 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-nD: Per-Layer Mixture-of-Experts Routing for Multi-Axis KV Cache Compression
Apr 20, 2026KV cache memory is the dominant bottleneck for long-context LLM inference. Existing compression methods each act on a single axis of the four-dimensional KV tensor -- token eviction (sequence), quantization (precision), low-rank projection (head dimension), or cross-layer sharing -- but apply the same recipe to every layer. We show that this homogeneity leaves accuracy on the table: different layers respond very differently to each compression operation, and the optimal per-layer mix of eviction and quantization is far from uniform. We propose MoE-nD, a mixture-of-experts framework that routes each layer to its own (eviction-ratio, K-bits, V-bits) tuple under a global memory budget. An offline-calibrated greedy solver chooses the routing that minimizes predicted quality loss; at inference time, per-layer heterogeneous eviction and quantization are applied jointly through a single attention patch. On a 4-task subset of LongBench-v1 (16k inputs, n=50 per task, adapted reasoning-model protocol; see section Experiments), MoE-nD's hetero variant matches our uncompressed 1.9~GB baseline at 14x compression (136~MB) while every other compressed baseline we tested (1d, 2d_uniform, 2d) at comparable or smaller memory stays under 8/100. The gains hold on AIME reasoning benchmarks (+6 to +27 pts over the strongest per-layer-quantization baseline across eight configurations). Two null results -- MATH-500 and LongBench's TREC -- share a principled cause (short inputs, solver picks keep=1.0 on most layers), cleanly characterizing when per-layer eviction routing has headroom to help.
sMGC: A Complex-Valued Graph Convolutional Network via Magnetic Laplacian for Directed Graphs
Oct 14, 2021
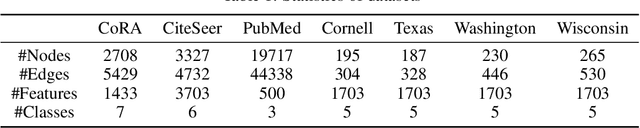
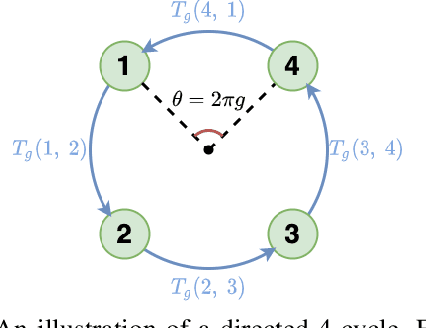
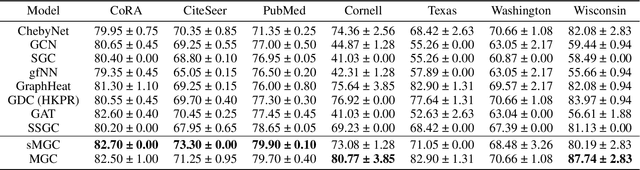
Recent advancements in Graph Neural Networks have led to state-of-the-art performance on representation learning of graphs for node classification. However, the majority of existing works process directed graphs by symmetrization, which may cause loss of directional information. In this paper, we propose the magnetic Laplacian that preserves edge directionality by encoding it into complex phase as a deformation of the combinatorial Laplacian. In addition, we design an Auto-Regressive Moving-Average (ARMA) filter that is capable of learning global features from graphs. To reduce time complexity, Taylor expansion is applied to approximate the filter. We derive complex-valued operations in graph neural network and devise a simplified Magnetic Graph Convolution network, namely sMGC. Our experiment results demonstrate that sMGC is a fast, powerful, and widely applicable GNN.