 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Balancing detectability and performance of attacks on the control channel of Markov Decision Processes
Sep 15, 2021
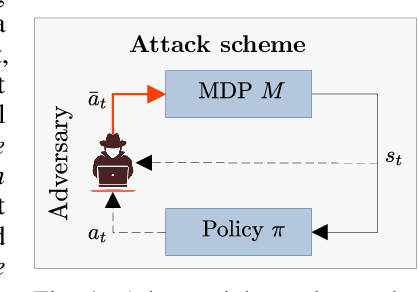
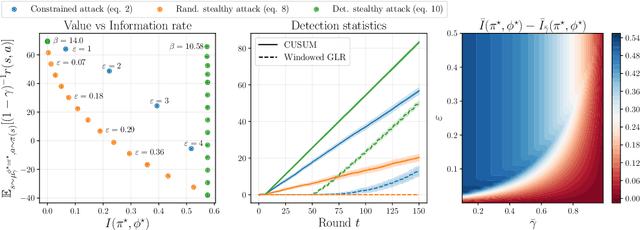
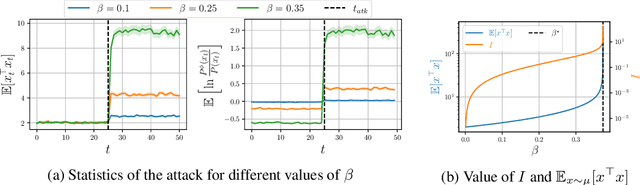
We investigate the problem of designing optimal stealthy poisoning attacks on the control channel of Markov decision processes (MDPs). This research is motivated by the recent interest of the research community for adversarial and poisoning attacks applied to MDPs, and reinforcement learning (RL) methods. The policies resulting from these methods have been shown to be vulnerable to attacks perturbing the observations of the decision-maker. In such an attack, drawing inspiration from adversarial examples used in supervised learning, the amplitude of the adversarial perturbation is limited according to some norm, with the hope that this constraint will make the attack imperceptible. However, such constraints do not grant any level of undetectability and do not take into account the dynamic nature of the underlying Markov process. In this paper, we propose a new attack formulation, based on information-theoretical quantities, that considers the objective of minimizing the detectability of the attack as well as the performance of the controlled process. We analyze the trade-off between the efficiency of the attack and its detectability. We conclude with examples and numerical simulations illustrating this trade-off.
Reinforcement Learning for Systematic FX Trading
Oct 10, 2021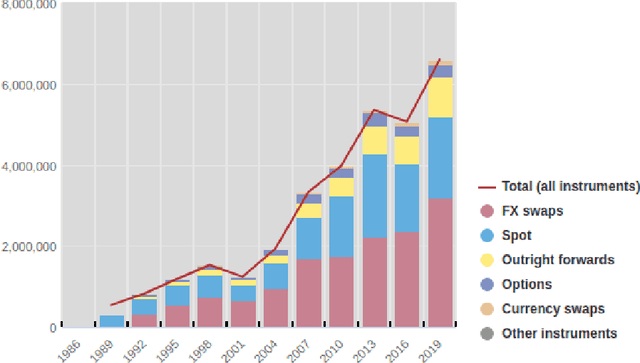
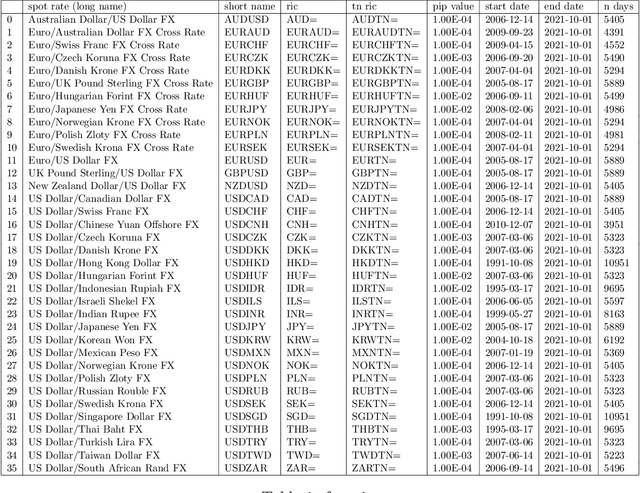
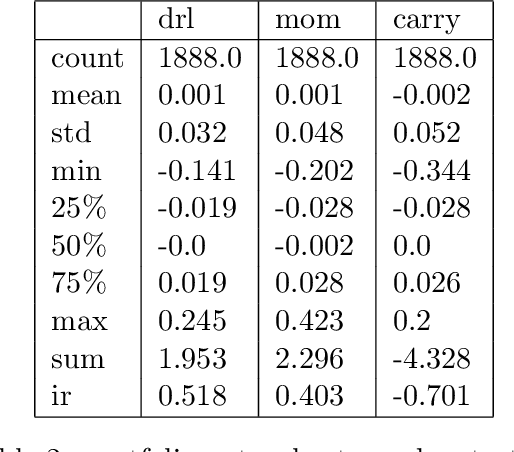
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
All You Can Embed: Natural Language based Vehicle Retrieval with Spatio-Temporal Transformers
Jun 18, 2021
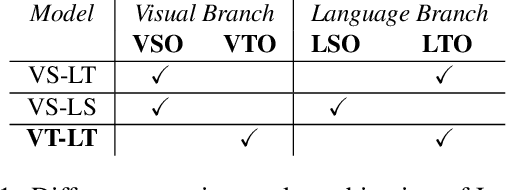
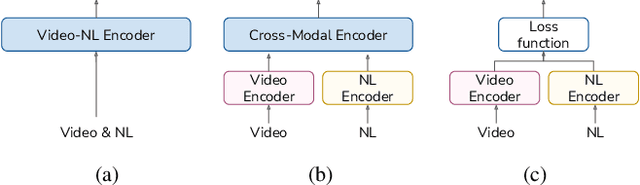
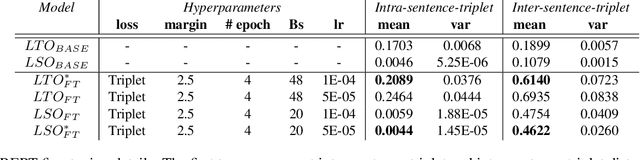
Combining Natural Language with Vision represents a unique and interesting challenge in the domain of Artificial Intelligence. The AI City Challenge Track 5 for Natural Language-Based Vehicle Retrieval focuses on the problem of combining visual and textual information, applied to a smart-city use case. In this paper, we present All You Can Embed (AYCE), a modular solution to correlate single-vehicle tracking sequences with natural language. The main building blocks of the proposed architecture are (i) BERT to provide an embedding of the textual descriptions, (ii) a convolutional backbone along with a Transformer model to embed the visual information. For the training of the retrieval model, a variation of the Triplet Margin Loss is proposed to learn a distance measure between the visual and language embeddings. The code is publicly available at https://github.com/cscribano/AYCE_2021.
Deep Reinforcement Learning for Green Security Games with Real-Time Information
Nov 06, 2018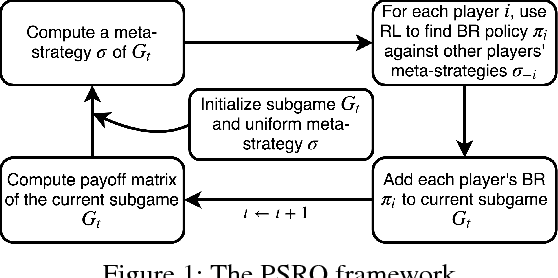
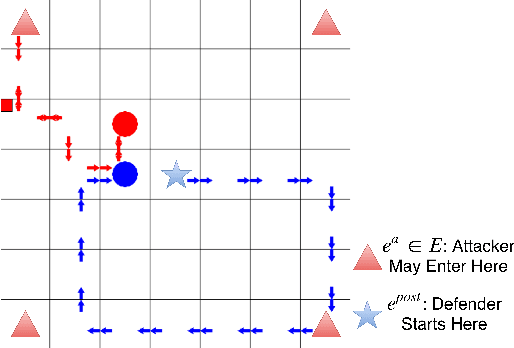

Green Security Games (GSGs) have been proposed and applied to optimize patrols conducted by law enforcement agencies in green security domains such as combating poaching, illegal logging and overfishing. However, real-time information such as footprints and agents' subsequent actions upon receiving the information, e.g., rangers following the footprints to chase the poacher, have been neglected in previous work. To fill the gap, we first propose a new game model GSG-I which augments GSGs with sequential movement and the vital element of real-time information. Second, we design a novel deep reinforcement learning-based algorithm, DeDOL, to compute a patrolling strategy that adapts to the real-time information against a best-responding attacker. DeDOL is built upon the double oracle framework and the policy-space response oracle, solving a restricted game and iteratively adding best response strategies to it through training deep Q-networks. Exploring the game structure, DeDOL uses domain-specific heuristic strategies as initial strategies and constructs several local modes for efficient and parallelized training. To our knowledge, this is the first attempt to use Deep Q-Learning for security games.
Learnable Discrete Wavelet Pooling (LDW-Pooling) For Convolutional Networks
Sep 15, 2021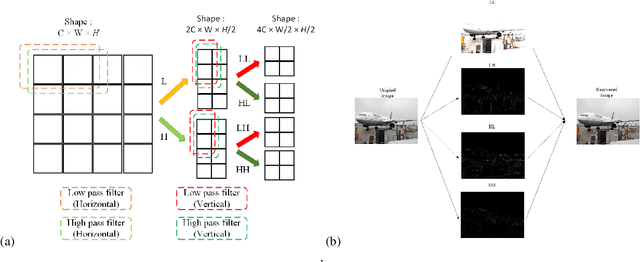

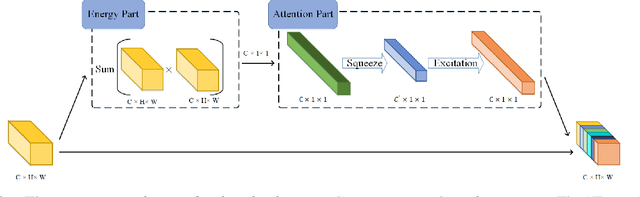
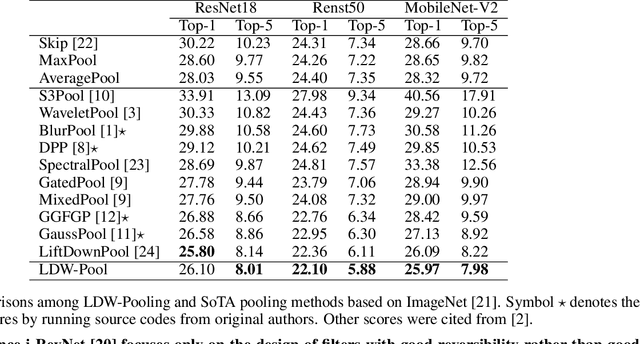
Pooling is a simple but essential layer in modern deep CNN architectures for feature aggregation and extraction. Typical CNN design focuses on the conv layers and activation functions, while leaving the pooling layers with fewer options. We introduce the Learning Discrete Wavelet Pooling (LDW-Pooling) that can be applied universally to replace standard pooling operations to better extract features with improved accuracy and efficiency. Motivated from the wavelet theory, we adopt the low-pass (L) and high-pass (H) filters horizontally and vertically for pooling on a 2D feature map. Feature signals are decomposed into four (LL, LH, HL, HH) subbands to retain features better and avoid information dropping. The wavelet transform ensures features after pooling can be fully preserved and recovered. We next adopt an energy-based attention learning to fine-select crucial and representative features. LDW-Pooling is effective and efficient when compared with other state-of-the-art pooling techniques such as WaveletPooling and LiftPooling. Extensive experimental validation shows that LDW-Pooling can be applied to a wide range of standard CNN architectures and consistently outperform standard (max, mean, mixed, and stochastic) pooling operations.
CADA: Multi-scale Collaborative Adversarial Domain Adaptation for Unsupervised Optic Disc and Cup Segmentation
Oct 05, 2021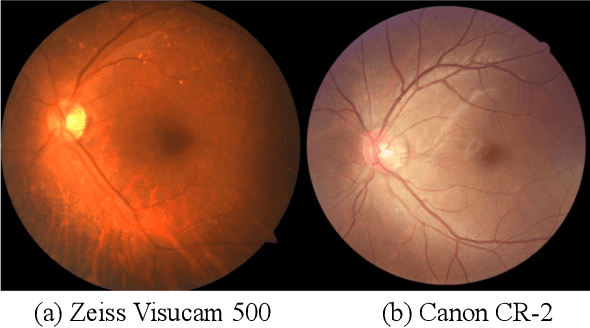

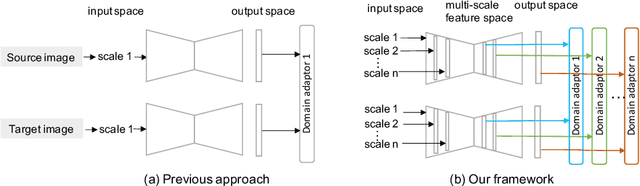
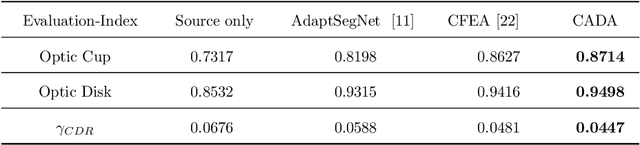
The diversity of retinal imaging devices poses a significant challenge: domain shift, which leads to performance degradation when applying the deep learning models trained on one domain to new testing domains. In this paper, we propose a multi-scale input along with multiple domain adaptors applied hierarchically in both feature and output spaces. The proposed training strategy and novel unsupervised domain adaptation framework, called Collaborative Adversarial Domain Adaptation (CADA), can effectively overcome the challenge. Multi-scale inputs can reduce the information loss due to the pooling layers used in the network for feature extraction, while our proposed CADA is an interactive paradigm that presents an exquisite collaborative adaptation through both adversarial learning and ensembling weights at different network layers. In particular, to produce a better prediction for the unlabeled target domain data, we simultaneously achieve domain invariance and model generalizability via adversarial learning at multi-scale outputs from different levels of network layers and maintaining an exponential moving average (EMA) of the historical weights during training. Without annotating any sample from the target domain, multiple adversarial losses in encoder and decoder layers guide the extraction of domain-invariant features to confuse the domain classifier. Meanwhile, the ensembling of weights via EMA reduces the uncertainty of adapting multiple discriminator learning. Comprehensive experimental results demonstrate that our CADA model incorporating multi-scale input training can overcome performance degradation and outperform state-of-the-art domain adaptation methods in segmenting retinal optic disc and cup from fundus images stemming from the REFUGE, Drishti-GS, and Rim-One-r3 datasets.
Local Augmentation for Graph Neural Networks
Sep 08, 2021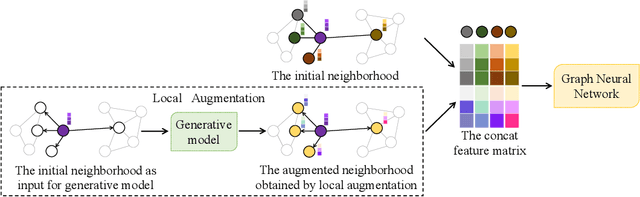
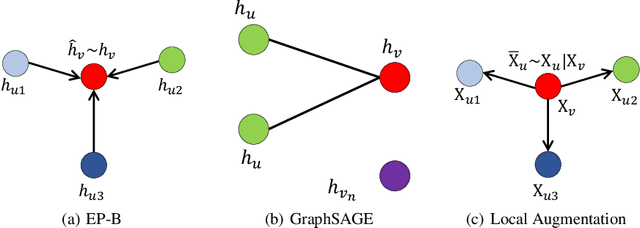

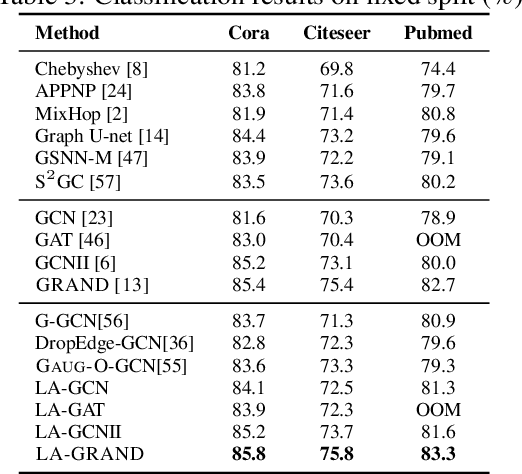
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
Collaborative Variational Bandwidth Auto-encoder for Recommender Systems
May 17, 2021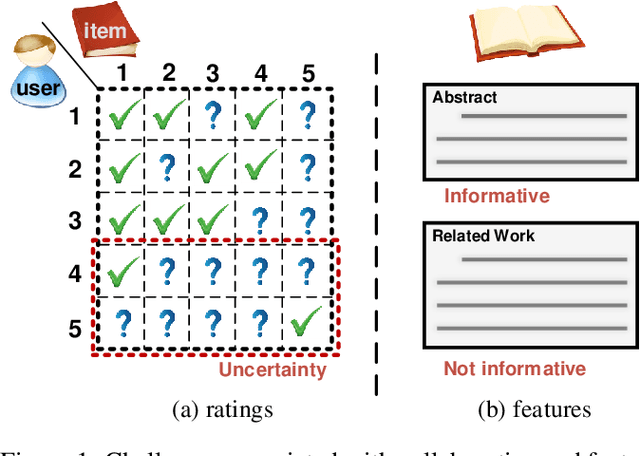
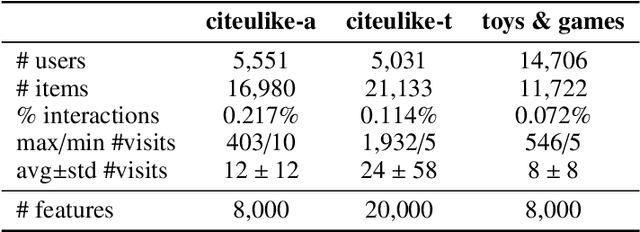
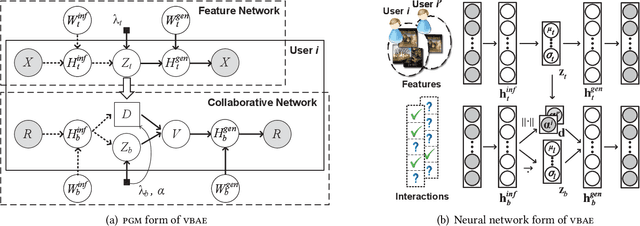
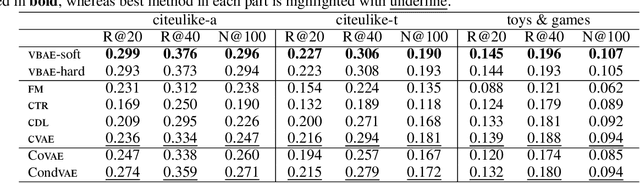
Collaborative filtering has been widely adopted by modern recommender systems to discover user preferences based on their past behaviors. However, the observed interactions for different users are usually unbalanced, which leads to high uncertainty in the collaborative embeddings of users with sparse ratings, thereby severely degenerating the recommendation performance. Consequently, more efforts have been dedicated to the hybrid recommendation strategy where user/item features are utilized as auxiliary information to address the sparsity problem. However, since these features contain rich multimodal patterns and most of them are irrelevant to the recommendation purpose, excessive reliance on these features will make the model difficult to generalize. To address the above two challenges, we propose a VBAE for recommendation. VBAE models both the collaborative and the user feature embeddings as Gaussian random variables inferred via deep neural networks to capture non-linear similarities between users based on their ratings and features. Furthermore, VBAE establishes an information regulation mechanism by introducing a user-dependent channel variable where the bandwidth is determined by the information already contained in the observed ratings to dynamically control the amount of information allowed to be accessed from the corresponding user features. The user-dependent channel variable alleviates the uncertainty problem when the ratings are sparse while avoids unnecessary dependence of the model on noisy user features simultaneously. Codes and datasets are released at https://github.com/yaochenzhu/vbae.
Low-Complexity Algorithm for Outage Optimal Resource Allocation in Energy Harvesting-Based UAV Identification Networks
Aug 21, 2021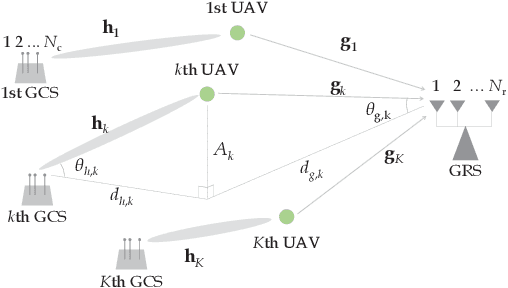
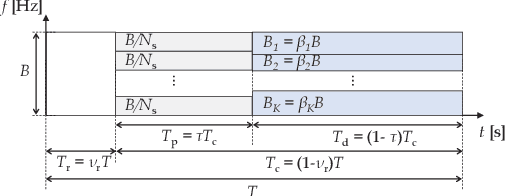
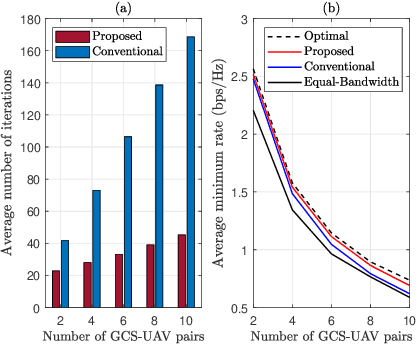
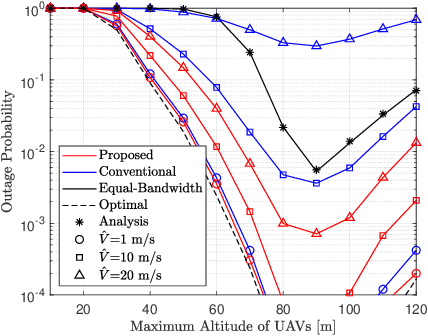
We study an unmanned aerial vehicle (UAV) identification network equipped with an energy harvesting (EH) technique. In the network, the UAVs harvest energy through radio frequency (RF) signals transmitted from ground control stations (GCSs) and then transmit their identification information to the ground receiver station (GRS). Specifically, we first derive a closed-form expression of the outage probability to evaluate the network performance. Then we obtain the closed-form expression of the optimal time allocation when the bandwidth is equally allocated to the UAVs. We also propose a fast-converging algorithm for time and the bandwidth allocation, which is necessary for the UAV environment with high mobility, to optimize the outage performance of EH-based UAV identification network. Simulation results show that the proposed algorithm outperforms the conventional bisection algorithm and achieves near-optimal performance.
WebQA: Multihop and Multimodal QA
Sep 01, 2021
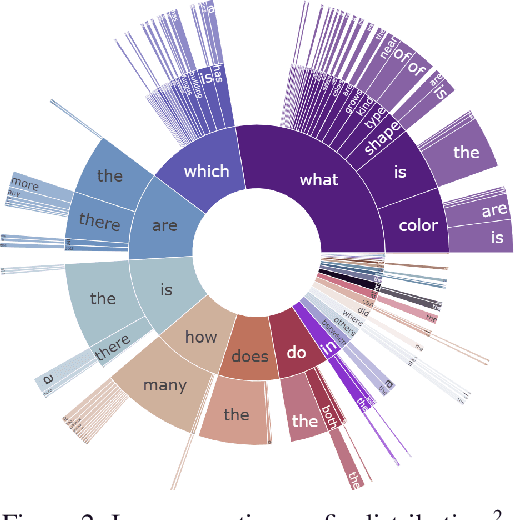


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.