 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Global AUC into Cluster-Level Contributions for Localized Model Diagnostics
Aug 10, 2025The Area Under the ROC Curve (AUC) is a widely used performance metric for binary classifiers. However, as a global ranking statistic, the AUC aggregates model behavior over the entire dataset, masking localized weaknesses in specific subpopulations. In high-stakes applications such as credit approval and fraud detection, these weaknesses can lead to financial risk or operational failures. In this paper, we introduce a formal decomposition of global AUC into intra- and inter-cluster components. This allows practitioners to evaluate classifier performance within and across clusters of data, enabling granular diagnostics and subgroup analysis. We also compare the AUC with additive performance metrics such as the Brier score and log loss, which support decomposability and direct attribution. Our framework enhances model development and validation practice by providing additional insights to detect model weakness for model risk management.
Human-Calibrated Automated Testing and Validation of Generative Language Models
Nov 25, 2024This paper introduces a comprehensive framework for the evaluation and validation of generative language models (GLMs), with a focus on Retrieval-Augmented Generation (RAG) systems deployed in high-stakes domains such as banking. GLM evaluation is challenging due to open-ended outputs and subjective quality assessments. Leveraging the structured nature of RAG systems, where generated responses are grounded in a predefined document collection, we propose the Human-Calibrated Automated Testing (HCAT) framework. HCAT integrates a) automated test generation using stratified sampling, b) embedding-based metrics for explainable assessment of functionality, risk and safety attributes, and c) a two-stage calibration approach that aligns machine-generated evaluations with human judgments through probability calibration and conformal prediction. In addition, the framework includes robustness testing to evaluate model performance against adversarial, out-of-distribution, and varied input conditions, as well as targeted weakness identification using marginal and bivariate analysis to pinpoint specific areas for improvement. This human-calibrated, multi-layered evaluation framework offers a scalable, transparent, and interpretable approach to GLM assessment, providing a practical and reliable solution for deploying GLMs in applications where accuracy, transparency, and regulatory compliance are paramount.
Towards a framework on tabular synthetic data generation: a minimalist approach: theory, use cases, and limitations
Nov 19, 2024We propose and study a minimalist approach towards synthetic tabular data generation. The model consists of a minimalistic unsupervised SparsePCA encoder (with contingent clustering step or log transformation to handle nonlinearity) and XGboost decoder which is SOTA for structured data regression and classification tasks. We study and contrast the methodologies with (variational) autoencoders in several toy low dimensional scenarios to derive necessary intuitions. The framework is applied to high dimensional simulated credit scoring data which parallels real-life financial applications. We applied the method to robustness testing to demonstrate practical use cases. The case study result suggests that the method provides an alternative to raw and quantile perturbation for model robustness testing. We show that the method is simplistic, guarantees interpretability all the way through, does not require extra tuning and provide unique benefits.
Less Discriminatory Alternative and Interpretable XGBoost Framework for Binary Classification
Oct 24, 2024



Fair lending practices and model interpretability are crucial concerns in the financial industry, especially given the increasing use of complex machine learning models. In response to the Consumer Financial Protection Bureau's (CFPB) requirement to protect consumers against unlawful discrimination, we introduce LDA-XGB1, a novel less discriminatory alternative (LDA) machine learning model for fair and interpretable binary classification. LDA-XGB1 is developed through biobjective optimization that balances accuracy and fairness, with both objectives formulated using binning and information value. It leverages the predictive power and computational efficiency of XGBoost while ensuring inherent model interpretability, including the enforcement of monotonic constraints. We evaluate LDA-XGB1 on two datasets: SimuCredit, a simulated credit approval dataset, and COMPAS, a real-world recidivism prediction dataset. Our results demonstrate that LDA-XGB1 achieves an effective balance between predictive accuracy, fairness, and interpretability, often outperforming traditional fair lending models. This approach equips financial institutions with a powerful tool to meet regulatory requirements for fair lending while maintaining the advantages of advanced machine learning techniques.
Inherently Interpretable Tree Ensemble Learning
Oct 24, 2024



Tree ensemble models like random forests and gradient boosting machines are widely used in machine learning due to their excellent predictive performance. However, a high-performance ensemble consisting of a large number of decision trees lacks sufficient transparency and explainability. In this paper, we demonstrate that when shallow decision trees are used as base learners, the ensemble learning algorithms can not only become inherently interpretable subject to an equivalent representation as the generalized additive models but also sometimes lead to better generalization performance. First, an interpretation algorithm is developed that converts the tree ensemble into the functional ANOVA representation with inherent interpretability. Second, two strategies are proposed to further enhance the model interpretability, i.e., by adding constraints in the model training stage and post-hoc effect pruning. Experiments on simulations and real-world datasets show that our proposed methods offer a better trade-off between model interpretation and predictive performance, compared with its counterpart benchmarks.
Automatic Generation of Behavioral Test Cases For Natural Language Processing Using Clustering and Prompting
Jul 31, 2024



Recent work in behavioral testing for natural language processing (NLP) models, such as Checklist, is inspired by related paradigms in software engineering testing. They allow evaluation of general linguistic capabilities and domain understanding, hence can help evaluate conceptual soundness and identify model weaknesses. However, a major challenge is the creation of test cases. The current packages rely on semi-automated approach using manual development which requires domain expertise and can be time consuming. This paper introduces an automated approach to develop test cases by exploiting the power of large language models and statistical techniques. It clusters the text representations to carefully construct meaningful groups and then apply prompting techniques to automatically generate Minimal Functionality Tests (MFT). The well-known Amazon Reviews corpus is used to demonstrate our approach. We analyze the behavioral test profiles across four different classification algorithms and discuss the limitations and strengths of those models.
Interpretable Machine Learning based on Functional ANOVA Framework: Algorithms and Comparisons
May 25, 2023



In the early days of machine learning (ML), the emphasis was on developing complex algorithms to achieve best predictive performance. To understand and explain the model results, one had to rely on post hoc explainability techniques, which are known to have limitations. Recently, with the recognition that interpretability is just as important, researchers are compromising on small increases in predictive performance to develop algorithms that are inherently interpretable. While doing so, the ML community has rediscovered the use of low-order functional ANOVA (fANOVA) models that have been known in the statistical literature for some time. This paper starts with a description of challenges with post hoc explainability and reviews the fANOVA framework with a focus on main effects and second-order interactions. This is followed by an overview of two recently developed techniques: Explainable Boosting Machines or EBM (Lou et al., 2013) and GAMI-Net (Yang et al., 2021b). The paper proposes a new algorithm, called GAMI-Lin-T, that also uses trees like EBM, but it does linear fits instead of piecewise constants within the partitions. There are many other differences, including the development of a new interaction filtering algorithm. Finally, the paper uses simulated and real datasets to compare selected ML algorithms. The results show that GAMI-Lin-T and GAMI-Net have comparable performances, and both are generally better than EBM.
Enhancing Robustness of Gradient-Boosted Decision Trees through One-Hot Encoding and Regularization
May 11, 2023Gradient-boosted decision trees (GBDT) are widely used and highly effective machine learning approach for tabular data modeling. However, their complex structure may lead to low robustness against small covariate perturbation in unseen data. In this study, we apply one-hot encoding to convert a GBDT model into a linear framework, through encoding of each tree leaf to one dummy variable. This allows for the use of linear regression techniques, plus a novel risk decomposition for assessing the robustness of a GBDT model against covariate perturbations. We propose to enhance the robustness of GBDT models by refitting their linear regression forms with $L_1$ or $L_2$ regularization. Theoretical results are obtained about the effect of regularization on the model performance and robustness. It is demonstrated through numerical experiments that the proposed regularization approach can enhance the robustness of the one-hot-encoded GBDT models.
PiML Toolbox for Interpretable Machine Learning Model Development and Validation
May 07, 2023PiML (read $\pi$-ML, /`pai.`em.`el/) is an integrated and open-access Python toolbox for interpretable machine learning model development and model diagnostics. It is designed with machine learning workflows in both low-code and high-code modes, including data pipeline, model training, model interpretation and explanation, and model diagnostics and comparison. The toolbox supports a growing list of interpretable models (e.g. GAM, GAMI-Net, XGB2) with inherent local and/or global interpretability. It also supports model-agnostic explainability tools (e.g. PFI, PDP, LIME, SHAP) and a powerful suite of model-agnostic diagnostics (e.g. weakness, uncertainty, robustness, fairness). Integration of PiML models and tests to existing MLOps platforms for quality assurance are enabled by flexible high-code APIs. Furthermore, PiML toolbox comes with a comprehensive user guide and hands-on examples, including the applications for model development and validation in banking. The project is available at https://github.com/SelfExplainML/PiML-Toolbox.
Explaining Adverse Actions in Credit Decisions Using Shapley Decomposition
Apr 26, 2022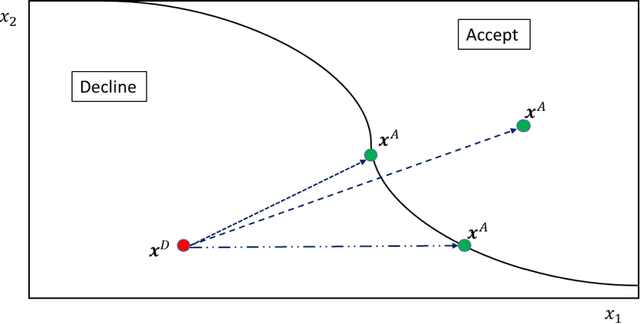
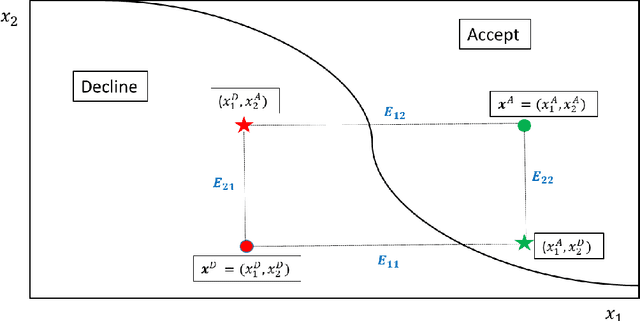

When a financial institution declines an application for credit, an adverse action (AA) is said to occur. The applicant is then entitled to an explanation for the negative decision. This paper focuses on credit decisions based on a predictive model for probability of default and proposes a methodology for AA explanation. The problem involves identifying the important predictors responsible for the negative decision and is straightforward when the underlying model is additive. However, it becomes non-trivial even for linear models with interactions. We consider models with low-order interactions and develop a simple and intuitive approach based on first principles. We then show how the methodology generalizes to the well-known Shapely decomposition and the recently proposed concept of Baseline Shapley (B-Shap). Unlike other Shapley techniques in the literature for local interpretability of machine learning results, B-Shap is computationally tractable since it involves just function evaluations. An illustrative case study is used to demonstrate the usefulness of the method. The paper also discusses situations with highly correlated predictors and desirable properties of fitted models in the credit-lending context, such as monotonicity and continuity.