 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Performance Effectiveness of Multimedia Information Search Using the Epsilon-Greedy Algorithm
Nov 22, 2019



In the search and retrieval of multimedia objects, it is impractical to either manually or automatically extract the contents for indexing since most of the multimedia contents are not machine extractable, while manual extraction tends to be highly laborious and time-consuming. However, by systematically capturing and analyzing the feedback patterns of human users, vital information concerning the multimedia contents can be harvested for effective indexing and subsequent search. By learning from the human judgment and mental evaluation of users, effective search indices can be gradually developed and built up, and subsequently be exploited to find the most relevant multimedia objects. To avoid hovering around a local maximum, we apply the epsilon-greedy method to systematically explore the search space. Through such methodic exploration, we show that the proposed approach is able to guarantee that the most relevant objects can always be discovered, even though initially it may have been overlooked or not regarded as relevant. The search behavior of the present approach is quantitatively analyzed, and closed-form expressions are obtained for the performance of two variants of the epsilon-greedy algorithm, namely EGSE-A and EGSE-B. Simulations and experiments on real data set have been performed which show good agreement with the theoretical findings. The present method is able to leverage exploration in an effective way to significantly raise the performance of multimedia information search, and enables the certain discovery of relevant objects which may be otherwise undiscoverable.
DEM Super-Resolution with EfficientNetV2
Sep 20, 2021

Efficient climate change monitoring and modeling rely on high-quality geospatial and environmental datasets. Due to limitations in technical capabilities or resources, the acquisition of high-quality data for many environmental disciplines is costly. Digital Elevation Model (DEM) datasets are such examples whereas their low-resolution versions are widely available, high-resolution ones are scarce. In an effort to rectify this problem, we propose and assess an EfficientNetV2 based model. The proposed model increases the spatial resolution of DEMs up to 16times without additional information.
Real-Time Ground-Plane Refined LiDAR SLAM
Oct 21, 2021

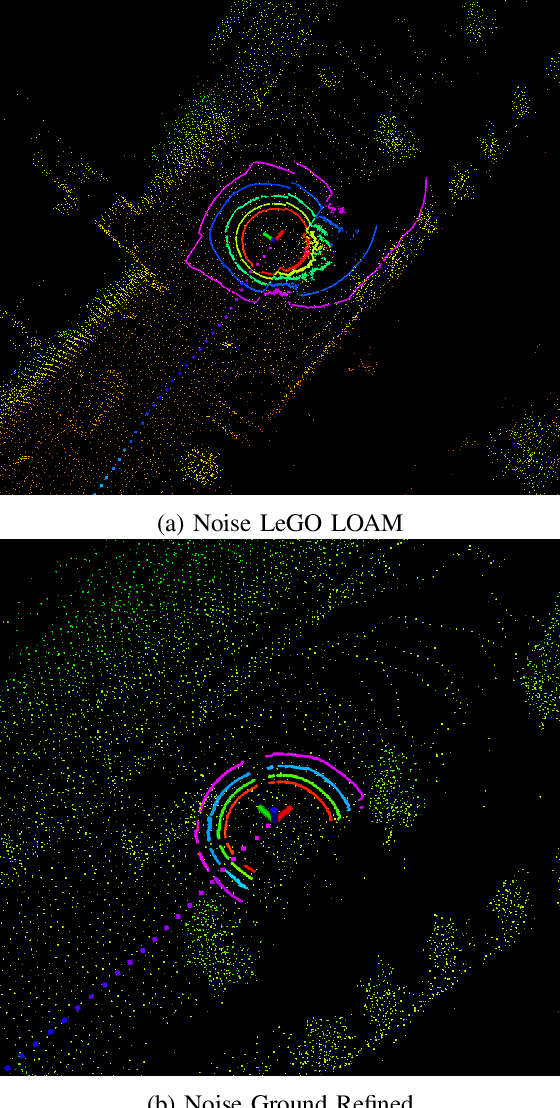
SLAM system using only point cloud has been proven successful in recent years. In most of these systems, they extract features for tracking after ground removal, which causes large variance on the z-axis. Ground actually provides robust information to obtain [t_z, \theta_{roll}, \theta_{pitch}]$. In this project, we followed the LeGO-LOAM, a light-weighted real-time SLAM system that extracts and registers ground as an addition to the original LOAM, and we proposed a new clustering-based method to refine the planar extraction algorithm for ground such that the system can handle much more noisy or dynamic environments. We implemented this method and compared it with LeGo-LOAM on our collected data of CMU campus, as well as a collected dataset for ATV (All-Terrain Vehicle) for off-road self-driving. Both visualization and evaluation results show obvious improvement of our algorithm.
Revisiting IPA-based Cross-lingual Text-to-speech
Oct 18, 2021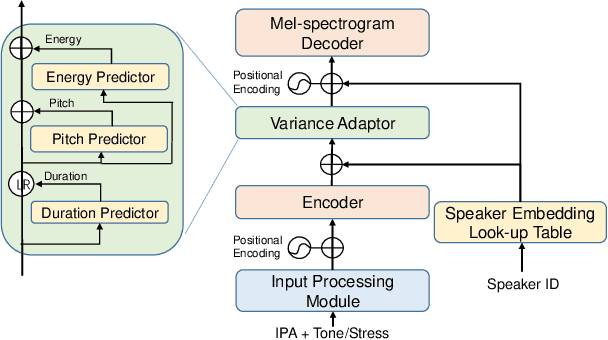
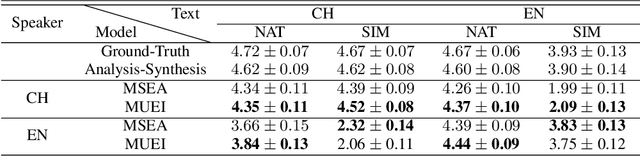
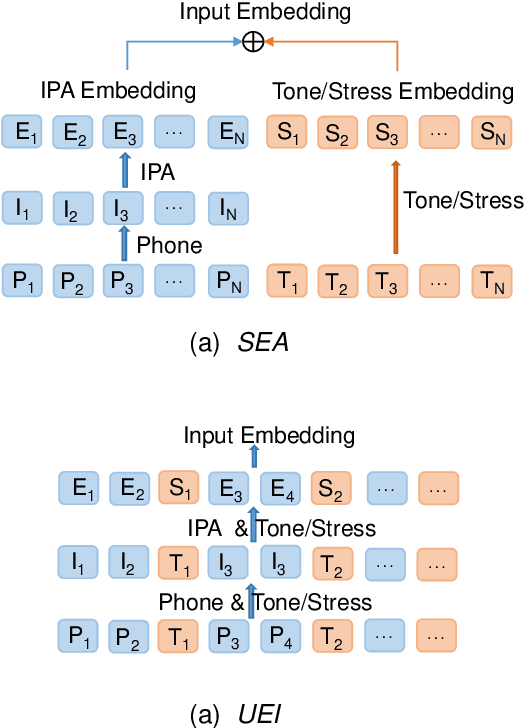
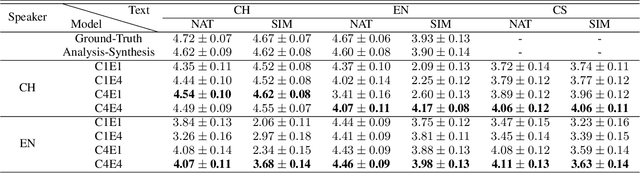
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.
Learning Temporal 3D Human Pose Estimation with Pseudo-Labels
Oct 14, 2021
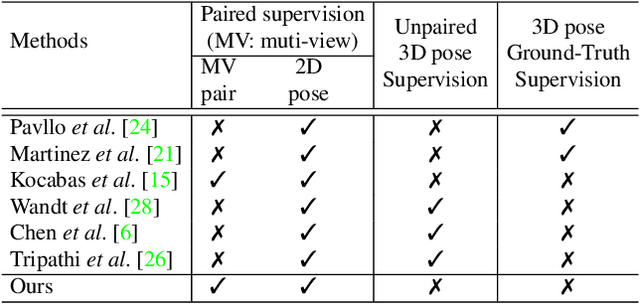
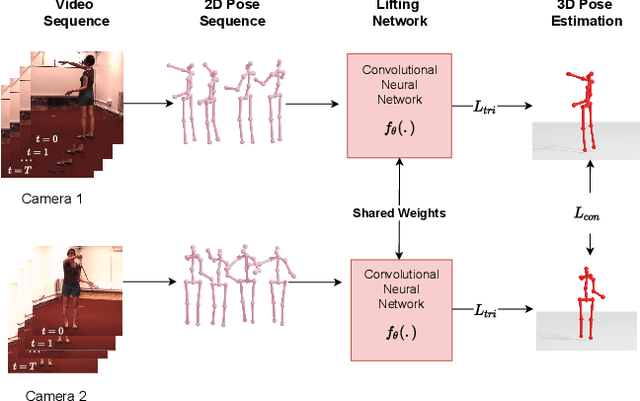

We present a simple, yet effective, approach for self-supervised 3D human pose estimation. Unlike the prior work, we explore the temporal information next to the multi-view self-supervision. During training, we rely on triangulating 2D body pose estimates of a multiple-view camera system. A temporal convolutional neural network is trained with the generated 3D ground-truth and the geometric multi-view consistency loss, imposing geometrical constraints on the predicted 3D body skeleton. During inference, our model receives a sequence of 2D body pose estimates from a single-view to predict the 3D body pose for each of them. An extensive evaluation shows that our method achieves state-of-the-art performance in the Human3.6M and MPI-INF-3DHP benchmarks. Our code and models are publicly available at \url{https://github.com/vru2020/TM_HPE/}.
sMGC: A Complex-Valued Graph Convolutional Network via Magnetic Laplacian for Directed Graphs
Oct 14, 2021
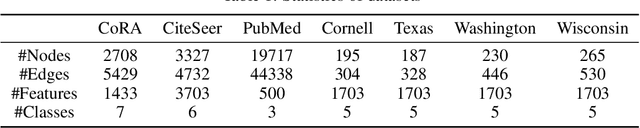
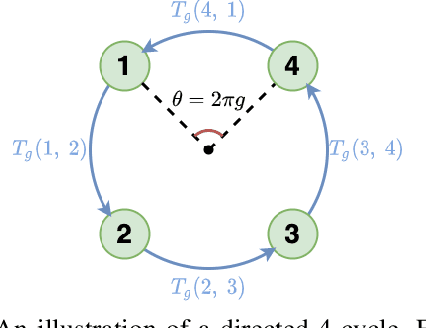
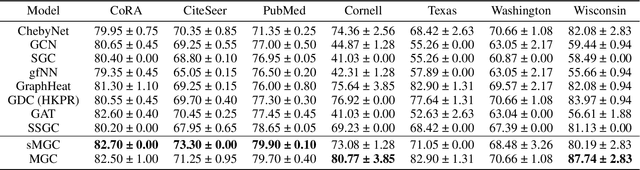
Recent advancements in Graph Neural Networks have led to state-of-the-art performance on representation learning of graphs for node classification. However, the majority of existing works process directed graphs by symmetrization, which may cause loss of directional information. In this paper, we propose the magnetic Laplacian that preserves edge directionality by encoding it into complex phase as a deformation of the combinatorial Laplacian. In addition, we design an Auto-Regressive Moving-Average (ARMA) filter that is capable of learning global features from graphs. To reduce time complexity, Taylor expansion is applied to approximate the filter. We derive complex-valued operations in graph neural network and devise a simplified Magnetic Graph Convolution network, namely sMGC. Our experiment results demonstrate that sMGC is a fast, powerful, and widely applicable GNN.
TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data
Jun 16, 2021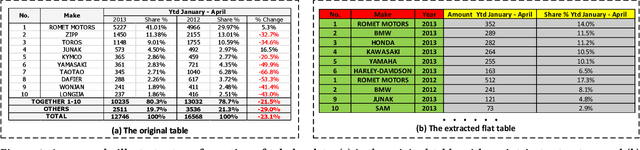
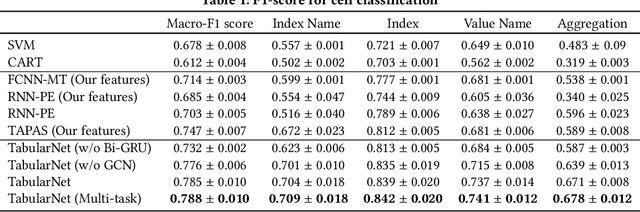
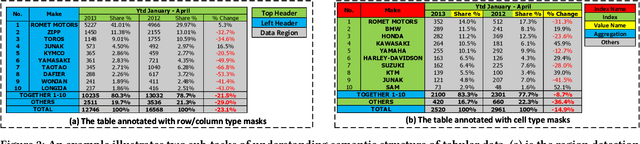
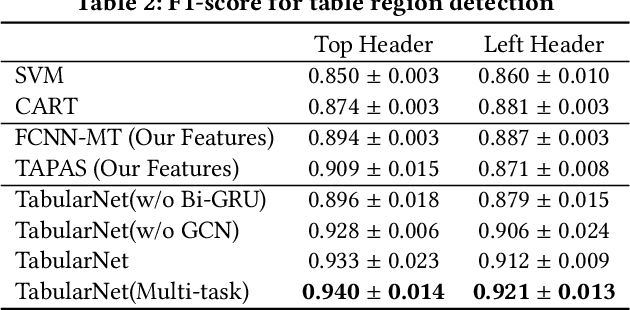
Tabular data are ubiquitous for the widespread applications of tables and hence have attracted the attention of researchers to extract underlying information. One of the critical problems in mining tabular data is how to understand their inherent semantic structures automatically. Existing studies typically adopt Convolutional Neural Network (CNN) to model the spatial information of tabular structures yet ignore more diverse relational information between cells, such as the hierarchical and paratactic relationships. To simultaneously extract spatial and relational information from tables, we propose a novel neural network architecture, TabularNet. The spatial encoder of TabularNet utilizes the row/column-level Pooling and the Bidirectional Gated Recurrent Unit (Bi-GRU) to capture statistical information and local positional correlation, respectively. For relational information, we design a new graph construction method based on the WordNet tree and adopt a Graph Convolutional Network (GCN) based encoder that focuses on the hierarchical and paratactic relationships between cells. Our neural network architecture can be a unified neural backbone for different understanding tasks and utilized in a multitask scenario. We conduct extensive experiments on three classification tasks with two real-world spreadsheet data sets, and the results demonstrate the effectiveness of our proposed TabularNet over state-of-the-art baselines.
Using Natural Language Processing to Understand Reasons and Motivators Behind Customer Calls in Financial Domain
Oct 18, 2021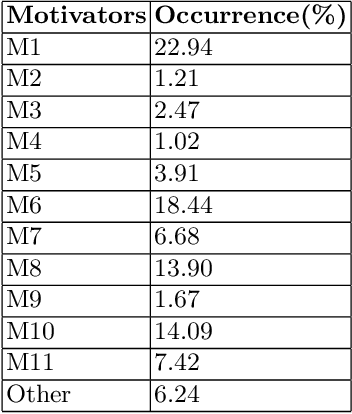
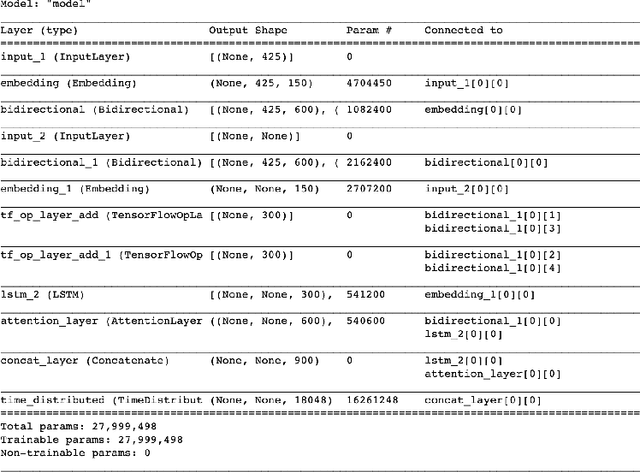
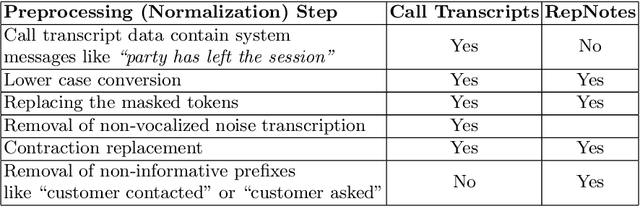
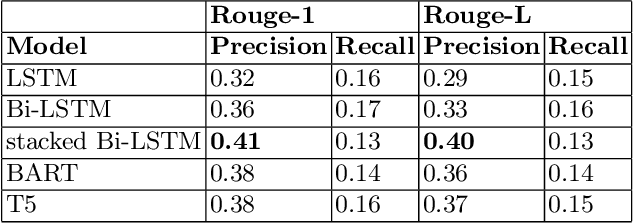
In this era of abundant digital information, customer satisfaction has become one of the prominent factors in the success of any business. Customers want a one-click solution for almost everything. They tend to get unsatisfied if they have to call about something which they could have done online. Moreover, incoming calls are a high-cost component for any business. Thus, it is essential to develop a framework capable of mining the reasons and motivators behind customer calls. This paper proposes two models. Firstly, an attention-based stacked bidirectional Long Short Term Memory Network followed by Hierarchical Clustering for extracting these reasons from transcripts of inbound calls. Secondly, a set of ensemble models based on probabilities from Support Vector Machines and Logistic Regression. It is capable of detecting factors that led to these calls. Extensive evaluation proves the effectiveness of these models.
Sent2Span: Span Detection for PICO Extraction in the Biomedical Text without Span Annotations
Sep 06, 2021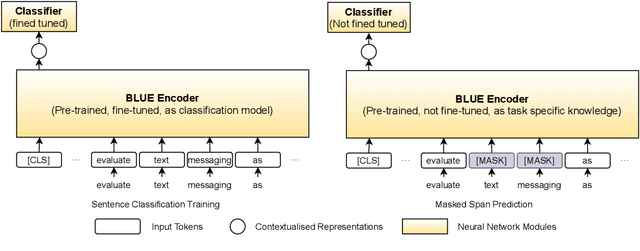
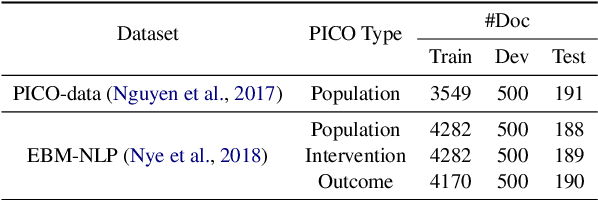
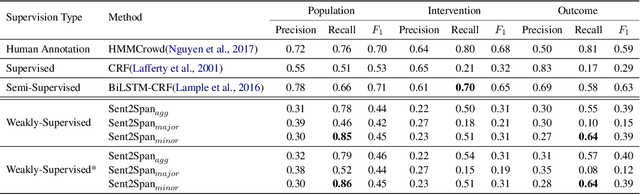
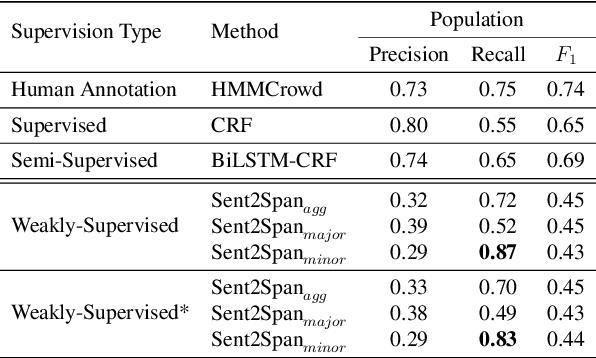
The rapid growth in published clinical trials makes it difficult to maintain up-to-date systematic reviews, which requires finding all relevant trials. This leads to policy and practice decisions based on out-of-date, incomplete, and biased subsets of available clinical evidence. Extracting and then normalising Population, Intervention, Comparator, and Outcome (PICO) information from clinical trial articles may be an effective way to automatically assign trials to systematic reviews and avoid searching and screening - the two most time-consuming systematic review processes. We propose and test a novel approach to PICO span detection. The major difference between our proposed method and previous approaches comes from detecting spans without needing annotated span data and using only crowdsourced sentence-level annotations. Experiments on two datasets show that PICO span detection results achieve much higher results for recall when compared to fully supervised methods with PICO sentence detection at least as good as human annotations. By removing the reliance on expert annotations for span detection, this work could be used in human-machine pipeline for turning low-quality crowdsourced, and sentence-level PICO annotations into structured information that can be used to quickly assign trials to relevant systematic reviews.
Towards Domain-Independent and Real-Time Gesture Recognition Using mmWave Signal
Nov 11, 2021
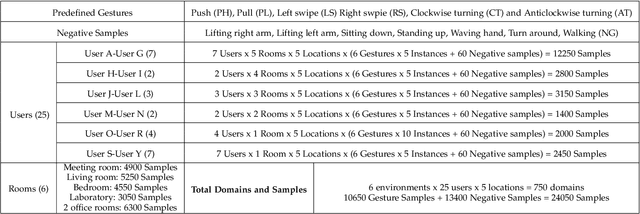


Human gesture recognition using millimeter wave (mmWave) signals provides attractive applications including smart home and in-car interface. While existing works achieve promising performance under controlled settings, practical applications are still limited due to the need of intensive data collection, extra training efforts when adapting to new domains (i.e. environments, persons and locations) and poor performance for real-time recognition. In this paper, we propose DI-Gesture, a domain-independent and real-time mmWave gesture recognition system. Specifically, we first derive the signal variation corresponding to human gestures with spatial-temporal processing. To enhance the robustness of the system and reduce data collecting efforts, we design a data augmentation framework based on the correlation between signal patterns and gesture variations. Furthermore, we propose a dynamic window mechanism to perform gesture segmentation automatically and accurately, thus enable real-time recognition. Finally, we build a lightweight neural network to extract spatial-temporal information from the data for gesture classification. Extensive experimental results show DI-Gesture achieves an average accuracy of 97.92%, 99.18% and 98.76% for new users, environments and locations, respectively. In real-time scenario, the accuracy of DI-Gesutre reaches over 97% with average inference time of 2.87ms, which demonstrates the superior robustness and effectiveness of our system.