 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Social Acceptance of eXtended Reality (XR) Agent Technology: A User Study (Extended Version)
Jul 22, 2025In this paper, we present the findings of a user study that evaluated the social acceptance of eXtended Reality (XR) agent technology, focusing on a remotely accessible, web-based XR training system developed for journalists. This system involves user interaction with a virtual avatar, enabled by a modular toolkit. The interactions are designed to provide tailored training for journalists in digital-remote settings, especially for sensitive or dangerous scenarios, without requiring specialized end-user equipment like headsets. Our research adapts and extends the Almere model, representing social acceptance through existing attributes such as perceived ease of use and perceived usefulness, along with added ones like dependability and security in the user-agent interaction. The XR agent was tested through a controlled experiment in a real-world setting, with data collected on users' perceptions. Our findings, based on quantitative and qualitative measurements involving questionnaires, contribute to the understanding of user perceptions and acceptance of XR agent solutions within a specific social context, while also identifying areas for the improvement of XR systems.
Systematic analysis of requirements for socially acceptable service robots
Sep 13, 2024In modern society, service robots are increasingly recognized for their wide range of practical applications. In large and crowded social spaces, such as museums and hospitals, these robots are required to safely move in the environment while exhibiting user-friendly behavior. Ensuring the safe and socially acceptable operation of robots in such settings presents several challenges. To enhance the social acceptance in the design process of service robots, we present a systematic analysis of requirements, categorized into functional and non-functional. These requirements are further classified into different categories, with a single requirement potentially belonging to multiple categories. Finally, considering the specific case of a receptionist robotic agent, we discuss the requirements it should possess to ensure social acceptance.
Self-Supervised Prediction of the Intention to Interact with a Service Robot
Sep 14, 2023



A service robot can provide a smoother interaction experience if it has the ability to proactively detect whether a nearby user intends to interact, in order to adapt its behavior e.g. by explicitly showing that it is available to provide a service. In this work, we propose a learning-based approach to predict the probability that a human user will interact with a robot before the interaction actually begins; the approach is self-supervised because after each encounter with a human, the robot can automatically label it depending on whether it resulted in an interaction or not. We explore different classification approaches, using different sets of features considering the pose and the motion of the user. We validate and deploy the approach in three scenarios. The first collects $3442$ natural sequences (both interacting and non-interacting) representing employees in an office break area: a real-world, challenging setting, where we consider a coffee machine in place of a service robot. The other two scenarios represent researchers interacting with service robots ($200$ and $72$ sequences, respectively). Results show that, even in challenging real-world settings, our approach can learn without external supervision, and can achieve accurate classification (i.e. AUROC greater than $0.9$) of the user's intention to interact with an advance of more than $3$s before the interaction actually occurs.
GROWL: Group Detection With Link Prediction
Nov 08, 2021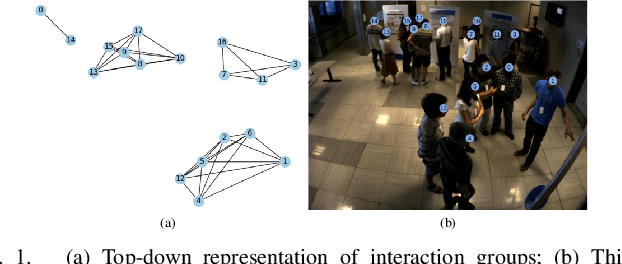
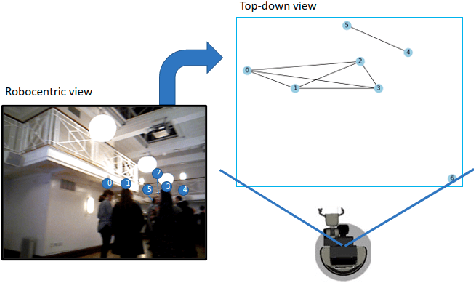
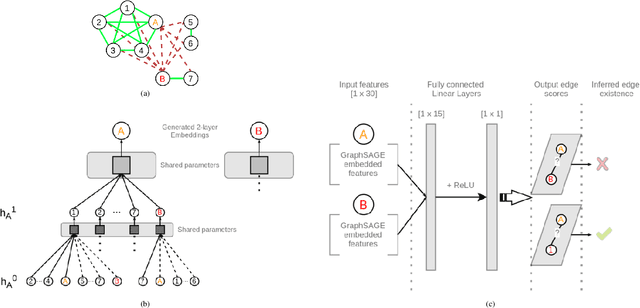
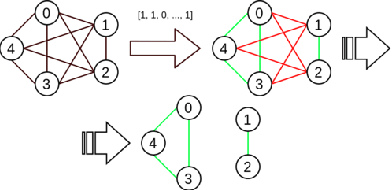
Interaction group detection has been previously addressed with bottom-up approaches which relied on the position and orientation information of individuals. These approaches were primarily based on pairwise affinity matrices and were limited to static, third-person views. This problem can greatly benefit from a holistic approach based on Graph Neural Networks (GNNs) beyond pairwise relationships, due to the inherent spatial configuration that exists between individuals who form interaction groups. Our proposed method, GROup detection With Link prediction (GROWL), demonstrates the effectiveness of a GNN based approach. GROWL predicts the link between two individuals by generating a feature embedding based on their neighbourhood in the graph and determines whether they are connected with a shallow binary classification method such as Multi-layer Perceptrons (MLPs). We test our method against other state-of-the-art group detection approaches on both a third-person view dataset and a robocentric (i.e., egocentric) dataset. In addition, we propose a multimodal approach based on RGB and depth data to calculate a representation GROWL can utilise as input. Our results show that a GNN based approach can significantly improve accuracy across different camera views, i.e., third-person and egocentric views.