 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Benign Overfitting (ABO): Overparameterized RLS for Online Learning in Non-stationary Time-series
Jan 29, 2026Overparameterized models have recently challenged conventional learning theory by exhibiting improved generalization beyond the interpolation limit, a phenomenon known as benign overfitting. This work introduces Adaptive Benign Overfitting (ABO), extending the recursive least-squares (RLS) framework to this regime through a numerically stable formulation based on orthogonal-triangular updates. A QR-based exponentially weighted RLS (QR-EWRLS) algorithm is introduced, combining random Fourier feature mappings with forgetting-factor regularization to enable online adaptation under non-stationary conditions. The orthogonal decomposition prevents the numerical divergence associated with covariance-form RLS while retaining adaptability to evolving data distributions. Experiments on nonlinear synthetic time series confirm that the proposed approach maintains bounded residuals and stable condition numbers while reproducing the double-descent behavior characteristic of overparameterized models. Applications to forecasting foreign exchange and electricity demand show that ABO is highly accurate (comparable to baseline kernel methods) while achieving speed improvements of between 20 and 40 percent. The results provide a unified view linking adaptive filtering, kernel approximation, and benign overfitting within a stable online learning framework.
When AI Trading Agents Compete: Adverse Selection of Meta-Orders by Reinforcement Learning-Based Market Making
Oct 31, 2025We investigate the mechanisms by which medium-frequency trading agents are adversely selected by opportunistic high-frequency traders. We use reinforcement learning (RL) within a Hawkes Limit Order Book (LOB) model in order to replicate the behaviours of high-frequency market makers. In contrast to the classical models with exogenous price impact assumptions, the Hawkes model accounts for endogenous price impact and other key properties of the market (Jain et al. 2024a). Given the real-world impracticalities of the market maker updating strategies for every event in the LOB, we formulate the high-frequency market making agent via an impulse control reinforcement learning framework (Jain et al. 2025). The RL used in the simulation utilises Proximal Policy Optimisation (PPO) and self-imitation learning. To replicate the adverse selection phenomenon, we test the RL agent trading against a medium frequency trader (MFT) executing a meta-order and demonstrate that, with training against the MFT meta-order execution agent, the RL market making agent learns to capitalise on the price drift induced by the meta-order. Recent empirical studies have shown that medium-frequency traders are increasingly subject to adverse selection by high-frequency trading agents. As high-frequency trading continues to proliferate across financial markets, the slippage costs incurred by medium-frequency traders are likely to increase over time. However, we do not observe that increased profits for the market making RL agent necessarily cause significantly increased slippages for the MFT agent.
Sequential Asset Ranking within Nonstationary Time Series
Feb 24, 2022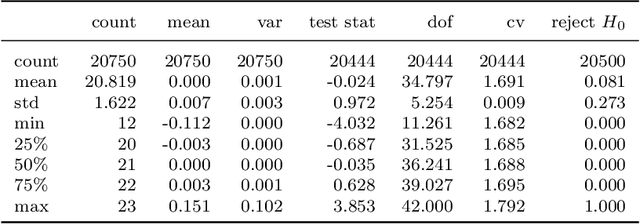
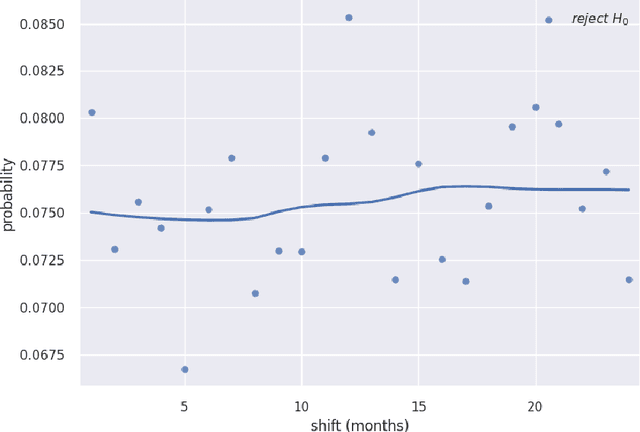
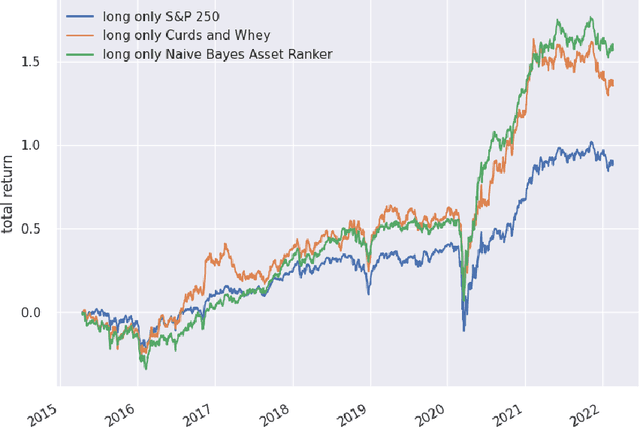
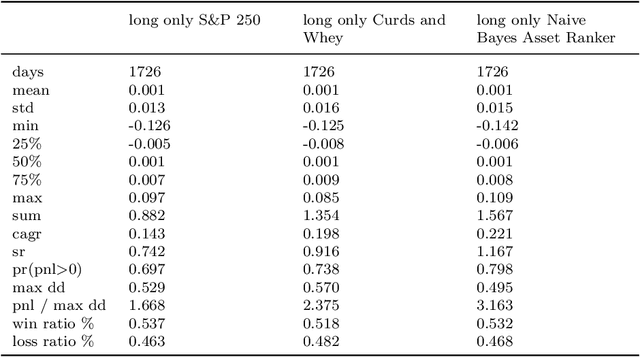
Financial time series are both autocorrelated and nonstationary, presenting modelling challenges that violate the independent and identically distributed random variables assumption of most regression and classification models. The prediction with expert advice framework makes no assumptions on the data-generating mechanism yet generates predictions that work well for all sequences, with performance nearly as good as the best expert with hindsight. We conduct research using S&P 250 daily sampled data, extending the academic research into cross-sectional momentum trading strategies. We introduce a novel ranking algorithm from the prediction with expert advice framework, the naive Bayes asset ranker, to select subsets of assets to hold in either long-only or long/short portfolios. Our algorithm generates the best total returns and risk-adjusted returns, net of transaction costs, outperforming the long-only holding of the S&P 250 with hindsight. Furthermore, our ranking algorithm outperforms a proxy for the regress-then-rank cross-sectional momentum trader, a sequentially fitted curds and whey multivariate regression procedure.
The Recurrent Reinforcement Learning Crypto Agent
Jan 29, 2022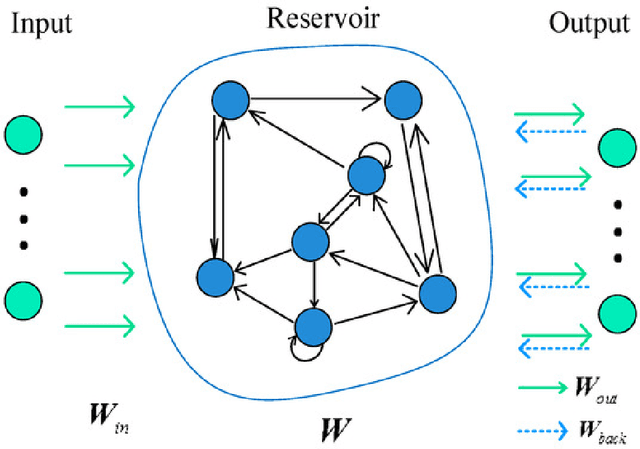
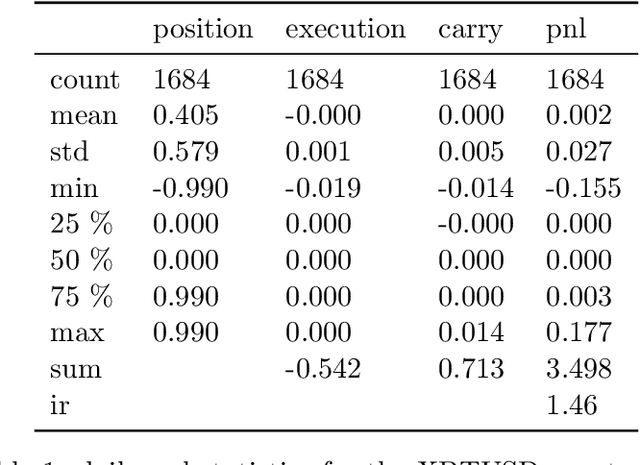
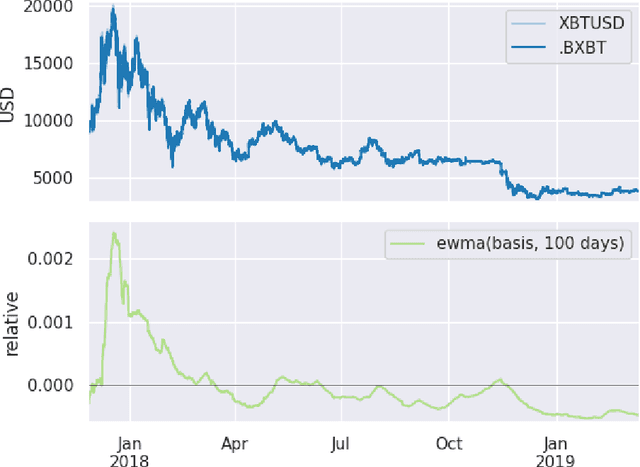
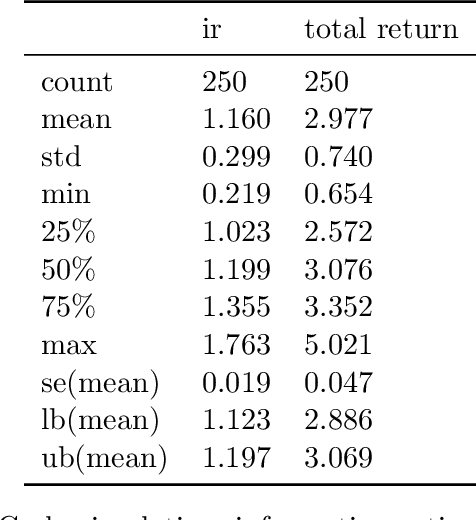
We demonstrate a novel application of online transfer learning for a digital assets trading agent. This agent makes use of a powerful feature space representation in the form of an echo state network, the output of which is made available to a direct, recurrent reinforcement learning agent. The agent learns to trade the XBTUSD (Bitcoin versus US Dollars) perpetual swap derivatives contract on BitMEX on an intraday basis. By learning from the multiple sources of impact on the quadratic risk-adjusted utility that it seeks to maximise, the agent avoids excessive over-trading, captures a funding profit, and can predict the market's direction. Overall, our crypto agent realises a total return of 350%, net of transaction costs, over roughly five years, 71% of which is down to funding profit. The annualised information ratio that it achieves is 1.46.
Reinforcement Learning for Systematic FX Trading
Oct 27, 2021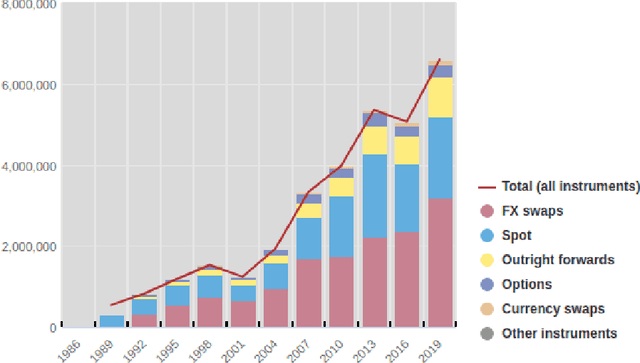
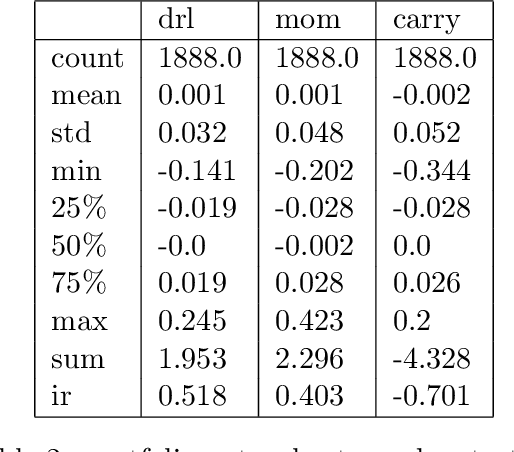
We explore online, inductive transfer learning, with a feature representation transfer from a radial basis function network, which is formed of Gaussian mixture model hidden processing units, whose output is made available to a direct, recurrent reinforcement learning agent. This recurrent reinforcement learning agent learns a desired position, via the policy gradient reinforcement learning paradigm. This transfer learner is put to work trading the major spot market currency pairs. In our experiment, we accurately account for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to the recurrent reinforcement learner via a quadratic utility, who learns to target a position directly. We improve upon earlier work by casting the problem of learning to target a risk position, in an online transfer learning context. Our agent achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3\%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive.
Online Learning with Radial Basis Function Networks
Mar 15, 2021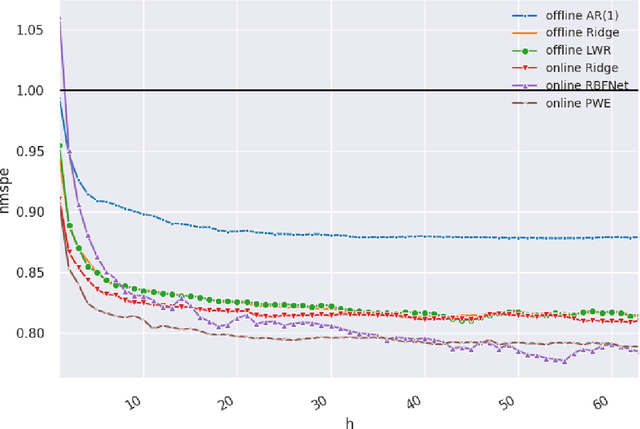
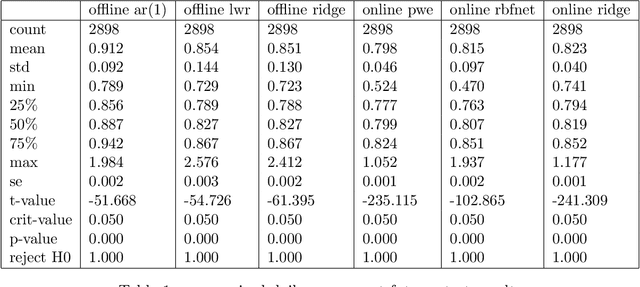
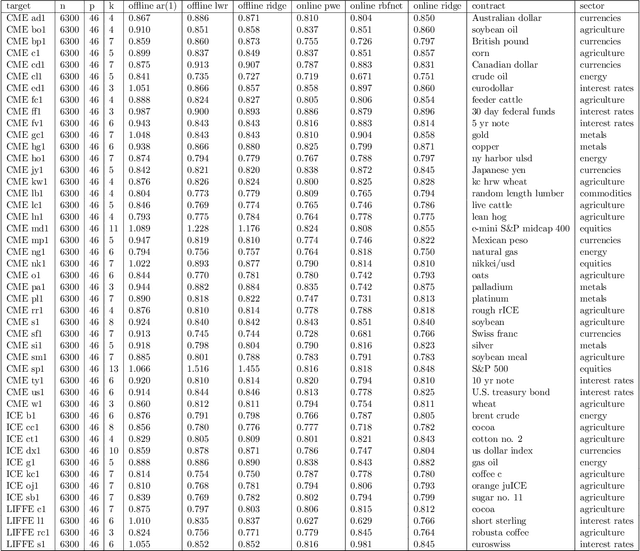
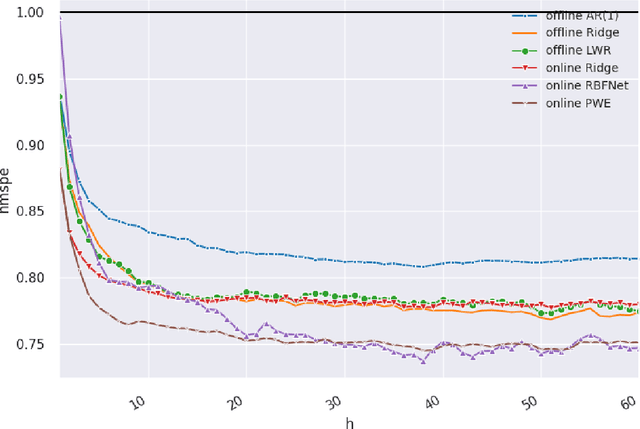
We investigate the benefits of feature selection, nonlinear modelling and online learning with forecasting in financial time series. We consider the sequential and continual learning sub-genres of online learning. Through empirical experimentation, which involves long term forecasting in daily sampled cross-asset futures, and short term forecasting in minutely sampled cash currency pairs, we find that the online learning techniques outperform the offline learning ones. We also find that, in the subset of models we use, sequential learning in time with online Ridge regression, provides the best next step ahead forecasts, and continual learning with an online radial basis function network, provides the best multi-step ahead forecasts. We combine the benefits of both in a precision weighted ensemble of the forecast errors and find superior forecast performance overall.
QuantNet: Transferring Learning Across Systematic Trading Strategies
Apr 07, 2020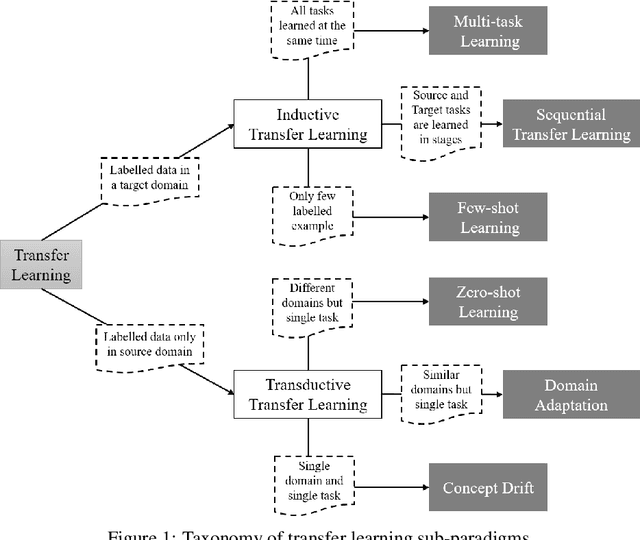

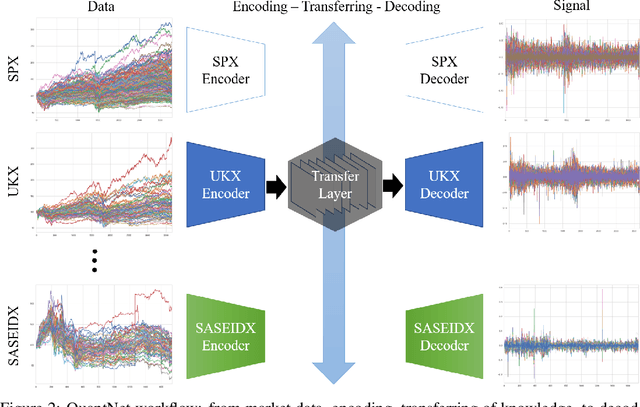
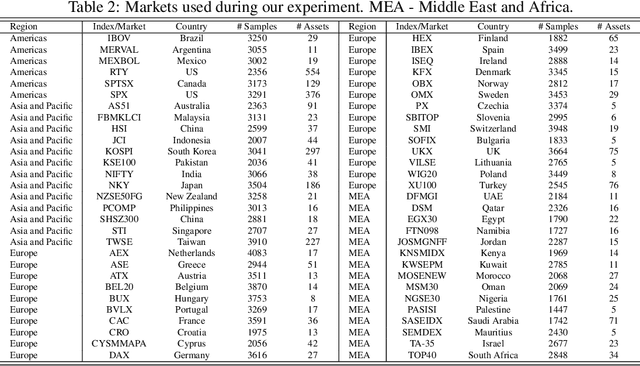
In this work we introduce QuantNet: an architecture that is capable of transferring knowledge over systematic trading strategies in several financial markets. By having a system that is able to leverage and share knowledge across them, our aim is two-fold: to circumvent the so-called Backtest Overfitting problem; and to generate higher risk-adjusted returns and fewer drawdowns. To do that, QuantNet exploits a form of modelling called Transfer Learning, where two layers are market-specific and another one is market-agnostic. This ensures that the transfer occurs across trading strategies, with the market-agnostic layer acting as a vehicle to share knowledge, cross-influence each strategy parameters, and ultimately the trading signal produced. In order to evaluate QuantNet, we compared its performance in relation to the option of not performing transfer learning, that is, using market-specific old-fashioned machine learning. In summary, our findings suggest that QuantNet performs better than non transfer-based trading strategies, improving Sharpe ratio in 15% and Calmar ratio in 41% across 3103 assets in 58 equity markets across the world. Code coming soon.
Generative Adversarial Networks for Financial Trading Strategies Fine-Tuning and Combination
Jan 07, 2019
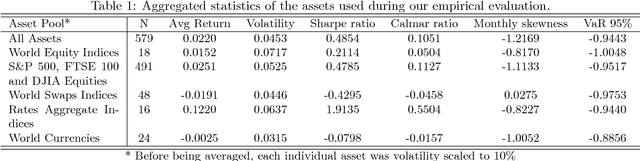
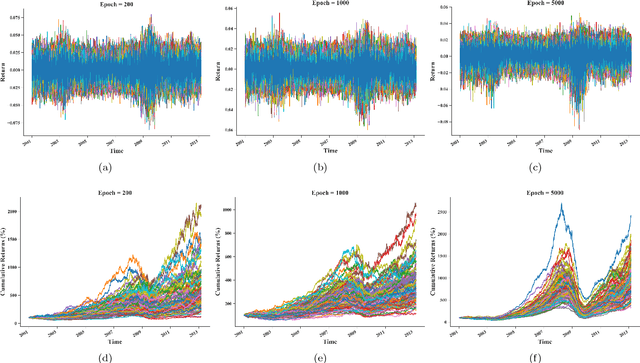
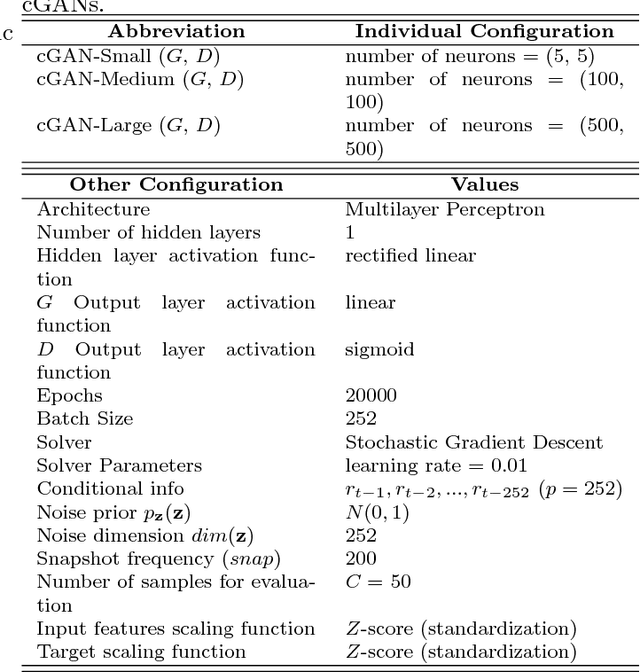
Systematic trading strategies are algorithmic procedures that allocate assets aiming to optimize a certain performance criterion. To obtain an edge in a highly competitive environment, the analyst needs to proper fine-tune its strategy, or discover how to combine weak signals in novel alpha creating manners. Both aspects, namely fine-tuning and combination, have been extensively researched using several methods, but emerging techniques such as Generative Adversarial Networks can have an impact into such aspects. Therefore, our work proposes the use of Conditional Generative Adversarial Networks (cGANs) for trading strategies calibration and aggregation. To this purpose, we provide a full methodology on: (i) the training and selection of a cGAN for time series data; (ii) how each sample is used for strategies calibration; and (iii) how all generated samples can be used for ensemble modelling. To provide evidence that our approach is well grounded, we have designed an experiment with multiple trading strategies, encompassing 579 assets. We compared cGAN with an ensemble scheme and model validation methods, both suited for time series. Our results suggest that cGANs are a suitable alternative for strategies calibration and combination, providing outperformance when the traditional techniques fail to generate any alpha.