 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSCOPE: Evaluating Contextual Privacy Across Agentic Workflows
Mar 05, 2026Agentic systems are increasingly acting on users' behalf, accessing calendars, email, and personal files to complete everyday tasks. Privacy evaluation for these systems has focused on the input and output boundaries, but each task involves several intermediate information flows, from agent queries to tool responses, that are not currently evaluated. We argue that every boundary in an agentic pipeline is a site of potential privacy violation and must be assessed independently. To support this, we introduce the Privacy Flow Graph, a Contextual Integrity-grounded framework that decomposes agentic execution into a sequence of information flows, each annotated with the five CI parameters, and traces violations to their point of origin. We present AgentSCOPE, a benchmark of 62 multi-tool scenarios across eight regulatory domains with ground truth at every pipeline stage. Our evaluation across seven state-of-the-art LLMs show that privacy violations in the pipeline occur in over 80% of scenarios, even when final outputs appear clean (24%), with most violations arising at the tool-response stage where APIs return sensitive data indiscriminately. These results indicate that output-level evaluation alone substantially underestimates the privacy risk of agentic systems.
CoFrGeNet: Continued Fraction Architectures for Language Generation
Jan 29, 2026Transformers are arguably the preferred architecture for language generation. In this paper, inspired by continued fractions, we introduce a new function class for generative modeling. The architecture family implementing this function class is named CoFrGeNets - Continued Fraction Generative Networks. We design novel architectural components based on this function class that can replace Multi-head Attention and Feed-Forward Networks in Transformer blocks while requiring much fewer parameters. We derive custom gradient formulations to optimize the proposed components more accurately and efficiently than using standard PyTorch-based gradients. Our components are a plug-in replacement requiring little change in training or inference procedures that have already been put in place for Transformer-based models thus making our approach easy to incorporate in large industrial workflows. We experiment on two very different transformer architectures GPT2-xl (1.5B) and Llama3 (3.2B), where the former we pre-train on OpenWebText and GneissWeb, while the latter we pre-train on the docling data mix which consists of nine different datasets. Results show that the performance on downstream classification, Q\& A, reasoning and text understanding tasks of our models is competitive and sometimes even superior to the original models with $\frac{2}{3}$ to $\frac{1}{2}$ the parameters and shorter pre-training time. We believe that future implementations customized to hardware will further bring out the true potential of our architectures.
CoFrNets: Interpretable Neural Architecture Inspired by Continued Fractions
Jun 05, 2025In recent years there has been a considerable amount of research on local post hoc explanations for neural networks. However, work on building interpretable neural architectures has been relatively sparse. In this paper, we present a novel neural architecture, CoFrNet, inspired by the form of continued fractions which are known to have many attractive properties in number theory, such as fast convergence of approximations to real numbers. We show that CoFrNets can be efficiently trained as well as interpreted leveraging their particular functional form. Moreover, we prove that such architectures are universal approximators based on a proof strategy that is different than the typical strategy used to prove universal approximation results for neural networks based on infinite width (or depth), which is likely to be of independent interest. We experiment on nonlinear synthetic functions and are able to accurately model as well as estimate feature attributions and even higher order terms in some cases, which is a testament to the representational power as well as interpretability of such architectures. To further showcase the power of CoFrNets, we experiment on seven real datasets spanning tabular, text and image modalities, and show that they are either comparable or significantly better than other interpretable models and multilayer perceptrons, sometimes approaching the accuracies of state-of-the-art models.
Protecting Users From Themselves: Safeguarding Contextual Privacy in Interactions with Conversational Agents
Feb 22, 2025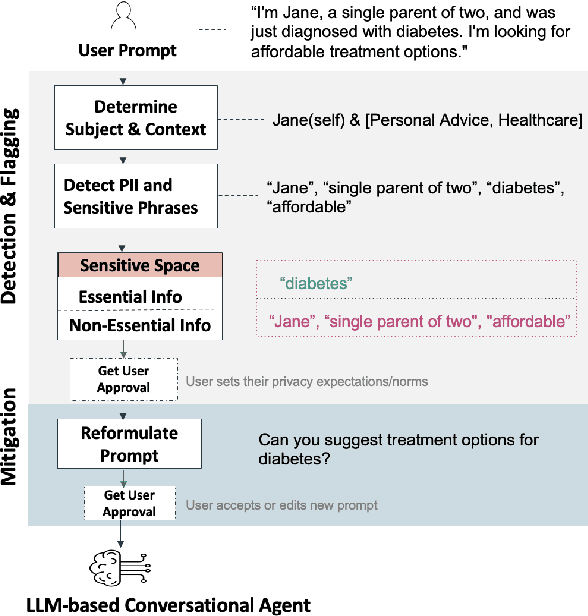

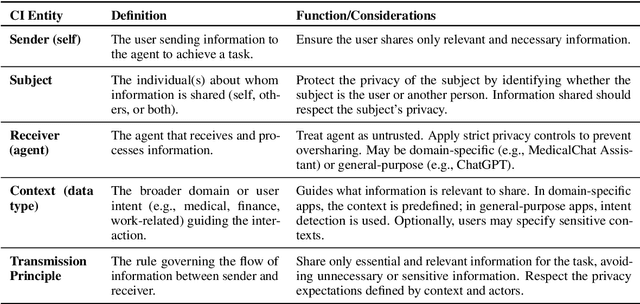
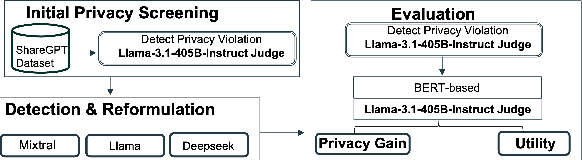
Conversational agents are increasingly woven into individuals' personal lives, yet users often underestimate the privacy risks involved. The moment users share information with these agents (e.g., LLMs), their private information becomes vulnerable to exposure. In this paper, we characterize the notion of contextual privacy for user interactions with LLMs. It aims to minimize privacy risks by ensuring that users (sender) disclose only information that is both relevant and necessary for achieving their intended goals when interacting with LLMs (untrusted receivers). Through a formative design user study, we observe how even "privacy-conscious" users inadvertently reveal sensitive information through indirect disclosures. Based on insights from this study, we propose a locally-deployable framework that operates between users and LLMs, and identifies and reformulates out-of-context information in user prompts. Our evaluation using examples from ShareGPT shows that lightweight models can effectively implement this framework, achieving strong gains in contextual privacy while preserving the user's intended interaction goals through different approaches to classify information relevant to the intended goals.
AGGA: A Dataset of Academic Guidelines for Generative AI and Large Language Models
Jan 07, 2025
This study introduces AGGA, a dataset comprising 80 academic guidelines for the use of Generative AIs (GAIs) and Large Language Models (LLMs) in academic settings, meticulously collected from official university websites. The dataset contains 188,674 words and serves as a valuable resource for natural language processing tasks commonly applied in requirements engineering, such as model synthesis, abstraction identification, and document structure assessment. Additionally, AGGA can be further annotated to function as a benchmark for various tasks, including ambiguity detection, requirements categorization, and the identification of equivalent requirements. Our methodologically rigorous approach ensured a thorough examination, with a selection of universities that represent a diverse range of global institutions, including top-ranked universities across six continents. The dataset captures perspectives from a variety of academic fields, including humanities, technology, and both public and private institutions, offering a broad spectrum of insights into the integration of GAIs and LLMs in academia.
Final-Model-Only Data Attribution with a Unifying View of Gradient-Based Methods
Dec 05, 2024



Training data attribution (TDA) is the task of attributing model behavior to elements in the training data. This paper draws attention to the common setting where one has access only to the final trained model, and not the training algorithm or intermediate information from training. To serve as a gold standard for TDA in this "final-model-only" setting, we propose further training, with appropriate adjustment and averaging, to measure the sensitivity of the given model to training instances. We then unify existing gradient-based methods for TDA by showing that they all approximate the further training gold standard in different ways. We investigate empirically the quality of these gradient-based approximations to further training, for tabular, image, and text datasets and models. We find that the approximation quality of first-order methods is sometimes high but decays with the amount of further training. In contrast, the approximations given by influence function methods are more stable but surprisingly lower in quality.
Identifying Sub-networks in Neural Networks via Functionally Similar Representations
Oct 21, 2024



Mechanistic interpretability aims to provide human-understandable insights into the inner workings of neural network models by examining their internals. Existing approaches typically require significant manual effort and prior knowledge, with strategies tailored to specific tasks. In this work, we take a step toward automating the understanding of the network by investigating the existence of distinct sub-networks. Specifically, we explore a novel automated and task-agnostic approach based on the notion of functionally similar representations within neural networks, reducing the need for human intervention. Our method identifies similar and dissimilar layers in the network, revealing potential sub-components. We achieve this by proposing, for the first time to our knowledge, the use of Gromov-Wasserstein distance, which overcomes challenges posed by varying distributions and dimensionalities across intermediate representations, issues that complicate direct layer-to-layer comparisons. Through experiments on algebraic and language tasks, we observe the emergence of sub-groups within neural network layers corresponding to functional abstractions. Additionally, we find that different training strategies influence the positioning of these sub-groups. Our approach offers meaningful insights into the behavior of neural networks with minimal human and computational cost.
Programming Refusal with Conditional Activation Steering
Sep 06, 2024



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
CELL your Model: Contrastive Explanation Methods for Large Language Models
Jun 17, 2024The advent of black-box deep neural network classification models has sparked the need to explain their decisions. However, in the case of generative AI such as large language models (LLMs), there is no class prediction to explain. Rather, one can ask why an LLM output a particular response to a given prompt. In this paper, we answer this question by proposing, to the best of our knowledge, the first contrastive explanation methods requiring simply black-box/query access. Our explanations suggest that an LLM outputs a reply to a given prompt because if the prompt was slightly modified, the LLM would have given a different response that is either less preferable or contradicts the original response. The key insight is that contrastive explanations simply require a distance function that has meaning to the user and not necessarily a real valued representation of a specific response (viz. class label). We offer two algorithms for finding contrastive explanations: i) A myopic algorithm, which although effective in creating contrasts, requires many model calls and ii) A budgeted algorithm, our main algorithmic contribution, which intelligently creates contrasts adhering to a query budget, necessary for longer contexts. We show the efficacy of these methods on diverse natural language tasks such as open-text generation, automated red teaming, and explaining conversational degradation.
Large Language Model Confidence Estimation via Black-Box Access
Jun 01, 2024



Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10\%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.