 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling AI-Native Mobility in 6G: A Real-World Dataset for Handover, Beam Management, and Timing Advance
May 12, 2026To address the issues of high interruption time and measurement report overhead under user equipment (UE) mobility especially in high speed 5G use cases the use of AI/ML techniques (AI/ML beam management and mobility procedures) have been proposed. These techniques rely heavily on data that are most often simulated for various scenarios and do not accurately reflect real deployment behavior or user traffic patterns. Therefore, there is an utmost need for realistic datasets under various conditions. This work presents a dataset collected from a commercially deployed network across various modes of mobility (pedestrian, bike, car, bus, and train) and at multiple speeds to depict real time UE mobility. When collecting the dataset, we focused primarily on handover (HO) scenarios, with the aim of reducing the HO interruption time and maintaining continuous throughput during and immediately after HO execution. To support this research, the dataset includes timing advance (TA) measurements at various signaling events such as RACH trigger, MAC CE, and PDCCH grant which are typically missing in existing works. We cover a detailed description of the creation of the dataset; experimental setup, data acquisition, and extraction. We also cover an exploratory analysis of the data, with a primary focus on mobility, beam management, and TA. We discuss multiple use cases in which the proposed dataset can facilitate understanding of the inference of the AI/ML model. One such use case is to train and evaluate various AI/ML models for TA prediction.
Reverse Distillation: Consistently Scaling Protein Language Model Representations
Mar 08, 2026Unlike the predictable scaling laws in natural language processing and computer vision, protein language models (PLMs) scale poorly: for many tasks, models within the same family plateau or even decrease in performance, with mid-sized models often outperforming the largest in the family. We introduce Reverse Distillation, a principled framework that decomposes large PLM representations into orthogonal subspaces guided by smaller models of the same family. The resulting embeddings have a nested, Matryoshka-style structure: the first k dimensions of a larger model's embedding are exactly the representation from the smaller model. This ensures that larger reverse-distilled models consistently outperform smaller ones. A motivating intuition is that smaller models, constrained by capacity, preferentially encode broadly-shared protein features. Reverse distillation isolates these shared features and orthogonally extracts additional contributions from larger models, preventing interference between the two. On ProteinGym benchmarks, reverse-distilled ESM-2 variants outperform their respective baselines at the same embedding dimensionality, with the reverse-distilled 15 billion parameter model achieving the strongest performance. Our framework is generalizable to any model family where scaling challenges persist. Code and trained models are available at https://github.com/rohitsinghlab/plm_reverse_distillation.
Physical Layer Design for Ambient IoT
Jan 16, 2025



There is a growing demand for ultra low power and ultra low complexity devices for applications which require maintenance-free and battery-less operation. One way to serve such applications is through backscatter devices, which communicate using energy harvested from ambient sources such as radio waves transmitted by a reader. Traditional backscatter devices, such as RFID, are limited by range, interference, low connection density, and security issues. To address these problems, the Third Generation Partnership Project (3GPP) has started working on Ambient IoT (A-IoT). For the realization of A-IoT devices, various aspects ranging from physical layer design, to the protocol stack, to the device architecture should be standardized. In this paper, we provide an overview of the standardization efforts on the physical layer design for A-IoT devices. The various physical channels and signals are discussed, followed by link level simulations to compare the performance of various configurations of reader to device and device to reader channels.
A Quick Guide to Quantum Communication
Feb 24, 2024



This article provides a quick overview of quantum communication, bringing together several innovative aspects of quantum enabled transmission. We first take a neutral look at the role of quantum communication, presenting its importance for the forthcoming wireless. Then, we summarise the principles and basic mechanisms involved in quantum communication, including quantum entanglement, quantum superposition, and quantum teleportation. Further, we highlight its groundbreaking features, opportunities, challenges and future prospects.
Enhancements for 5G NR PRACH Reception: An AI/ML Approach
Jan 12, 2024



Random Access is an important step in enabling the initial attachment of a User Equipment (UE) to a Base Station (gNB). The UE identifies itself by embedding a Preamble Index (RAPID) in the phase rotation of a known base sequence, which it transmits on the Physical Random Access Channel (PRACH). The signal on the PRACH also enables the estimation of propagation delay, often known as Timing Advance (TA), which is induced by virtue of the UE's position. Traditional receivers estimate the RAPID and TA using correlation-based techniques. This paper presents an alternative receiver approach that uses AI/ML models, wherein two neural networks are proposed, one for the RAPID and one for the TA. Different from other works, these two models can run in parallel as opposed to sequentially. Experiments with both simulated data and over-the-air hardware captures highlight the improved performance of the proposed AI/ML-based techniques compared to conventional correlation methods.
Indexed Multiple Access with Reconfigurable Intelligent Surfaces: The Reflection Tuning Potential
Feb 15, 2023



Indexed modulation (IM) is an evolving technique that has become popular due to its ability of parallel data communication over distinct combinations of transmission entities. In this article, we first provide a comprehensive survey of IM-enabled multiple access (MA) techniques, emphasizing the shortcomings of existing non-indexed MA schemes. Theoretical comparisons are presented to show how the notion of indexing eliminates the limitations of non-indexed solutions. We also discuss the benefits that the utilization of a reconfigurable intelligent surface (RIS) can offer when deployed as an indexing entity. In particular, we propose an RIS-indexed multiple access (RIMA) transmission scheme that utilizes dynamic phase tuning to embed multi-user information over a single carrier. The performance of the proposed RIMA is assessed in light of simulation results that confirm its performance gains. The article further includes a list of relevant open technical issues and research directions.
Granger causal inference on DAGs identifies genomic loci regulating transcription
Oct 18, 2022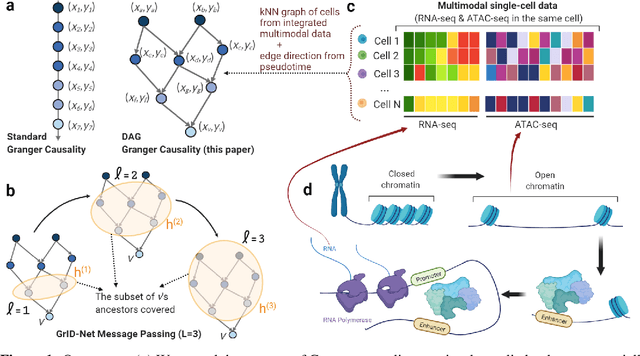
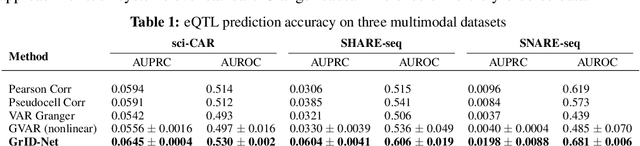
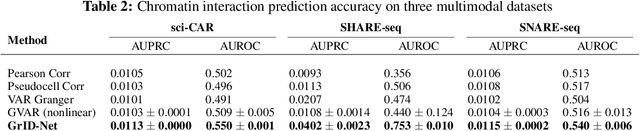
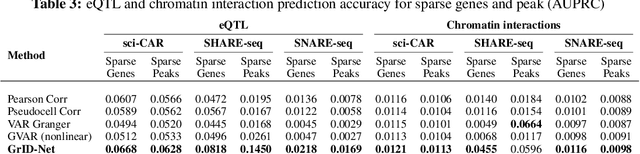
When a dynamical system can be modeled as a sequence of observations, Granger causality is a powerful approach for detecting predictive interactions between its variables. However, traditional Granger causal inference has limited utility in domains where the dynamics need to be represented as directed acyclic graphs (DAGs) rather than as a linear sequence, such as with cell differentiation trajectories. Here, we present GrID-Net, a framework based on graph neural networks with lagged message passing for Granger causal inference on DAG-structured systems. Our motivating application is the analysis of single-cell multimodal data to identify genomic loci that mediate the regulation of specific genes. To our knowledge, GrID-Net is the first single-cell analysis tool that accounts for the temporal lag between a genomic locus becoming accessible and its downstream effect on a target gene's expression. We applied GrID-Net on multimodal single-cell assays that profile chromatin accessibility (ATAC-seq) and gene expression (RNA-seq) in the same cell and show that it dramatically outperforms existing methods for inferring regulatory locus-gene links, achieving up to 71% greater agreement with independent population genetics-based estimates. By extending Granger causality to DAG-structured dynamical systems, our work unlocks new domains for causal analyses and, more specifically, opens a path towards elucidating gene regulatory interactions relevant to cellular differentiation and complex human diseases at unprecedented scale and resolution.
Ultra-dense Low Data Rate Communication in the THz
Sep 22, 2020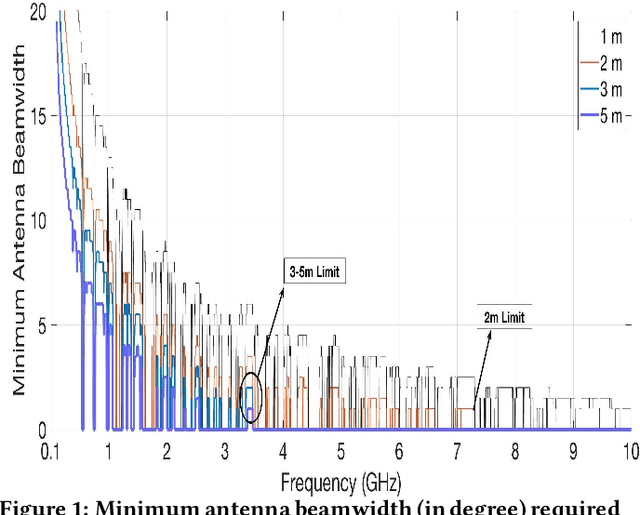
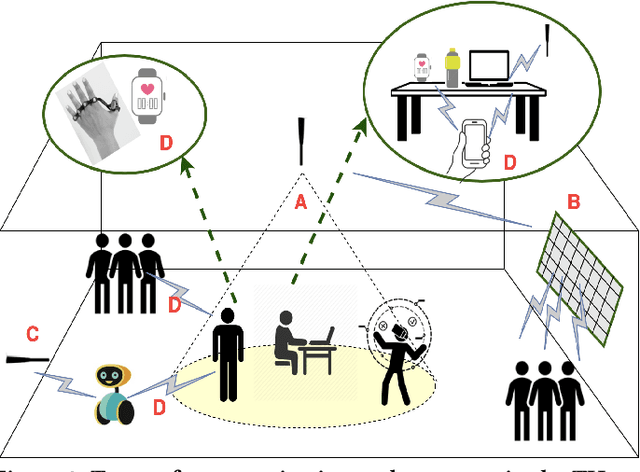
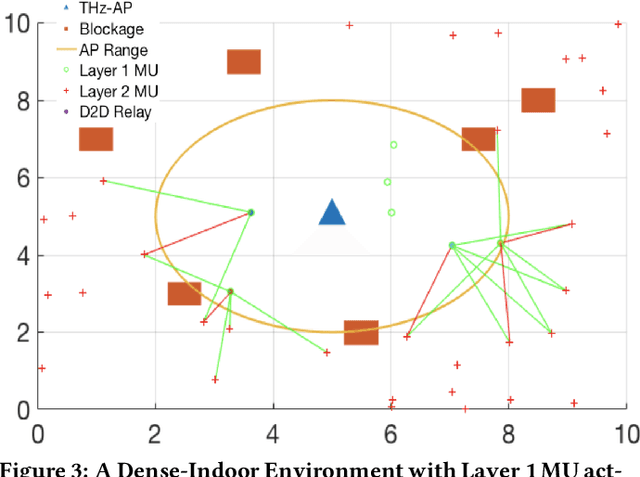
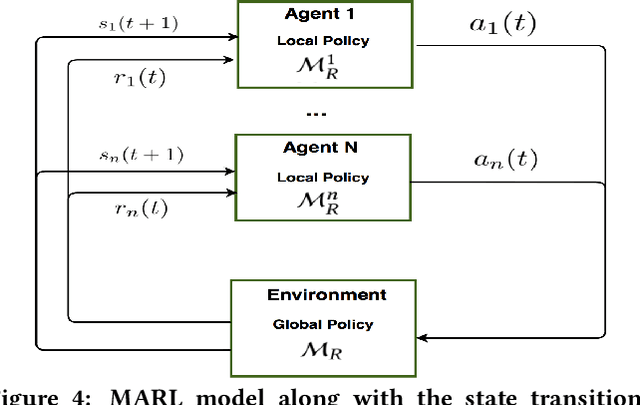
In the future, with the advent of Internet of Things (IoT), wireless sensors, and multiple 5G killer applications, an indoor room might be filled with $1000$s of devices demanding low data rates. Such high-level densification and mobility of these devices will overwhelm the system and result in higher interference, frequent outages, and lower coverage. The THz band has a massive amount of greenfield spectrum to cater to this dense-indoor deployment. However, a limited coverage range of the THz will require networks to have more infrastructure and depend on non-line-of-sight (NLOS) type communication. This form of communication might not be profitable for network operators and can even result in inefficient resource utilization for devices demanding low data rates. Using distributed device-to-device (D2D) communication in the THz, we can cater to these Ultra-dense Low Data Rate (UDLD) type applications. D2D in THz can be challenging, but with opportunistic allocation and smart learning algorithms, these challenges can be mitigated. We propose a 2-Layered distributed D2D model, where devices use coordinated multi-agent reinforcement learning (MARL) to maximize efficiency and user coverage for dense-indoor deployment. We show that densification and mobility in a network can be used to further the limited coverage range of THz devices, without the need for extra infrastructure or resources.
MOTH- Mobility-induced Outages in THz: A Beyond 5G application
Nov 19, 2019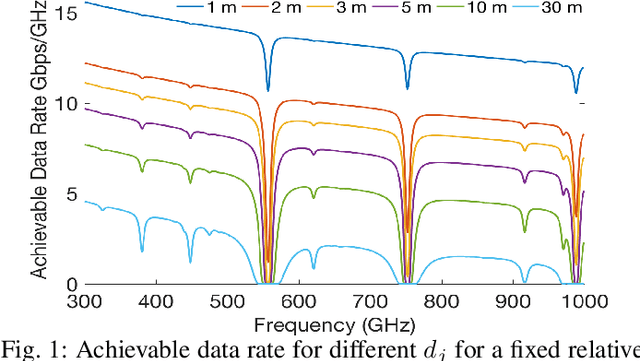
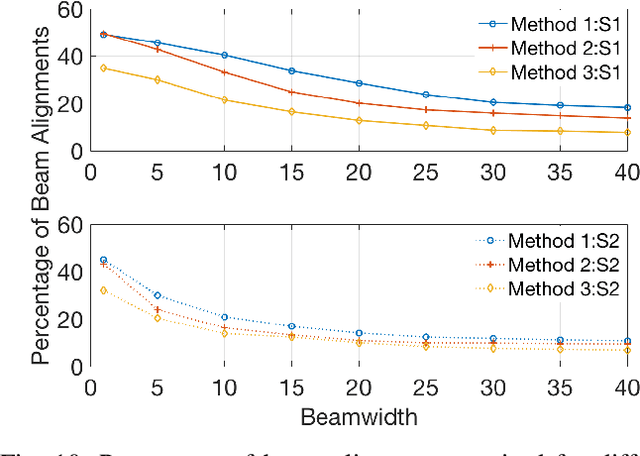
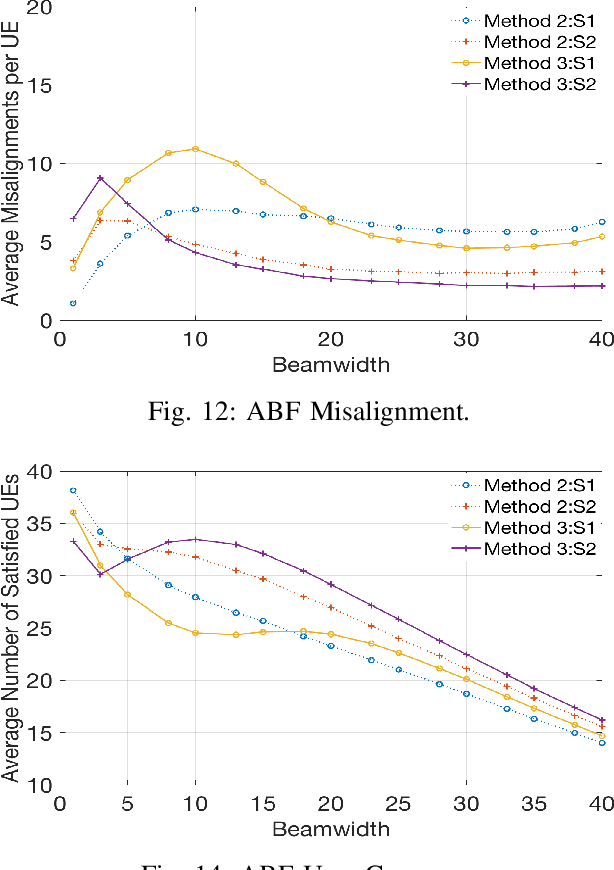
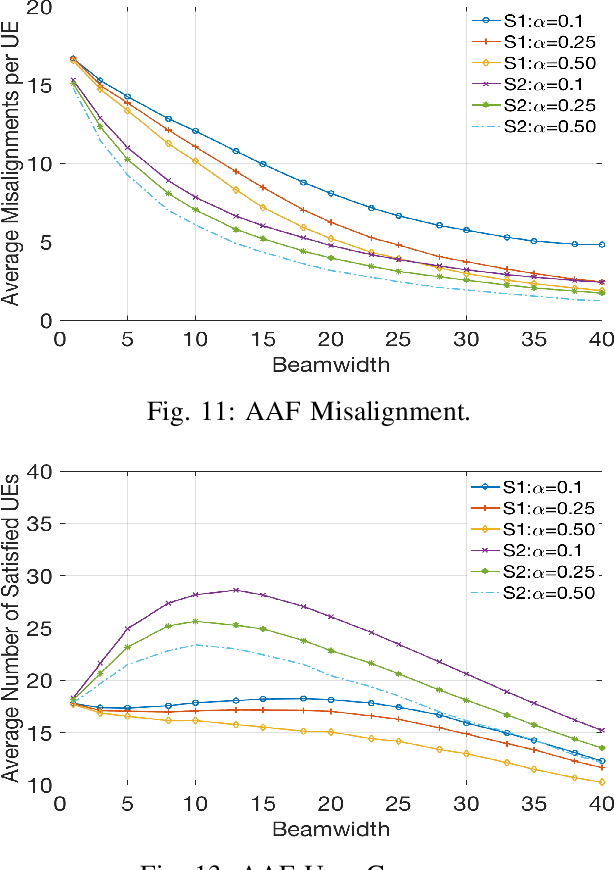
5G will enable the growing demand for Internet of Things (IoT), high-resolution video streaming, and low latency wireless services. Demand for such services is expected to growth rapid, which will require a search for Beyond 5G technological advancements in wireless communications. Part of these advancements is the need for additional spectrum, namely moving toward the terahertz (THz) range. To compensate for the high path loss in THz, narrow beamwidths are used to improve antenna gains. However, with narrow beamwidths, even minor fluctuations in device location (such as through body movement) can cause frequent link failures due to beam misalignment. In this paper, we provide a solution to these small-scale indoor movement that result in mobility-induced outages. Like a moth randomly flutters about, Mobility-induced Outages in THz (MOTH) can be ephemeral in nature and hard to avoid. To deal with MOTH we propose two methods to predict these outage scenarios: (i) Align-After-Failure (AAF), which predicts based on fixed time margins, and (ii) Align-Before-Failure (ABF), which learns the time margins through user mobility patterns. In this paper, two different online classifiers were used to train the ABF model to predicate if a mobility-induced outage is going to occur; thereby, significantly reducing the time spent in outage scenarios. Simulation results demonstrate a relationship between optimal beamwidth and human mobility patterns. Additionally, to cater to a future with dense deployment of Wireless Personal Area Network (WPAN), it is necessary that we have efficient deployment of resources (e.g., THz-APs). One solution is to maximize the user coverage for a single AP, which might be dependent on multiple parameters. We identify these parameters and observe their tradeoffs for improving user coverage through a single THz-AP.
Stay Ahead of Poachers: Illegal Wildlife Poaching Prediction and Patrol Planning Under Uncertainty with Field Test Evaluations
Mar 08, 2019
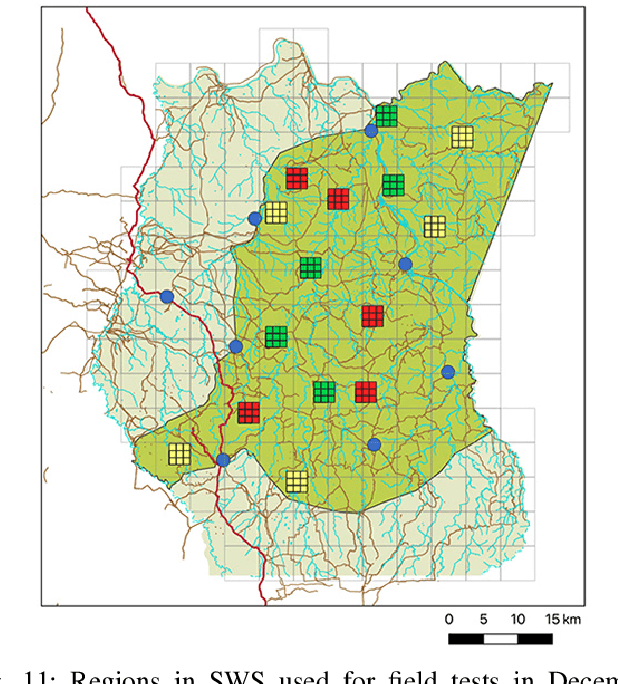

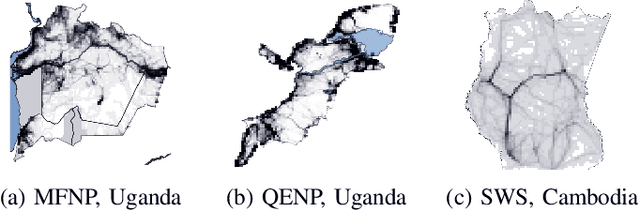
Illegal wildlife poaching threatens ecosystems and drives endangered species toward extinction. However, efforts for wildlife monitoring and protection in conservation areas are constrained by the limited resources of law enforcement agencies. To aid in wildlife protection, PAWS is an ML pipeline that has been developed as an end-to-end, data-driven approach to combat illegal poaching. PAWS assists park managers by identifying areas at high risk of poaching throughout protected areas based on real-world data and generating optimal patrol routes for deployment in the field. In this paper, we address significant challenges including extreme class imbalance (up to 1:200), bias, and uncertainty in wildlife poaching data to enhance PAWS and apply its methodology to several national parks with diverse characteristics. (i) We use Gaussian processes to quantify predictive uncertainty, which we exploit to increase the robustness of our prescribed patrols. We evaluate our approach on real-world historic poaching data from Murchison Falls and Queen Elizabeth National Parks in Uganda and, for the first time, Srepok Wildlife Sanctuary in Cambodia. (ii) We present the results of large-scale field tests conducted in Murchison Falls and Srepok Wildlife Sanctuary which confirm that the predictive power of PAWS extends promisingly to multiple parks. This paper is part of an effort to expand PAWS to 600 parks around the world through integration with SMART conservation software.