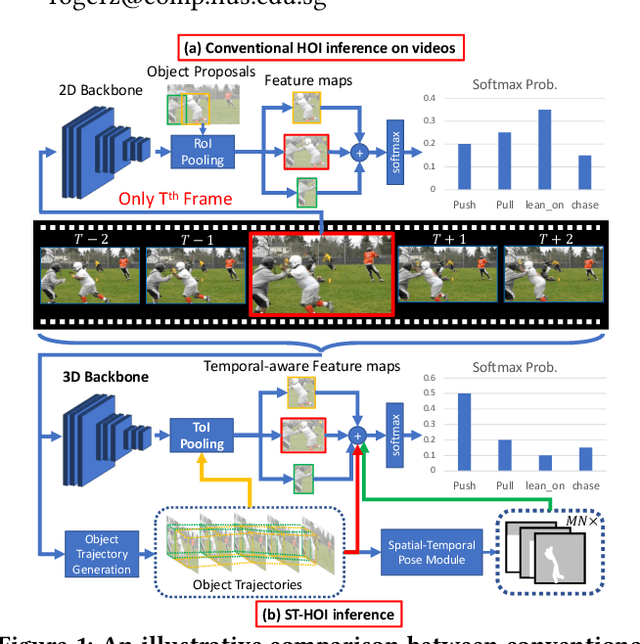

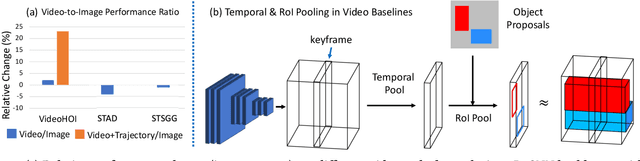
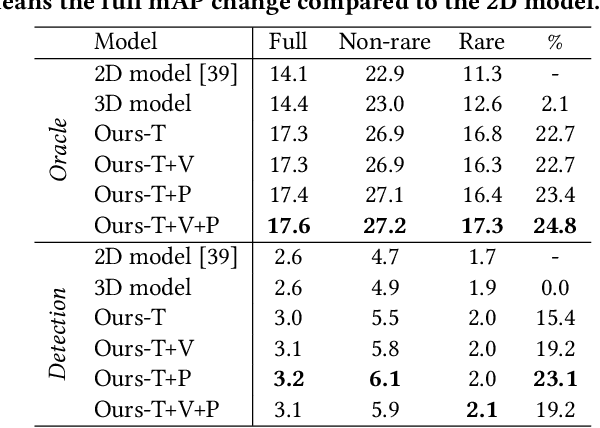
Detecting human-object interactions (HOI) is an important step toward a comprehensive visual understanding of machines. While detecting non-temporal HOIs (e.g., sitting on a chair) from static images is feasible, it is unlikely even for humans to guess temporal-related HOIs (e.g., opening/closing a door) from a single video frame, where the neighboring frames play an essential role. However, conventional HOI methods operating on only static images have been used to predict temporal-related interactions, which is essentially guessing without temporal contexts and may lead to sub-optimal performance. In this paper, we bridge this gap by detecting video-based HOIs with explicit temporal information. We first show that a naive temporal-aware variant of a common action detection baseline does not work on video-based HOIs due to a feature-inconsistency issue. We then propose a simple yet effective architecture named Spatial-Temporal HOI Detection (ST-HOI) utilizing temporal information such as human and object trajectories, correctly-localized visual features, and spatial-temporal masking pose features. We construct a new video HOI benchmark dubbed VidHOI where our proposed approach serves as a solid baseline.
Model-agnostic vs. Model-intrinsic Interpretability for Explainable Product Search
Aug 11, 2021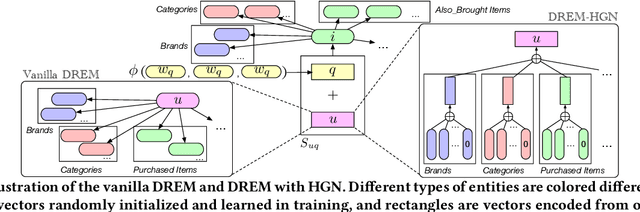
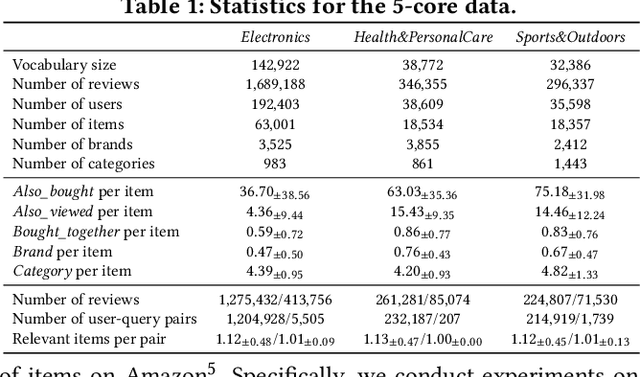

Product retrieval systems have served as the main entry for customers to discover and purchase products online. With increasing concerns on the transparency and accountability of AI systems, studies on explainable information retrieval has received more and more attention in the research community. Interestingly, in the domain of e-commerce, despite the extensive studies on explainable product recommendation, the studies of explainable product search is still in an early stage. In this paper, we study how to construct effective explainable product search by comparing model-agnostic explanation paradigms with model-intrinsic paradigms and analyzing the important factors that determine the performance of product search explanations. We propose an explainable product search model with model-intrinsic interpretability and conduct crowdsourcing to compare it with the state-of-the-art explainable product search model with model-agnostic interpretability. We observe that both paradigms have their own advantages and the effectiveness of search explanations on different properties are affected by different factors. For example, explanation fidelity is more important for user's overall satisfaction on the system while explanation novelty may be more useful in attracting user purchases. These findings could have important implications for the future studies and design of explainable product search engines.
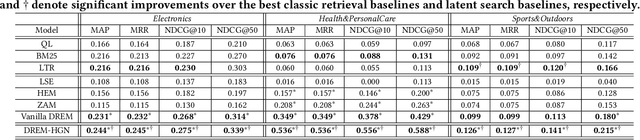
PCN: Part and Context Information for Pedestrian Detection with CNNs
Apr 12, 2018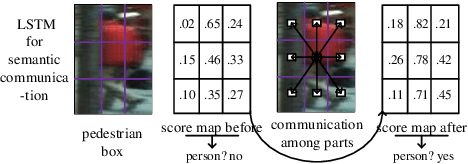

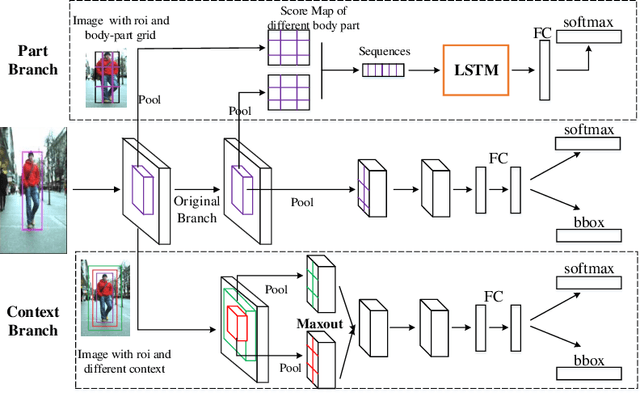
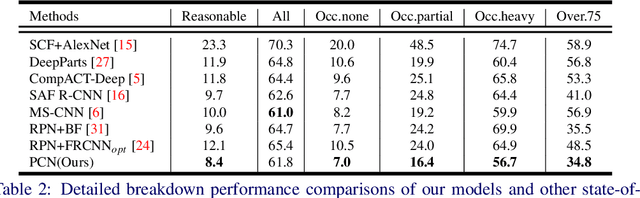
Pedestrian detection has achieved great improvements in recent years, while complex occlusion handling is still one of the most important problems. To take advantage of the body parts and context information for pedestrian detection, we propose the part and context network (PCN) in this work. PCN specially utilizes two branches which detect the pedestrians through body parts semantic and context information, respectively. In the Part Branch, the semantic information of body parts can communicate with each other via recurrent neural networks. In the Context Branch, we adopt a local competition mechanism for adaptive context scale selection. By combining the outputs of all branches, we develop a strong complementary pedestrian detector with a lower miss rate and better localization accuracy, especially for occlusion pedestrian. Comprehensive evaluations on two challenging pedestrian detection datasets (i.e. Caltech and INRIA) well demonstrated the effectiveness of the proposed PCN.
End-to-end Ultrasound Frame to Volume Registration
Jul 14, 2021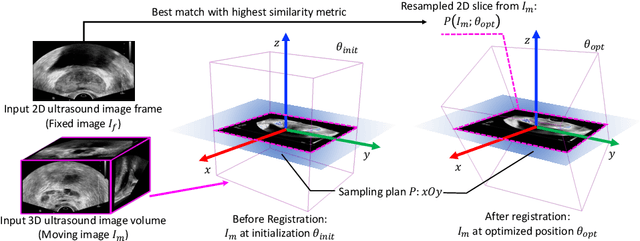
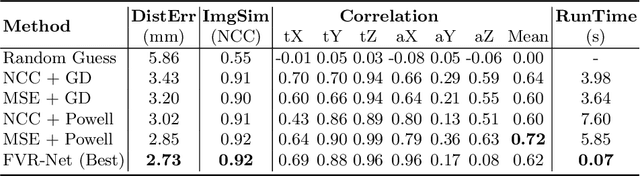
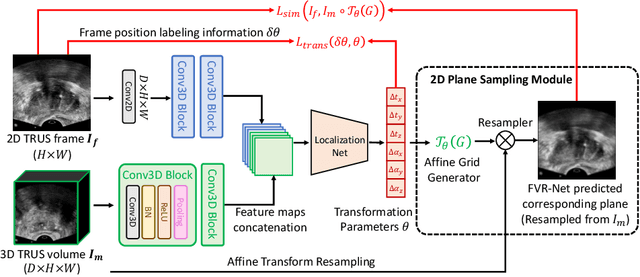
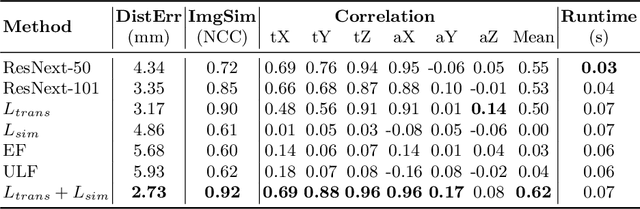
Fusing intra-operative 2D transrectal ultrasound (TRUS) image with pre-operative 3D magnetic resonance (MR) volume to guide prostate biopsy can significantly increase the yield. However, such a multimodal 2D/3D registration problem is a very challenging task. In this paper, we propose an end-to-end frame-to-volume registration network (FVR-Net), which can efficiently bridge the previous research gaps by aligning a 2D TRUS frame with a 3D TRUS volume without requiring hardware tracking. The proposed FVR-Net utilizes a dual-branch feature extraction module to extract the information from TRUS frame and volume to estimate transformation parameters. We also introduce a differentiable 2D slice sampling module which allows gradients backpropagating from an unsupervised image similarity loss for content correspondence learning. Our model shows superior efficiency for real-time interventional guidance with highly competitive registration accuracy.
A Real-Time Online Learning Framework for Joint 3D Reconstruction and Semantic Segmentation of Indoor Scenes
Aug 11, 2021
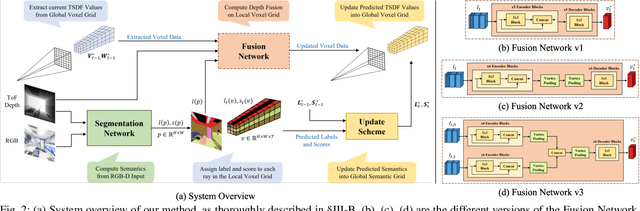

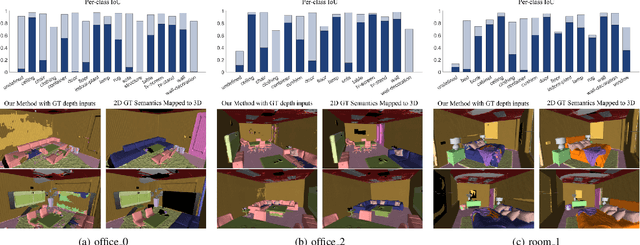
This paper presents a real-time online vision framework to jointly recover an indoor scene's 3D structure and semantic label. Given noisy depth maps, a camera trajectory, and 2D semantic labels at train time, the proposed neural network learns to fuse the depth over frames with suitable semantic labels in the scene space. Our approach exploits the joint volumetric representation of the depth and semantics in the scene feature space to solve this task. For a compelling online fusion of the semantic labels and geometry in real-time, we introduce an efficient vortex pooling block while dropping the routing network in online depth fusion to preserve high-frequency surface details. We show that the context information provided by the semantics of the scene helps the depth fusion network learn noise-resistant features. Not only that, it helps overcome the shortcomings of the current online depth fusion method in dealing with thin object structures, thickening artifacts, and false surfaces. Experimental evaluation on the Replica dataset shows that our approach can perform depth fusion at 37, 10 frames per second with an average reconstruction F-score of 88%, and 91%, respectively, depending on the depth map resolution. Moreover, our model shows an average IoU score of 0.515 on the ScanNet 3D semantic benchmark leaderboard.
Tourbillon: a Physically Plausible Neural Architecture
Jul 22, 2021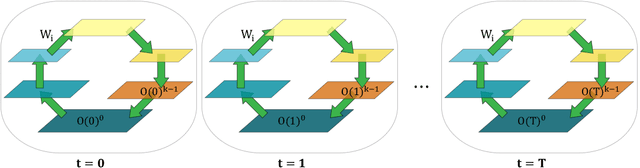
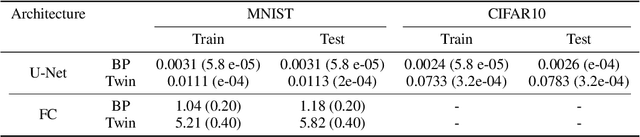
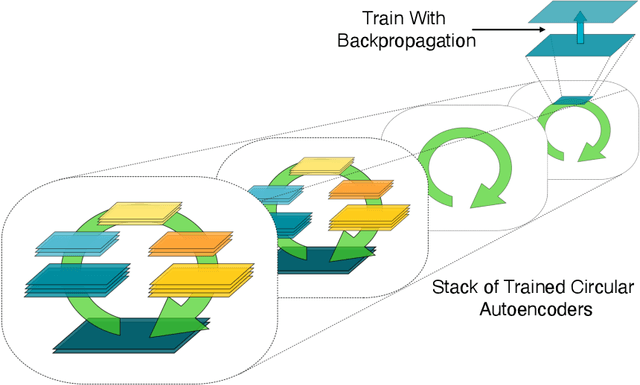
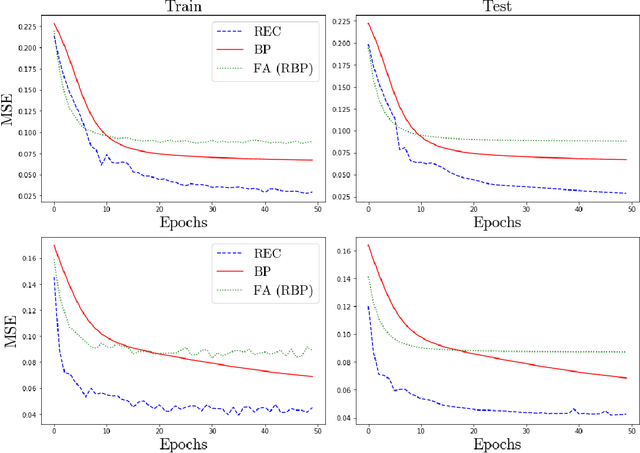
In a physical neural system, backpropagation is faced with a number of obstacles including: the need for labeled data, the violation of the locality learning principle, the need for symmetric connections, and the lack of modularity. Tourbillon is a new architecture that addresses all these limitations. At its core, it consists of a stack of circular autoencoders followed by an output layer. The circular autoencoders are trained in self-supervised mode by recirculation algorithms and the top layer in supervised mode by stochastic gradient descent, with the option of propagating error information through the entire stack using non-symmetric connections. While the Tourbillon architecture is meant primarily to address physical constraints, and not to improve current engineering applications of deep learning, we demonstrate its viability on standard benchmark datasets including MNIST, Fashion MNIST, and CIFAR10. We show that Tourbillon can achieve comparable performance to models trained with backpropagation and outperform models that are trained with other physically plausible algorithms, such as feedback alignment.
Group-Node Attention for Community Evolution Prediction
Jul 09, 2021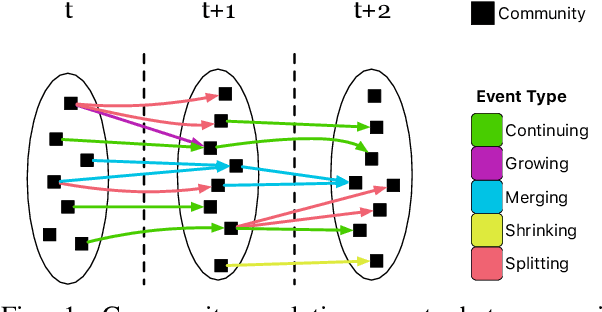
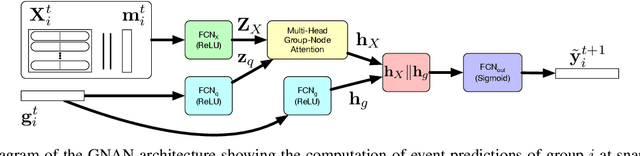
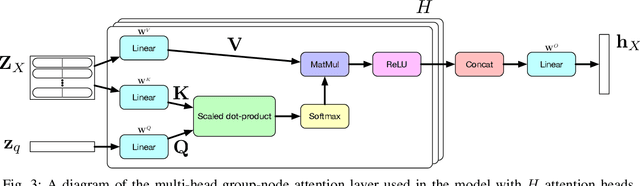
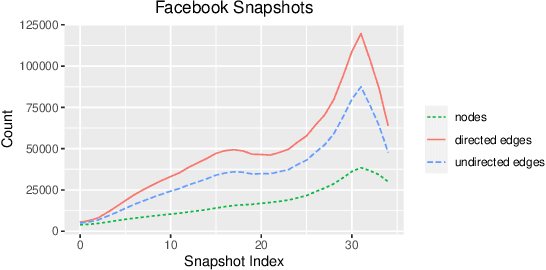
Communities in social networks evolve over time as people enter and leave the network and their activity behaviors shift. The task of predicting structural changes in communities over time is known as community evolution prediction. Existing work in this area has focused on the development of frameworks for defining events while using traditional classification methods to perform the actual prediction. We present a novel graph neural network for predicting community evolution events from structural and temporal information. The model (GNAN) includes a group-node attention component which enables support for variable-sized inputs and learned representation of groups based on member and neighbor node features. A comparative evaluation with standard baseline methods is performed and we demonstrate that our model outperforms the baselines. Additionally, we show the effects of network trends on model performance.
LSENet: Location and Seasonality Enhanced Network for Multi-Class Ocean Front Detection
Aug 05, 2021
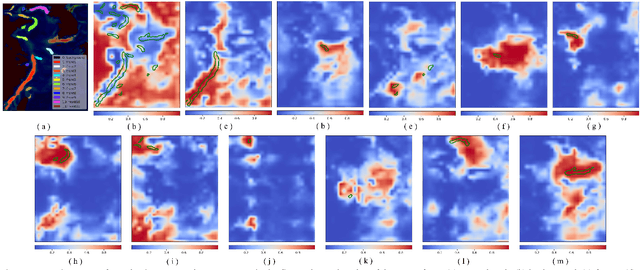
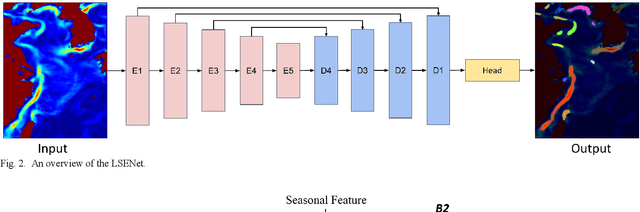
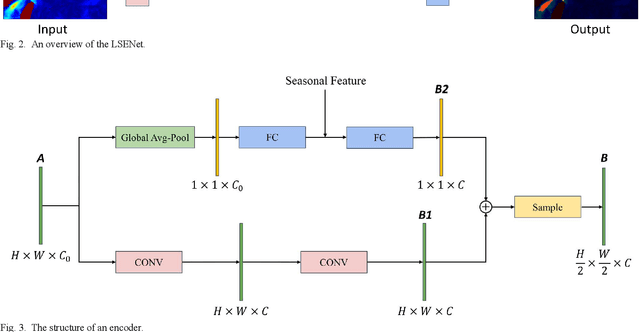
Ocean fronts can cause the accumulation of nutrients and affect the propagation of underwater sound, so high-precision ocean front detection is of great significance to the marine fishery and national defense fields. However, the current ocean front detection methods either have low detection accuracy or most can only detect the occurrence of ocean front by binary classification, rarely considering the differences of the characteristics of multiple ocean fronts in different sea areas. In order to solve the above problems, we propose a semantic segmentation network called location and seasonality enhanced network (LSENet) for multi-class ocean fronts detection at pixel level. In this network, we first design a channel supervision unit structure, which integrates the seasonal characteristics of the ocean front itself and the contextual information to improve the detection accuracy. We also introduce a location attention mechanism to adaptively assign attention weights to the fronts according to their frequently occurred sea area, which can further improve the accuracy of multi-class ocean front detection. Compared with other semantic segmentation methods and current representative ocean front detection method, the experimental results demonstrate convincingly that our method is more effective.
TransLoc3D : Point Cloud based Large-scale Place Recognition using Adaptive Receptive Fields
May 25, 2021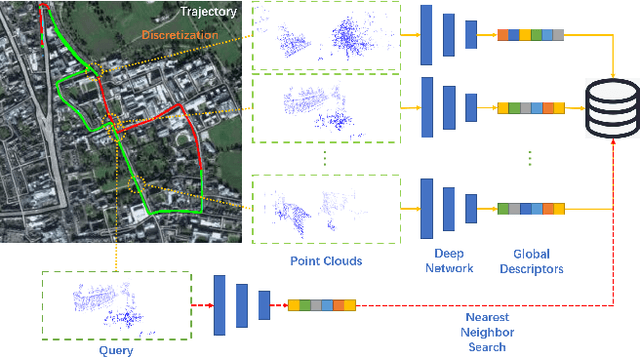
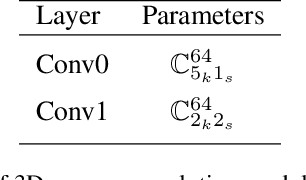
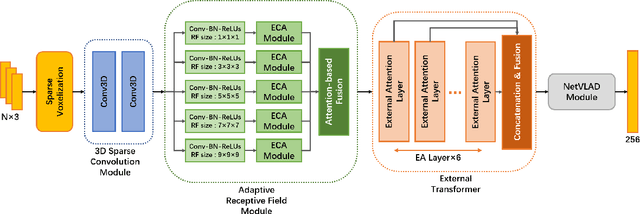
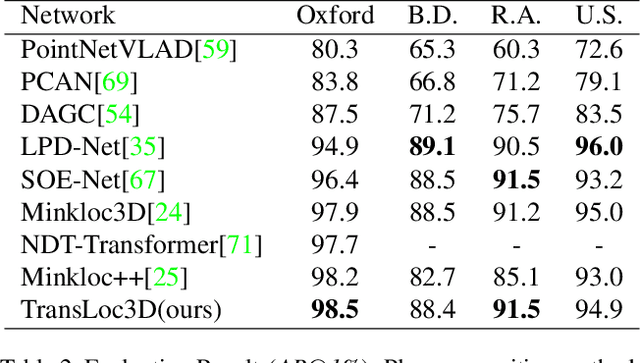
Place recognition plays an essential role in the field of autonomous driving and robot navigation. Although a number of point cloud based methods have been proposed and achieved promising results, few of them take the size difference of objects into consideration. For small objects like pedestrians and vehicles, large receptive fields will capture unrelated information, while small receptive fields would fail to encode complete geometric information for large objects such as buildings. We argue that fixed receptive fields are not well suited for place recognition, and propose a novel Adaptive Receptive Field Module (ARFM), which can adaptively adjust the size of the receptive field based on the input point cloud. We also present a novel network architecture, named TransLoc3D, to obtain discriminative global descriptors of point clouds for the place recognition task. TransLoc3D consists of a 3D sparse convolutional module, an ARFM module, an external transformer network which aims to capture long range dependency and a NetVLAD layer. Experiments show that our method outperforms prior state-of-the-art results, with an improvement of 1.1\% on average recall@1 on the Oxford RobotCar dataset, and 0.8\% on the B.D. dataset.