 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN Based Joint Beamforming Design for Extremely Large-Scale RIS Assisted Near-Field ISAC Systems
Mar 02, 2026This paper investigates an extremely large-scale reconfigurable intelligent surface (XL-RIS) assisted near-field integrated sensing and communication (ISAC) system, where a multi-antenna base station (BS) simultaneously sends unicast data to multiple single-antenna communication users (CUs) and senses multiple targets (TGTs). The BS, CUs and TGTs are \emph{all} assumed to be located in the near-field region of the XL-RIS. We aim to maximize the weighted sum rate (WSR) of all CUs, subject to the sensing beampattern gain constraint for each TGT, the transmit power constraint for the BS, and the unit modulus constraints on the XL-RIS phase shift. First, we develop a fractional programming (FP) based block coordinate descent (BCD) algorithm to obtain a locally optimal solution for such a non-convex joint design problem. Secondly, to address the high-dimensional spatial correlations and scalability of the XL-RIS near-field channels, we propose a customized graph neural network (GNN) scheme to generate the BS transmit beamforming variables and the XL-RIS reflecting coefficient vector for ISAC, where the near-field ISAC system is modeled as a heterogeneous graph comprising XL-RIS/CU/TGT nodes. The proposed GNN scheme can effectively learn the near-field channel state information (CSI) features, in which the message passing mechanism is employed to exchange CSI among these directly connected nodes in the graph. Furthermore, each XL-RIS/CU/TGT node maintains a feature vector for mapping to the BS transmit beamforming variables or the XL-RIS reflecting coefficient vector. Numerical results show that the proposed GNN-based beamforming design scheme achieves a better performance than the existing baselines, in terms of computational efficiency, feasibility, robustness, and the ability of generalization.
Channel Estimation and Passive Beamforming for Pixel-based Reconfigurable Intelligent Surfaces with Non-Separable State Response
Oct 23, 2025



Pixel-based reconfigurable intelligent surfaces (RISs) employ a novel design to achieve high reflection gain at a lower hardware cost by eliminating the phase shifters used in traditional RIS. However, this design presents challenges for channel estimation and passive beamforming due to its non-separable state response, rendering existing solutions ineffective. To address this, we first approximate the non-separable RIS response functions using a kernel-based method and a deep neural network, achieving high accuracy while reducing computational and memory complexity. Next, we propose a simplified cascaded channel model that focuses on dominated scattering paths with limited unknown parameters, along with customized algorithms to estimate short-term and long-term parameters separately. Finally, we introduce a low-complexity passive beamforming algorithm to configure the discrete RIS state vector, maximizing the achievable rate. Our simulation results demonstrate that the proposed solution significantly outperforms various baselines across a wide SNR range.
Channel Estimation and Analog Precoding for Pixel-based Fluid-Antenna-Assisted Multiuser MIMO-OFDM Systems
Sep 11, 2025Pixel-based fluid antennas provide enhanced multiplexing gains and quicker radiation pattern switching than traditional designs. However, this innovation introduces challenges for channel estimation and analog precoding due to the state-non-separable channel response problem. This paper explores a multiuser MIMO-OFDM system utilizing pixel-based fluid antennas, informed by measurements from a real-world prototype. We present a sparse channel recovery framework for uplink channel sounding, employing an approximate separable channel response model with DNN-based antenna radiation functions. We then propose two low-complexity channel estimation algorithms that leverage orthogonal matching pursuit and variational Bayesian inference to accurately recover channel responses across various scattering cluster angles. These estimations enable the prediction of composite channels for all fluid antenna states, leading to an analog precoding scheme that optimally selects switching states for different antennas. Our simulation results indicate that the proposed approach significantly outperforms several baseline methods, especially in high signal-to-noise ratio environments with numerous users.
Basis Expansion Extrapolation based Long-Term Channel Prediction for Massive MIMO OTFS Systems
Jul 02, 2025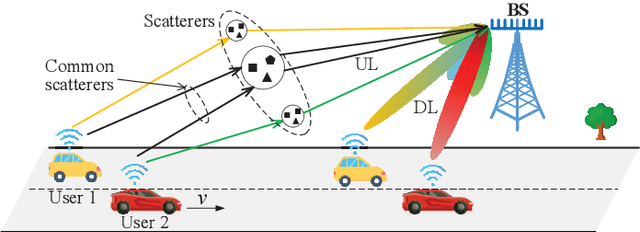
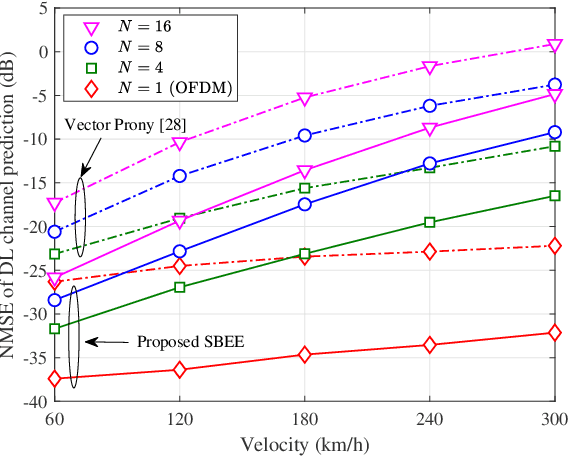
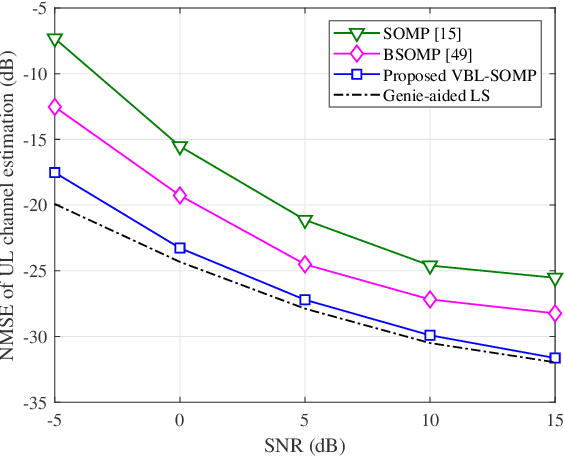
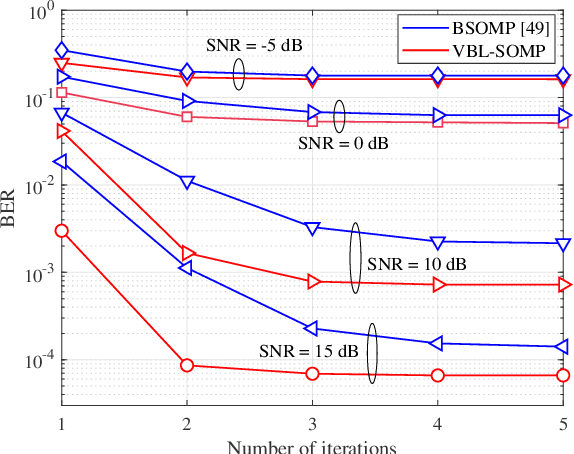
Massive multi-input multi-output (MIMO) combined with orthogonal time frequency space (OTFS) modulation has emerged as a promising technique for high-mobility scenarios. However, its performance could be severely degraded due to channel aging caused by user mobility and high processing latency. In this paper, an integrated scheme of uplink (UL) channel estimation and downlink (DL) channel prediction is proposed to alleviate channel aging in time division duplex (TDD) massive MIMO-OTFS systems. Specifically, first, an iterative basis expansion model (BEM) based UL channel estimation scheme is proposed to accurately estimate UL channels with the aid of carefully designed OTFS frame pattern. Then a set of Slepian sequences are used to model the estimated UL channels, and the dynamic Slepian coefficients are fitted by a set of orthogonal polynomials. A channel predictor is derived to predict DL channels by iteratively extrapolating the Slepian coefficients. Simulation results verify that the proposed UL channel estimation and DL channel prediction schemes outperform the existing schemes in terms of normalized mean square error of channel estimation/prediction and DL spectral efficiency, with less pilot overhead.
DMRS-Based Uplink Channel Estimation for MU-MIMO Systems with Location-Specific SCSI Acquisition
Jun 13, 2025With the growing number of users in multi-user multiple-input multiple-output (MU-MIMO) systems, demodulation reference signals (DMRSs) are efficiently multiplexed in the code domain via orthogonal cover codes (OCC) to ensure orthogonality and minimize pilot interference. In this paper, we investigate uplink DMRS-based channel estimation for MU-MIMO systems with Type II OCC pattern standardized in 3GPP Release 18, leveraging location-specific statistical channel state information (SCSI) to enhance performance. Specifically, we propose a SCSI-assisted Bayesian channel estimator (SA-BCE) based on the minimum mean square error criterion to suppress the pilot interference and noise, albeit at the cost of cubic computational complexity due to matrix inversions. To reduce this complexity while maintaining performance, we extend the scheme to a windowed version (SA-WBCE), which incorporates antenna-frequency domain windowing and beam-delay domain processing to exploit asymptotic sparsity and mitigate energy leakage in practical systems. To avoid the frequent real-time SCSI acquisition, we construct a grid-based location-specific SCSI database based on the principle of spatial consistency, and subsequently leverage the uplink received signals within each grid to extract the SCSI. Facilitated by the multilinear structure of wireless channels, we formulate the SCSI acquisition problem within each grid as a tensor decomposition problem, where the factor matrices are parameterized by the multi-path powers, delays, and angles. The computational complexity of SCSI acquisition can be significantly reduced by exploiting the Vandermonde structure of the factor matrices. Simulation results demonstrate that the proposed location-specific SCSI database construction method achieves high accuracy, while the SA-BCE and SA-WBCE significantly outperform state-of-the-art benchmarks in MU-MIMO systems.
Bayesian Deep End-to-End Learning for MIMO-OFDM System with Delay-Domain Sparse Precoder
Apr 29, 2025This paper introduces a novel precoder design aimed at reducing pilot overhead for effective channel estimation in multiple-input multiple-output orthogonal frequency division multiplexing (MIMO-OFDM) applications utilizing high-order modulation. We propose an innovative demodulation reference signal scheme that achieves up to an 8x reduction in overhead by implementing a delay-domain sparsity constraint on the precoder. Furthermore, we present a deep neural network (DNN)-based end-to-end architecture that integrates a propagation channel estimation module, a precoder design module, and an effective channel estimation module. Additionally, we propose a Bayesian model-assisted training framework that incorporates domain knowledge, resulting in an interpretable datapath design. Simulation results demonstrate that our proposed solution significantly outperforms various baseline schemes while exhibiting substantially lower computational complexity.
Joint Mode Selection and Beamforming Designs for Hybrid-RIS Assisted ISAC Systems
Dec 05, 2024



This paper considers a hybrid reconfigurable intelligent surface (RIS) assisted integrated sensing and communication (ISAC) system, where each RIS element can flexibly switch between the active and passive modes. Subject to the signal-to-interference-plus-noise ratio (SINR) constraint for each communication user (CU) and the transmit power constraints for both the base station (BS) and the active RIS elements, with the objective of maximizing the minimum beampattern gain among multiple targets, we jointly optimize the BS transmit beamforming for ISAC and the mode selection of each RIS reflecting element, as well as the RIS reflection coefficient matrix. Such formulated joint hybrid-RIS assisted ISAC design problem is a mixed-integer nonlinear program, which is decomposed into two low-dimensional subproblems being solved in an alternating manner. Specifically, by using the semidefinite relaxation (SDR) technique along with the rank-one beamforming construction process, we efficiently obtain the optimal ISAC transmit beamforming design at the BS. Via the SDR and successive convex approximation (SCA) techniques, we jointly determine the active/passive mode selection and reflection coefficient for each RIS element. Numerical results demonstrate that the proposed design solution is significantly superior to the existing baseline solutions.
Bayesian Federated Model Compression for Communication and Computation Efficiency
Apr 11, 2024In this paper, we investigate Bayesian model compression in federated learning (FL) to construct sparse models that can achieve both communication and computation efficiencies. We propose a decentralized Turbo variational Bayesian inference (D-Turbo-VBI) FL framework where we firstly propose a hierarchical sparse prior to promote a clustered sparse structure in the weight matrix. Then, by carefully integrating message passing and VBI with a decentralized turbo framework, we propose the D-Turbo-VBI algorithm which can (i) reduce both upstream and downstream communication overhead during federated training, and (ii) reduce the computational complexity during local inference. Additionally, we establish the convergence property for thr proposed D-Turbo-VBI algorithm. Simulation results show the significant gain of our proposed algorithm over the baselines in reducing communication overhead during federated training and computational complexity of final model.
A unified framework for STAR-RIS coefficients optimization
Oct 13, 2023Simultaneously transmitting and reflecting (STAR) reconfigurable intelligent surface (RIS), which serves users located on both sides of the surface, has recently emerged as a promising enhancement to the traditional reflective only RIS. Due to the lack of a unified comparison of communication systems equipped with different modes of STAR-RIS and the performance degradation caused by the constraints involving discrete selection, this paper proposes a unified optimization framework for handling the STAR-RIS operating mode and discrete phase constraints. With a judiciously introduced penalty term, this framework transforms the original problem into two iterative subproblems, with one containing the selection-type constraints, and the other subproblem handling other wireless resource. Convergent point of the whole algorithm is found to be at least a stationary point under mild conditions. As an illustrative example, the proposed framework is applied to a sum-rate maximization problem in the downlink transmission. Simulation results show that the algorithms from the proposed framework outperform other existing algorithms tailored for different STAR-RIS scenarios. Furthermore, it is found that 4 or even 2 discrete phases STAR-RIS could achieve almost the same sum-rate performance as the continuous phase setting, showing for the first time that discrete phase is not necessarily a cause of significant performance degradation.
Structured Bayesian Compression for Deep Neural Networks Based on The Turbo-VBI Approach
Feb 21, 2023



With the growth of neural network size, model compression has attracted increasing interest in recent research. As one of the most common techniques, pruning has been studied for a long time. By exploiting the structured sparsity of the neural network, existing methods can prune neurons instead of individual weights. However, in most existing pruning methods, surviving neurons are randomly connected in the neural network without any structure, and the non-zero weights within each neuron are also randomly distributed. Such irregular sparse structure can cause very high control overhead and irregular memory access for the hardware and even increase the neural network computational complexity. In this paper, we propose a three-layer hierarchical prior to promote a more regular sparse structure during pruning. The proposed three-layer hierarchical prior can achieve per-neuron weight-level structured sparsity and neuron-level structured sparsity. We derive an efficient Turbo-variational Bayesian inferencing (Turbo-VBI) algorithm to solve the resulting model compression problem with the proposed prior. The proposed Turbo-VBI algorithm has low complexity and can support more general priors than existing model compression algorithms. Simulation results show that our proposed algorithm can promote a more regular structure in the pruned neural networks while achieving even better performance in terms of compression rate and inferencing accuracy compared with the baselines.