 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GFlowNet Foundations
Nov 17, 2021
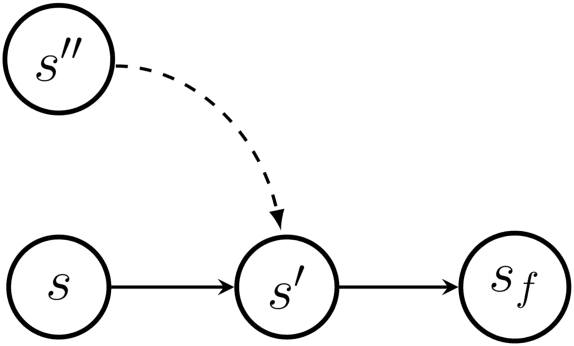
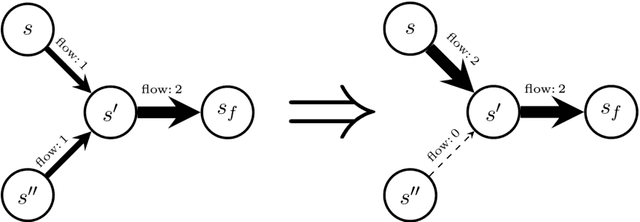
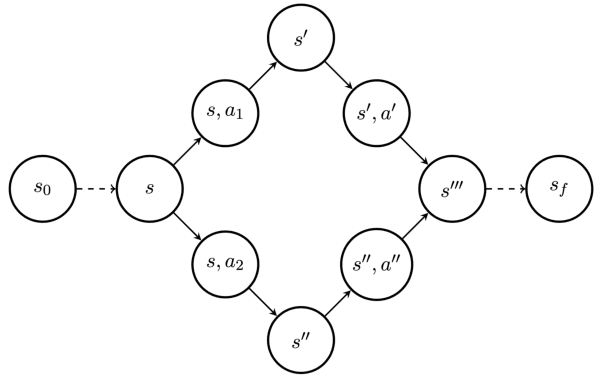
Generative Flow Networks (GFlowNets) have been introduced as a method to sample a diverse set of candidates in an active learning context, with a training objective that makes them approximately sample in proportion to a given reward function. In this paper, we show a number of additional theoretical properties of GFlowNets. They can be used to estimate joint probability distributions and the corresponding marginal distributions where some variables are unspecified and, of particular interest, can represent distributions over composite objects like sets and graphs. GFlowNets amortize the work typically done by computationally expensive MCMC methods in a single but trained generative pass. They could also be used to estimate partition functions and free energies, conditional probabilities of supersets (supergraphs) given a subset (subgraph), as well as marginal distributions over all supersets (supergraphs) of a given set (graph). We introduce variations enabling the estimation of entropy and mutual information, sampling from a Pareto frontier, connections to reward-maximizing policies, and extensions to stochastic environments, continuous actions and modular energy functions.
Supervised Linear Dimension-Reduction Methods: Review, Extensions, and Comparisons
Sep 09, 2021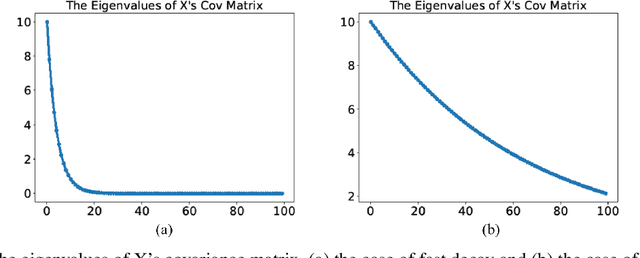
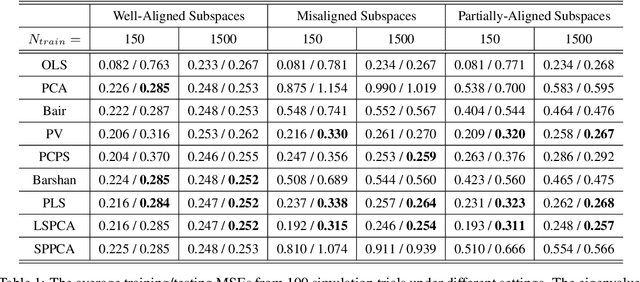
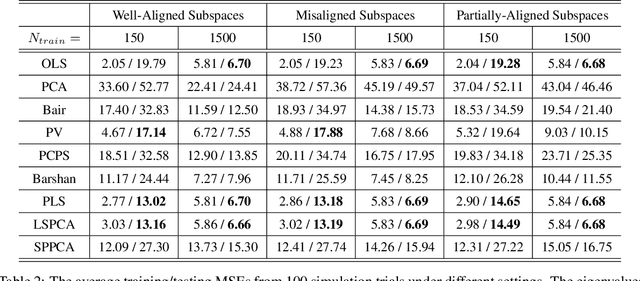
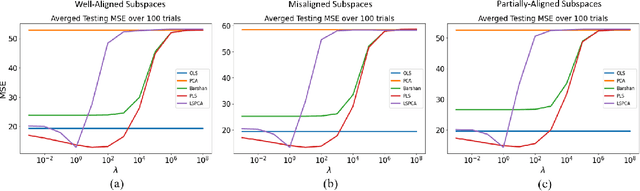
Principal component analysis (PCA) is a well-known linear dimension-reduction method that has been widely used in data analysis and modeling. It is an unsupervised learning technique that identifies a suitable linear subspace for the input variable that contains maximal variation and preserves as much information as possible. PCA has also been used in prediction models where the original, high-dimensional space of predictors is reduced to a smaller, more manageable, set before conducting regression analysis. However, this approach does not incorporate information in the response during the dimension-reduction stage and hence can have poor predictive performance. To address this concern, several supervised linear dimension-reduction techniques have been proposed in the literature. This paper reviews selected techniques, extends some of them, and compares their performance through simulations. Two of these techniques, partial least squares (PLS) and least-squares PCA (LSPCA), consistently outperform the others in this study.
Building Information Modeling and Classification by Visual Learning At A City Scale
Oct 14, 2019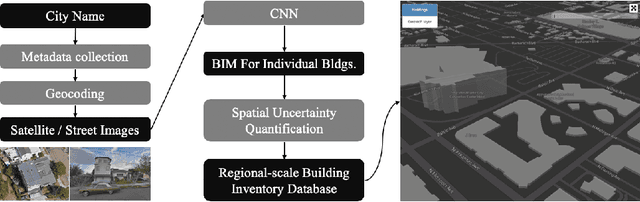

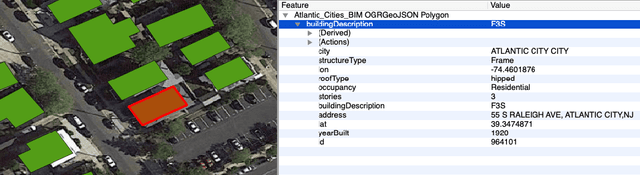
In this paper, we provide two case studies to demonstrate how artificial intelligence can empower civil engineering. In the first case, a machine learning-assisted framework, BRAILS, is proposed for city-scale building information modeling. Building information modeling (BIM) is an efficient way of describing buildings, which is essential to architecture, engineering, and construction. Our proposed framework employs deep learning technique to extract visual information of buildings from satellite/street view images. Further, a novel machine learning (ML)-based statistical tool, SURF, is proposed to discover the spatial patterns in building metadata. The second case focuses on the task of soft-story building classification. Soft-story buildings are a type of buildings prone to collapse during a moderate or severe earthquake. Hence, identifying and retrofitting such buildings is vital in the current earthquake preparedness efforts. For this task, we propose an automated deep learning-based procedure for identifying soft-story buildings from street view images at a regional scale. We also create a large-scale building image database and a semi-automated image labeling approach that effectively annotates new database entries. Through extensive computational experiments, we demonstrate the effectiveness of the proposed method.
DA-LMR: A Robust Lane Markings Representation for Data Association Methods
Nov 17, 2021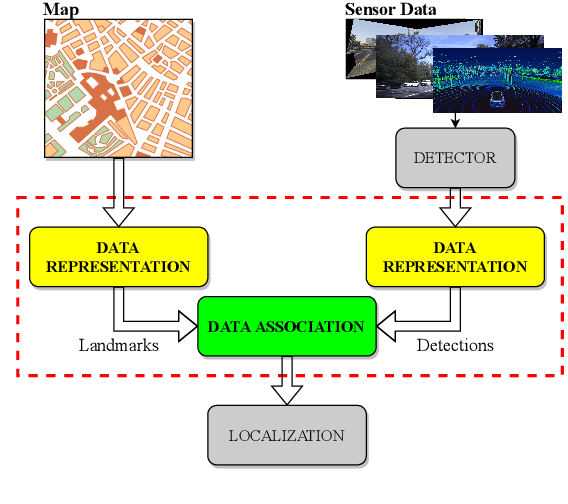
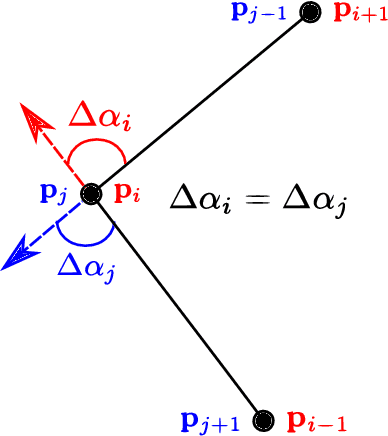

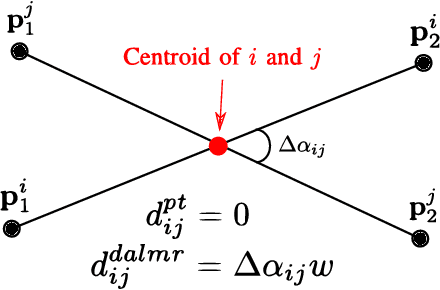
While complete localization approaches are widely studied in the literature, their data association and data representation subprocesses usually go unnoticed. However, both are a key part of the final pose estimation. In this work, we present DA-LMR (Delta-Angle Lane Markings Representation), a robust data representation in the context of localization approaches. We propose a representation of lane markings that encodes how a curve changes in each point and includes this information in an additional dimension, thus providing a more detailed geometric structure description of the data. We also propose DC-SAC (Distance-Compatible Sample Consensus), a data association method. This is a heuristic version of RANSAC that dramatically reduces the hypothesis space by distance compatibility restrictions. We compare the presented methods with some state-of-the-art data representation and data association approaches in different noisy scenarios. The DA-LMR and DC-SAC produce the most promising combination among those compared, reaching 98.1% in precision and 99.7% in recall for noisy data with 0.5m of standard deviation.
Trustworthy Multimodal Regression with Mixture of Normal-inverse Gamma Distributions
Nov 11, 2021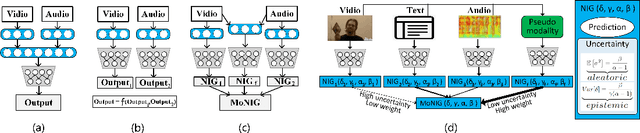
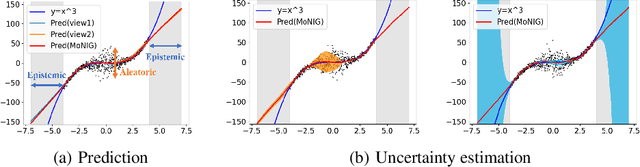
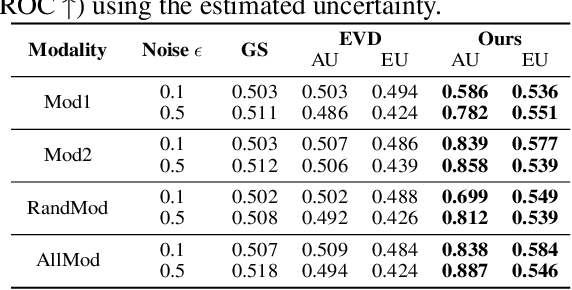
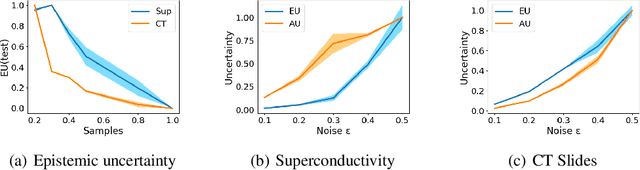
Multimodal regression is a fundamental task, which integrates the information from different sources to improve the performance of follow-up applications. However, existing methods mainly focus on improving the performance and often ignore the confidence of prediction for diverse situations. In this study, we are devoted to trustworthy multimodal regression which is critical in cost-sensitive domains. To this end, we introduce a novel Mixture of Normal-Inverse Gamma distributions (MoNIG) algorithm, which efficiently estimates uncertainty in principle for adaptive integration of different modalities and produces a trustworthy regression result. Our model can be dynamically aware of uncertainty for each modality, and also robust for corrupted modalities. Furthermore, the proposed MoNIG ensures explicitly representation of (modality-specific/global) epistemic and aleatoric uncertainties, respectively. Experimental results on both synthetic and different real-world data demonstrate the effectiveness and trustworthiness of our method on various multimodal regression tasks (e.g., temperature prediction for superconductivity, relative location prediction for CT slices, and multimodal sentiment analysis).
Building Accurate Simple Models with Multihop
Sep 14, 2021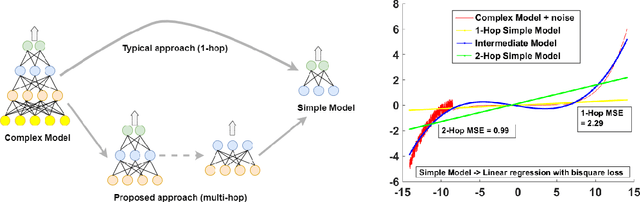
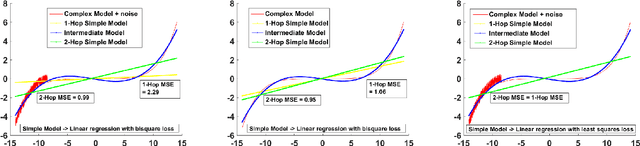
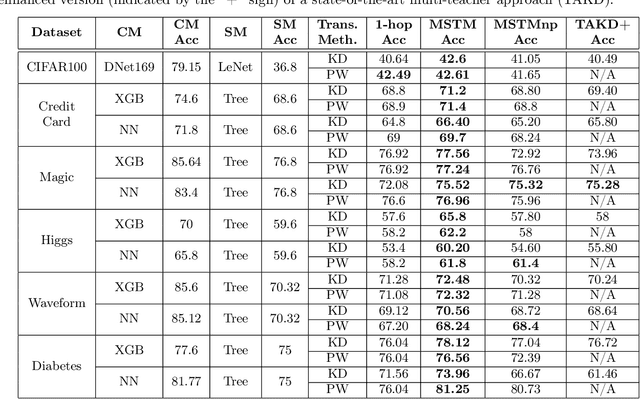
Knowledge transfer from a complex high performing model to a simpler and potentially low performing one in order to enhance its performance has been of great interest over the last few years as it finds applications in important problems such as explainable artificial intelligence, model compression, robust model building and learning from small data. Known approaches to this problem (viz. Knowledge Distillation, Model compression, ProfWeight, etc.) typically transfer information directly (i.e. in a single/one hop) from the complex model to the chosen simple model through schemes that modify the target or reweight training examples on which the simple model is trained. In this paper, we propose a meta-approach where we transfer information from the complex model to the simple model by dynamically selecting and/or constructing a sequence of intermediate models of decreasing complexity that are less intricate than the original complex model. Our approach can transfer information between consecutive models in the sequence using any of the previously mentioned approaches as well as work in 1-hop fashion, thus generalizing these approaches. In the experiments on real data, we observe that we get consistent gains for different choices of models over 1-hop, which on average is more than 2\% and reaches up to 8\% in a particular case. We also empirically analyze conditions under which the multi-hop approach is likely to be beneficial over the traditional 1-hop approach, and report other interesting insights. To the best of our knowledge, this is the first work that proposes such a multi-hop approach to perform knowledge transfer given a single high performing complex model, making it in our opinion, an important methodological contribution.
TransZero: Attribute-guided Transformer for Zero-Shot Learning
Dec 03, 2021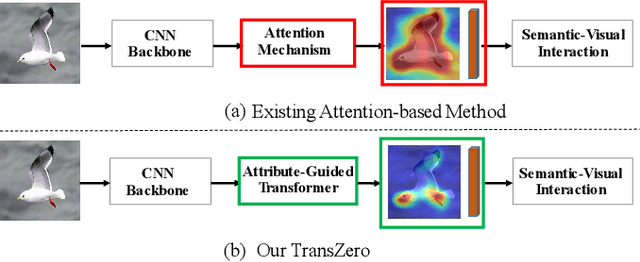
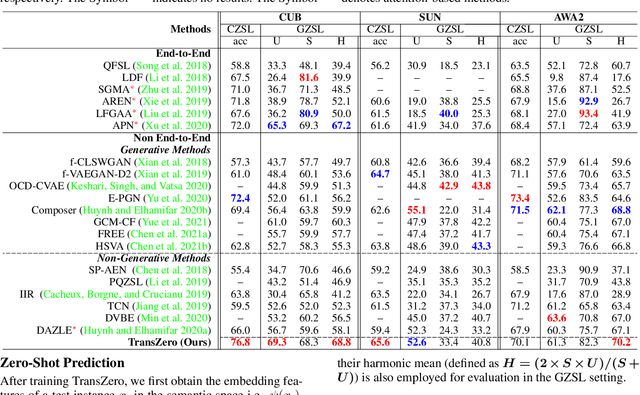
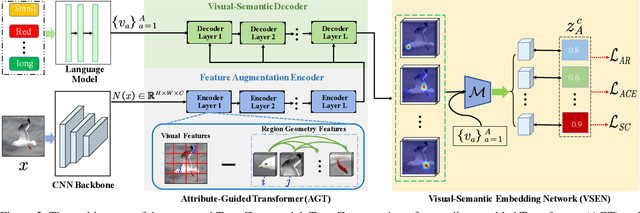
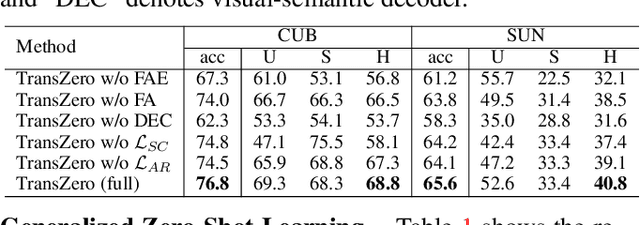
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is learned from attribute descriptions shared between different classes, which act as strong priors for localizing object attributes that represent discriminative region features, enabling significant visual-semantic interaction. Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected. In this paper, we propose an attribute-guided Transformer network, termed TransZero, to refine visual features and learn attribute localization for discriminative visual embedding representations in ZSL. Specifically, TransZero takes a feature augmentation encoder to alleviate the cross-dataset bias between ImageNet and ZSL benchmarks, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. To learn locality-augmented visual features, TransZero employs a visual-semantic decoder to localize the image regions most relevant to each attribute in a given image, under the guidance of semantic attribute information. Then, the locality-augmented visual features and semantic vectors are used to conduct effective visual-semantic interaction in a visual-semantic embedding network. Extensive experiments show that TransZero achieves the new state of the art on three ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero}.
IV-GNN : Interval Valued Data Handling Using Graph Neural Network
Nov 17, 2021
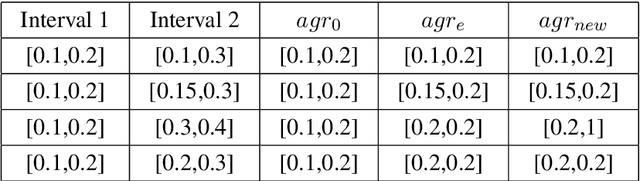

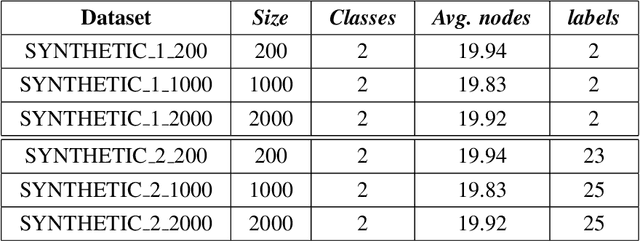
Graph Neural Network (GNN) is a powerful tool to perform standard machine learning on graphs. To have a Euclidean representation of every node in the Non-Euclidean graph-like data, GNN follows neighbourhood aggregation and combination of information recursively along the edges of the graph. Despite having many GNN variants in the literature, no model can deal with graphs having nodes with interval-valued features. This article proposes an Interval-ValuedGraph Neural Network, a novel GNN model where, for the first time, we relax the restriction of the feature space being countable. Our model is much more general than existing models as any countable set is always a subset of the universal set $R^{n}$, which is uncountable. Here, to deal with interval-valued feature vectors, we propose a new aggregation scheme of intervals and show its expressive power to capture different interval structures. We validate our theoretical findings about our model for graph classification tasks by comparing its performance with those of the state-of-the-art models on several benchmark network and synthetic datasets.
An Automatic Approach for Generating Rich, Linked Geo-Metadata from Historical Map Images
Dec 03, 2021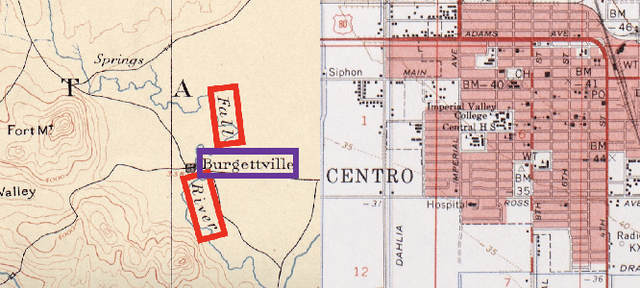
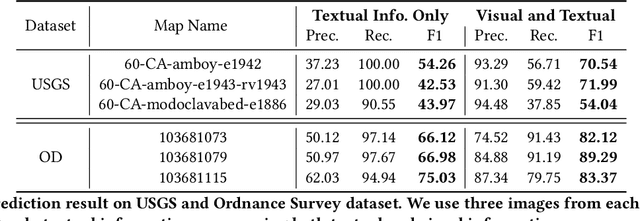
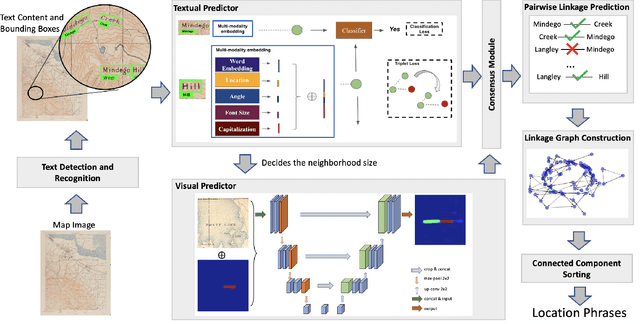
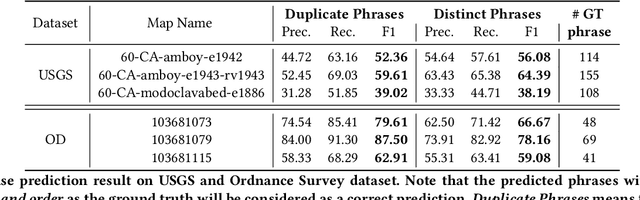
Historical maps contain detailed geographic information difficult to find elsewhere covering long-periods of time (e.g., 125 years for the historical topographic maps in the US). However, these maps typically exist as scanned images without searchable metadata. Existing approaches making historical maps searchable rely on tedious manual work (including crowd-sourcing) to generate the metadata (e.g., geolocations and keywords). Optical character recognition (OCR) software could alleviate the required manual work, but the recognition results are individual words instead of location phrases (e.g., "Black" and "Mountain" vs. "Black Mountain"). This paper presents an end-to-end approach to address the real-world problem of finding and indexing historical map images. This approach automatically processes historical map images to extract their text content and generates a set of metadata that is linked to large external geospatial knowledge bases. The linked metadata in the RDF (Resource Description Framework) format support complex queries for finding and indexing historical maps, such as retrieving all historical maps covering mountain peaks higher than 1,000 meters in California. We have implemented the approach in a system called mapKurator. We have evaluated mapKurator using historical maps from several sources with various map styles, scales, and coverage. Our results show significant improvement over the state-of-the-art methods. The code has been made publicly available as modules of the Kartta Labs project at https://github.com/kartta-labs/Project.
Rate-Splitting Multiple Access for Satellite-Terrestrial Integrated Networks:Benefits of Coordination and Cooperation
Nov 28, 2021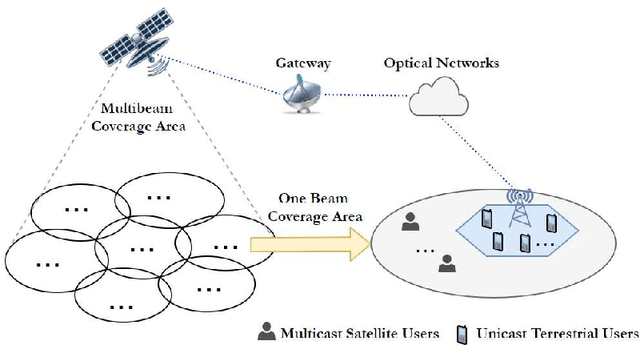
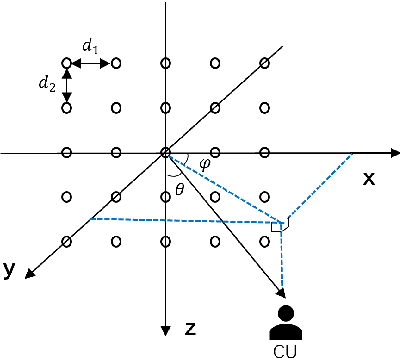
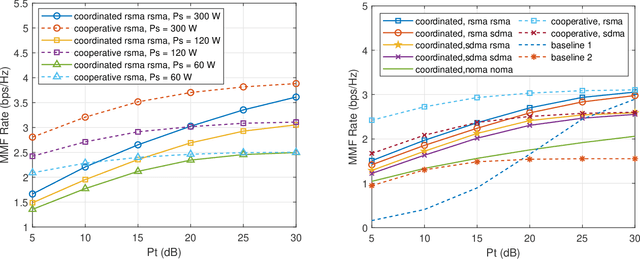
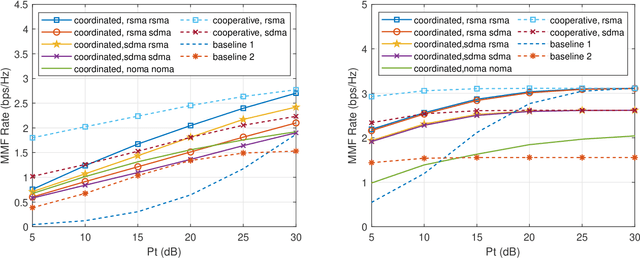
This work studies the joint beamforming design problem of achieving max-min rate fairness in a satellite-terrestrial integrated network (STIN) where the satellite provides wide coverage to multibeam multicast satellite users (SUs), and the terrestrial base station (BS) serves multiple cellular users (CUs) in a densely populated area. Both the satellite and BS operate in the same frequency band. Since rate-splitting multiple access (RSMA) has recently emerged as a promising strategy for non-orthogonal transmission and robust interference management in multi-antenna wireless networks, we present two RSMA-based STIN schemes, namely the coordinated scheme relying on channel state information (CSI) sharing and the cooperative scheme relying on CSI and data sharing. Our objective is to maximize the minimum fairness rate amongst all SUs and CUs subject to transmit power constraints at the satellite and the BS. A joint beamforming algorithm is proposed to reformulate the original problem into an approximately equivalent convex one which can be iteratively solved. Moreover, an expectation-based robust joint beamforming algorithm is proposed against the practical environment when satellite channel phase uncertainties are considered. Simulation results demonstrate the effectiveness and robustness of our proposed RSMA schemes for STIN, and exhibit significant performance gains compared with various traditional transmission strategies.