 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Overview of AI and Communication for 6G Network: Fundamentals, Challenges, and Future Research Opportunities
Dec 19, 2024



With the increasing demand for seamless connectivity and intelligent communication, the integration of artificial intelligence (AI) and communication for sixth-generation (6G) network is emerging as a revolutionary architecture. This paper presents a comprehensive overview of AI and communication for 6G networks, emphasizing their foundational principles, inherent challenges, and future research opportunities. We commence with a retrospective analysis of AI and the evolution of large-scale AI models, underscoring their pivotal roles in shaping contemporary communication technologies. The discourse then transitions to a detailed exposition of the envisioned integration of AI within 6G networks, delineated across three progressive developmental stages. The initial stage, AI for Network, focuses on employing AI to augment network performance, optimize efficiency, and enhance user service experiences. The subsequent stage, Network for AI, highlights the role of the network in facilitating and buttressing AI operations and presents key enabling technologies, including digital twins for AI and semantic communication. In the final stage, AI as a Service, it is anticipated that future 6G networks will innately provide AI functions as services and support application scenarios like immersive communication and intelligent industrial robots. Specifically, we have defined the quality of AI service, which refers to the measurement framework system of AI services within the network. In addition to these developmental stages, we thoroughly examine the standardization processes pertinent to AI in network contexts, highlighting key milestones and ongoing efforts. Finally, we outline promising future research opportunities that could drive the evolution and refinement of AI and communication for 6G, positioning them as a cornerstone of next-generation communication infrastructure.
A Peaceman-Rachford Splitting Approach with Deep Equilibrium Network for Channel Estimation
Oct 31, 2024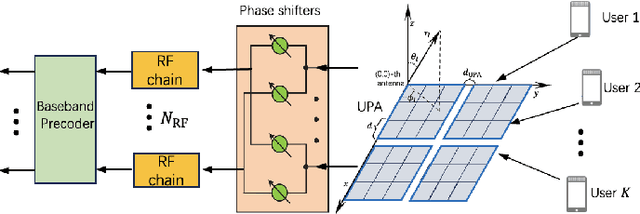

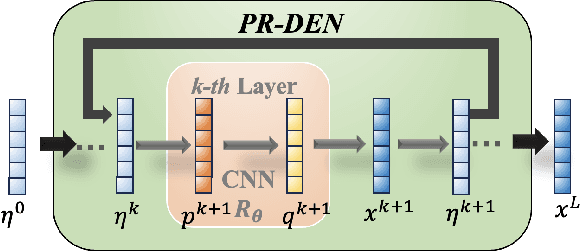
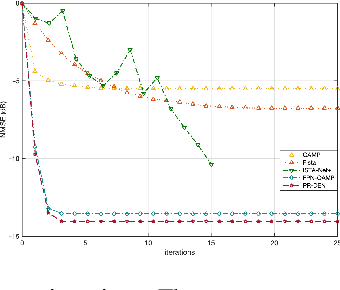
Multiple-input multiple-output (MIMO) is pivotal for wireless systems, yet its high-dimensional, stochastic channel poses significant challenges for accurate estimation, highlighting the critical need for robust estimation techniques. In this paper, we introduce a novel channel estimation method for the MIMO system. The main idea is to construct a fixed-point equation for channel estimation, which can be implemented into the deep equilibrium (DEQ) model with a fixed network. Specifically, the Peaceman-Rachford (PR) splitting method is applied to the dual form of the regularized minimization problem to construct fixed-point equation with non-expansive property. Then, the fixed-point equation is implemented into the DEQ model with a fixed layer, leveraging its advantage of the low training complexity. Moreover, we provide a rigorous theoretical analysis, demonstrating the convergence and optimality of our approach. Additionally, simulations of hybrid far- and near-field channels demonstrate that our approach yields favorable results, indicating its ability to advance channel estimation in MIMO system.
Snake Learning: A Communication- and Computation-Efficient Distributed Learning Framework for 6G
May 06, 2024



In the evolution towards 6G, integrating Artificial Intelligence (AI) with advanced network infrastructure emerges as a pivotal strategy for enhancing network intelligence and resource utilization. Existing distributed learning frameworks like Federated Learning and Split Learning often struggle with significant challenges in dynamic network environments including high synchronization demands, costly communication overheads, severe computing resource consumption, and data heterogeneity across network nodes. These obstacles hinder the applications of ubiquitous computing capabilities of 6G networks, especially in light of the trend of escalating model parameters and training data volumes. To address these challenges effectively, this paper introduces "Snake Learning", a cost-effective distributed learning framework. Specifically, Snake Learning respects the heterogeneity of inter-node computing capability and local data distribution in 6G networks, and sequentially trains the designated part of model layers on individual nodes. This layer-by-layer serpentine update mechanism contributes to significantly reducing the requirements for storage, memory and communication during the model training phase, and demonstrates superior adaptability and efficiency for both Computer Vision (CV) training and Large Language Model (LLM) fine-tuning tasks across homogeneous and heterogeneous data distributions.
Learning Channel Capacity with Neural Mutual Information Estimator Based on Message Importance Measure
Dec 04, 2023Channel capacity estimation plays a crucial role in beyond 5G intelligent communications. Despite its significance, this task is challenging for a majority of channels, especially for the complex channels not modeled as the well-known typical ones. Recently, neural networks have been used in mutual information estimation and optimization. They are particularly considered as efficient tools for learning channel capacity. In this paper, we propose a cooperative framework to simultaneously estimate channel capacity and design the optimal codebook. First, we will leverage MIM-based GAN, a novel form of generative adversarial network (GAN) using message importance measure (MIM) as the information distance, into mutual information estimation, and develop a novel method, named MIM-based mutual information estimator (MMIE). Then, we design a generalized cooperative framework for channel capacity learning, in which a generator is regarded as an encoder producing the channel input, while a discriminator is the mutual information estimator that assesses the performance of the generator. Through the adversarial training, the generator automatically learns the optimal codebook and the discriminator estimates the channel capacity. Numerical experiments will demonstrate that compared with several conventional estimators, the MMIE achieves state-of-the-art performance in terms of accuracy and stability.
NetGPT: A Native-AI Network Architecture Beyond Provisioning Personalized Generative Services
Jul 23, 2023



Large language models (LLMs) have triggered tremendous success to empower daily life by generative information, and the personalization of LLMs could further contribute to their applications due to better alignment with human intents. Towards personalized generative services, a collaborative cloud-edge methodology sounds promising, as it facilitates the effective orchestration of heterogeneous distributed communication and computing resources. In this article, after discussing the pros and cons of several candidate cloud-edge collaboration techniques, we put forward NetGPT to capably deploy appropriate LLMs at the edge and the cloud in accordance with their computing capacity. In addition, edge LLMs could efficiently leverage location-based information for personalized prompt completion, thus benefiting the interaction with cloud LLMs. After deploying representative open-source LLMs (e.g., GPT-2-base and LLaMA model) at the edge and the cloud, we present the feasibility of NetGPT on the basis of low-rank adaptation-based light-weight fine-tuning. Subsequently, we highlight substantial essential changes required for a native artificial intelligence (AI) network architecture towards NetGPT, with special emphasis on deeper integration of communications and computing resources and careful calibration of logical AI workflow. Furthermore, we demonstrate several by-product benefits of NetGPT, given edge LLM's astonishing capability to predict trends and infer intents, which possibly leads to a unified solution for intelligent network management \& orchestration. In a nutshell, we argue that NetGPT is a promising native-AI network architecture beyond provisioning personalized generative services.
RHFedMTL: Resource-Aware Hierarchical Federated Multi-Task Learning
Jun 01, 2023The rapid development of artificial intelligence (AI) over massive applications including Internet-of-things on cellular network raises the concern of technical challenges such as privacy, heterogeneity and resource efficiency. Federated learning is an effective way to enable AI over massive distributed nodes with security. However, conventional works mostly focus on learning a single global model for a unique task across the network, and are generally less competent to handle multi-task learning (MTL) scenarios with stragglers at the expense of acceptable computation and communication cost. Meanwhile, it is challenging to ensure the privacy while maintain a coupled multi-task learning across multiple base stations (BSs) and terminals. In this paper, inspired by the natural cloud-BS-terminal hierarchy of cellular works, we provide a viable resource-aware hierarchical federated MTL (RHFedMTL) solution to meet the heterogeneity of tasks, by solving different tasks within the BSs and aggregating the multi-task result in the cloud without compromising the privacy. Specifically, a primal-dual method has been leveraged to effectively transform the coupled MTL into some local optimization sub-problems within BSs. Furthermore, compared with existing methods to reduce resource cost by simply changing the aggregation frequency, we dive into the intricate relationship between resource consumption and learning accuracy, and develop a resource-aware learning strategy for local terminals and BSs to meet the resource budget. Extensive simulation results demonstrate the effectiveness and superiority of RHFedMTL in terms of improving the learning accuracy and boosting the convergence rate.
FedNC: A Secure and Efficient Federated Learning Method Inspired by Network Coding
May 05, 2023



Federated Learning (FL) is a promising distributed learning mechanism which still faces two major challenges, namely privacy breaches and system efficiency. In this work, we reconceptualize the FL system from the perspective of network information theory, and formulate an original FL communication framework, FedNC, which is inspired by Network Coding (NC). The main idea of FedNC is mixing the information of the local models by making random linear combinations of the original packets, before uploading for further aggregation. Due to the benefits of the coding scheme, both theoretical and experimental analysis indicate that FedNC improves the performance of traditional FL in several important ways, including security, throughput, and robustness. To the best of our knowledge, this is the first framework where NC is introduced in FL. As FL continues to evolve within practical network frameworks, more applications and variants can be further designed based on FedNC.
FedLP: Layer-wise Pruning Mechanism for Communication-Computation Efficient Federated Learning
Mar 11, 2023



Federated learning (FL) has prevailed as an efficient and privacy-preserved scheme for distributed learning. In this work, we mainly focus on the optimization of computation and communication in FL from a view of pruning. By adopting layer-wise pruning in local training and federated updating, we formulate an explicit FL pruning framework, FedLP (Federated Layer-wise Pruning), which is model-agnostic and universal for different types of deep learning models. Two specific schemes of FedLP are designed for scenarios with homogeneous local models and heterogeneous ones. Both theoretical and experimental evaluations are developed to verify that FedLP relieves the system bottlenecks of communication and computation with marginal performance decay. To the best of our knowledge, FedLP is the first framework that formally introduces the layer-wise pruning into FL. Within the scope of federated learning, more variants and combinations can be further designed based on FedLP.
ISFL: Trustworthy Federated Learning for Non-i.i.d. Data with Local Importance Sampling
Oct 05, 2022
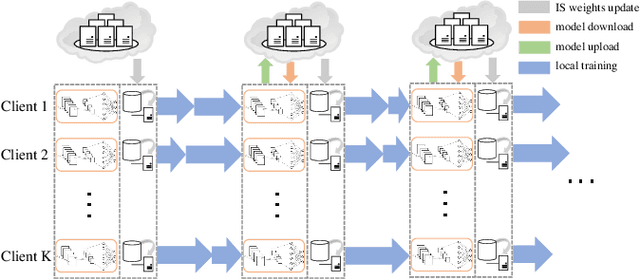
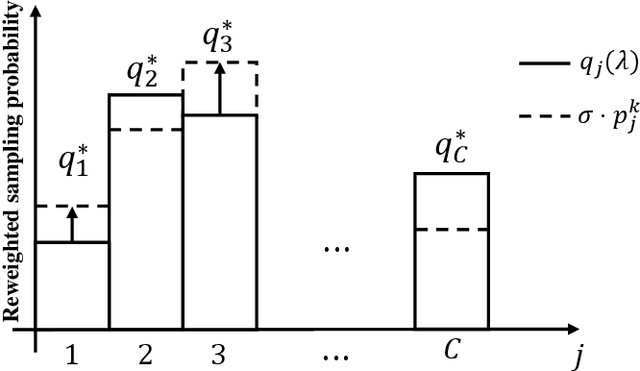
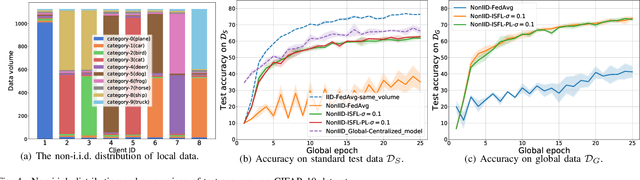
As a promising integrated computation and communication learning paradigm, federated learning (FL) carries a periodic sharing from distributed clients. Due to the non-i.i.d. data distribution on clients, FL model suffers from the gradient diversity, poor performance, bad convergence, etc. In this work, we aim to tackle this key issue by adopting data-driven importance sampling (IS) for local training. We propose a trustworthy framework, named importance sampling federated learning (ISFL), which is especially compatible with neural network (NN) models. The framework is evaluated both theoretically and experimentally. Firstly, we derive the parameter deviation bound between ISFL and the centralized full-data training to identify the main factors of the non-i.i.d. dilemmas. We will then formulate the selection of optimal IS weights as an optimization problem and obtain theoretical solutions. We also employ water-filling methods to calculate the IS weights and develop the complete ISFL algorithms. The experimental results on CIFAR-10 fit our proposed theories well and prove that ISFL reaps higher performance, as well as better convergence on non-i.i.d. data. To the best of our knowledge, ISFL is the first non-i.i.d. FL solution from the local sampling aspect which exhibits theoretical NN compatibility. Furthermore, as a local sampling approach, ISFL can be easily migrated into emerging FL frameworks.