 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Communication with Adaptive Universal Transformer
Aug 20, 2021
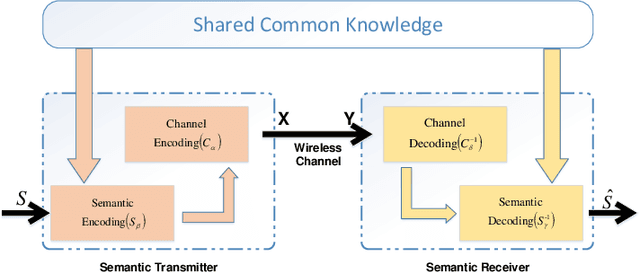
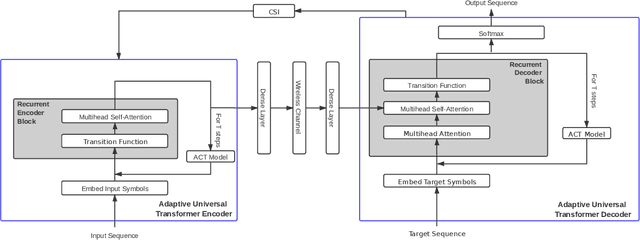
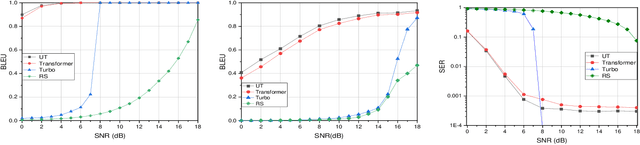
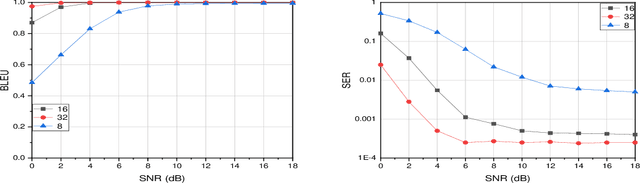
With the development of deep learning (DL), natural language processing (NLP) makes it possible for us to analyze and understand a large amount of language texts. Accordingly, we can achieve a semantic communication in terms of joint semantic source and channel coding over a noisy channel with the help of NLP. However, the existing method to realize this goal is to use a fixed transformer of NLP while ignoring the difference of semantic information contained in each sentence. To solve this problem, we propose a new semantic communication system based on Universal Transformer. Compared with the traditional transformer, an adaptive circulation mechanism is introduced in the Universal Transformer. Through the introduction of the circulation mechanism, the new semantic communication system can be more flexible to transmit sentences with different semantic information, and achieve better end-to-end performance under various channel conditions.
Cross-modal Consensus Network for Weakly Supervised Temporal Action Localization
Jul 27, 2021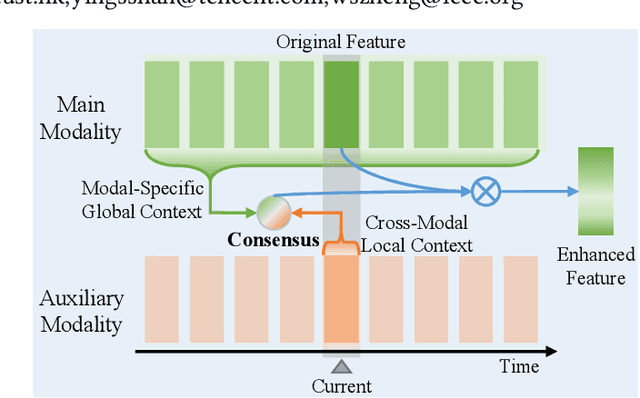
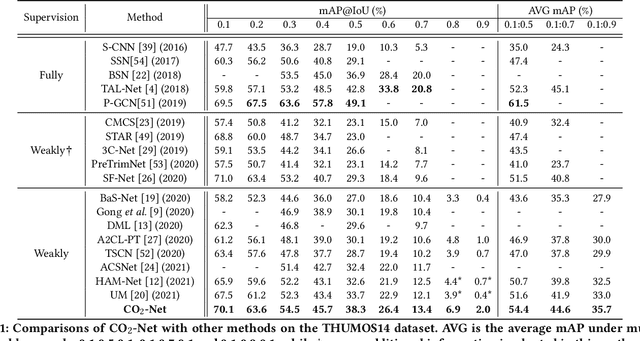
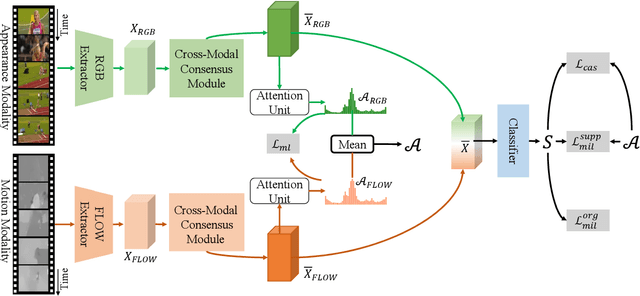
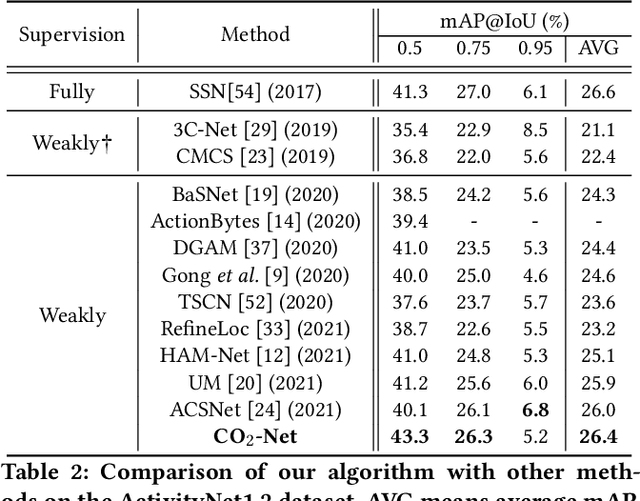
Weakly supervised temporal action localization (WS-TAL) is a challenging task that aims to localize action instances in the given video with video-level categorical supervision. Both appearance and motion features are used in previous works, while they do not utilize them in a proper way but apply simple concatenation or score-level fusion. In this work, we argue that the features extracted from the pretrained extractor, e.g., I3D, are not the WS-TALtask-specific features, thus the feature re-calibration is needed for reducing the task-irrelevant information redundancy. Therefore, we propose a cross-modal consensus network (CO2-Net) to tackle this problem. In CO2-Net, we mainly introduce two identical proposed cross-modal consensus modules (CCM) that design a cross-modal attention mechanism to filter out the task-irrelevant information redundancy using the global information from the main modality and the cross-modal local information of the auxiliary modality. Moreover, we treat the attention weights derived from each CCMas the pseudo targets of the attention weights derived from another CCM to maintain the consistency between the predictions derived from two CCMs, forming a mutual learning manner. Finally, we conduct extensive experiments on two common used temporal action localization datasets, THUMOS14 and ActivityNet1.2, to verify our method and achieve the state-of-the-art results. The experimental results show that our proposed cross-modal consensus module can produce more representative features for temporal action localization.
Sparse-MLP: A Fully-MLP Architecture with Conditional Computation
Sep 08, 2021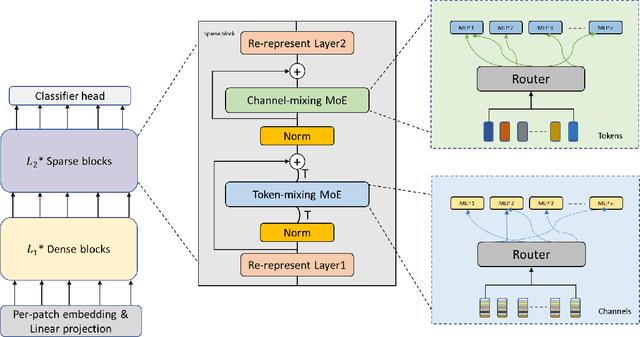

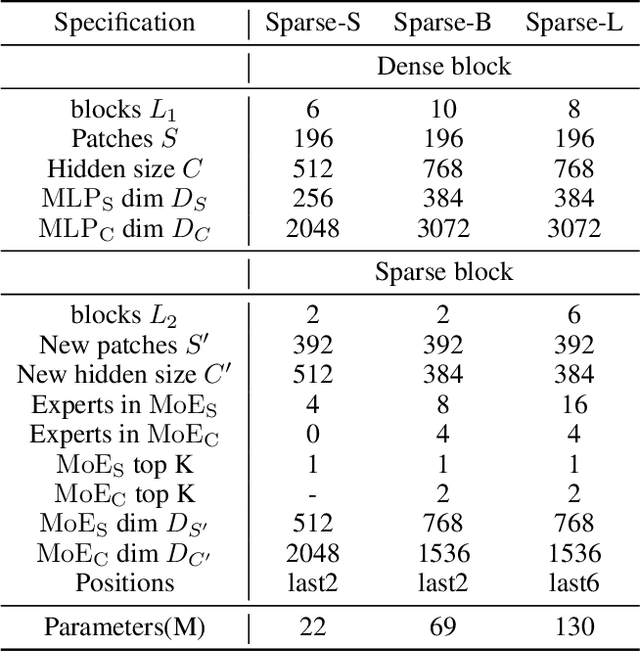
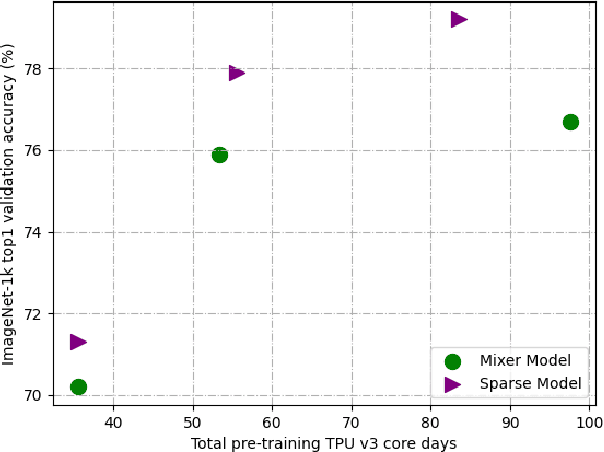
Mixture-of-Experts (MoE) with sparse conditional computation has been proved an effective architecture for scaling attention-based models to more parameters with comparable computation cost. In this paper, we propose Sparse-MLP, scaling the recent MLP-Mixer model with sparse MoE layers, to achieve a more computation-efficient architecture. We replace a subset of dense MLP blocks in the MLP-Mixer model with Sparse blocks. In each Sparse block, we apply two stages of MoE layers: one with MLP experts mixing information within channels along image patch dimension, one with MLP experts mixing information within patches along the channel dimension. Besides, to reduce computational cost in routing and improve expert capacity, we design Re-represent layers in each Sparse block. These layers are to re-scale image representations by two simple but effective linear transformations. When pre-training on ImageNet-1k with MoCo v3 algorithm, our models can outperform dense MLP models by 2.5\% on ImageNet Top-1 accuracy with fewer parameters and computational cost. On small-scale downstream image classification tasks, i.e. Cifar10 and Cifar100, our Sparse-MLP can still achieve better performance than baselines.
Learning Dynamic Compact Memory Embedding for Deformable Visual Object Tracking
Nov 23, 2021
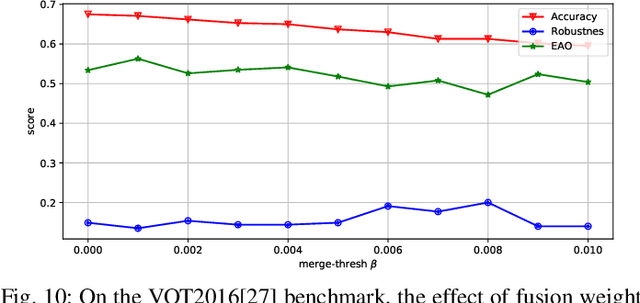

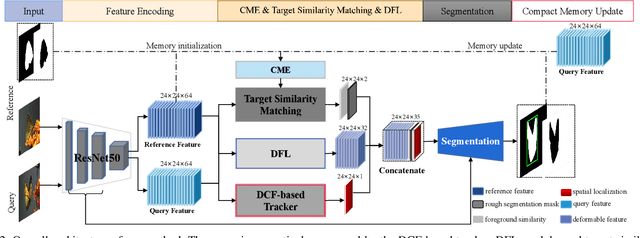
Recently, template-based trackers have become the leading tracking algorithms with promising performance in terms of efficiency and accuracy. However, the correlation operation between query feature and the given template only exploits accurate target localization, leading to state estimation error especially when the target suffers from severe deformable variations. To address this issue, segmentation-based trackers have been proposed that employ per-pixel matching to improve the tracking performance of deformable objects effectively. However, most of existing trackers only refer to the target features in the initial frame, thereby lacking the discriminative capacity to handle challenging factors, e.g., similar distractors, background clutter, appearance change, etc. To this end, we propose a dynamic compact memory embedding to enhance the discrimination of the segmentation-based deformable visual tracking method. Specifically, we initialize a memory embedding with the target features in the first frame. During the tracking process, the current target features that have high correlation with existing memory are updated to the memory embedding online. To further improve the segmentation accuracy for deformable objects, we employ a point-to-global matching strategy to measure the correlation between the pixel-wise query features and the whole template, so as to capture more detailed deformation information. Extensive evaluations on six challenging tracking benchmarks including VOT2016, VOT2018, VOT2019, GOT-10K, TrackingNet, and LaSOT demonstrate the superiority of our method over recent remarkable trackers. Besides, our method outperforms the excellent segmentation-based trackers, i.e., D3S and SiamMask on DAVIS2017 benchmark.
GROWL: Group Detection With Link Prediction
Nov 08, 2021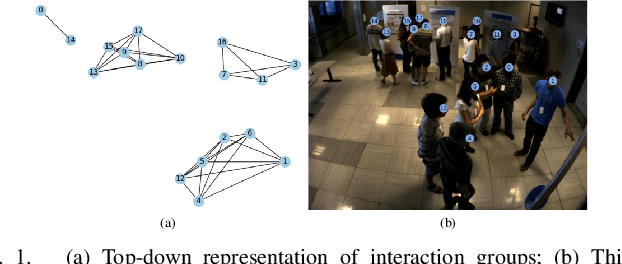
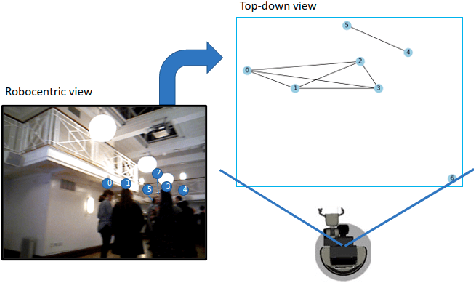
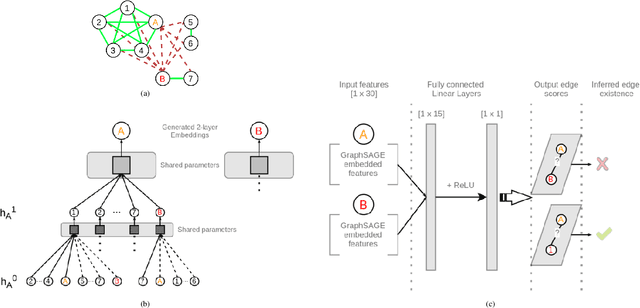
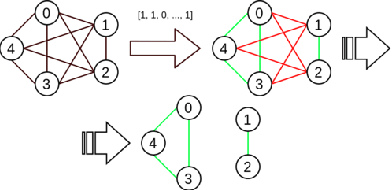
Interaction group detection has been previously addressed with bottom-up approaches which relied on the position and orientation information of individuals. These approaches were primarily based on pairwise affinity matrices and were limited to static, third-person views. This problem can greatly benefit from a holistic approach based on Graph Neural Networks (GNNs) beyond pairwise relationships, due to the inherent spatial configuration that exists between individuals who form interaction groups. Our proposed method, GROup detection With Link prediction (GROWL), demonstrates the effectiveness of a GNN based approach. GROWL predicts the link between two individuals by generating a feature embedding based on their neighbourhood in the graph and determines whether they are connected with a shallow binary classification method such as Multi-layer Perceptrons (MLPs). We test our method against other state-of-the-art group detection approaches on both a third-person view dataset and a robocentric (i.e., egocentric) dataset. In addition, we propose a multimodal approach based on RGB and depth data to calculate a representation GROWL can utilise as input. Our results show that a GNN based approach can significantly improve accuracy across different camera views, i.e., third-person and egocentric views.
A Quantization QoE Evaluation Approach in 6DoF Point Cloud Video Streaming
Nov 08, 2021

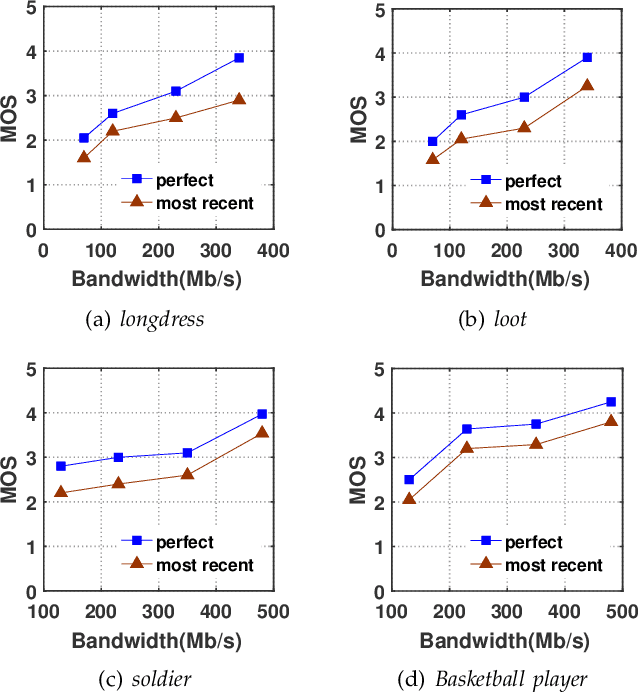

Point cloud video has been widely used by augmented reality (AR) and virtual reality (VR) applications as it allows users to have an immersive experience of six degrees of freedom (6DoFs). Yet there is still a lack of research on quality of experience (QoE) model of point cloud video streaming, which cannot provide optimization metric for streaming systems. Besides, position and color information contained in each pixel of point cloud video, and viewport distance effect caused by 6DoFs viewing procedure make the traditional objective quality evaluation metric cannot be directly used in point cloud video streaming system. In this paper we first analyze the subjective and objective factors related to QoE model. Then an experimental system to simulate point cloud video streaming is setup and detailed subjective quality evaluation experiments are carried out. Based on collected mean opinion score (MOS) data, we propose a QoE model for point cloud video streaming. We also verify the model by actual subjective scoring, and the results show that the proposed QoE model can accurately reflect users' visual perception. We also make the experimental database public to promote the QoE research of point cloud video streaming.
Waveform Learning for Next-Generation Wireless Communication Systems
Sep 02, 2021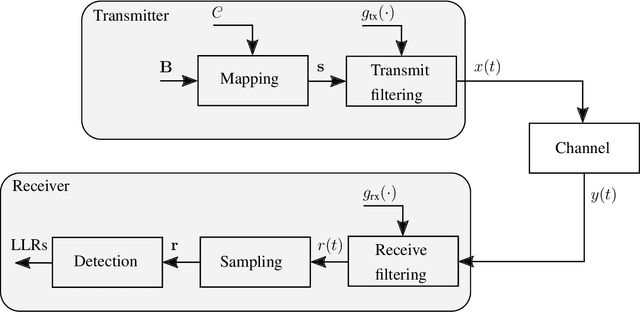
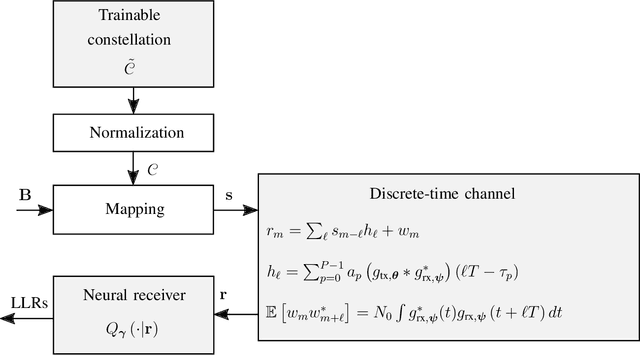
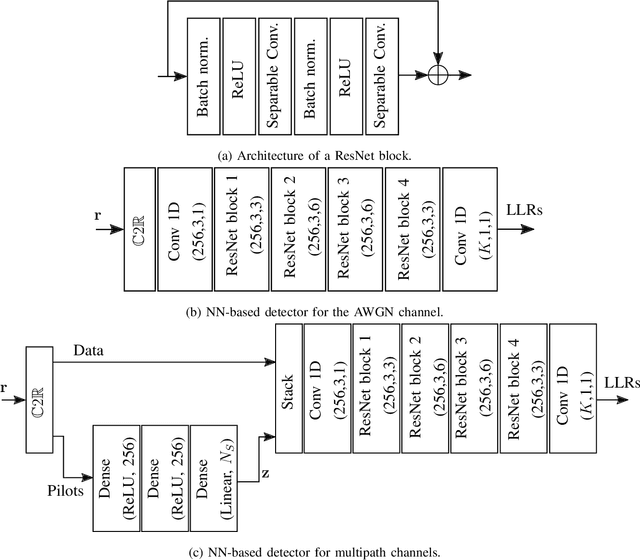
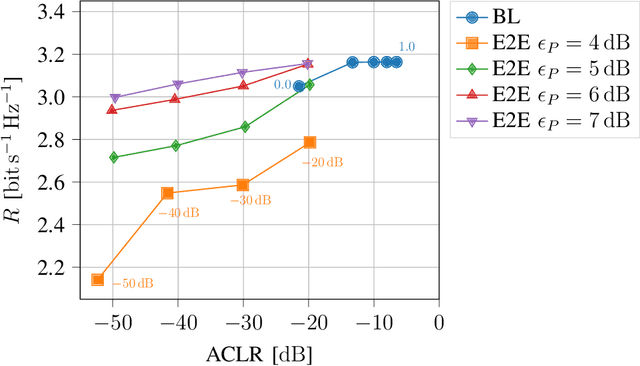
We propose a learning-based method for the joint design of a transmit and receive filter, the constellation geometry and associated bit labeling, as well as a neural network (NN)-based detector. The method maximizes an achievable information rate, while simultaneously satisfying constraints on the adjacent channel leakage ratio (ACLR) and peak-to-average power ratio (PAPR). This allows control of the tradeoff between spectral containment, peak power, and communication rate. Evaluation on an additive white Gaussian noise (AWGN) channel shows significant reduction of ACLR and PAPR compared to a conventional baseline relying on quadrature amplitude modulation (QAM) and root-raised-cosine (RRC), without significant loss of information rate. When considering a 3rd Generation Partnership Project (3GPP) multipath channel, the learned waveform and neural receiver enable competitive or higher rates than an orthogonal frequency division multiplexing (OFDM) baseline, while reducing the ACLR by 10 dB and the PAPR by 2 dB. The proposed method incurs no additional complexity on the transmitter side and might be an attractive tool for waveform design of beyond-5G systems.
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021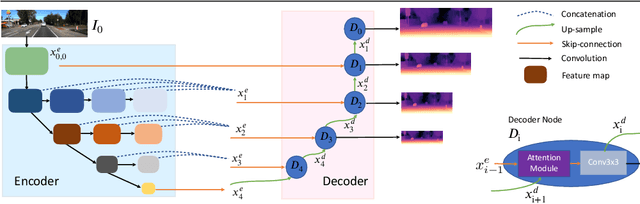
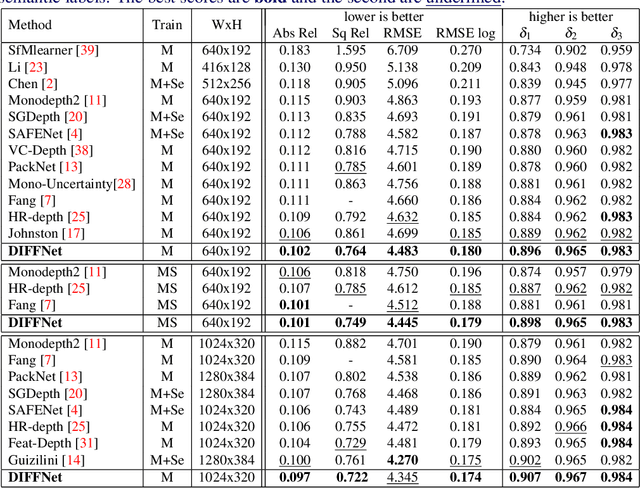

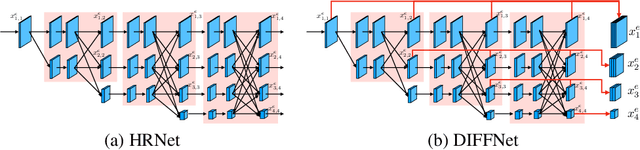
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.
Over-the-Air Aggregation for Federated Learning: Waveform Superposition and Prototype Validation
Oct 27, 2021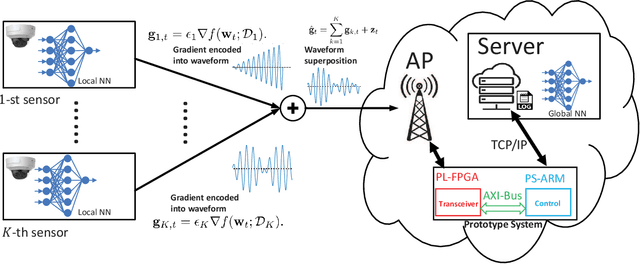
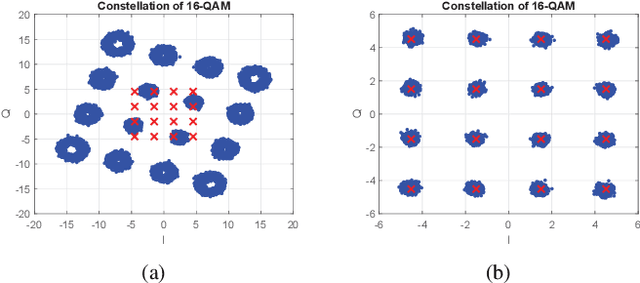
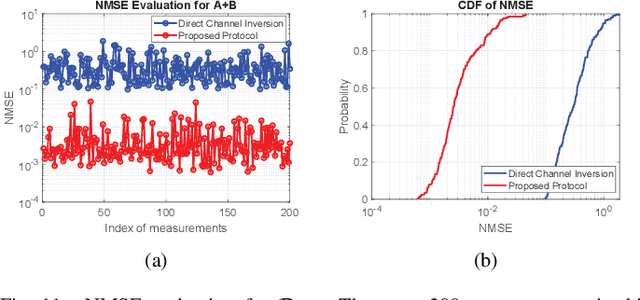

In this paper, we develop an orthogonal-frequency-division-multiplexing (OFDM)-based over-the-air (OTA) aggregation solution for wireless federated learning (FL). In particular, the local gradients in massive IoT devices are modulated by an analog waveform and are then transmitted using the same wireless resources. To this end, achieving perfect waveform superposition is the key challenge, which is difficult due to the existence of frame timing offset (TO) and carrier frequency offset (CFO). In order to address these issues, we propose a two-stage waveform pre-equalization technique with a customized multiple access protocol that can estimate and then mitigate the TO and CFO for the OTA aggregation. Based on the proposed solution, we develop a hardware transceiver and application software to train a real-world FL task, which learns a deep neural network to predict the received signal strength with global positioning system information. Experiments verify that the proposed OTA aggregation solution can achieve comparable performance to offline learning procedures with high prediction accuracy.
Policy Gradients Incorporating the Future
Aug 04, 2021

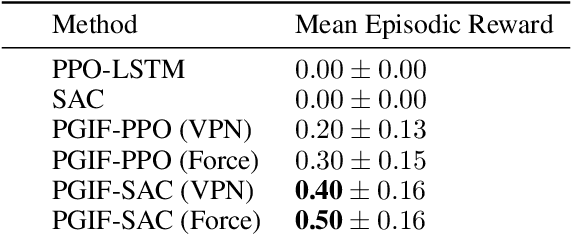

Reasoning about the future -- understanding how decisions in the present time affect outcomes in the future -- is one of the central challenges for reinforcement learning (RL), especially in highly-stochastic or partially observable environments. While predicting the future directly is hard, in this work we introduce a method that allows an agent to "look into the future" without explicitly predicting it. Namely, we propose to allow an agent, during its training on past experience, to observe what \emph{actually} happened in the future at that time, while enforcing an information bottleneck to avoid the agent overly relying on this privileged information. This gives our agent the opportunity to utilize rich and useful information about the future trajectory dynamics in addition to the present. Our method, Policy Gradients Incorporating the Future (PGIF), is easy to implement and versatile, being applicable to virtually any policy gradient algorithm. We apply our proposed method to a number of off-the-shelf RL algorithms and show that PGIF is able to achieve higher reward faster in a variety of online and offline RL domains, as well as sparse-reward and partially observable environments.