 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Visual Semantic Reasoning: Multi-Stage Decoder for Text Recognition
Jul 27, 2021
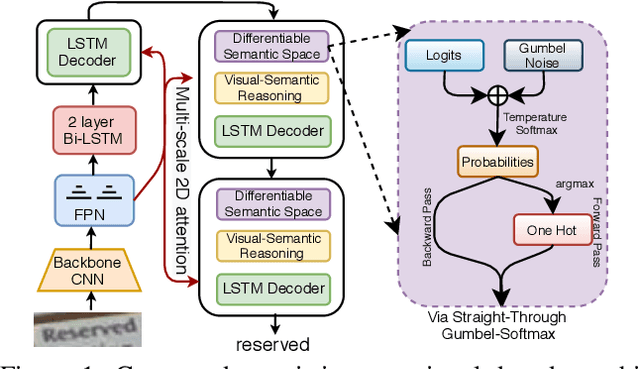
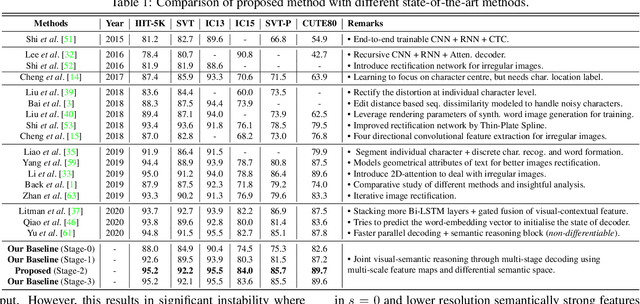
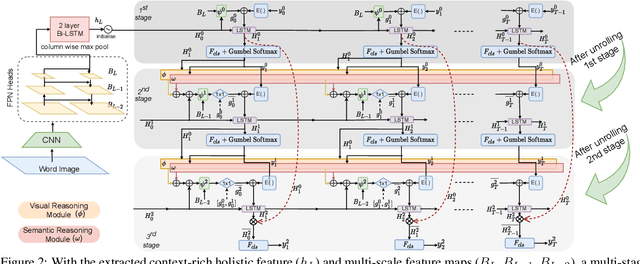
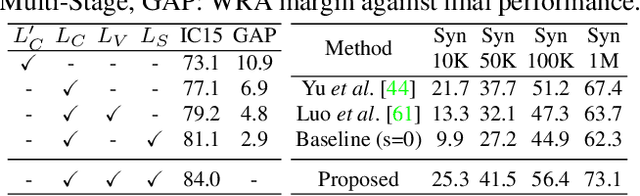
Although text recognition has significantly evolved over the years, state-of-the-art (SOTA) models still struggle in the wild scenarios due to complex backgrounds, varying fonts, uncontrolled illuminations, distortions and other artefacts. This is because such models solely depend on visual information for text recognition, thus lacking semantic reasoning capabilities. In this paper, we argue that semantic information offers a complementary role in addition to visual only. More specifically, we additionally utilize semantic information by proposing a multi-stage multi-scale attentional decoder that performs joint visual-semantic reasoning. Our novelty lies in the intuition that for text recognition, the prediction should be refined in a stage-wise manner. Therefore our key contribution is in designing a stage-wise unrolling attentional decoder where non-differentiability, invoked by discretely predicted character labels, needs to be bypassed for end-to-end training. While the first stage predicts using visual features, subsequent stages refine on top of it using joint visual-semantic information. Additionally, we introduce multi-scale 2D attention along with dense and residual connections between different stages to deal with varying scales of character sizes, for better performance and faster convergence during training. Experimental results show our approach to outperform existing SOTA methods by a considerable margin.
An Overview of Computer Supported Query Formulation
May 19, 2021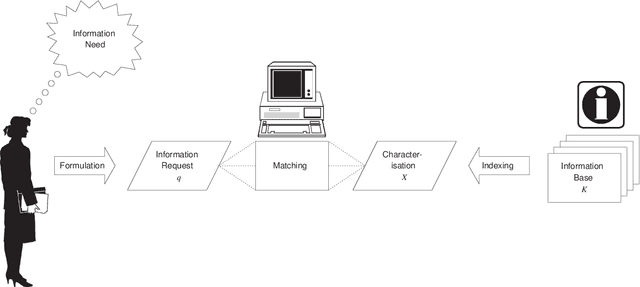
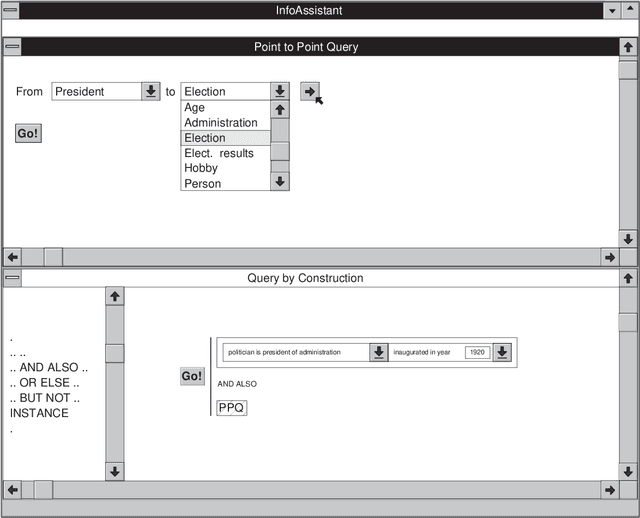
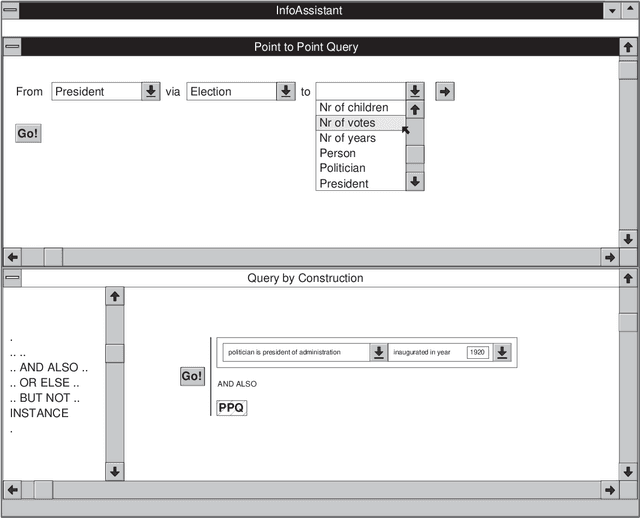
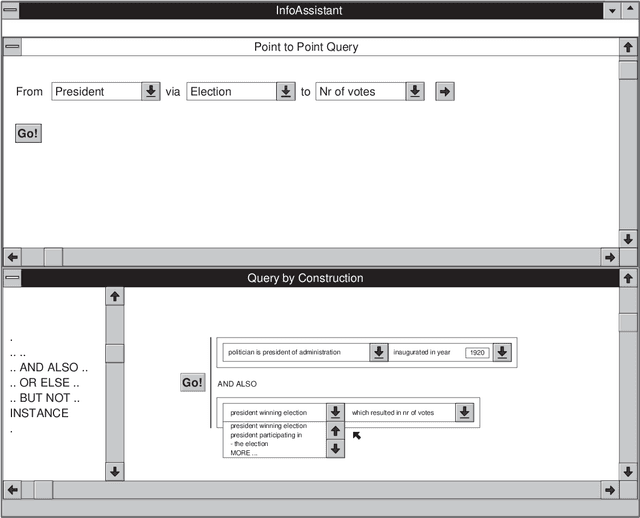
Most present day organisations make use of some automated information system. This usually means that a large body of vital corporate information is stored in these information systems. As a result, an essential function of information systems should be the support of disclosure of this information. We purposely use the term {\em information disclosure} in this context. When using the term information disclosure we envision a computer supported mechanism that allows for an easy and intuitive formulation of queries in a language that is as close to the user's perception of the universe of discourse as possible. From this point of view, it is only obvious that we do not consider a simple query mechanism where users have to enter complex queries manually and look up what information is stored in a set of relational tables. Without a set of adequate information disclosure avenues an information system becomes worthless since there is no use in storing information that will never be retrieved.
MC-SSL0.0: Towards Multi-Concept Self-Supervised Learning
Nov 30, 2021
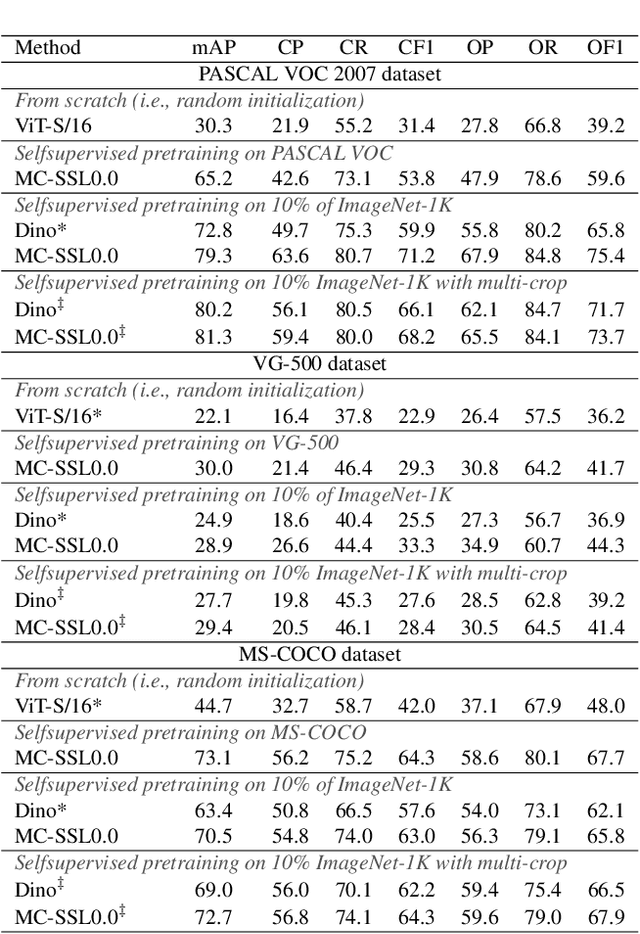
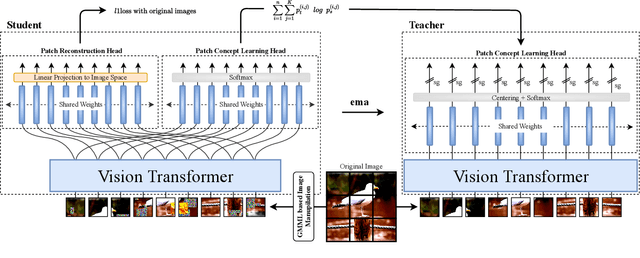
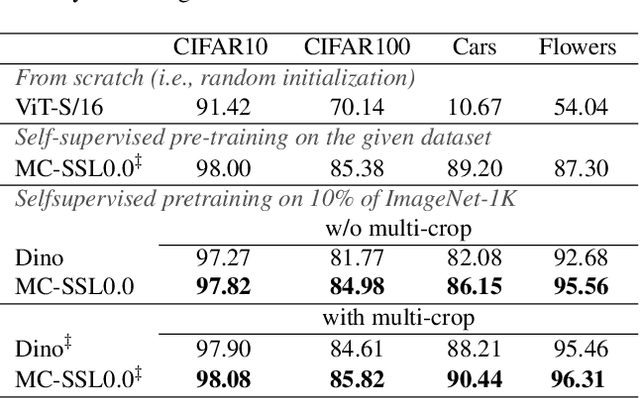
Self-supervised pretraining is the method of choice for natural language processing models and is rapidly gaining popularity in many vision tasks. Recently, self-supervised pretraining has shown to outperform supervised pretraining for many downstream vision applications, marking a milestone in the area. This superiority is attributed to the negative impact of incomplete labelling of the training images, which convey multiple concepts, but are annotated using a single dominant class label. Although Self-Supervised Learning (SSL), in principle, is free of this limitation, the choice of pretext task facilitating SSL is perpetuating this shortcoming by driving the learning process towards a single concept output. This study aims to investigate the possibility of modelling all the concepts present in an image without using labels. In this aspect the proposed SSL frame-work MC-SSL0.0 is a step towards Multi-Concept Self-Supervised Learning (MC-SSL) that goes beyond modelling single dominant label in an image to effectively utilise the information from all the concepts present in it. MC-SSL0.0 consists of two core design concepts, group masked model learning and learning of pseudo-concept for data token using a momentum encoder (teacher-student) framework. The experimental results on multi-label and multi-class image classification downstream tasks demonstrate that MC-SSL0.0 not only surpasses existing SSL methods but also outperforms supervised transfer learning. The source code will be made publicly available for community to train on bigger corpus.
OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication
Sep 17, 2021

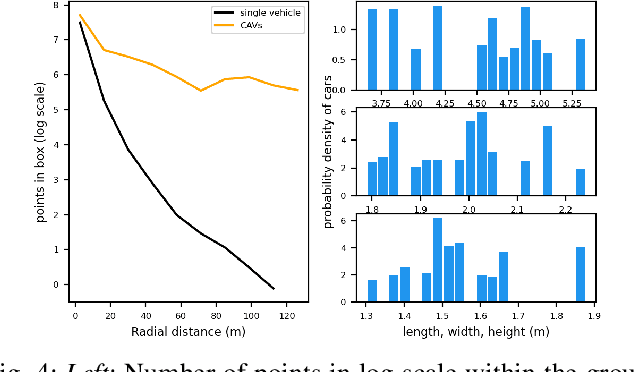
Employing Vehicle-to-Vehicle communication to enhance perception performance in self-driving technology has attracted considerable attention recently; however, the absence of a suitable open dataset for benchmarking algorithms has made it difficult to develop and assess cooperative perception technologies. To this end, we present the first large-scale open simulated dataset for Vehicle-to-Vehicle perception. It contains over 70 interesting scenes, 11,464 frames, and 232,913 annotated 3D vehicle bounding boxes, collected from 8 towns in CARLA and a digital town of Culver City, Los Angeles. We then construct a comprehensive benchmark with a total of 16 implemented models to evaluate several information fusion strategies~(i.e. early, late, and intermediate fusion) with state-of-the-art LiDAR detection algorithms. Moreover, we propose a new Attentive Intermediate Fusion pipeline to aggregate information from multiple connected vehicles. Our experiments show that the proposed pipeline can be easily integrated with existing 3D LiDAR detectors and achieve outstanding performance even with large compression rates. To encourage more researchers to investigate Vehicle-to-Vehicle perception, we will release the dataset, benchmark methods, and all related codes in https://mobility-lab.seas.ucla.edu/opv2v/.
Revisiting Flow Information for Traffic Prediction
Jun 03, 2019
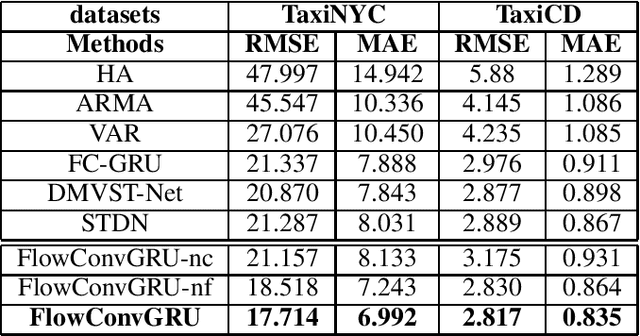
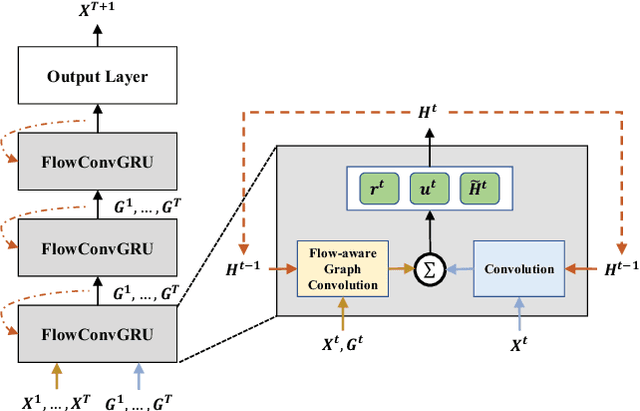
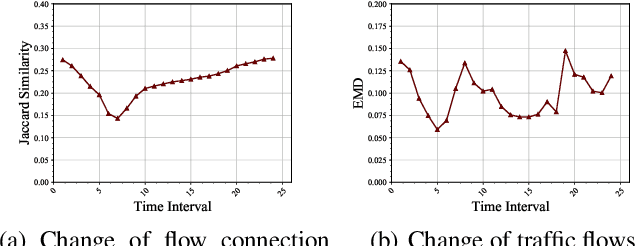
Traffic prediction is a fundamental task in many real applications, which aims to predict the future traffic volume in any region of a city. In essence, traffic volume in a region is the aggregation of traffic flows from/to the region. However, existing traffic prediction methods focus on modeling complex spatiotemporal traffic correlations and seldomly study the influence of the original traffic flows among regions. In this paper, we revisit the traffic flow information and exploit the direct flow correlations among regions towards more accurate traffic prediction. We introduce a novel flow-aware graph convolution to model dynamic flow correlations among regions. We further introduce an integrated Gated Recurrent Unit network to incorporate flow correlations with spatiotemporal modeling. The experimental results on real-world traffic datasets validate the effectiveness of the proposed method, especially on the traffic conditions with a great change on flows.
Learning Transferable Parameters for Unsupervised Domain Adaptation
Aug 13, 2021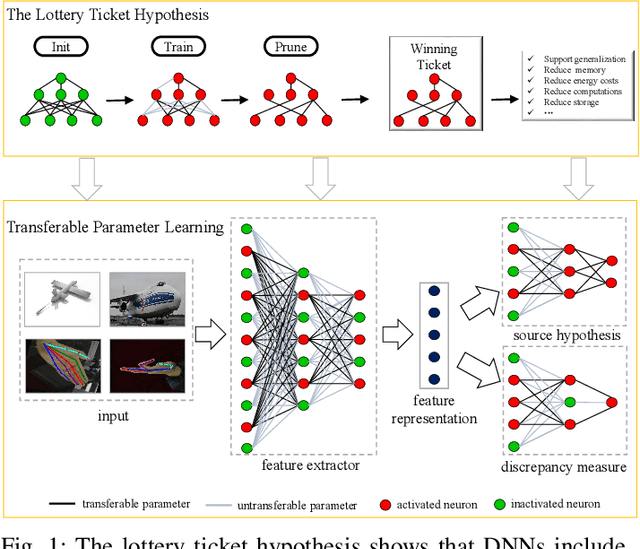

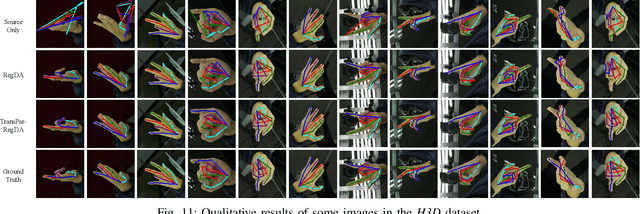

Unsupervised domain adaptation (UDA) enables a learning machine to adapt from a labeled source domain to an unlabeled domain under the distribution shift. Thanks to the strong representation ability of deep neural networks, recent remarkable achievements in UDA resort to learning domain-invariant features. Intuitively, the hope is that a good feature representation, together with the hypothesis learned from the source domain, can generalize well to the target domain. However, the learning processes of domain-invariant features and source hypothesis inevitably involve domain-specific information that would degrade the generalizability of UDA models on the target domain. In this paper, motivated by the lottery ticket hypothesis that only partial parameters are essential for generalization, we find that only partial parameters are essential for learning domain-invariant information and generalizing well in UDA. Such parameters are termed transferable parameters. In contrast, the other parameters tend to fit domain-specific details and often fail to generalize, which we term as untransferable parameters. Driven by this insight, we propose Transferable Parameter Learning (TransPar) to reduce the side effect brought by domain-specific information in the learning process and thus enhance the memorization of domain-invariant information. Specifically, according to the distribution discrepancy degree, we divide all parameters into transferable and untransferable ones in each training iteration. We then perform separate updates rules for the two types of parameters. Extensive experiments on image classification and regression tasks (keypoint detection) show that TransPar outperforms prior arts by non-trivial margins. Moreover, experiments demonstrate that TransPar can be integrated into the most popular deep UDA networks and be easily extended to handle any data distribution shift scenarios.
Accelerated Multi-Modal MR Imaging with Transformers
Jun 29, 2021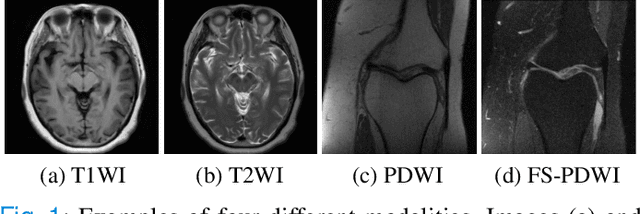
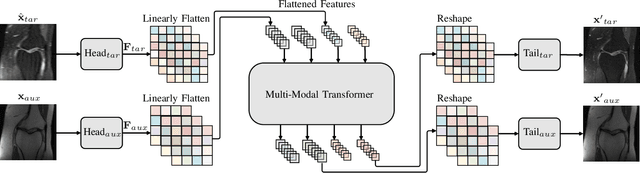
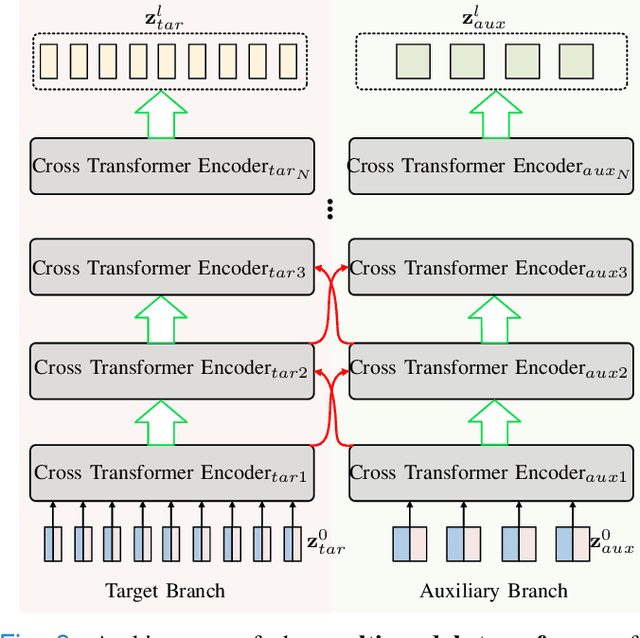
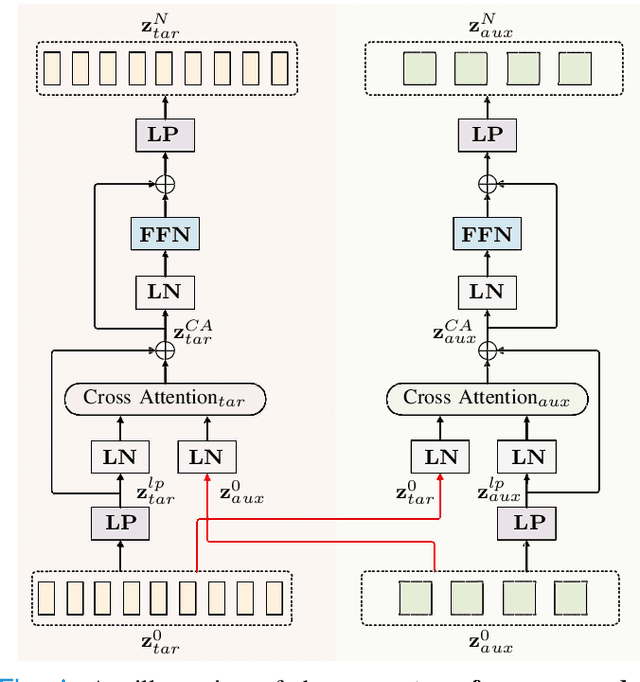
Accelerating multi-modal magnetic resonance (MR) imaging is a new and effective solution for fast MR imaging, providing superior performance in restoring the target modality from its undersampled counterpart with guidance from an auxiliary modality. However, existing works simply introduce the auxiliary modality as prior information, lacking in-depth investigations on the potential mechanisms for fusing two modalities. Further, they usually rely on the convolutional neural networks (CNNs), which focus on local information and prevent them from fully capturing the long-distance dependencies of global knowledge. To this end, we propose a multi-modal transformer (MTrans), which is capable of transferring multi-scale features from the target modality to the auxiliary modality, for accelerated MR imaging. By restructuring the transformer architecture, our MTrans gains a powerful ability to capture deep multi-modal information. More specifically, the target modality and the auxiliary modality are first split into two branches and then fused using a multi-modal transformer module. This module is based on an improved multi-head attention mechanism, named the cross attention module, which absorbs features from the auxiliary modality that contribute to the target modality. Our framework provides two appealing benefits: (i) MTrans is the first attempt at using improved transformers for multi-modal MR imaging, affording more global information compared with CNN-based methods. (ii) A new cross attention module is proposed to exploit the useful information in each branch at different scales. It affords both distinct structural information and subtle pixel-level information, which supplement the target modality effectively.
Deep-Unfolding Beamforming for Intelligent Reflecting Surface assisted Full-Duplex Systems
Dec 04, 2021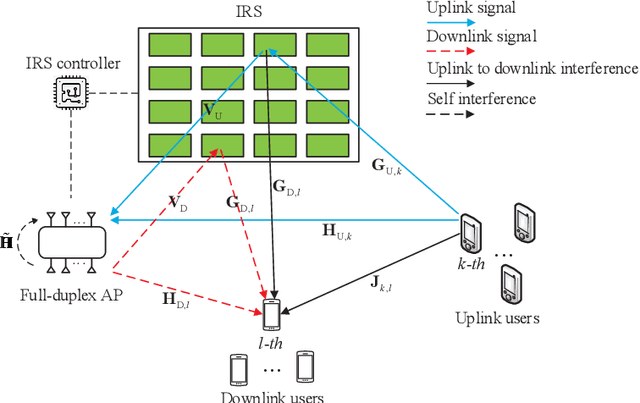
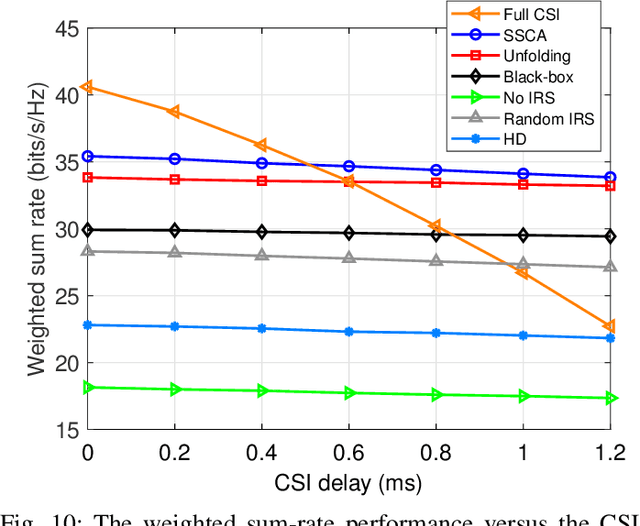
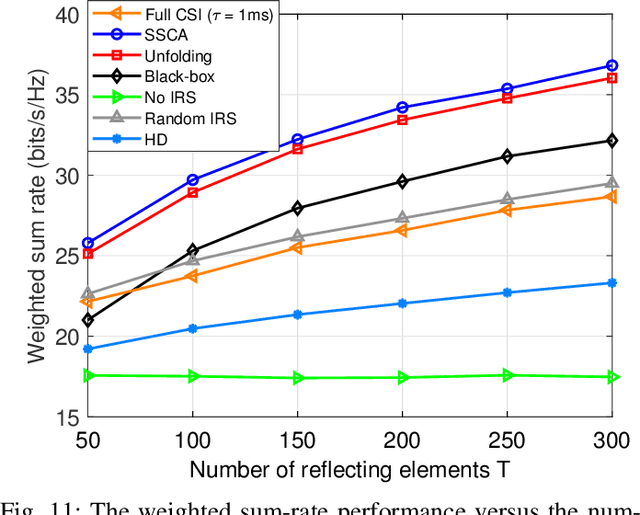
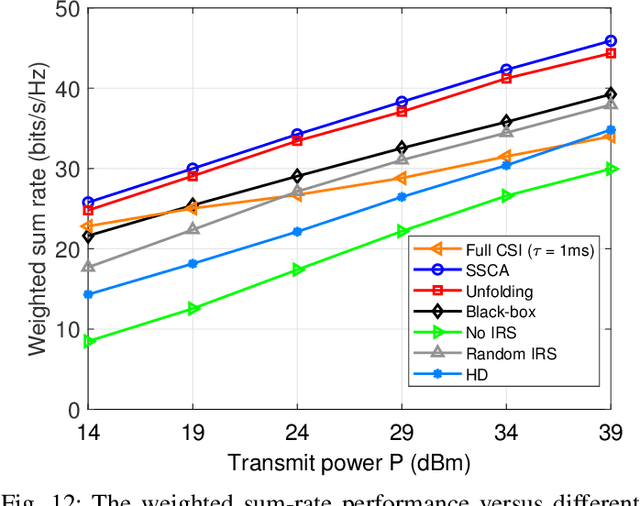
In this paper, we investigate an intelligent reflecting surface (IRS) assisted multi-user multiple-input multiple-output (MIMO) full-duplex (FD) system. We jointly optimize the active beamforming matrices at the access point (AP) and uplink users, and the passive beamforming matrix at the IRS to maximize the weighted sum-rate of the system. Since it is practically difficult to acquire the channel state information (CSI) for IRS-related links due to its passive operation and large number of elements, we conceive a mixed-timescale beamforming scheme. Specifically, the high-dimensional passive beamforming matrix at the IRS is updated based on the channel statistics while the active beamforming matrices are optimized relied on the low-dimensional real-time effective CSI at each time slot. We propose an efficient stochastic successive convex approximation (SSCA)-based algorithm for jointly designing the active and passive beamforming matrices. Moreover, due to the high computational complexity caused by the matrix inversion computation in the SSCA-based optimization algorithm, we further develop a deep-unfolding neural network (NN) to address this issue. The proposed deep-unfolding NN maintains the structure of the SSCA-based algorithm but introduces a novel non-linear activation function and some learnable parameters induced by the first-order Taylor expansion to approximate the matrix inversion. In addition, we develop a black-box NN as a benchmark. Simulation results show that the proposed mixed-timescale algorithm outperforms the existing single-timescale algorithm and the proposed deep-unfolding NN approaches the performance of the SSCA-based algorithm with much reduced computational complexity when deployed online.
Adaptive Neural Message Passing for Inductive Learning on Hypergraphs
Sep 22, 2021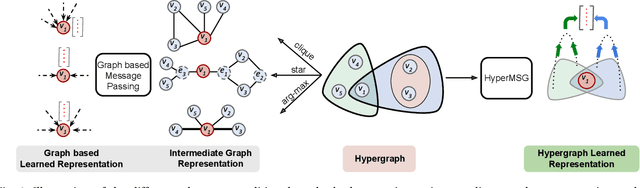
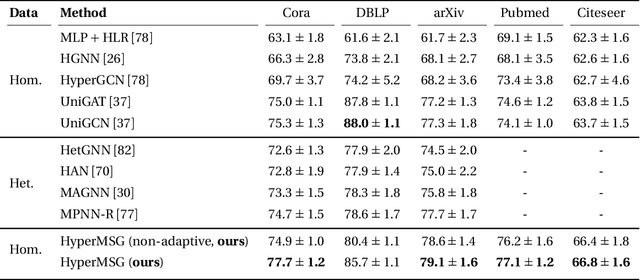
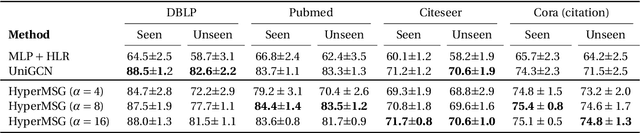
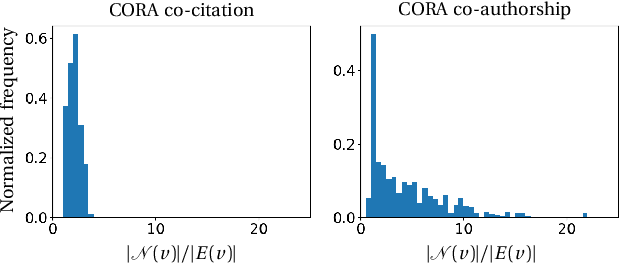
Graphs are the most ubiquitous data structures for representing relational datasets and performing inferences in them. They model, however, only pairwise relations between nodes and are not designed for encoding the higher-order relations. This drawback is mitigated by hypergraphs, in which an edge can connect an arbitrary number of nodes. Most hypergraph learning approaches convert the hypergraph structure to that of a graph and then deploy existing geometric deep learning methods. This transformation leads to information loss, and sub-optimal exploitation of the hypergraph's expressive power. We present HyperMSG, a novel hypergraph learning framework that uses a modular two-level neural message passing strategy to accurately and efficiently propagate information within each hyperedge and across the hyperedges. HyperMSG adapts to the data and task by learning an attention weight associated with each node's degree centrality. Such a mechanism quantifies both local and global importance of a node, capturing the structural properties of a hypergraph. HyperMSG is inductive, allowing inference on previously unseen nodes. Further, it is robust and outperforms state-of-the-art hypergraph learning methods on a wide range of tasks and datasets. Finally, we demonstrate the effectiveness of HyperMSG in learning multimodal relations through detailed experimentation on a challenging multimedia dataset.
MMPTRACK: Large-scale Densely Annotated Multi-camera Multiple People Tracking Benchmark
Nov 30, 2021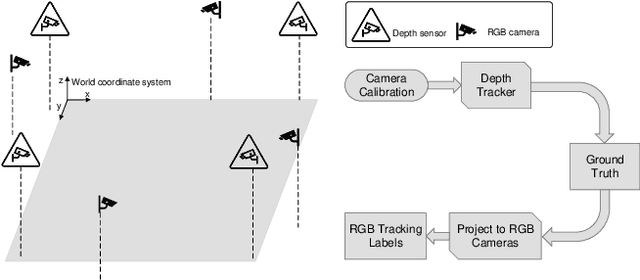
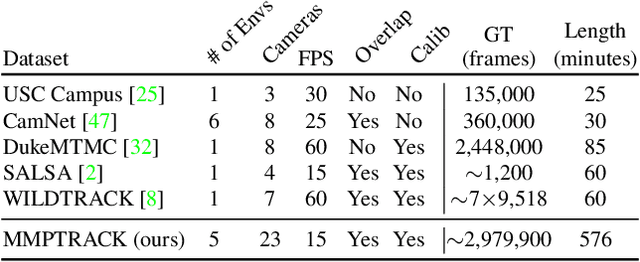

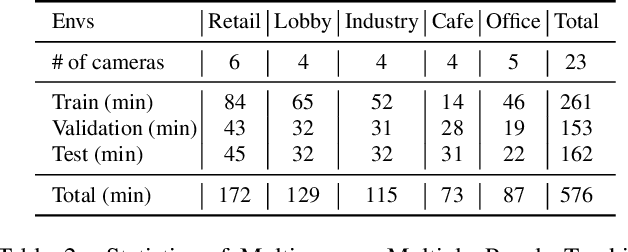
Multi-camera tracking systems are gaining popularity in applications that demand high-quality tracking results, such as frictionless checkout because monocular multi-object tracking (MOT) systems often fail in cluttered and crowded environments due to occlusion. Multiple highly overlapped cameras can significantly alleviate the problem by recovering partial 3D information. However, the cost of creating a high-quality multi-camera tracking dataset with diverse camera settings and backgrounds has limited the dataset scale in this domain. In this paper, we provide a large-scale densely-labeled multi-camera tracking dataset in five different environments with the help of an auto-annotation system. The system uses overlapped and calibrated depth and RGB cameras to build a high-performance 3D tracker that automatically generates the 3D tracking results. The 3D tracking results are projected to each RGB camera view using camera parameters to create 2D tracking results. Then, we manually check and correct the 3D tracking results to ensure the label quality, which is much cheaper than fully manual annotation. We have conducted extensive experiments using two real-time multi-camera trackers and a person re-identification (ReID) model with different settings. This dataset provides a more reliable benchmark of multi-camera, multi-object tracking systems in cluttered and crowded environments. Also, our results demonstrate that adapting the trackers and ReID models on this dataset significantly improves their performance. Our dataset will be publicly released upon the acceptance of this work.