 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometryCrafter: Consistent Geometry Estimation for Open-world Videos with Diffusion Priors
Apr 01, 2025



Despite remarkable advancements in video depth estimation, existing methods exhibit inherent limitations in achieving geometric fidelity through the affine-invariant predictions, limiting their applicability in reconstruction and other metrically grounded downstream tasks. We propose GeometryCrafter, a novel framework that recovers high-fidelity point map sequences with temporal coherence from open-world videos, enabling accurate 3D/4D reconstruction, camera parameter estimation, and other depth-based applications. At the core of our approach lies a point map Variational Autoencoder (VAE) that learns a latent space agnostic to video latent distributions for effective point map encoding and decoding. Leveraging the VAE, we train a video diffusion model to model the distribution of point map sequences conditioned on the input videos. Extensive evaluations on diverse datasets demonstrate that GeometryCrafter achieves state-of-the-art 3D accuracy, temporal consistency, and generalization capability.
3D Gaussian Editing with A Single Image
Aug 14, 2024



The modeling and manipulation of 3D scenes captured from the real world are pivotal in various applications, attracting growing research interest. While previous works on editing have achieved interesting results through manipulating 3D meshes, they often require accurately reconstructed meshes to perform editing, which limits their application in 3D content generation. To address this gap, we introduce a novel single-image-driven 3D scene editing approach based on 3D Gaussian Splatting, enabling intuitive manipulation via directly editing the content on a 2D image plane. Our method learns to optimize the 3D Gaussians to align with an edited version of the image rendered from a user-specified viewpoint of the original scene. To capture long-range object deformation, we introduce positional loss into the optimization process of 3D Gaussian Splatting and enable gradient propagation through reparameterization. To handle occluded 3D Gaussians when rendering from the specified viewpoint, we build an anchor-based structure and employ a coarse-to-fine optimization strategy capable of handling long-range deformation while maintaining structural stability. Furthermore, we design a novel masking strategy to adaptively identify non-rigid deformation regions for fine-scale modeling. Extensive experiments show the effectiveness of our method in handling geometric details, long-range, and non-rigid deformation, demonstrating superior editing flexibility and quality compared to previous approaches.
Texture-GS: Disentangling the Geometry and Texture for 3D Gaussian Splatting Editing
Mar 15, 2024



3D Gaussian splatting, emerging as a groundbreaking approach, has drawn increasing attention for its capabilities of high-fidelity reconstruction and real-time rendering. However, it couples the appearance and geometry of the scene within the Gaussian attributes, which hinders the flexibility of editing operations, such as texture swapping. To address this issue, we propose a novel approach, namely Texture-GS, to disentangle the appearance from the geometry by representing it as a 2D texture mapped onto the 3D surface, thereby facilitating appearance editing. Technically, the disentanglement is achieved by our proposed texture mapping module, which consists of a UV mapping MLP to learn the UV coordinates for the 3D Gaussian centers, a local Taylor expansion of the MLP to efficiently approximate the UV coordinates for the ray-Gaussian intersections, and a learnable texture to capture the fine-grained appearance. Extensive experiments on the DTU dataset demonstrate that our method not only facilitates high-fidelity appearance editing but also achieves real-time rendering on consumer-level devices, e.g. a single RTX 2080 Ti GPU.
MBPTrack: Improving 3D Point Cloud Tracking with Memory Networks and Box Priors
Mar 09, 2023



3D single object tracking has been a crucial problem for decades with numerous applications such as autonomous driving. Despite its wide-ranging use, this task remains challenging due to the significant appearance variation caused by occlusion and size differences among tracked targets. To address these issues, we present MBPTrack, which adopts a Memory mechanism to utilize past information and formulates localization in a coarse-to-fine scheme using Box Priors given in the first frame. Specifically, past frames with targetness masks serve as an external memory, and a transformer-based module propagates tracked target cues from the memory to the current frame. To precisely localize objects of all sizes, MBPTrack first predicts the target center via Hough voting. By leveraging box priors given in the first frame, we adaptively sample reference points around the target center that roughly cover the target of different sizes. Then, we obtain dense feature maps by aggregating point features into the reference points, where localization can be performed more effectively. Extensive experiments demonstrate that MBPTrack achieves state-of-the-art performance on KITTI, nuScenes and Waymo Open Dataset, while running at 50 FPS on a single RTX3090 GPU.
CXTrack: Improving 3D Point Cloud Tracking with Contextual Information
Nov 12, 2022



3D single object tracking plays an essential role in many applications, such as autonomous driving. It remains a challenging problem due to the large appearance variation and the sparsity of points caused by occlusion and limited sensor capabilities. Therefore, contextual information across two consecutive frames is crucial for effective object tracking. However, points containing such useful information are often overlooked and cropped out in existing methods, leading to insufficient use of important contextual knowledge. To address this issue, we propose CXTrack, a novel transformer-based network for 3D object tracking, which exploits ConteXtual information to improve the tracking results. Specifically, we design a target-centric transformer network that directly takes point features from two consecutive frames and the previous bounding box as input to explore contextual information and implicitly propagate target cues. To achieve accurate localization for objects of all sizes, we propose a transformer-based localization head with a novel center embedding module to distinguish the target from distractors. Extensive experiments on three large-scale datasets, KITTI, nuScenes and Waymo Open Dataset, show that CXTrack achieves state-of-the-art tracking performance while running at 29 FPS.
Gradient-based Point Cloud Denoising with Uniformity
Jul 21, 2022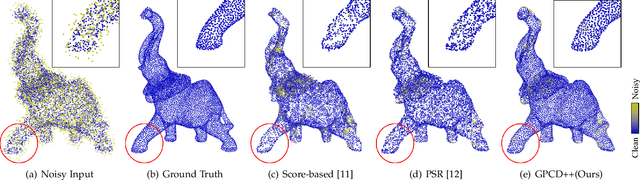
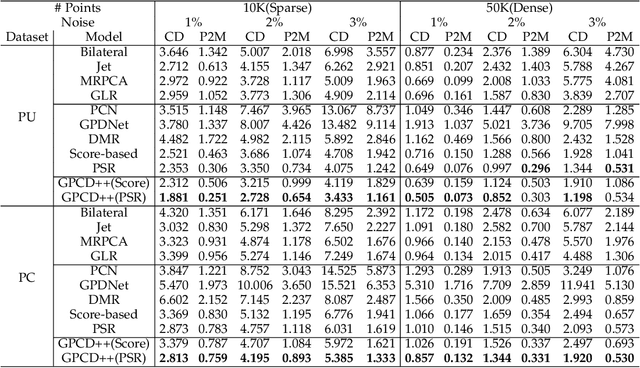
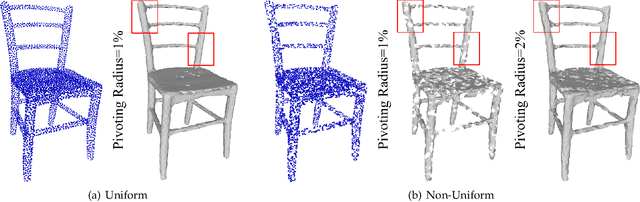
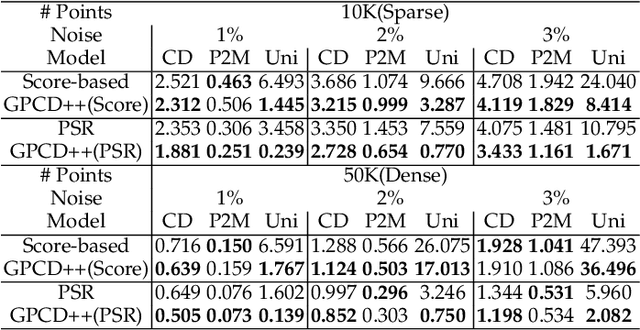
Point clouds captured by depth sensors are often contaminated by noises, obstructing further analysis and applications. In this paper, we emphasize the importance of point distribution uniformity to downstream tasks. We demonstrate that point clouds produced by existing gradient-based denoisers lack uniformity despite having achieved promising quantitative results. To this end, we propose GPCD++, a gradient-based denoiser with an ultra-lightweight network named UniNet to address uniformity. Compared with previous state-of-the-art methods, our approach not only generates competitive or even better denoising results, but also significantly improves uniformity which largely benefits applications such as surface reconstruction.
Attention Mechanisms in Computer Vision: A Survey
Nov 15, 2021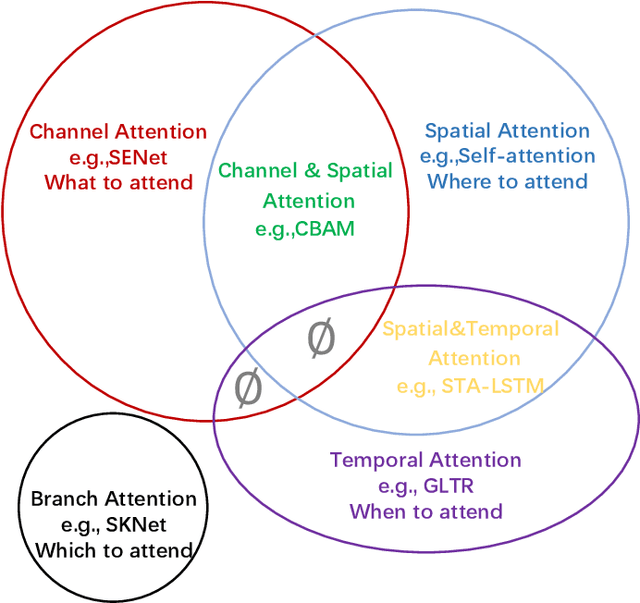

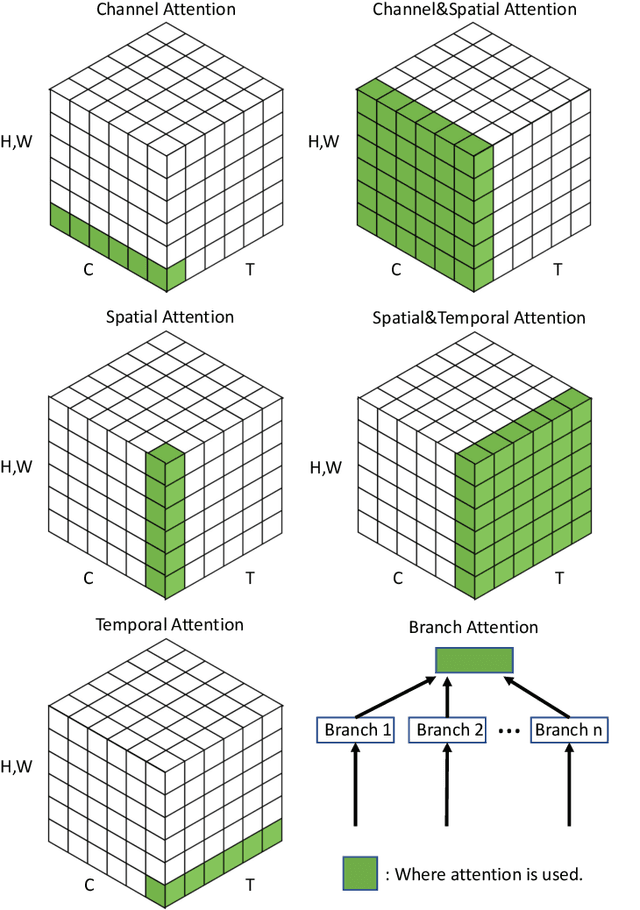
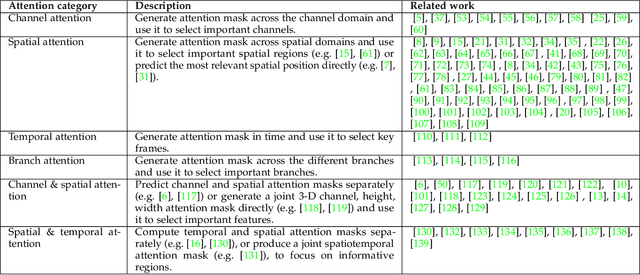
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is dedicated to collecting related work. We also suggest future directions for attention mechanism research.
TransLoc3D : Point Cloud based Large-scale Place Recognition using Adaptive Receptive Fields
Jun 01, 2021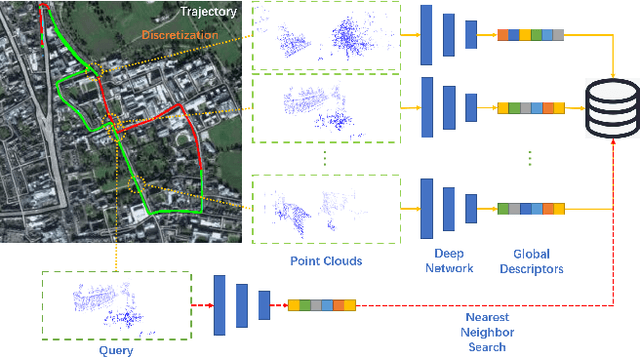
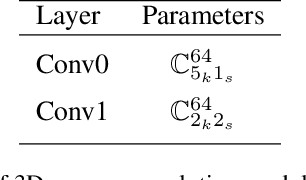
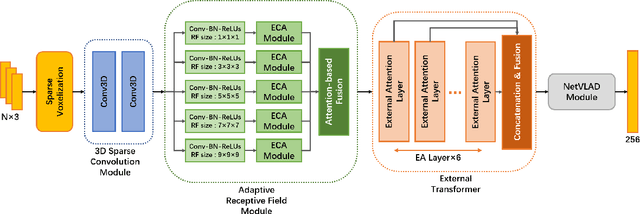
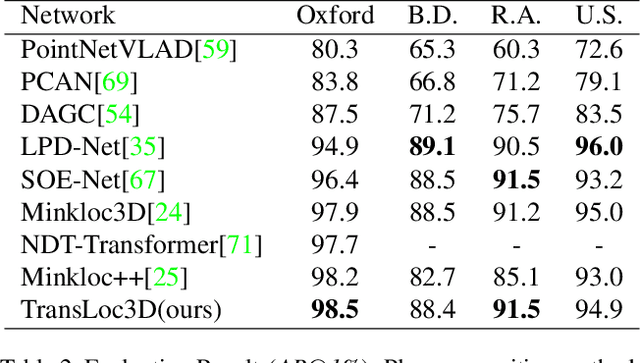
Place recognition plays an essential role in the field of autonomous driving and robot navigation. Although a number of point cloud based methods have been proposed and achieved promising results, few of them take the size difference of objects into consideration. For small objects like pedestrians and vehicles, large receptive fields will capture unrelated information, while small receptive fields would fail to encode complete geometric information for large objects such as buildings. We argue that fixed receptive fields are not well suited for place recognition, and propose a novel Adaptive Receptive Field Module (ARFM), which can adaptively adjust the size of the receptive field based on the input point cloud. We also present a novel network architecture, named TransLoc3D, to obtain discriminative global descriptors of point clouds for the place recognition task. TransLoc3D consists of a 3D sparse convolutional module, an ARFM module, an external transformer network which aims to capture long range dependency and a NetVLAD layer. Experiments show that our method outperforms prior state-of-the-art results, with an improvement of 1.1\% on average recall@1 on the Oxford RobotCar dataset, and 0.8\% on the B.D. dataset.