 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Query Formulation using Query By Navigation
May 20, 2021
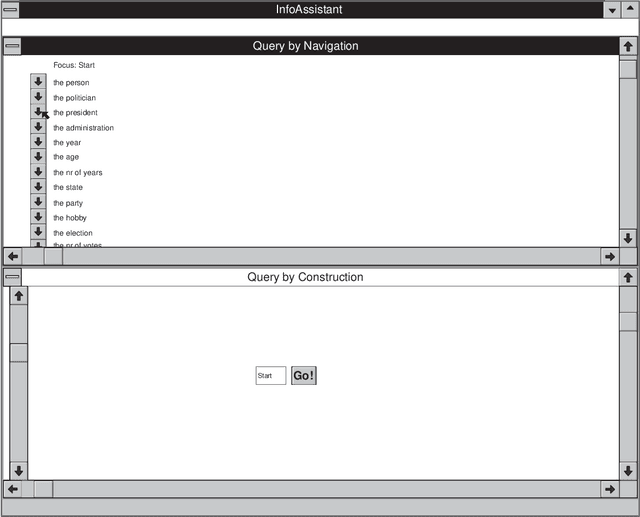


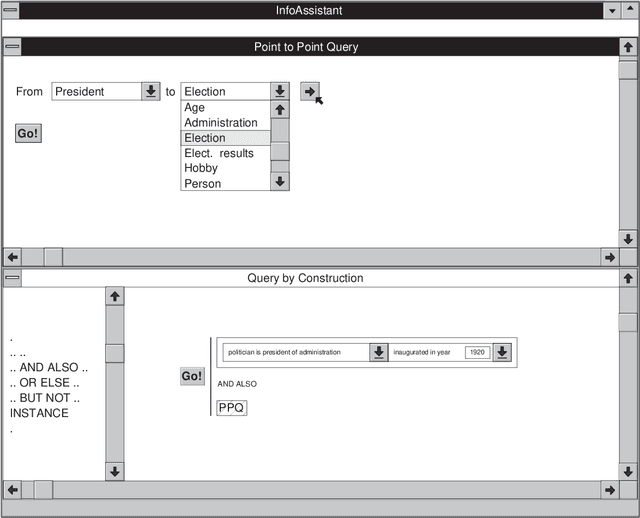
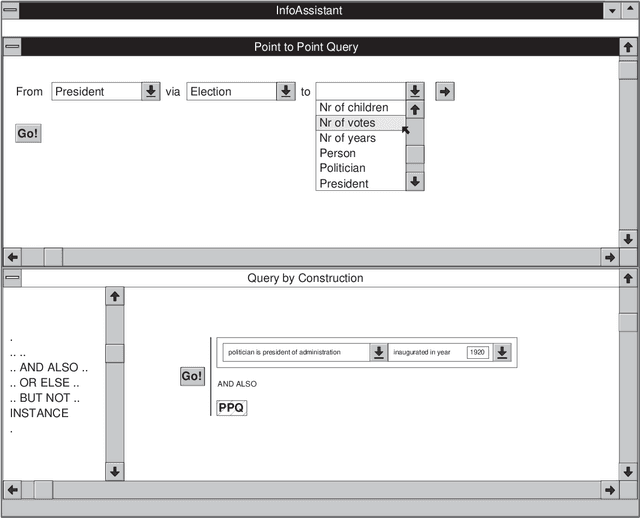
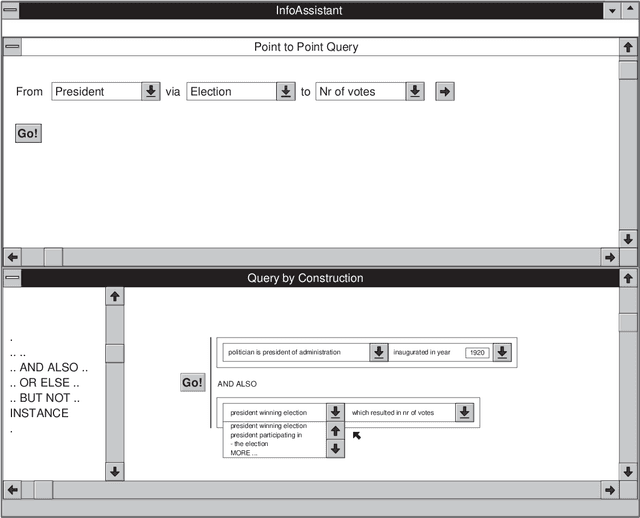
Effective information disclosure in the context of databases with a large conceptual schema is known to be a non-trivial problem. In particular the formulation of ad-hoc queries is a major problem in such contexts. Existing approaches for tackling this problem include graphical query interfaces, query by navigation, query by construction, and point to point queries. In this report we propose an adoption of the query by navigation mechanism that is especially geared towards the InfoAssistant product. Query by navigation is based on ideas from the information retrieval world, in particular on the stratified hypermedia architecture. When using our approach to the formulations of queries, a user will first formulate a number of simple queries corresponding to linear paths through the information structure. The formulation of the linear paths is the result of the {\em explorative phase} of the query formulation. Once users have specified a number of these linear paths, they may combine them to form more complex queries. Examples of such combinations are: concatenation, union, intersection and selection. This last process is referred to as {\em query by construction}, and is the {\em constructive phase} of the query formulation process.
An Overview of Computer Supported Query Formulation
May 19, 2021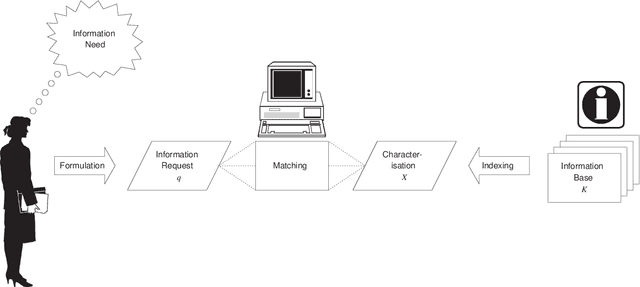
Most present day organisations make use of some automated information system. This usually means that a large body of vital corporate information is stored in these information systems. As a result, an essential function of information systems should be the support of disclosure of this information. We purposely use the term {\em information disclosure} in this context. When using the term information disclosure we envision a computer supported mechanism that allows for an easy and intuitive formulation of queries in a language that is as close to the user's perception of the universe of discourse as possible. From this point of view, it is only obvious that we do not consider a simple query mechanism where users have to enter complex queries manually and look up what information is stored in a set of relational tables. Without a set of adequate information disclosure avenues an information system becomes worthless since there is no use in storing information that will never be retrieved.
Discovering the Information that is lost in our Databases -- Why bother storing data if you can't find the information?
May 18, 2021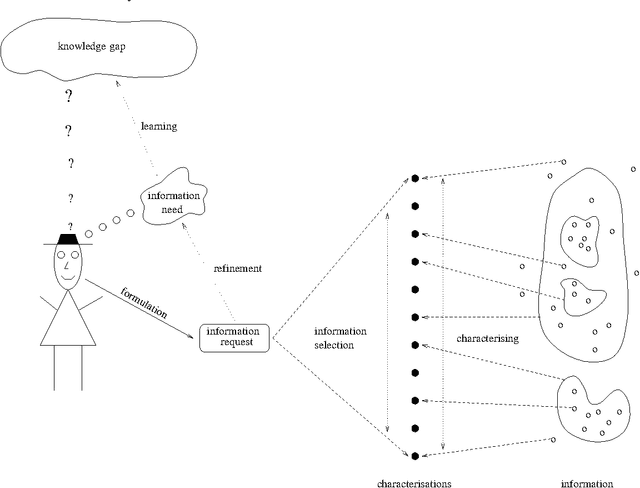
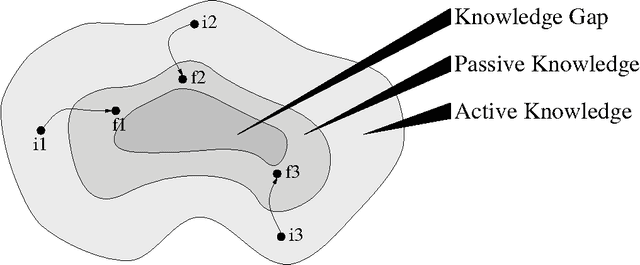
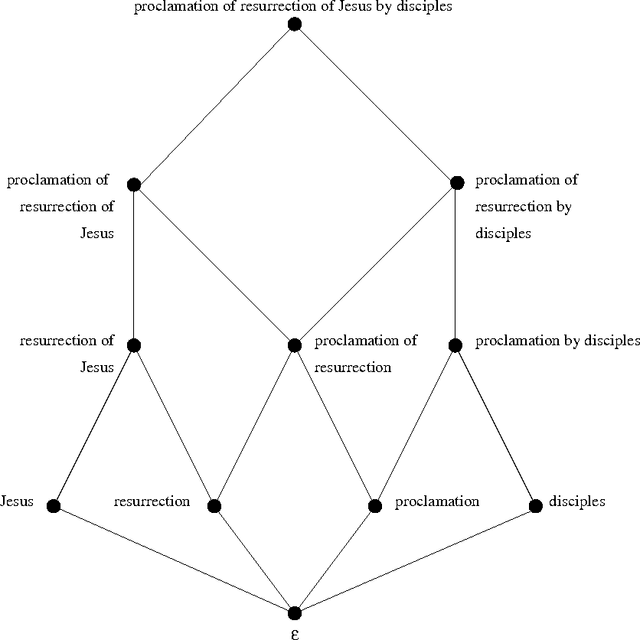
We are surrounded by an ever increasing amount of data that is stored in a variety of databases. In this article we will use a very liberal definition of \EM{database}. Basically any collection of data can be regarded as a database, ranging from the files in a directory on a disk, to ftp and web servers, through to relational or object-oriented databases. The sole reason for storing data in databases is that there is an anticipated need for the stored data at some time in the future. This means that providing smooth access paths by which stored information can be retrieved is at least as important as ensuring integrity of the stored information. In practice, however, providing users with adequate avenues by which to access stored information has received far less attention.
A General Theory for the Evolution of Application Models -- Full version
May 18, 2021



In this article we focus on evolving information systems. First a delimitation of the concept of evolution is provided, resulting in a first attempt to a general theory for such evolutions. The theory makes a distinction between the underlying information structure at the conceptual level, its evolution on the one hand, and the description and semantics of operations on the information structure and its population on the other hand. Main issues within this theory are object typing, type relatedness and identification of objects. In terms of these concepts, we propose some axioms on the well-formedness of evolution. In this general theory, the underlying data model is a parameter, making the theory applicable for a wide range of modelling techniques, including object-role modelling and object oriented techniques.