 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncLane: Decoupling Refinement from Advancement in Diffusion Language Model Decoding
Jun 07, 2026Block-wise semi-autoregressive decoding is the standard inference paradigm for diffusion large language models (DLMs), but it imposes a strict dependency between blocks: the next block cannot begin until the current block is fully decoded or its denoising budget is exhausted. We observe that once a block exposes a reliable delimiter boundary or stable semantic prefix, continuation generation need not wait for every residual token to be resolved. We propose AsyncLane, a training-free decoding scheduler that decouples refinement from advancement. AsyncLane forks a generate lane at observed delimiter boundaries into a refine lane and a continuation generate lane: the prefix remains editable, while the continuation advances before prefix refinement finishes. The resulting lane tree records decoding dependencies and output order, while execution proceeds over the active lane set. To make this asynchronous schedule efficient under bidirectional attention, AsyncLane combines shared-prefix lane batching, lookahead draft reuse, cascading termination, and compact cache refresh with refresh-logit reuse, preventing model-call cost from scaling directly with the number of lanes. AsyncLane is a drop-in replacement for block-wise DLM samplers and requires no retraining. Experiments on mathematical reasoning and code generation show that AsyncLane consistently improves throughput while maintaining competitive quality. Across LLaDA and Dream backbones, AsyncLane achieves the highest TPS in all evaluated benchmark-length settings; relative to the fastest competing baseline, it reaches peak speedups of 2.95x on LLaDA and 3.04x on Dream, with especially large gains under longer generation budgets.
DiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion
Jan 30, 2026Current speech language models generate responses directly without explicit reasoning, leading to errors that cannot be corrected once audio is produced. We introduce \textbf{``Silent Thought, Spoken Answer''} -- a paradigm where speech LLMs generate internal text reasoning alongside spoken responses, with thinking traces informing speech quality. To realize this, we present \method{}, the first diffusion-based speech-text language model supporting both understanding and generation, unifying discrete text and tokenized speech under a single masked diffusion framework. Unlike autoregressive approaches, \method{} jointly generates reasoning traces and speech tokens through iterative denoising, with modality-specific masking schedules. We also construct \dataset{}, the first speech QA dataset with paired text reasoning traces, containing 26K samples totaling 319 hours. Experiments show \method{} achieves state-of-the-art speech-to-speech QA accuracy, outperforming the best baseline by up to 9 points, while attaining the best TTS quality among generative models (6.2\% WER) and preserving language understanding (66.2\% MMLU). Ablations confirm that both the diffusion architecture and thinking traces contribute to these gains.
MoST: Mixing Speech and Text with Modality-Aware Mixture of Experts
Jan 15, 2026We present MoST (Mixture of Speech and Text), a novel multimodal large language model that seamlessly integrates speech and text processing through our proposed Modality-Aware Mixture of Experts (MAMoE) architecture. While current multimodal models typically process diverse modality representations with identical parameters, disregarding their inherent representational differences, we introduce specialized routing pathways that direct tokens to modality-appropriate experts based on input type. MAMoE simultaneously enhances modality-specific learning and cross-modal understanding through two complementary components: modality-specific expert groups that capture domain-specific patterns and shared experts that facilitate information transfer between modalities. Building on this architecture, we develop an efficient transformation pipeline that adapts the pretrained MoE language model through strategic post-training on ASR and TTS datasets, followed by fine-tuning with a carefully curated speech-text instruction dataset. A key feature of this pipeline is that it relies exclusively on fully accessible, open-source datasets to achieve strong performance and data efficiency. Comprehensive evaluations across ASR, TTS, audio language modeling, and spoken question answering benchmarks show that MoST consistently outperforms existing models of comparable parameter counts. Our ablation studies confirm that the modality-specific routing mechanism and shared experts design significantly contribute to performance gains across all tested domains. To our knowledge, MoST represents the first fully open-source speech-text LLM built on a Mixture of Experts architecture. \footnote{We release MoST model, training code, inference code, and training data at https://github.com/NUS-HPC-AI-Lab/MoST
EnvBridge: Bridging Diverse Environments with Cross-Environment Knowledge Transfer for Embodied AI
Oct 22, 2024



In recent years, Large Language Models (LLMs) have demonstrated high reasoning capabilities, drawing attention for their applications as agents in various decision-making processes. One notably promising application of LLM agents is robotic manipulation. Recent research has shown that LLMs can generate text planning or control code for robots, providing substantial flexibility and interaction capabilities. However, these methods still face challenges in terms of flexibility and applicability across different environments, limiting their ability to adapt autonomously. Current approaches typically fall into two categories: those relying on environment-specific policy training, which restricts their transferability, and those generating code actions based on fixed prompts, which leads to diminished performance when confronted with new environments. These limitations significantly constrain the generalizability of agents in robotic manipulation. To address these limitations, we propose a novel method called EnvBridge. This approach involves the retention and transfer of successful robot control codes from source environments to target environments. EnvBridge enhances the agent's adaptability and performance across diverse settings by leveraging insights from multiple environments. Notably, our approach alleviates environmental constraints, offering a more flexible and generalizable solution for robotic manipulation tasks. We validated the effectiveness of our method using robotic manipulation benchmarks: RLBench, MetaWorld, and CALVIN. Our experiments demonstrate that LLM agents can successfully leverage diverse knowledge sources to solve complex tasks. Consequently, our approach significantly enhances the adaptability and robustness of robotic manipulation agents in planning across diverse environments.
RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents
Feb 06, 2024



Owing to recent advancements, Large Language Models (LLMs) can now be deployed as agents for increasingly complex decision-making applications in areas including robotics, gaming, and API integration. However, reflecting past experiences in current decision-making processes, an innate human behavior, continues to pose significant challenges. Addressing this, we propose Retrieval-Augmented Planning (RAP) framework, designed to dynamically leverage past experiences corresponding to the current situation and context, thereby enhancing agents' planning capabilities. RAP distinguishes itself by being versatile: it excels in both text-only and multimodal environments, making it suitable for a wide range of tasks. Empirical evaluations demonstrate RAP's effectiveness, where it achieves SOTA performance in textual scenarios and notably enhances multimodal LLM agents' performance for embodied tasks. These results highlight RAP's potential in advancing the functionality and applicability of LLM agents in complex, real-world applications.
One Student Knows All Experts Know: From Sparse to Dense
Jan 26, 2022
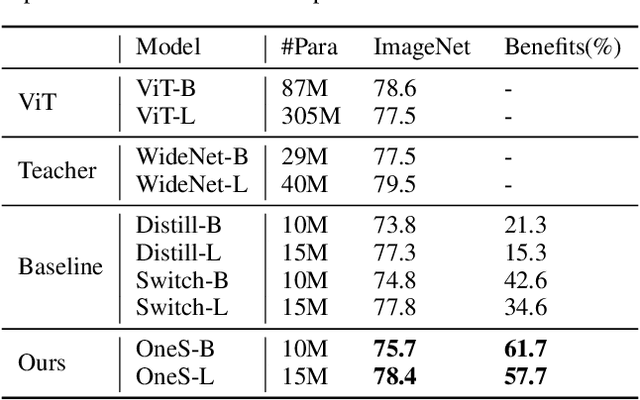
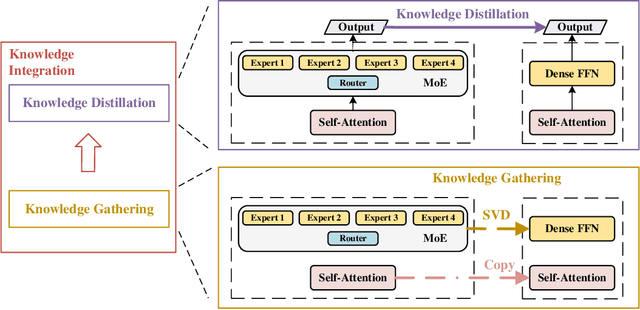
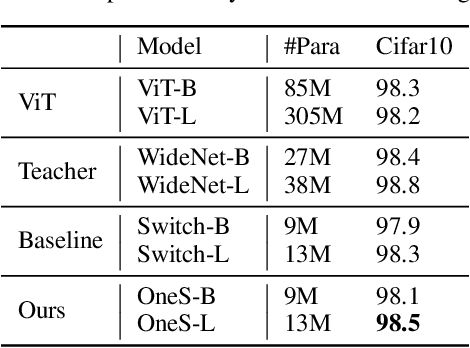
Human education system trains one student by multiple experts. Mixture-of-experts (MoE) is a powerful sparse architecture including multiple experts. However, sparse MoE model is hard to implement, easy to overfit, and not hardware-friendly. In this work, inspired by human education model, we propose a novel task, knowledge integration, to obtain a dense student model (OneS) as knowledgeable as one sparse MoE. We investigate this task by proposing a general training framework including knowledge gathering and knowledge distillation. Specifically, we first propose Singular Value Decomposition Knowledge Gathering (SVD-KG) to gather key knowledge from different pretrained experts. We then refine the dense student model by knowledge distillation to offset the noise from gathering. On ImageNet, our OneS preserves $61.7\%$ benefits from MoE. OneS can achieve $78.4\%$ top-1 accuracy with only $15$M parameters. On four natural language processing datasets, OneS obtains $88.2\%$ MoE benefits and outperforms SoTA by $51.7\%$ using the same architecture and training data. In addition, compared with the MoE counterpart, OneS can achieve $3.7 \times$ inference speedup due to the hardware-friendly architecture.
Sparse-MLP: A Fully-MLP Architecture with Conditional Computation
Sep 08, 2021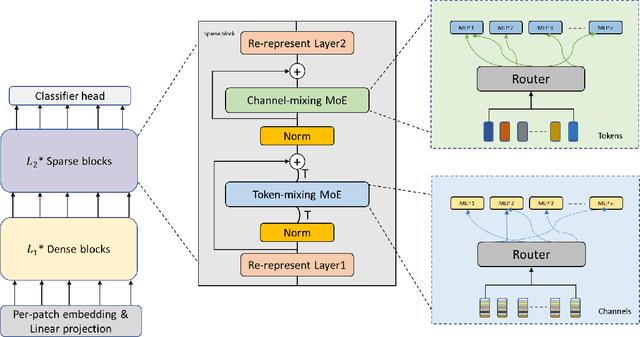

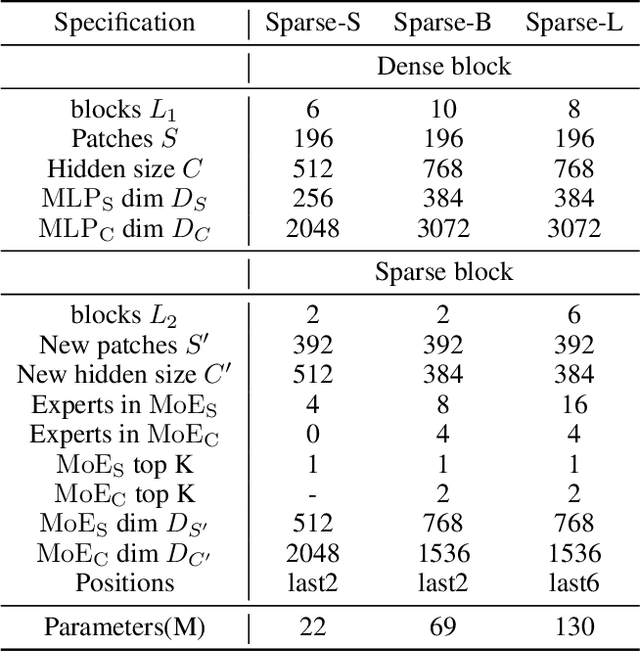
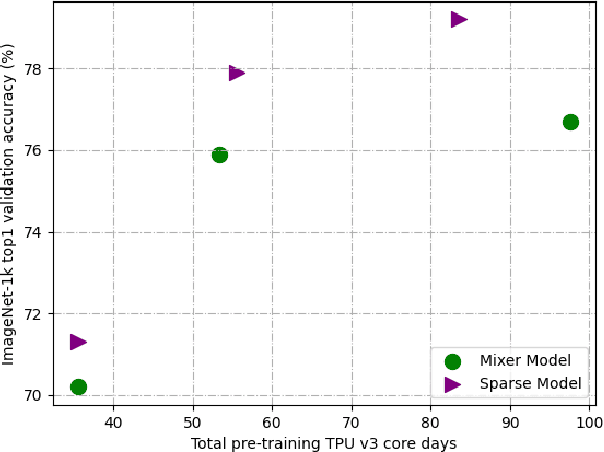
Mixture-of-Experts (MoE) with sparse conditional computation has been proved an effective architecture for scaling attention-based models to more parameters with comparable computation cost. In this paper, we propose Sparse-MLP, scaling the recent MLP-Mixer model with sparse MoE layers, to achieve a more computation-efficient architecture. We replace a subset of dense MLP blocks in the MLP-Mixer model with Sparse blocks. In each Sparse block, we apply two stages of MoE layers: one with MLP experts mixing information within channels along image patch dimension, one with MLP experts mixing information within patches along the channel dimension. Besides, to reduce computational cost in routing and improve expert capacity, we design Re-represent layers in each Sparse block. These layers are to re-scale image representations by two simple but effective linear transformations. When pre-training on ImageNet-1k with MoCo v3 algorithm, our models can outperform dense MLP models by 2.5\% on ImageNet Top-1 accuracy with fewer parameters and computational cost. On small-scale downstream image classification tasks, i.e. Cifar10 and Cifar100, our Sparse-MLP can still achieve better performance than baselines.
Go Wider Instead of Deeper
Jul 29, 2021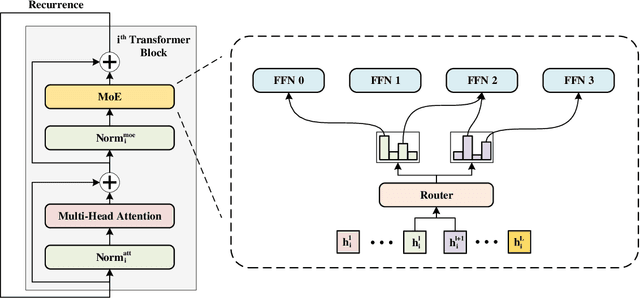
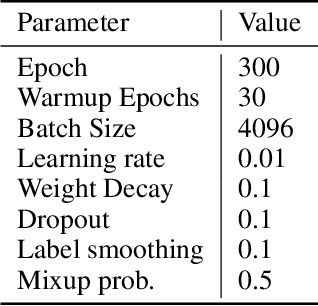
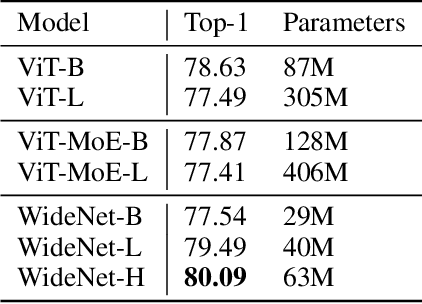
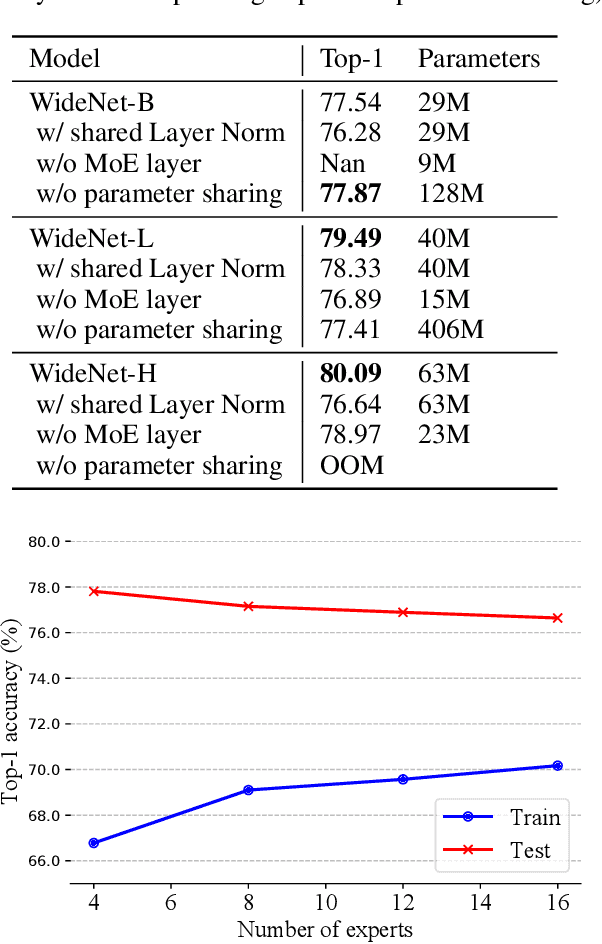
The transformer has recently achieved impressive results on various tasks. To further improve the effectiveness and efficiency of the transformer, there are two trains of thought among existing works: (1) going wider by scaling to more trainable parameters; (2) going shallower by parameter sharing or model compressing along with the depth. However, larger models usually do not scale well when fewer tokens are available to train, and advanced parallelisms are required when the model is extremely large. Smaller models usually achieve inferior performance compared to the original transformer model due to the loss of representation power. In this paper, to achieve better performance with fewer trainable parameters, we propose a framework to deploy trainable parameters efficiently, by going wider instead of deeper. Specially, we scale along model width by replacing feed-forward network (FFN) with mixture-of-experts (MoE). We then share the MoE layers across transformer blocks using individual layer normalization. Such deployment plays the role to transform various semantic representations, which makes the model more parameter-efficient and effective. To evaluate our framework, we design WideNet and evaluate it on ImageNet-1K. Our best model outperforms Vision Transformer (ViT) by $1.46\%$ with $0.72 \times$ trainable parameters. Using $0.46 \times$ and $0.13 \times$ parameters, our WideNet can still surpass ViT and ViT-MoE by $0.83\%$ and $2.08\%$, respectively.