 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Road Ahead in Autonomous Driving: The KITScenes Multimodal Dataset
Jun 01, 2026Existing autonomous driving datasets have enabled major progress, but fall short in sensor fidelity, map completeness, or geographic diversity. We present KITScenes Multimodal, a European dataset built around high-fidelity sensors and maps. Our fully synchronized sensor suite combines high-resolution global-shutter cameras, long-range lidar beyond 400m, 4D imaging radar, and redundant GNSS/INS localization. Our HD maps are, to our knowledge, the most complete of any sensor dataset, validated through autonomous driving trials on open-source software. For the first time in a public dataset, all driving-relevant traffic elements, such as traffic lights, are mapped in 3D to a reprojection-accurate level with full topological connectivity. Recorded in cities with irregular street layouts and mixed traffic modes, our dataset complements existing datasets by broadening the available geographic diversity. We also introduce four benchmarks, each advancing spatial learning for embodied AI: online HD map construction, long-range depth estimation, novel view synthesis, and end-to-end driving. Project page: https://kitscenes.com/
Mosaic: An Extensible Framework for Composing Rule-Based and Learned Motion Planners
Apr 15, 2026Safe and explainable motion planning remains a central challenge in autonomous driving. While rule-based planners offer predictable and explainable behavior, they often fail to grasp the complexity and uncertainty of real-world traffic. Conversely, learned planners exhibit strong adaptability but suffer from reduced transparency and occasional safety violations. We introduce Mosaic, an extensible framework for structured decision-making that integrates both paradigms through arbitration graphs. By decoupling trajectory verification and scoring from the generation of trajectories by individual planners, every decision becomes transparent and traceable. Trajectory verification at a higher level introduces redundancy between the planners, limiting emergency braking to the rare case where all planners fail to produce a valid trajectory. Through unified scoring and optimal trajectory selection, rule-based and learned planners with complementary strengths and weaknesses can be combined to yield the best of both worlds. In experimental evaluation on nuPlan, Mosaic achieves 95.48 CLS-NR and 93.98 CLS-R on the Val14 closed-loop benchmark, setting a new state of the art, while reducing at-fault collisions by 30% compared to either planner in isolation. On the interPlan benchmark, focused on highly interactive and difficult scenarios, Mosaic scores 54.30 CLS-R, outperforming its best constituent planner by 23.3% - all without retraining or requiring additional data. The code is available at github.com/KIT-MRT/mosaic.
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Mar 24, 2026In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
MapGCLR: Geospatial Contrastive Learning of Representations for Online Vectorized HD Map Construction
Mar 11, 2026Autonomous vehicles rely on map information to understand the world around them. However, the creation and maintenance of offline high-definition (HD) maps remains costly. A more scalable alternative lies in online HD map construction, which only requires map annotations at training time. To further reduce the need for annotating vast training labels, self-supervised training provides an alternative. This work focuses on improving the latent birds-eye-view (BEV) feature grid representation within a vectorized online HD map construction model by enforcing geospatial consistency between overlapping BEV feature grids as part of a contrastive loss function. To ensure geospatial overlap for contrastive pairs, we introduce an approach to analyze the overlap between traversals within a given dataset and generate subsidiary dataset splits following adjustable multi-traversal requirements. We train the same model supervised using a reduced set of single-traversal labeled data and self-supervised on a broader unlabeled set of data following our multi-traversal requirements, effectively implementing a semi-supervised approach. Our approach outperforms the supervised baseline across the board, both quantitatively in terms of the downstream tasks vectorized map perception performance and qualitatively in terms of segmentation in the principal component analysis (PCA) visualization of the BEV feature space.
Impact of Localization Errors on Label Quality for Online HD Map Construction
Mar 03, 2026High-definition (HD) maps are crucial for autonomous vehicles, but their creation and maintenance is very costly. This motivates the idea of online HD map construction. To provide a continuous large-scale stream of training data, existing HD maps can be used as labels for onboard sensor data from consumer vehicle fleets. However, compared to current, well curated HD map perception datasets, this fleet data suffers from localization errors, resulting in distorted map labels. We introduce three kinds of localization errors, Ramp, Gaussian, and Perlin noise, to examine their influence on generated map labels. We train a variant of MapTRv2, a state-of-the-art online HD map construction model, on the Argoverse 2 dataset with various levels of localization errors and assess the degradation of model performance. Since localization errors affect distant labels more severely, but are also less significant to driving performance, we introduce a distance-based map construction metric. Our experiments reveal that localization noise affects the model performance significantly. We demonstrate that errors in heading angle exert a more substantial influence than position errors, as angle errors result in a greater distortion of labels as distance to the vehicle increases. Furthermore, we can demonstrate that the model benefits from non-distorted ground truth (GT) data and that the performance decreases more than linearly with the increase in noisy data. Our study additionally provides a qualitative evaluation of the extent to which localization errors influence the construction of HD maps.
Radar-based Pose Optimization for HD Map Generation from Noisy Multi-Drive Vehicle Fleet Data
Mar 03, 2026High-definition (HD) maps are important for autonomous driving, but their manual generation and maintenance is very expensive. This motivates the usage of an automated map generation pipeline. Fleet vehicles provide sufficient sensors for map generation, but their measurements are less precise, introducing noise into the mapping pipeline. This work focuses on mitigating the localization noise component through aligning radar measurements in terms of raw radar point clouds of vehicle poses of different drives and performing pose graph optimization to produce a globally optimized solution between all drives present in the dataset. Improved poses are first used to generate a global radar occupancy map, aimed to facilitate precise on-vehicle localization. Through qualitative analysis we show contrast-rich feature clarity, focusing on omnipresent guardrail posts as the main feature type observable in the map. Second, the improved poses can be used as a basis for an existing lane boundary map generation pipeline, majorly improving map output compared to its original pure line detection based optimization approach.
XD-MAP: Cross-Modal Domain Adaptation using Semantic Parametric Mapping
Jan 20, 2026Until open-world foundation models match the performance of specialized approaches, the effectiveness of deep learning models remains heavily dependent on dataset availability. Training data must align not only with the target object categories but also with the sensor characteristics and modalities. To bridge the gap between available datasets and deployment domains, domain adaptation strategies are widely used. In this work, we propose a novel approach to transferring sensor-specific knowledge from an image dataset to LiDAR, an entirely different sensing domain. Our method XD-MAP leverages detections from a neural network on camera images to create a semantic parametric map. The map elements are modeled to produce pseudo labels in the target domain without any manual annotation effort. Unlike previous domain transfer approaches, our method does not require direct overlap between sensors and enables extending the angular perception range from a front-view camera to a full 360 view. On our large-scale road feature dataset, XD-MAP outperforms single shot baseline approaches by +19.5 mIoU for 2D semantic segmentation, +19.5 PQth for 2D panoptic segmentation, and +32.3 mIoU in 3D semantic segmentation. The results demonstrate the effectiveness of our approach achieving strong performance on LiDAR data without any manual labeling.
NaviHydra: Controllable Navigation-guided End-to-end Autonomous Driving with Hydra-distillation
Dec 11, 2025



The complexity of autonomous driving scenarios requires robust models that can interpret high-level navigation commands and generate safe trajectories. While traditional rule-based systems can react to these commands, they often struggle in dynamic environments, and end-to-end methods face challenges in complying with explicit navigation commands. To address this, we present NaviHydra, a controllable navigation-guided end-to-end model distilled from an existing rule-based simulator. Our framework accepts high-level navigation commands as control signals, generating trajectories that align with specified intentions. We utilize a Bird's Eye View (BEV) based trajectory gathering method to enhance the trajectory feature extraction. Additionally, we introduce a novel navigation compliance metric to evaluate adherence to intended route, improving controllability and navigation safety. To comprehensively assess our model's controllability, we design a test that evaluates its response to various navigation commands. Our method significantly outperforms baseline models, achieving state-of-the-art results in the NAVSIM benchmark, demonstrating its effectiveness in advancing autonomous driving.
FlowDrive: moderated flow matching with data balancing for trajectory planning
Sep 26, 2025Learning-based planners are sensitive to the long-tailed distribution of driving data. Common maneuvers dominate datasets, while dangerous or rare scenarios are sparse. This imbalance can bias models toward the frequent cases and degrade performance on critical scenarios. To tackle this problem, we compare balancing strategies for sampling training data and find reweighting by trajectory pattern an effective approach. We then present FlowDrive, a flow-matching trajectory planner that learns a conditional rectified flow to map noise directly to trajectory distributions with few flow-matching steps. We further introduce moderated, in-the-loop guidance that injects small perturbation between flow steps to systematically increase trajectory diversity while remaining scene-consistent. On nuPlan and the interaction-focused interPlan benchmarks, FlowDrive achieves state-of-the-art results among learning-based planners and approaches methods with rule-based refinements. After adding moderated guidance and light post-processing (FlowDrive*), it achieves overall state-of-the-art performance across nearly all benchmark splits.
Vision-based Lifting of 2D Object Detections for Automated Driving
Jun 13, 2025

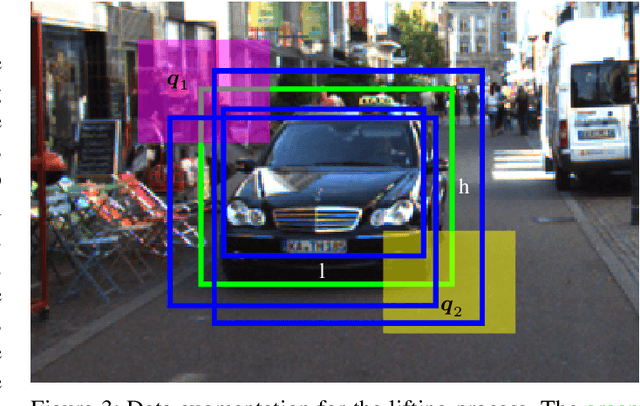

Image-based 3D object detection is an inevitable part of autonomous driving because cheap onboard cameras are already available in most modern cars. Because of the accurate depth information, currently, most state-of-the-art 3D object detectors heavily rely on LiDAR data. In this paper, we propose a pipeline which lifts the results of existing vision-based 2D algorithms to 3D detections using only cameras as a cost-effective alternative to LiDAR. In contrast to existing approaches, we focus not only on cars but on all types of road users. To the best of our knowledge, we are the first using a 2D CNN to process the point cloud for each 2D detection to keep the computational effort as low as possible. Our evaluation on the challenging KITTI 3D object detection benchmark shows results comparable to state-of-the-art image-based approaches while having a runtime of only a third.
* https://ieeexplore.ieee.org/document/9190325