 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Hidden Structure in Self-Supervised Learning
Jun 30, 2021

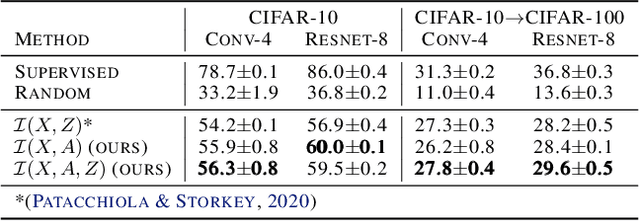
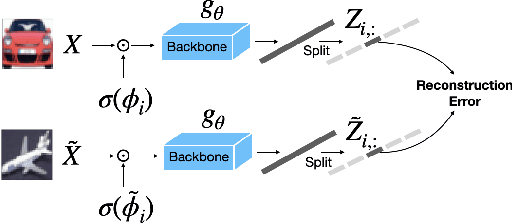
This work considers the problem of learning structured representations from raw images using self-supervised learning. We propose a principled framework based on a mutual information objective, which integrates self-supervised and structure learning. Furthermore, we devise a post-hoc procedure to interpret the meaning of the learnt representations. Preliminary experiments on CIFAR-10 show that the proposed framework achieves higher generalization performance in downstream classification tasks and provides more interpretable representations compared to the ones learnt through traditional self-supervised learning.
Multi-modal and frequency-weighted tensor nuclear norm for hyperspectral image denoising
Jun 23, 2021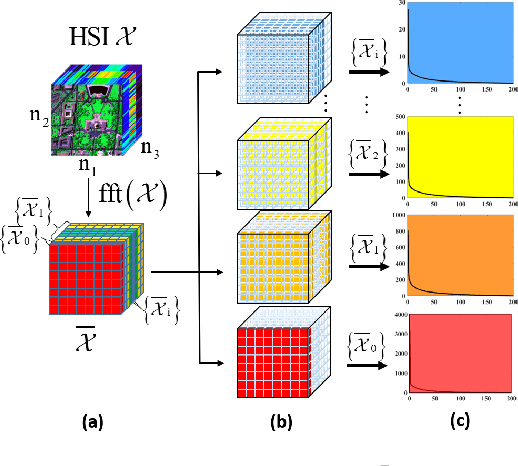

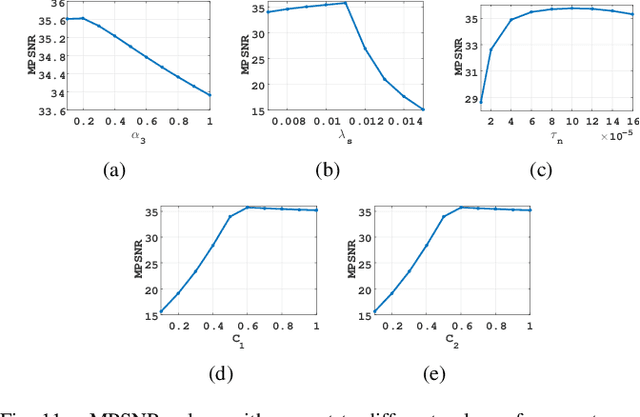
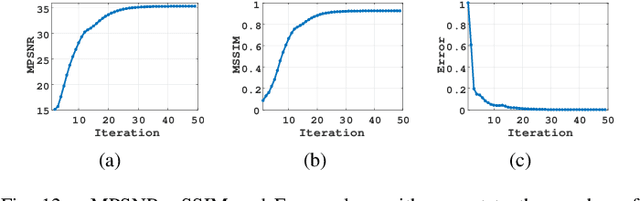
Low-rankness is important in the hyperspectral image (HSI) denoising tasks. The tensor nuclear norm (TNN), defined based on the tensor singular value decomposition, is a state-of-the-art method to describe the low-rankness of HSI. However, TNN ignores some of the physical meanings of HSI in tackling the denoising tasks, leading to suboptimal denoising performance. In this paper, we propose the multi-modal and frequency-weighted tensor nuclear norm (MFWTNN) and the non-convex MFWTNN for HSI denoising tasks. Firstly, we investigate the physical meaning of frequency components and reconsider their weights to improve the low-rank representation ability of TNN. Meanwhile, we also consider the correlation among two spatial dimensions and the spectral dimension of HSI and combine the above improvements to TNN to propose MFWTNN. Secondly, we use non-convex functions to approximate the rank function of the frequency tensor and propose the NonMFWTNN to relax the MFWTNN better. Besides, we adaptively choose bigger weights for slices mainly containing noise information and smaller weights for slices containing profile information. Finally, we develop the efficient alternating direction method of multiplier (ADMM) based algorithm to solve the proposed models, and the effectiveness of our models are substantiated in simulated and real HSI datasets.
A parallel-network continuous quantitative trading model with GARCH and PPO
May 21, 2021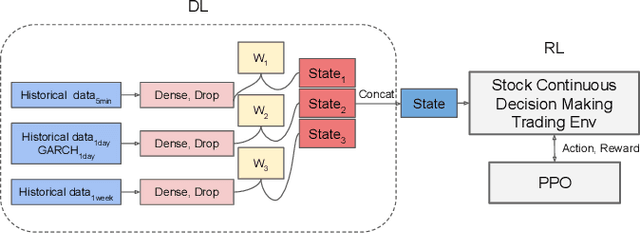
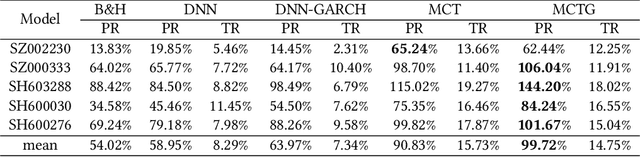
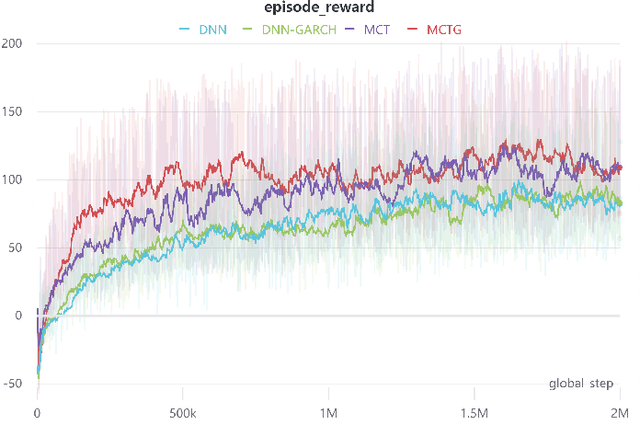
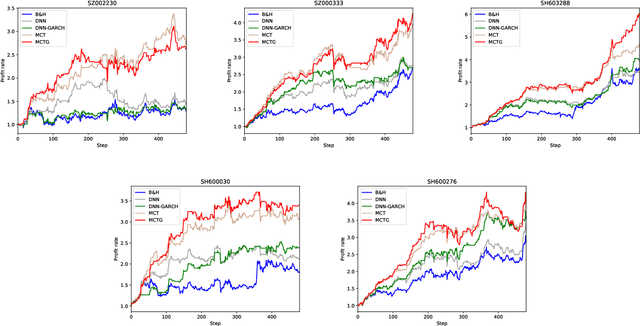
It is a difficult task for both professional investors and individual traders continuously making profit in stock market. With the development of computer science and deep reinforcement learning, Buy\&Hold (B\&H) has been oversteped by many artificial intelligence trading algorithms. However, the information and process are not enough, which limit the performance of reinforcement learning algorithms. Thus, we propose a parallel-network continuous quantitative trading model with GARCH and PPO to enrich the basical deep reinforcement learning model, where the deep learning parallel network layers deal with 3 different frequencies data (including GARCH information) and proximal policy optimization (PPO) algorithm interacts actions and rewards with stock trading environment. Experiments in 5 stocks from Chinese stock market show our method achieves more extra profit comparing with basical reinforcement learning methods and bench models.
Deep Learning from Dual-Energy Information for Whole-Heart Segmentation in Dual-Energy and Single-Energy Non-Contrast-Enhanced Cardiac CT
Aug 10, 2020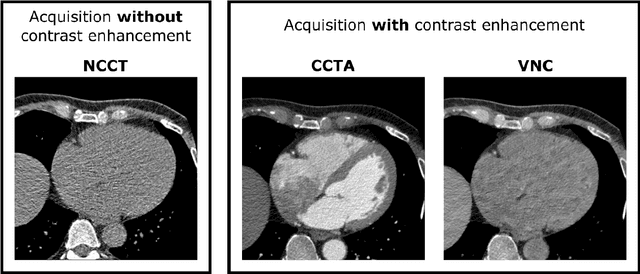
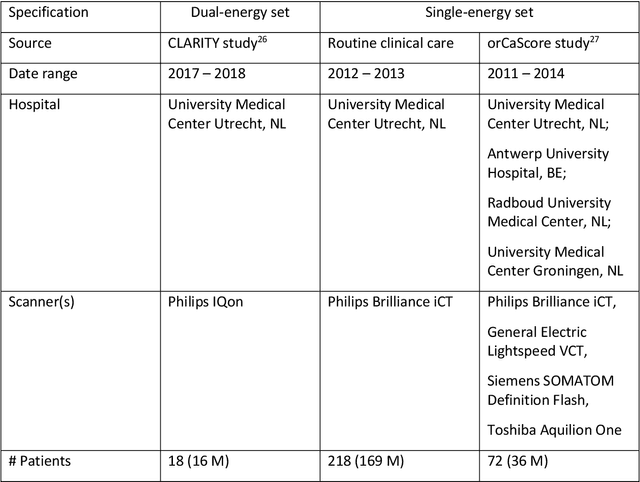
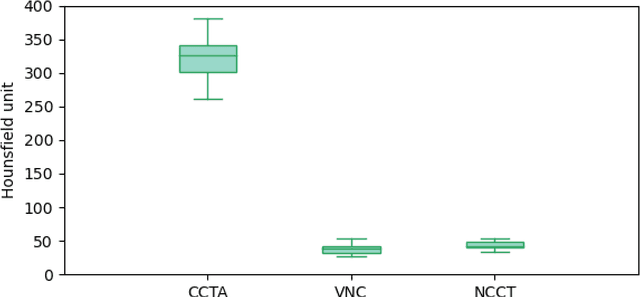

Deep learning-based whole-heart segmentation in coronary CT angiography (CCTA) allows the extraction of quantitative imaging measures for cardiovascular risk prediction. Automatic extraction of these measures in patients undergoing only non-contrast-enhanced CT (NCCT) scanning would be valuable. In this work, we leverage information provided by a dual-layer detector CT scanner to obtain a reference standard in virtual non-contrast (VNC) CT images mimicking NCCT images, and train a 3D convolutional neural network (CNN) for the segmentation of VNC as well as NCCT images. Contrast-enhanced acquisitions on a dual-layer detector CT scanner were reconstructed into a CCTA and a perfectly aligned VNC image. In each CCTA image, manual reference segmentations of the left ventricular (LV) myocardium, LV cavity, right ventricle, left atrium, right atrium, ascending aorta, and pulmonary artery trunk were obtained and propagated to the corresponding VNC image. These VNC images and reference segmentations were used to train 3D CNNs for automatic segmentation in either VNC images or NCCT images. Automatic segmentations in VNC images showed good agreement with reference segmentations, with an average Dice similarity coefficient of 0.897 \pm 0.034 and an average symmetric surface distance of 1.42 \pm 0.45 mm. Volume differences [95% confidence interval] between automatic NCCT and reference CCTA segmentations were -19 [-67; 30] mL for LV myocardium, -25 [-78; 29] mL for LV cavity, -29 [-73; 14] mL for right ventricle, -20 [-62; 21] mL for left atrium, and -19 [-73; 34] mL for right atrium, respectively. In 214 (74%) NCCT images from an independent multi-vendor multi-center set, two observers agreed that the automatic segmentation was mostly accurate or better. This method might enable quantification of additional cardiac measures from NCCT images for improved cardiovascular risk prediction.
CDCGen: Cross-Domain Conditional Generation via Normalizing Flows and Adversarial Training
Aug 25, 2021
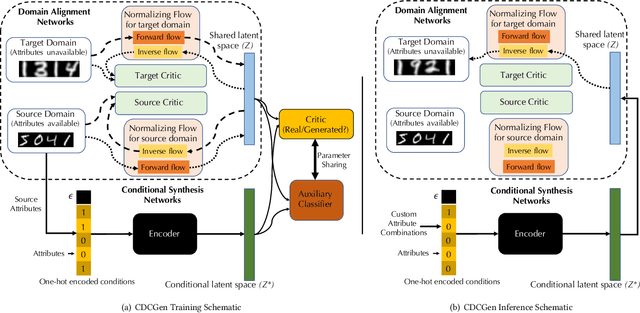


How to generate conditional synthetic data for a domain without utilizing information about its labels/attributes? Our work presents a solution to the above question. We propose a transfer learning-based framework utilizing normalizing flows, coupled with both maximum-likelihood and adversarial training. We model a source domain (labels available) and a target domain (labels unavailable) with individual normalizing flows, and perform domain alignment to a common latent space using adversarial discriminators. Due to the invertible property of flow models, the mapping has exact cycle consistency. We also learn the joint distribution of the data samples and attributes in the source domain by employing an encoder to map attributes to the latent space via adversarial training. During the synthesis phase, given any combination of attributes, our method can generate synthetic samples conditioned on them in the target domain. Empirical studies confirm the effectiveness of our method on benchmarked datasets. We envision our method to be particularly useful for synthetic data generation in label-scarce systems by generating non-trivial augmentations via attribute transformations. These synthetic samples will introduce more entropy into the label-scarce domain than their geometric and photometric transformation counterparts, helpful for robust downstream tasks.
Impact of Channel Aging on Zero-Forcing Precoding in Cell-Free Massive MIMO Systems
Jul 03, 2021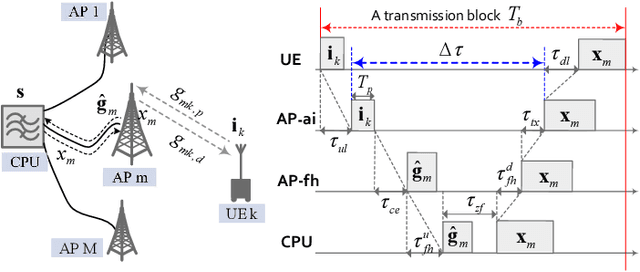
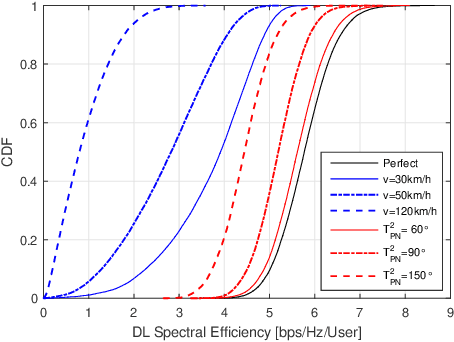
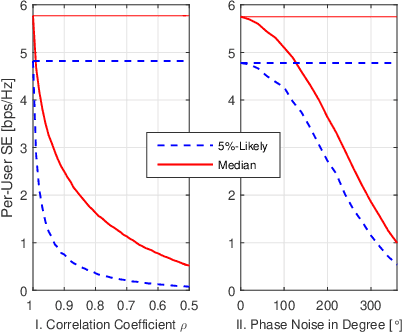
In the context of cell-free massive multi-input multi-output (mMIMO), zero-forcing precoding (ZFP) requires the exchange of instantaneous channel state information and precoded data symbols via a fronthaul network. It causes considerable propagation and processing delays, which degrade performance. This letter analyzes the impact of channel aging on the performance of ZFP in cell-free mMIMO. The aging effects of not only user mobility but also phase noise are considered. Numerical results in terms of per-user spectral efficiency are illustrated.
Direct Detection Under Tukey Signalling
May 28, 2021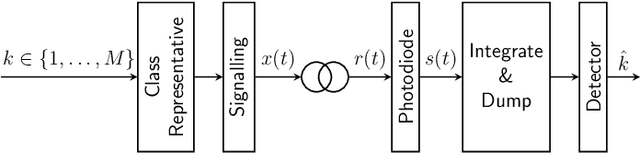
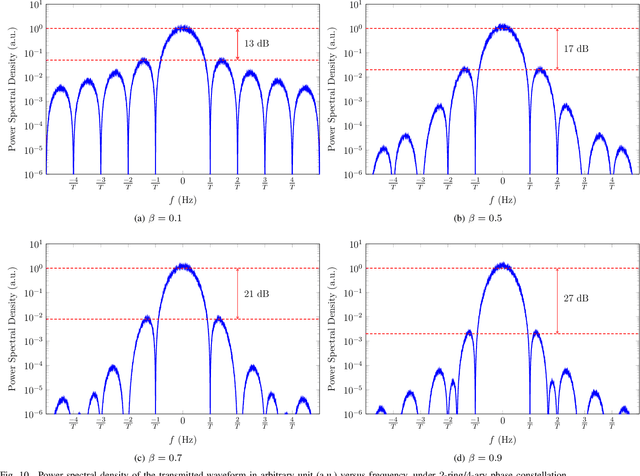
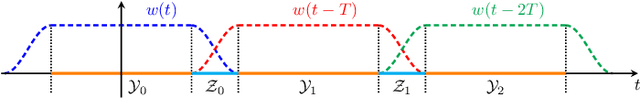
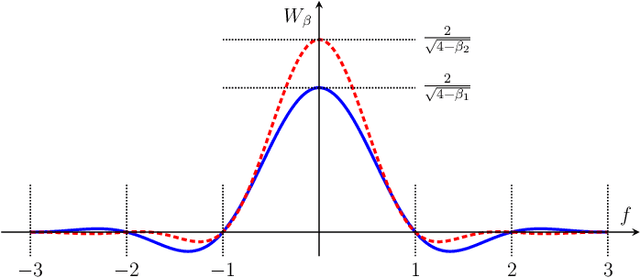
A new direct-detection-compatible signalling scheme is proposed for fiber-optic communication over short distances. Controlled inter-symbol interference is exploited to extract phase information, thereby achieving data rates within one bit per channel-use of those of a coherent detector.
FusionPainting: Multimodal Fusion with Adaptive Attention for 3D Object Detection
Jun 23, 2021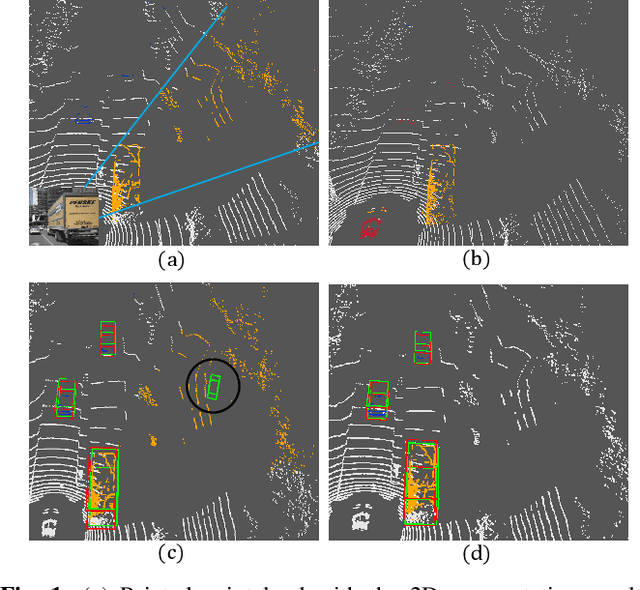
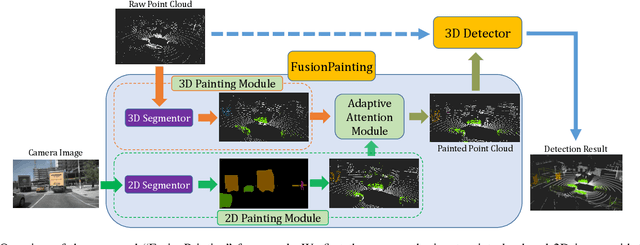
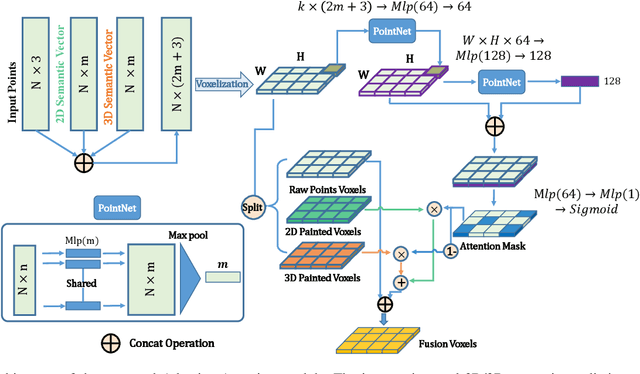
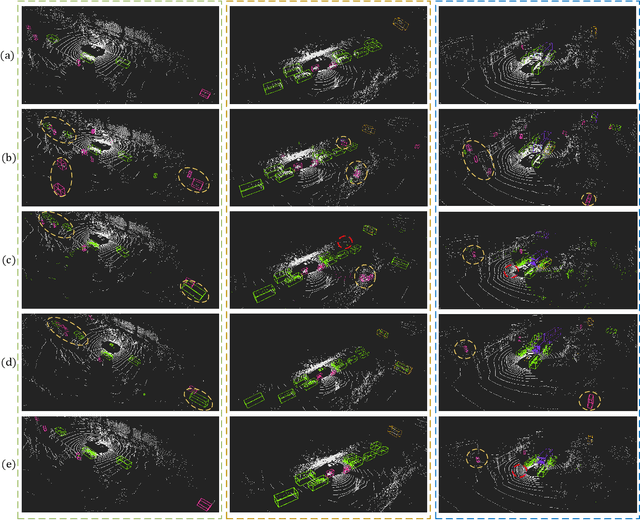
Accurate detection of obstacles in 3D is an essential task for autonomous driving and intelligent transportation. In this work, we propose a general multimodal fusion framework FusionPainting to fuse the 2D RGB image and 3D point clouds at a semantic level for boosting the 3D object detection task. Especially, the FusionPainting framework consists of three main modules: a multi-modal semantic segmentation module, an adaptive attention-based semantic fusion module, and a 3D object detector. First, semantic information is obtained for 2D images and 3D Lidar point clouds based on 2D and 3D segmentation approaches. Then the segmentation results from different sensors are adaptively fused based on the proposed attention-based semantic fusion module. Finally, the point clouds painted with the fused semantic label are sent to the 3D detector for obtaining the 3D objection results. The effectiveness of the proposed framework has been verified on the large-scale nuScenes detection benchmark by comparing it with three different baselines. The experimental results show that the fusion strategy can significantly improve the detection performance compared to the methods using only point clouds, and the methods using point clouds only painted with 2D segmentation information. Furthermore, the proposed approach outperforms other state-of-the-art methods on the nuScenes testing benchmark.
R-PCC: A Baseline for Range Image-based Point Cloud Compression
Sep 16, 2021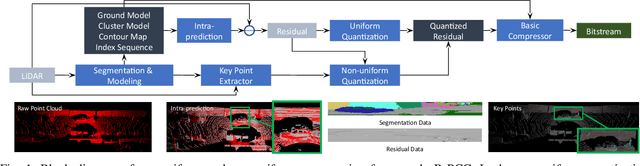
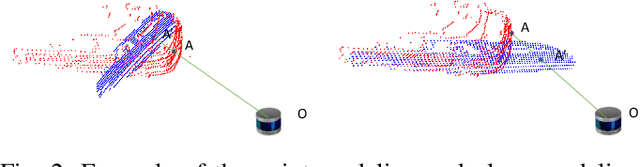

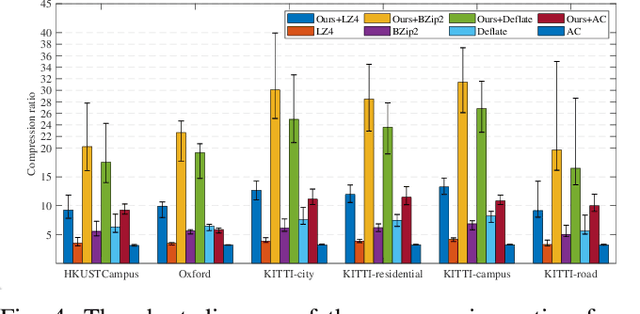
In autonomous vehicles or robots, point clouds from LiDAR can provide accurate depth information of objects compared with 2D images, but they also suffer a large volume of data, which is inconvenient for data storage or transmission. In this paper, we propose a Range image-based Point Cloud Compression method, R-PCC, which can reconstruct the point cloud with uniform or non-uniform accuracy loss. We segment the original large-scale point cloud into small and compact regions for spatial redundancy and salient region classification. Compared with other voxel-based or image-based compression methods, our method can keep and align all points from the original point cloud in the reconstructed point cloud. It can also control the maximum reconstruction error for each point through a quantization module. In the experiments, we prove that our easier FPS-based segmentation method can achieve better performance than instance-based segmentation methods such as DBSCAN. To verify the advantages of our proposed method, we evaluate the reconstruction quality and fidelity for 3D object detection and SLAM, as the downstream tasks. The experimental results show that our elegant framework can achieve 30$\times$ compression ratio without affecting downstream tasks, and our non-uniform compression framework shows a great improvement on the downstream tasks compared with the state-of-the-art large-scale point cloud compression methods. Our real-time method is efficient and effective enough to act as a baseline for range image-based point cloud compression. The code is available on https://github.com/StevenWang30/R-PCC.git.
Uni-FedRec: A Unified Privacy-Preserving News Recommendation Framework for Model Training and Online Serving
Sep 11, 2021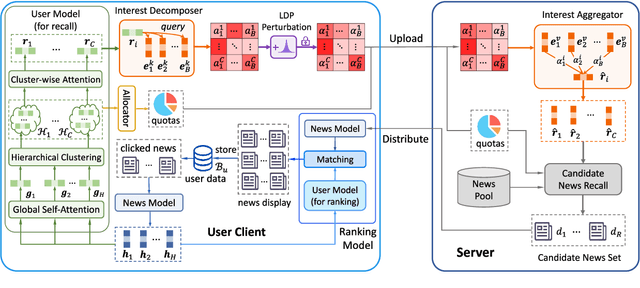
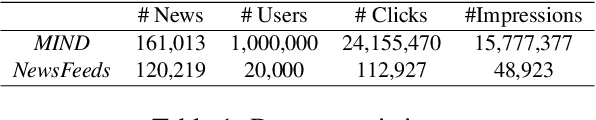
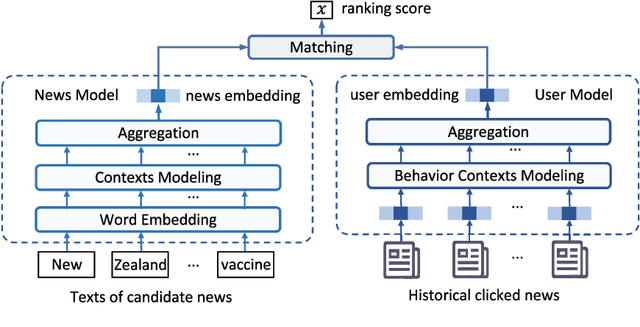
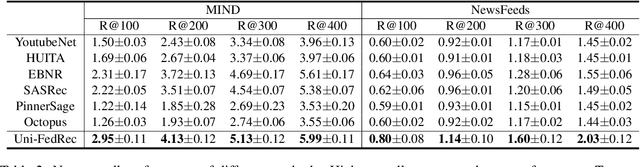
News recommendation is important for personalized online news services. Most existing news recommendation methods rely on centrally stored user behavior data to both train models offline and provide online recommendation services. However, user data is usually highly privacy-sensitive, and centrally storing them may raise privacy concerns and risks. In this paper, we propose a unified news recommendation framework, which can utilize user data locally stored in user clients to train models and serve users in a privacy-preserving way. Following a widely used paradigm in real-world recommender systems, our framework contains two stages. The first one is for candidate news generation (i.e., recall) and the second one is for candidate news ranking (i.e., ranking). At the recall stage, each client locally learns multiple interest representations from clicked news to comprehensively model user interests. These representations are uploaded to the server to recall candidate news from a large news pool, which are further distributed to the user client at the ranking stage for personalized news display. In addition, we propose an interest decomposer-aggregator method with perturbation noise to better protect private user information encoded in user interest representations. Besides, we collaboratively train both recall and ranking models on the data decentralized in a large number of user clients in a privacy-preserving way. Experiments on two real-world news datasets show that our method can outperform baseline methods and effectively protect user privacy.