 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Explainable Recommendation with Large Language Models
Jan 31, 2024



Providing explanations within the recommendation system would boost user satisfaction and foster trust, especially by elaborating on the reasons for selecting recommended items tailored to the user. The predominant approach in this domain revolves around generating text-based explanations, with a notable emphasis on applying large language models (LLMs). However, refining LLMs for explainable recommendations proves impractical due to time constraints and computing resource limitations. As an alternative, the current approach involves training the prompt rather than the LLM. In this study, we developed a model that utilizes the ID vectors of user and item inputs as prompts for GPT-2. We employed a joint training mechanism within a multi-task learning framework to optimize both the recommendation task and explanation task. This strategy enables a more effective exploration of users' interests, improving recommendation effectiveness and user satisfaction. Through the experiments, our method achieving 1.59 DIV, 0.57 USR and 0.41 FCR on the Yelp, TripAdvisor and Amazon dataset respectively, demonstrates superior performance over four SOTA methods in terms of explainability evaluation metric. In addition, we identified that the proposed model is able to ensure stable textual quality on the three public datasets.
Stochastic Planner-Actor-Critic for Unsupervised Deformable Image Registration
Dec 14, 2021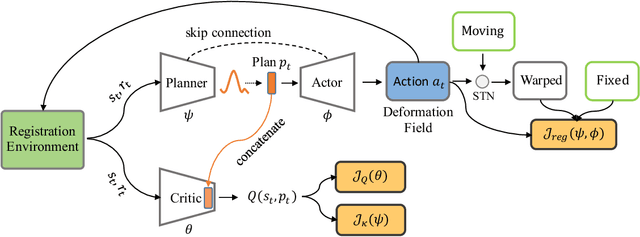
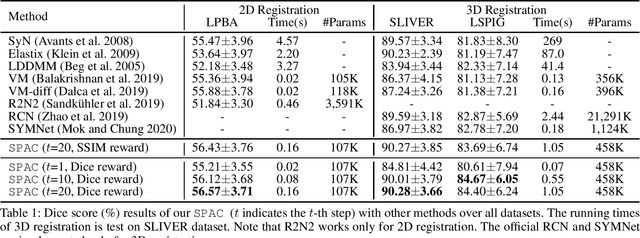
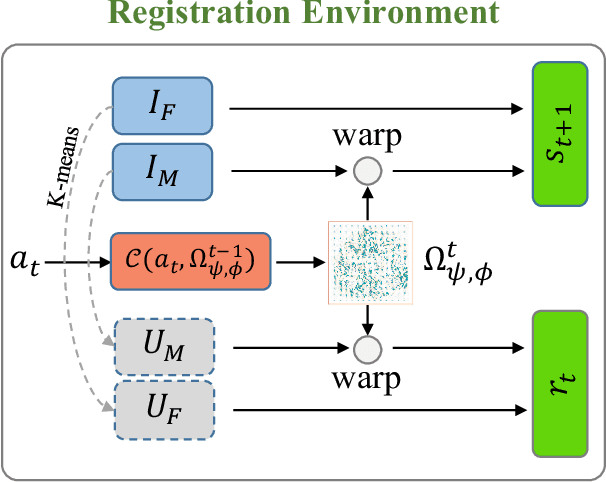
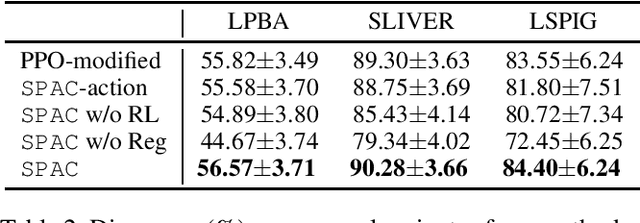
Large deformations of organs, caused by diverse shapes and nonlinear shape changes, pose a significant challenge for medical image registration. Traditional registration methods need to iteratively optimize an objective function via a specific deformation model along with meticulous parameter tuning, but which have limited capabilities in registering images with large deformations. While deep learning-based methods can learn the complex mapping from input images to their respective deformation field, it is regression-based and is prone to be stuck at local minima, particularly when large deformations are involved. To this end, we present Stochastic Planner-Actor-Critic (SPAC), a novel reinforcement learning-based framework that performs step-wise registration. The key notion is warping a moving image successively by each time step to finally align to a fixed image. Considering that it is challenging to handle high dimensional continuous action and state spaces in the conventional reinforcement learning (RL) framework, we introduce a new concept `Plan' to the standard Actor-Critic model, which is of low dimension and can facilitate the actor to generate a tractable high dimensional action. The entire framework is based on unsupervised training and operates in an end-to-end manner. We evaluate our method on several 2D and 3D medical image datasets, some of which contain large deformations. Our empirical results highlight that our work achieves consistent, significant gains and outperforms state-of-the-art methods.
Stochastic Actor-Executor-Critic for Image-to-Image Translation
Dec 14, 2021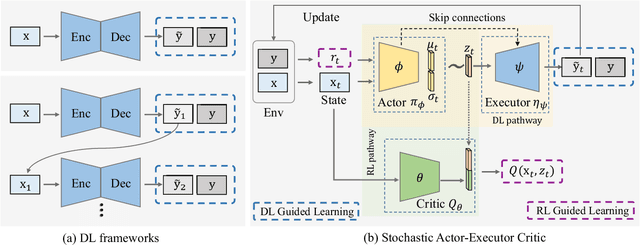
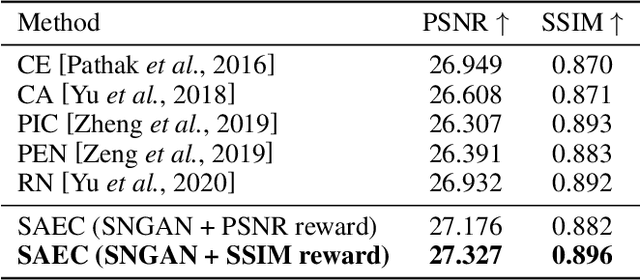


Training a model-free deep reinforcement learning model to solve image-to-image translation is difficult since it involves high-dimensional continuous state and action spaces. In this paper, we draw inspiration from the recent success of the maximum entropy reinforcement learning framework designed for challenging continuous control problems to develop stochastic policies over high dimensional continuous spaces including image representation, generation, and control simultaneously. Central to this method is the Stochastic Actor-Executor-Critic (SAEC) which is an off-policy actor-critic model with an additional executor to generate realistic images. Specifically, the actor focuses on the high-level representation and control policy by a stochastic latent action, as well as explicitly directs the executor to generate low-level actions to manipulate the state. Experiments on several image-to-image translation tasks have demonstrated the effectiveness and robustness of the proposed SAEC when facing high-dimensional continuous space problems.
CADA: Multi-scale Collaborative Adversarial Domain Adaptation for Unsupervised Optic Disc and Cup Segmentation
Oct 05, 2021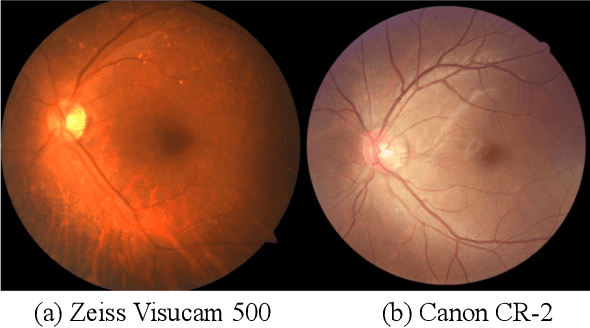

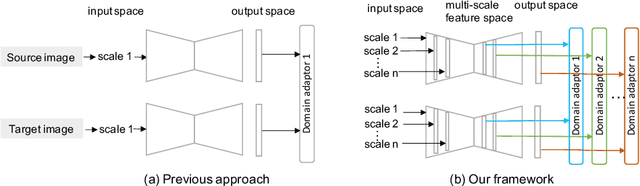
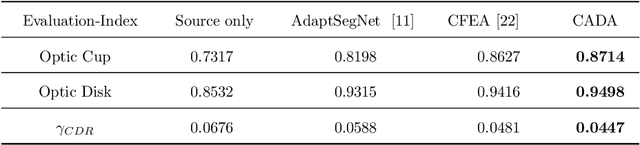
The diversity of retinal imaging devices poses a significant challenge: domain shift, which leads to performance degradation when applying the deep learning models trained on one domain to new testing domains. In this paper, we propose a multi-scale input along with multiple domain adaptors applied hierarchically in both feature and output spaces. The proposed training strategy and novel unsupervised domain adaptation framework, called Collaborative Adversarial Domain Adaptation (CADA), can effectively overcome the challenge. Multi-scale inputs can reduce the information loss due to the pooling layers used in the network for feature extraction, while our proposed CADA is an interactive paradigm that presents an exquisite collaborative adaptation through both adversarial learning and ensembling weights at different network layers. In particular, to produce a better prediction for the unlabeled target domain data, we simultaneously achieve domain invariance and model generalizability via adversarial learning at multi-scale outputs from different levels of network layers and maintaining an exponential moving average (EMA) of the historical weights during training. Without annotating any sample from the target domain, multiple adversarial losses in encoder and decoder layers guide the extraction of domain-invariant features to confuse the domain classifier. Meanwhile, the ensembling of weights via EMA reduces the uncertainty of adapting multiple discriminator learning. Comprehensive experimental results demonstrate that our CADA model incorporating multi-scale input training can overcome performance degradation and outperform state-of-the-art domain adaptation methods in segmenting retinal optic disc and cup from fundus images stemming from the REFUGE, Drishti-GS, and Rim-One-r3 datasets.
Transferable Adversarial Examples for Anchor Free Object Detection
Jun 04, 2021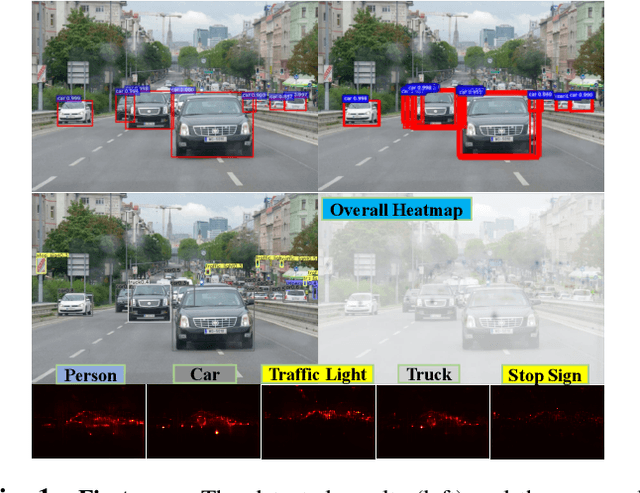
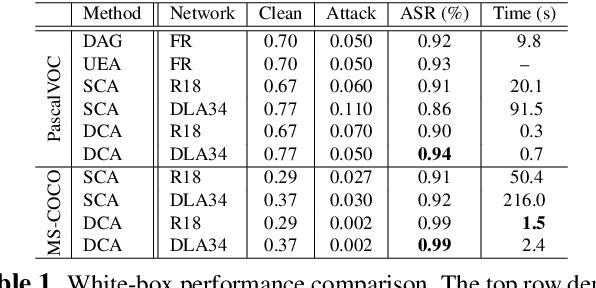
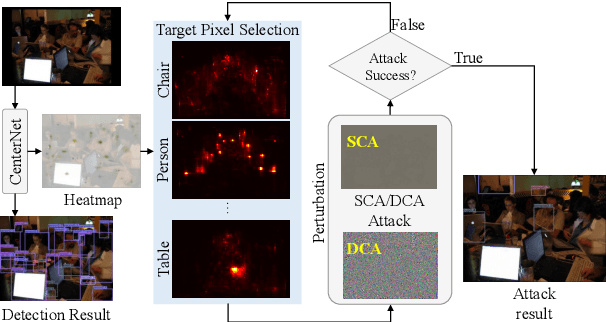
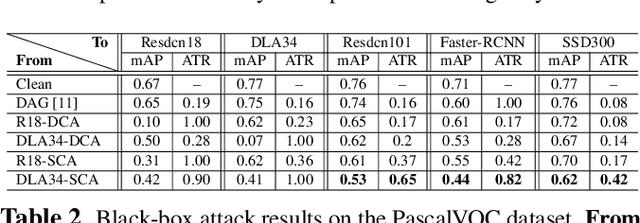
Deep neural networks have been demonstrated to be vulnerable to adversarial attacks: subtle perturbation can completely change prediction result. The vulnerability has led to a surge of research in this direction, including adversarial attacks on object detection networks. However, previous studies are dedicated to attacking anchor-based object detectors. In this paper, we present the first adversarial attack on anchor-free object detectors. It conducts category-wise, instead of previously instance-wise, attacks on object detectors, and leverages high-level semantic information to efficiently generate transferable adversarial examples, which can also be transferred to attack other object detectors, even anchor-based detectors such as Faster R-CNN. Experimental results on two benchmark datasets demonstrate that our proposed method achieves state-of-the-art performance and transferability.
Imperceptible Adversarial Examples for Fake Image Detection
Jun 03, 2021
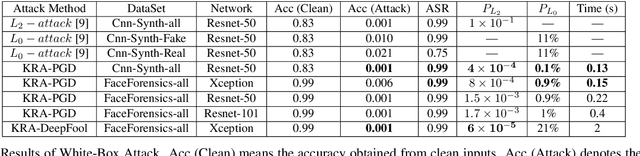

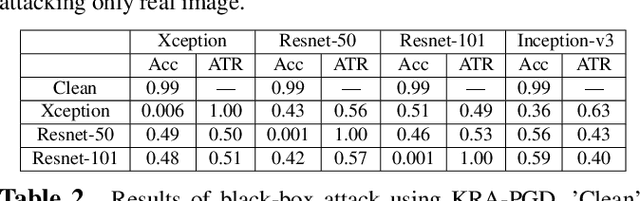
Fooling people with highly realistic fake images generated with Deepfake or GANs brings a great social disturbance to our society. Many methods have been proposed to detect fake images, but they are vulnerable to adversarial perturbations -- intentionally designed noises that can lead to the wrong prediction. Existing methods of attacking fake image detectors usually generate adversarial perturbations to perturb almost the entire image. This is redundant and increases the perceptibility of perturbations. In this paper, we propose a novel method to disrupt the fake image detection by determining key pixels to a fake image detector and attacking only the key pixels, which results in the $L_0$ and the $L_2$ norms of adversarial perturbations much less than those of existing works. Experiments on two public datasets with three fake image detectors indicate that our proposed method achieves state-of-the-art performance in both white-box and black-box attacks.
Fast Local Attack: Generating Local Adversarial Examples for Object Detectors
Oct 27, 2020

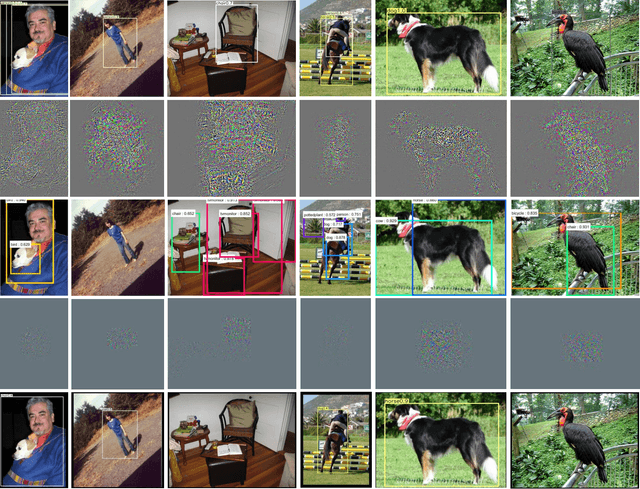

The deep neural network is vulnerable to adversarial examples. Adding imperceptible adversarial perturbations to images is enough to make them fail. Most existing research focuses on attacking image classifiers or anchor-based object detectors, but they generate globally perturbation on the whole image, which is unnecessary. In our work, we leverage higher-level semantic information to generate high aggressive local perturbations for anchor-free object detectors. As a result, it is less computationally intensive and achieves a higher black-box attack as well as transferring attack performance. The adversarial examples generated by our method are not only capable of attacking anchor-free object detectors, but also able to be transferred to attack anchor-based object detector.
Graph Neural Networks for UnsupervisedDomain Adaptation of Histopathological ImageAnalytics
Aug 21, 2020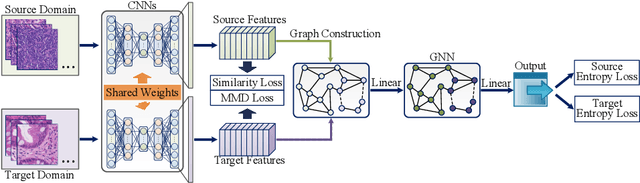

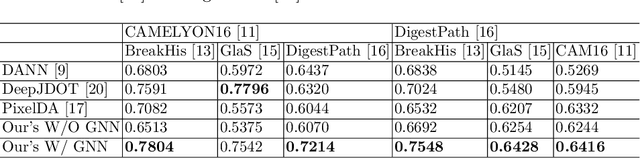
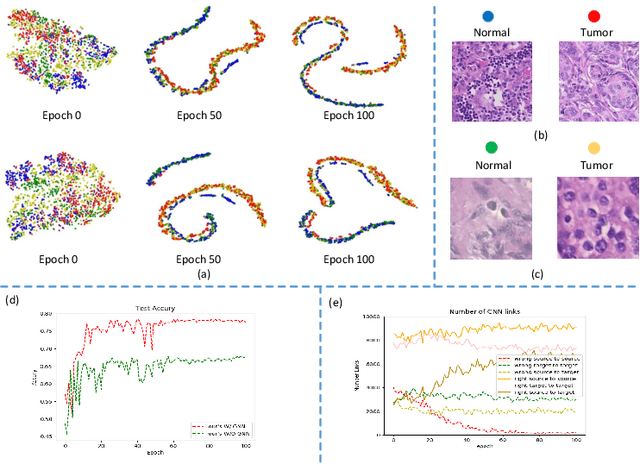
Annotating histopathological images is a time-consuming andlabor-intensive process, which requires broad-certificated pathologistscarefully examining large-scale whole-slide images from cells to tissues.Recent frontiers of transfer learning techniques have been widely investi-gated for image understanding tasks with limited annotations. However,when applied for the analytics of histology images, few of them can effec-tively avoid the performance degradation caused by the domain discrep-ancy between the source training dataset and the target dataset, suchas different tissues, staining appearances, and imaging devices. To thisend, we present a novel method for the unsupervised domain adaptationin histopathological image analysis, based on a backbone for embeddinginput images into a feature space, and a graph neural layer for propa-gating the supervision signals of images with labels. The graph model isset up by connecting every image with its close neighbors in the embed-ded feature space. Then graph neural network is employed to synthesizenew feature representation from every image. During the training stage,target samples with confident inferences are dynamically allocated withpseudo labels. The cross-entropy loss function is used to constrain thepredictions of source samples with manually marked labels and targetsamples with pseudo labels. Furthermore, the maximum mean diversityis adopted to facilitate the extraction of domain-invariant feature repre-sentations, and contrastive learning is exploited to enhance the categorydiscrimination of learned features. In experiments of the unsupervised do-main adaptation for histopathological image classification, our methodachieves state-of-the-art performance on four public datasets
Category-wise Attack: Transferable Adversarial Examples for Anchor Free Object Detection
Feb 10, 2020Deep neural networks have been demonstrated to be vulnerable to adversarial attacks: sutle perturbations can completely change the classification results. Their vulnerability has led to a surge of research in this direction. However, most works dedicated to attacking anchor-based object detection models. In this work, we aim to present an effective and efficient algorithm to generate adversarial examples to attack anchor-free object models based on two approaches. First, we conduct category-wise instead of instance-wise attacks on the object detectors. Second, we leverage the high-level semantic information to generate the adversarial examples. Surprisingly, the generated adversarial examples it not only able to effectively attack the targeted anchor-free object detector but also to be transferred to attack other object detectors, even anchor-based detectors such as Faster R-CNN.
Domain Embedded Multi-model Generative Adversarial Networks for Image-based Face Inpainting
Feb 05, 2020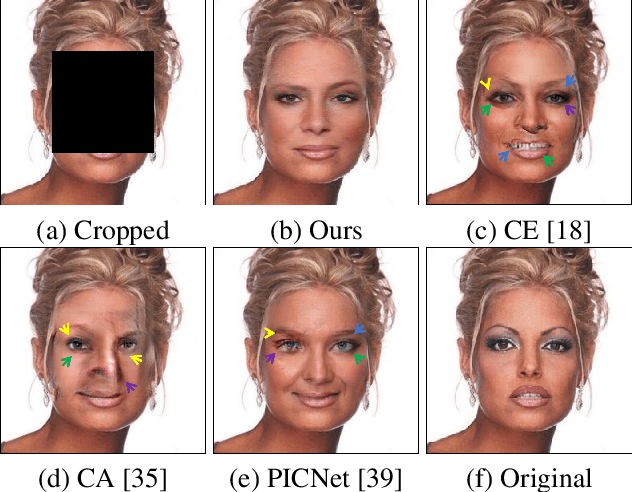
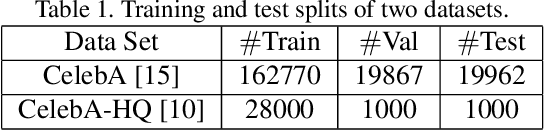
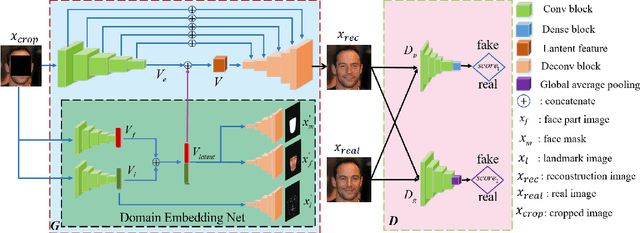
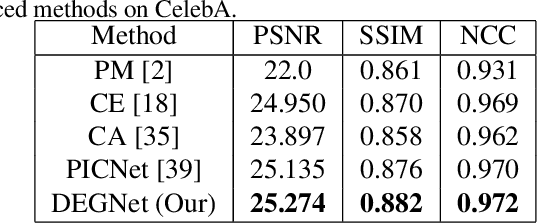
Prior knowledge of face shape and location plays an important role in face inpainting. However, traditional facing inpainting methods mainly focus on the generated image resolution of the missing portion but without consideration of the special particularities of the human face explicitly and generally produce discordant facial parts. To solve this problem, we present a stable variational latent generative model for large inpainting of face images. We firstly represent only face regions with the latent variable space but simultaneously constraint the random vectors to offer control over the distribution of latent variables, and combine with the non-face parts textures to generate a face image with plausible contents. Two adversarial discriminators are finally used to judge whether the generated distribution is close to the real distribution or not. It can not only synthesize novel image structures but also explicitly utilize the latent space with Eigenfaces to make better predictions. Furthermore, our work better evaluates the side face impainting problem. Experiments on both CelebA and CelebA-HQ face datasets demonstrate that our proposed approach generates higher quality inpainting results than existing ones.